- The paper introduces a novel technique integrating learnable viewpoint tokens to explicitly condition camera positions in text-to-image models.
- The methodology employs a 5-dimensional parameterization and a multi-layer perceptron to encode precise camera parameters within text embeddings.
- Experimental results show superior camera pose fidelity and high image quality across varying orientations compared to existing models.
Detailed Summary of "Camera Control for Text-to-Image Generation via Learning Viewpoint Tokens" (2604.19954)
Introduction
The paper addresses the limitation of current text-to-image models in providing precise camera control using natural language. These models often fail to accurately render specified viewpoints due to the ambiguous nature of language, typically defaulting to biased canonical angles or inconsistent geometric outputs. The authors propose a novel framework that integrates parametric camera tokens into the text-to-image generation process, allowing for explicit viewpoint conditioning. This approach uses a curated dataset comprising both 3D-rendered images and photorealistic augmentations to fine-tune the image generation models, achieving state-of-the-art accuracy in viewpoint specification.

Figure 1: Our model vs.\ Gemini 2.5 Flash Image (Nano Banana)—illustrating improved camera pose control.
Methodology
Viewpoint Parameterization
The authors use an object-centric coordinate system where the object is centered at the origin, and its front faces the positive x-axis. Camera viewpoints are parameterized using a 5-dimensional representation: azimuth, elevation, radius, pitch, and yaw. This setup ensures consistent camera placement and reduces ambiguity in viewpoint specification.
Viewpoint Token Encoding
Camera parameters are encoded into learnable viewpoint tokens via a multi-layer perceptron (MLP) architecture. These tokens are then concatenated with text embeddings, allowing the combined input to flow through a text-to-image generation model. This encoding seamlessly integrates geometric information into the text prompts, enabling better control over image generation concerning specific viewpoints.
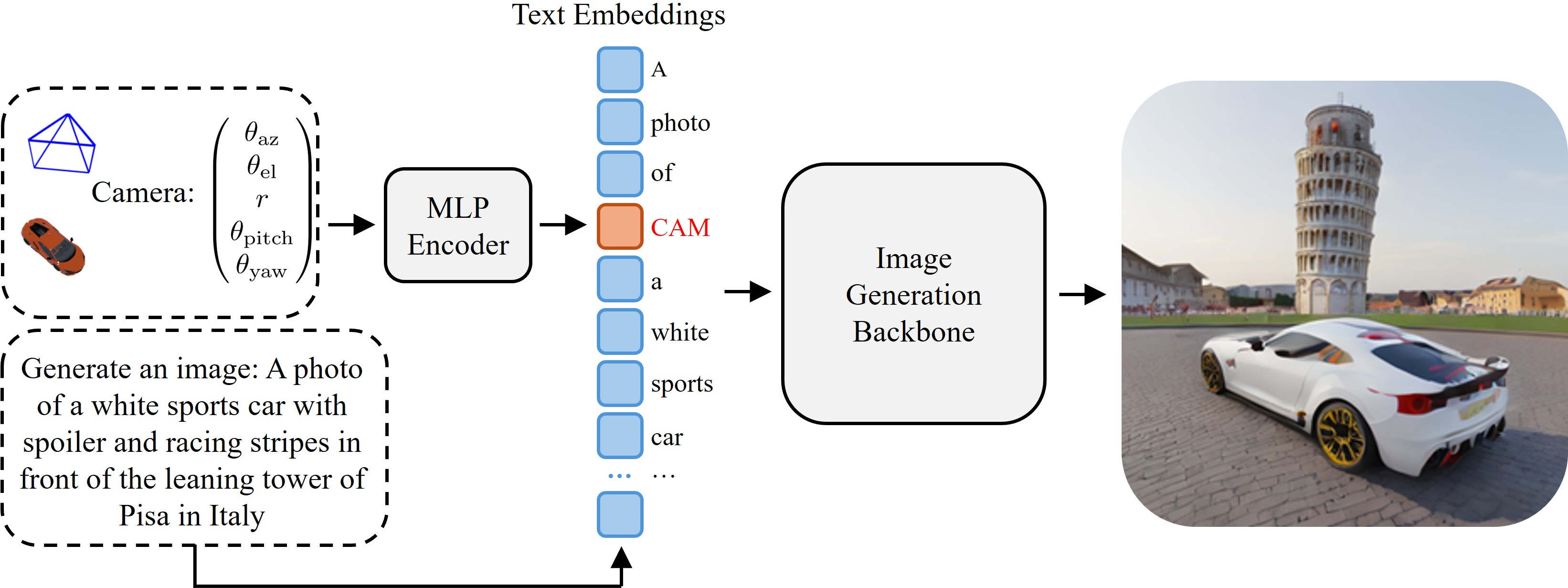
Figure 2: Architecture overview of the method, mapping camera parameters to token embeddings.
Dataset Design
The primary dataset consists of 3D-rendered images to provide geometric supervision, complemented by a smaller set of photorealistic images for appearance diversity. Rendering involves sampling varied camera viewpoints around objects from TexVerse, ensuring robust geometric representation in training. The photorealistic dataset is created using a commercial image generation system to augment rendered images, enriching the training set with realistic appearances while maintaining object poses.
Experimental Results
Quantitative evaluations demonstrate that the proposed method significantly outperforms existing models like Compass Control and Stable Virtual Camera in terms of camera pose fidelity across multiple parameters (azimuth, elevation, radius, yaw, and pitch). The ability to maintain high image quality and adherence to textual prompts is highlighted through superior CLIP similarity scores compared to baseline models.



Figure 3: Results at varying camera elevations, exhibiting precise control over perspective adjustments.
Qualitative Comparisons
The paper presents extensive qualitative comparisons showing the method’s robustness to novel categories and complex scenarios. Unlike other methods that often overfit to the training distribution or fail under challenging camera angles, the proposed approach consistently generates semantically accurate outputs even for unseen object categories.



Figure 4: Examples of failure cases in competing methods, highlighting misalignments not present in the proposed framework.
Discussion
The research shows how integrating explicit 3D camera structures into text-to-image generation models can significantly improve viewpoint control. It challenges the existing reliance on implicit language descriptions for geometric tasks, opening new avenues for developing geometrically aware prompts. The method’s compatibility with various T2I backbones further underscores its versatility and potential for widespread application in tasks requiring precise spatial manipulation.
Conclusion
This study introduces an innovative approach to enhancing camera control in text-to-image generation by learning viewpoint tokens, achieving state-of-the-art viewpoint accuracy while preserving high visual fidelity. This framework not only enhances geometric understanding but also demonstrates scalability across different generative backbones. Such advancements signify a step towards more flexible and reliable text-to-image models that respond accurately to detailed viewpoint specifications, presenting substantial implications for future research in photorealistic image synthesis and 3D-aware text-to-image applications.

