- The paper presents a diffusion-based framework that tokenizes lighting attributes for precise image relighting without requiring explicit 3D inverse rendering.
- It leverages a large-scale synthetic dataset to enforce physically consistent control over ambient, diffuse, and point light effects in varied scenes.
- Experiments show significant improvements in relighting metrics (e.g., PSNR, SSIM) and user preference compared to environment map-based methods.
TokenLight: Diffusion-Based Precise Lighting Control via Attribute Tokens
Introduction
TokenLight is presented as a framework for highly controlled image relighting, introducing a compact, tokenized factorization of lighting parameters for 2D images. Unlike prior paradigms relying on environment maps, global text prompts, or explicit 3D inverse-rendering decomposition, TokenLight directly encodes physically meaningful illumination attributes as tokens—specifically, per-light intensity, color, diffuseness, and 3D position—enabling precise and intuitive controllability. Relighting is learned as conditional generation via a large-scale, synthetically annotated dataset, with the objective of directly mapping scene appearance and desired lighting deltas to plausible, physically consistent relit outputs. This approach circumvents conventional inverse rendering, instead relying on the generative capacity of diffusion transformers pre-trained on large-scale text-conditioned image/video corpora and fine-tuned for lighting manipulation tasks.
Data Generation, Lighting Controls, and Scene Parameterization
TokenLight’s effectiveness is predicated on a deeply supervised, large-scale synthetic dataset where controllable per-light edits are available as ground truth. 3D scenes are rendered with varied combinations of:
- Ambient scale (global environment intensity modulation),
- Diffuse spread (controlling shadow softness),
- Point light insertion (location, color, intensity, radius/diffuseness), and
- In-scene fixture masking (segmentation and continuous per-light edits).
This approach leverages path-traced renders and procedurally generated assets to ensure coverage of challenging geometric and photometric effects needed for robust generalization. Lighting parameters are encoded in a canonical, scene-agnostic coordinate system; the parameterization remains invariant under similarity transformations, guaranteeing that user controls in image space have predictable geometric interpretation regardless of 3D scene composition. Figure 1 illustrates diverse editing controls and data supervision strategy.
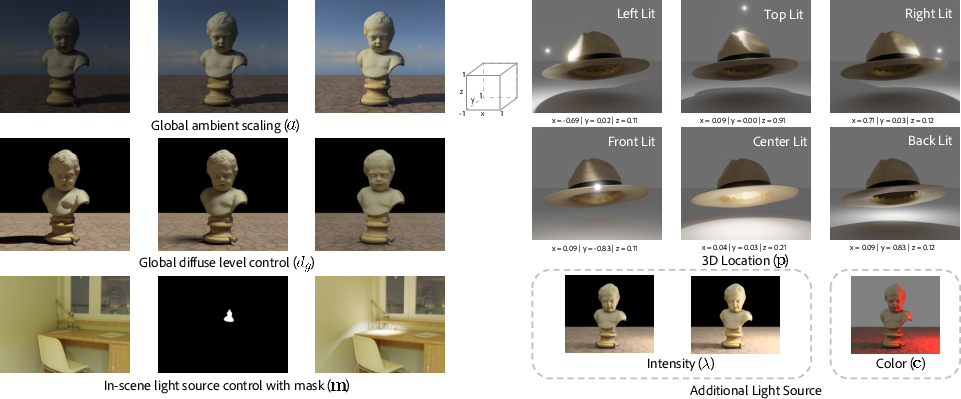
Figure 1: Data construction showing granular, supervised control over per-light renders, ambient intensity, diffuse spread, and in-scene light fixture masking.
The viewpoint-agnostic camera/light parameter mapping is formalized with explicit scene transformations (scale, translation, rotation). Figure 2 conveys the unification of camera and light attributes in canonical space and the equivalence of visual effects under arbitrary placement.

Figure 2: Scene-agnostic camera and lighting parameterization via canonical reference transformation, ensuring consistent visual effects irrespective of scene geometry or layout.
Methodology and Model Architecture
Image relighting in TokenLight is structured as a conditional generation problem: Ir∼pθ(⋅∣I,ΔL)
where I is the input image and ΔL is a set of attribute tokens encoding the desired illumination adjustment. Scalar attributes are Fourier embedded, spatial attributes tokenized per component, and light masks VA-encoded to yield a unified conditioning sequence. This sequence is processed in tandem with latent image tokens using a transformer-based diffusion backbone (see Figure 3).
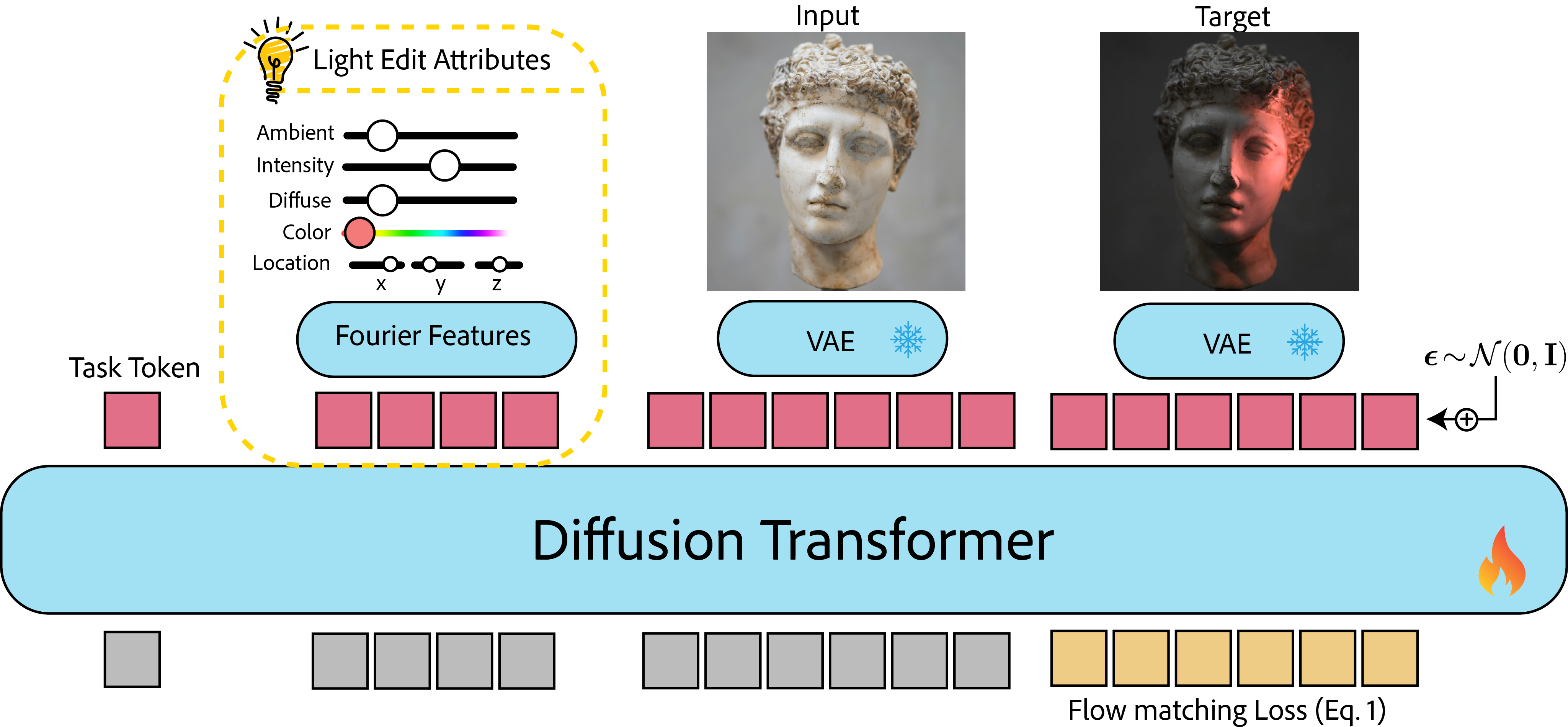
Figure 3: Architecture overview; image tokens and lighting tokens jointly inform the denoising transformer for edit-aware generation.
The conditional diffusion model is trained with a flow-matching objective, optimizing straight-line velocity prediction between Gaussian noise and target image latent, guided by paired lighting-attribute deltas. Importantly, no explicit geometry/material estimation is performed; generalization arises purely from structured data coverage and the semantic content of the tokenized attributes.
Spatial Lighting Control and Quantitative Evaluation
TokenLight establishes a new standard on synthetic and real benchmarks targeting precise spatially localized lighting edits. Key experimental findings include:
- On synthetic object relighting benchmarks, TokenLight achieves significantly higher PSNR and SSIM, and lower LPIPS compared to environment map–based alternatives such as Neural Gaffer and DiffusionRenderer (e.g., 21.98 PSNR vs. 16.76).
- Sensitivity/accuracy analysis (via confusion matrix) demonstrates the model’s high spatial disentanglement: B/A substantially outperforms Neural Gaffer (1.88 vs. 1.11), indicating robust positional awareness (see Figure 4).

Figure 5: Quantitative comparison on synthetic data, confirming superior spatial relighting accuracy relative to environment map–based methods.

Figure 4: Light-position trajectory and confusion analysis, showing TokenLight's superior localization precision and minimal positional confusion.
- User preference studies indicate strong perceptual superiority, with 77.5%–89.2% favoring TokenLight over state-of-the-art baselines across a diverse set of edits.
Real-World Fixture Control and Visible Fixture-60
TokenLight’s framework extends to in-scene relighting of real images, leveraging ground-truth paired captures with controlled fixture on/off states and explicit mask annotations.
Qualitative Comparisons and In-the-Wild Control
Systematic visual comparisons against GenLit and Careaga et al. highlight TokenLight's robustness and semantic coherence:
- Unlike GenLit, which exhibits spatial drift and scene-camera entanglement, TokenLight's scene-agnostic parameterization provides stable lighting control across perspectives (see Figure 7).
- The method handles challenging materials (transparency, hair, fur, specularity) with plausible physicality unattainable by two-stage or direct-intrinsic baselines (see Figures 7, 12).



Figure 8: Continuous spatial relighting and complex in-the-wild control: TokenLight synthesizes expected occlusion, shadowing, and volumetric effects via simple 3D token edits.

Figure 7: TokenLight maintains stable top-light placement and consistent shadow orientation across different scene poses—unlike GenLit.
Advanced Lighting Controls: Diffuse, Ambient, and Multi-Light
TokenLight supports global ambient scaling and fine-grained diffuse level manipulation:
- Progressive reduction of ambient illumination cleanly separates masked source effects from global illumination (Figure 9).
- Diffuse control enables both softening and sharpening of shadows (Figures 17 and 18).
- Multi-light control is structured via repeated attribute tokens allowing independent sweeps and color mixing, supporting complex photographic lighting setups without explicit 3D scene recovery (Figure 10).

Figure 9: Continuous ambient scaling demonstrating separation between fixture reflections and global illumination in image space.

Figure 11: Increasing diffuse levels create softer shadows via global ambient-light diffusion control.

Figure 12: Negative diffuse control yields progressively sharper shadows, reversing diffuse softening as needed.


Figure 10: Multi-light, multi-trajectory control: Each light's movement produces predictable, disentangled lighting in a single inference pass.
Limitations and Future Directions
TokenLight inherits the limitations of computational scaling, requiring substantial resources for real-time or long-horizon video relighting; future work may incorporate model distillation and video-aware conditioning [(2604.15310), dmd2, consistency_models]. Stochastic seed variability results in subtle, but non-deterministic, shadow placement at extreme diffuse levels. Generalization to outdoor scenes is reduced due to an indoor-biased training corpus. Extension to spatiotemporal (video) relighting is non-trivial, opening questions regarding canonical coordinate persistence, camera/object tracking, and frame-consistent editing.
Conclusion
TokenLight demonstrates that attribute tokenization—when grounded in physically interpretable lighting parameters and supported by comprehensive synthetic supervision—enables precise, continuous, and semantically meaningful image relighting not previously achievable without explicit 3D scene analysis. The disentangled design offers a path to more accessible, granular lighting control in 2D image editing workflows, bridging the functional gap between interactive 3D DCCs and photorealistic single-image manipulation. Future research avenues include model acceleration, robust outdoor generalization, and scalable video relighting via temporally persistent canonical parameterizations.
Reference: "TokenLight: Precise Lighting Control in Images using Attribute Tokens" (2604.15310).
