- The paper introduces a model that transfers spatial reasoning to predict plausible camera trajectories by integrating vision, language, and camera modules.
- It employs a diffusion-based transformer with wavelet-based regularization to generate smooth, semantically aligned camera paths.
- CT-1 achieves significant improvements in control fidelity and video quality, advancing intent-aligned, camera-controllable video synthesis.
CT-1: Vision-Language-Camera Models for Spatial Reasoning in Camera-Controllable Video Generation
Problem Motivation and Technical Context
Camera-controllable video generation with explicit and semantic-level control over camera motion is a critical capability for both practical production pipelines and embodied world models. Previous approaches have bifurcated into direct trajectory parameter conditioning—requiring, but seldom receiving, precisely curated camera motion parameters—or vague natural language controls that provide minimal guarantees that generated video conforms to the specified camera operation. This breaks down in scenarios demanding semantic and geometric alignment with user intent, scene content, and complex real-world environments.
CT-1 introduces a new instantiation: Vision-Language-Camera (VLC) models, realizing a system that can transfer spatial reasoning knowledge from multimodal instructions to physically and semantically valid camera trajectories for video generation. The framework directly addresses the core issues of annotation bottlenecks in trajectory design and the inferential gap between semantic intent and low-level scene-specific motion planning.
Architecture and Methodology
Model Framework
The CT-1 framework integrates three principal modules: vision-language semantic embedding, a diffusion-based transformer for trajectory modeling, and downstream controllable video generators.
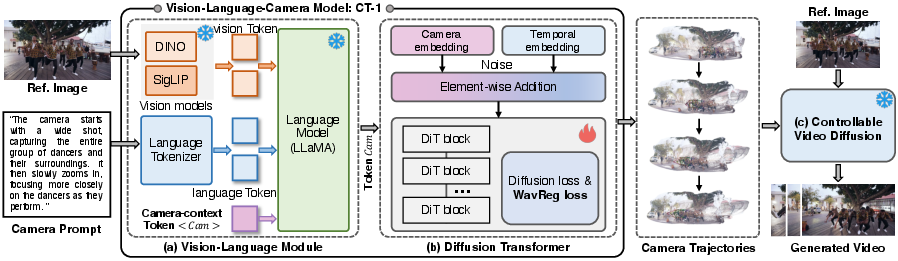
Figure 2: The CT-1 framework: (a) Vision-language embedding extracts multimodal scene and intent cues, (b) a DiT-based module models trajectory distributions, and (c) video generation is conditioned on predicted camera trajectories.
The visual backbone employs a dual-encoder pipeline (DINOv2 and SigLIP) to capture local and global scene representations. Language understanding is built on LLaMA-2, and the coupled system fuses image features, textual prompt tokens, and a learnable camera-context token (<CAM>) as a unified input sequence. Cross-modal integration utilizes causal attention, yielding a compact global representation, ftcam, that informs trajectory generation.
The core CT-1 module is a diffusion transformer (DiT) trained to model the conditional distribution over temporally coherent camera trajectories on SE(3). Instead of deterministic prediction, the trajectory output is explicitly distributional, inferring plausible camera motions that are scene-aware and semantically aligned. Conditioning is implemented by prepending the fused <CAM> and timestep embeddings, enabling explicit propagation of scene and intent knowledge into all temporal steps.
A key innovation is the introduction of Wavelet-based Regularization Loss (WavReg). Wavelet analysis on empirical data reveals that camera motion signals are dominated by structured, low-frequency components encoding physically plausible, smooth motion, while high frequencies represent undesirable jitter or erratic behavior. The WavReg loss decomposes trajectories via a multi-level discrete Haar transform, assigning heavy penalties to errors at low-frequency scales and lighter penalties to higher frequencies, directly reflecting the perceptual and physical properties of realistic camera dynamics. The overall CT-1 loss combines diffusion objectives with frequency-aware regularization.
Dataset: CT-200K Pipeline
To enable high-fidelity learning, CT-1 is trained on CT-200K—a large-scale, curated dataset (47M frames) with fine-grained camera trajectories paired with multimodal annotations. Automated annotation leverages state-of-the-art vision-LLMs (VLMs), LLMs for semantic filtering, and the VGGT model for 3D pose estimation. The data curation pipeline systematically filters static/noisy videos and synthesizes diverse general and reasoning (egocentric, action-driven) scenarios, rigorously reviewed by annotators for scene/intent diversity.

Figure 1: CT-200 dataset examples post-curation, displaying paired video frames and camera motion prompts.
Quantitative Evaluation and Comparative Results
Performance is primarily evaluated on CameraBench100 (six canonical camera motions in diverse environments) using a success rate metric assessed by dual human experts, focusing on semantic and physical alignment with trajectory descriptions.
CT-1 exhibits 81.6% camera control accuracy, representing a substantial 25.7% improvement over the best baseline (Wan2.2 w/ Prompt Extension), and 171% or greater improvement over previous VLM-based trajectory systems. In OOD (out-of-distribution) and complex motion scenarios, the method consistently outperforms all other models, reflecting robust generalization and semantic controllability.

Figure 5: CT-1 achieves superior semantic and physical alignment in OOD scenarios compared with CogVideoX and related methods.
Video quality is on par or slightly superior, with VBench results showing CT-1 bests baselines on imaging quality (0.709), motion smoothness (0.990), and dynamic degree (0.830).
Trajectory Analysis and Model Behavior
Trajectory visualizations demonstrate that CT-1 reliably infers geometrically valid and semantically nuanced 3D camera paths, remaining robust under both short and extended text prompts. The model flexibly adapts to both variable reference images and text conditions, reflecting learned disentanglement of scene geometry and motion semantics.

Figure 7: Example camera trajectories predicted by CT-1, aligned with semantic motion descriptions and scene geometry.

Figure 4: CT-1 preserves smoothness and intent consistency under longer, more complex language instructions.
Further, application of the same motion prompt to varied reference images produces scene-adaptive trajectories, and distinct prompts on a shared image yield semantically differentiated paths.
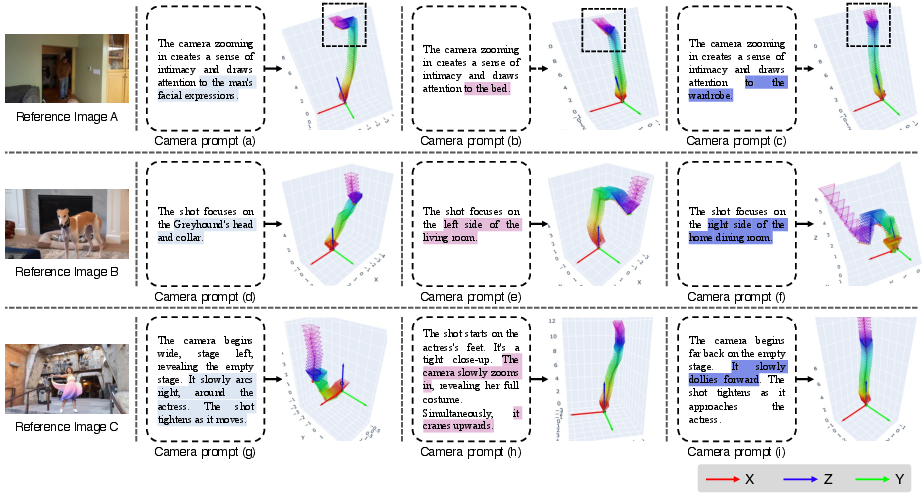
Figure 6: Fixed scene with varying prompts—CT-1 generates diverse but contextually consistent trajectories.
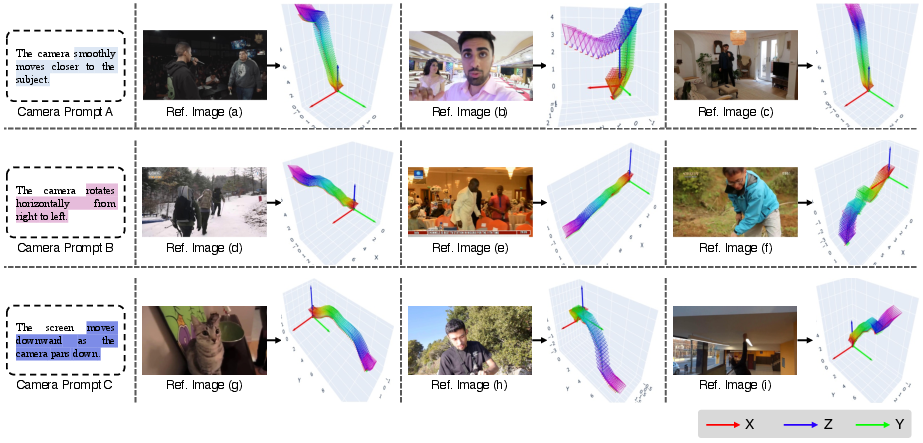
Figure 8: Fixed prompt and varied reference images yield trajectory adaptation to scene structure.
Downstream Video Generation and Modular Integration
CT-1-inferred trajectories can be seamlessly applied as conditioning signals to a range of camera-controllable video generators, including CameraNoise, CameraCtrl, and MotionCtrl, resulting in substantially improved control fidelity and motion naturalness compared with native or text-only conditioning protocols.
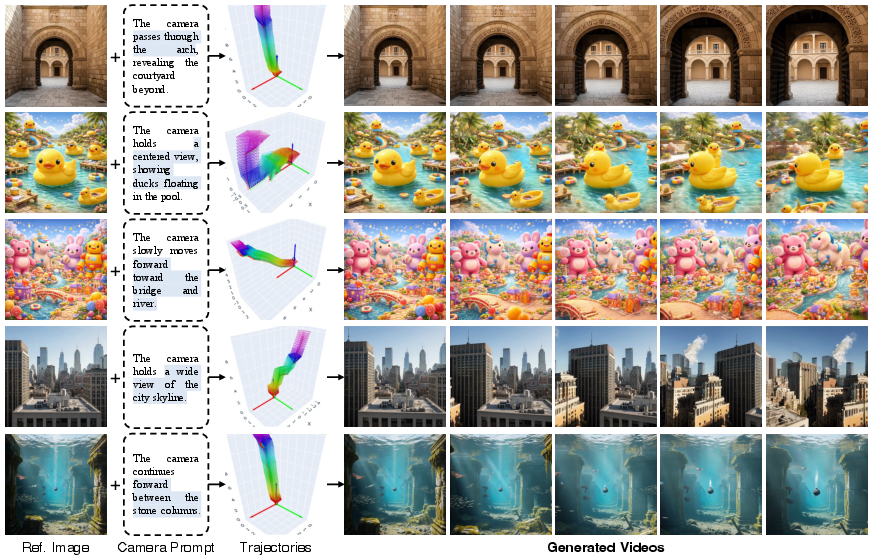
Figure 9: Qualitative video generation: CT-1 trajectories drive camera-consistent synthesis aligned with semantic input.
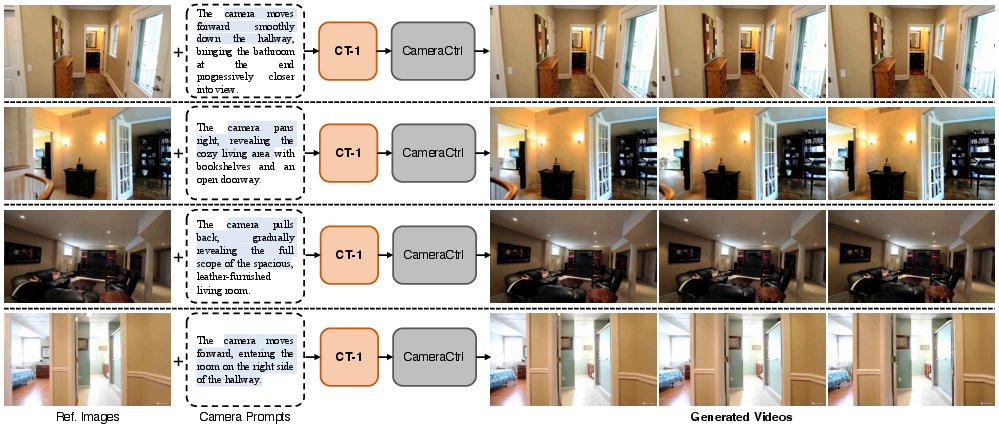
Figure 10: Integration of CT-1 trajectories with CameraCtrl; robust scene-adaptation observed on RealEstate10K.
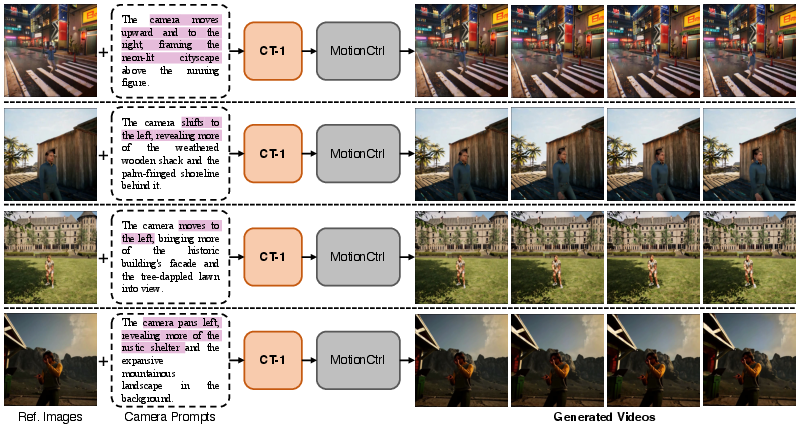
Figure 11: MotionCtrl results with CT-1 guidance display improved spatiotemporal coherence and intent matching.

Figure 12: Driving scenario: CT-1 enables physically realistic, prompt-aligned camera motion in knowledge-rich driving scenes.
Ablations and Analytical Insights
Model scaling positively correlates with control accuracy; the 458M-parameter CT-1 model achieves state-of-the-art results, confirming the architectural scalability of DiT-based VLCs.
WavReg ablations empirically validate the necessity of frequency-aware supervision; simple velocity or acceleration regularizers are inferior, and the balancing coefficient β is crucial—optimal values sharply increase both visual quality and success rate.
Multi-instance cross-validation demonstrates distributional modeling: CT-1 maintains discriminable and stable trajectories under repeated sampling, reflecting robust generalization and nontrivial diversity.
Camera-context token ablation establishes that neither text nor image alone, nor generic pooling, provides the same level of spatial-semantic control; explicit <CAM> conditioning is essential for cross-modal grounding of intent and scene structure.
Implications and Future Directions
CT-1’s introduction of distributional, spatially grounded camera trajectory modeling in a controllable generation pipeline sets a new technical foundation for scalable, intent-aligned, physically plausible video synthesis. The modular design supports direct integration with a broad class of diffusion video generators and accommodates plug-and-play improvements in both VLM/LLM backbones and downstream synthesis strategies.
Practically, this approach enables high-level, natural-control video editing, content creation, virtual cinematography, and embodied simulation, minimizing the need for manual trajectory design or post-hoc adjustment. Theoretically, the demonstrated importance of frequency-domain and explicit scene-intent disentanglement will inform the design of future VL architectures, world models, and multimodal planners. The CT-200K dataset provides further opportunities for benchmarking cross-modal spatial reasoning and extends the scope of intent-conditioned scene modeling across domains.
Given the non-uniqueness of physically valid camera motions, downstream research will likely explore learning multimodal trajectory distributions, reinforcement and active feedback from viewers (human-in-the-loop), and extending VLC paradigms to non-visual sensors and dynamic world models.
Conclusion
CT-1 establishes a new state-of-the-art in aligning visual content, user intent, and physically plausible camera control for video generation. By integrating vision-language modeling, diffusion-based distributional trajectory inference, and frequency-aware regularization, CT-1 bridges semantic reasoning and explicit scene embedding, producing compelling improvements in both control fidelity and downstream video synthesis. The methodology and CT-200K resource together mark a significant advance in spatially controllable, intent-aligned video generation systems.
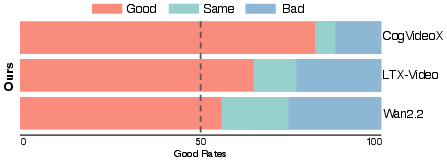
Figure 13: User study: Preference surveys indicate consistent human favorability for CT-1 in visual quality, motion fidelity, and camera controllability.