Thinking with Camera: A Unified Multimodal Model for Camera-Centric Understanding and Generation
Abstract: Camera-centric understanding and generation are two cornerstones of spatial intelligence, yet they are typically studied in isolation. We present Puffin, a unified camera-centric multimodal model that extends spatial awareness along the camera dimension. Puffin integrates language regression and diffusion-based generation to interpret and create scenes from arbitrary viewpoints. To bridge the modality gap between cameras and vision-language, we introduce a novel paradigm that treats camera as language, enabling thinking with camera. This guides the model to align spatially grounded visual cues with photographic terminology while reasoning across geometric context. Puffin is trained on Puffin-4M, a large-scale dataset of 4 million vision-language-camera triplets. We incorporate both global camera parameters and pixel-wise camera maps, yielding flexible and reliable spatial generation. Experiments demonstrate Puffin superior performance over specialized models for camera-centric generation and understanding. With instruction tuning, Puffin generalizes to diverse cross-view tasks such as spatial imagination, world exploration, and photography guidance. We will release the code, models, dataset pipeline, and benchmark to advance multimodal spatial intelligence research.























Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Thinking with Camera: A Simple Explanation
Overview
This paper introduces Puffin, a smart computer system that understands and creates images by focusing on the camera itself. Instead of just recognizing what’s in a picture, Puffin learns how the camera was tilted, how wide it was zoomed, and where it was pointing. It can also generate new images that match specific camera settings (like “tilt down” or “35mm lens”). The big idea is to “think with the camera” by turning technical camera numbers into everyday photography words, so the model can reason about space more naturally.
Key Questions the Paper Tries to Answer
- How can a computer figure out a camera’s settings (like angle and zoom) just from an image?
- How can we create new images that match the exact camera angle and lens we want?
- Can we turn camera numbers into simple photography terms so the model can reason better?
- Is it possible to build one unified system that does both understanding and generation well?
How Puffin Works (in everyday language)
Think of Puffin as three parts working together:
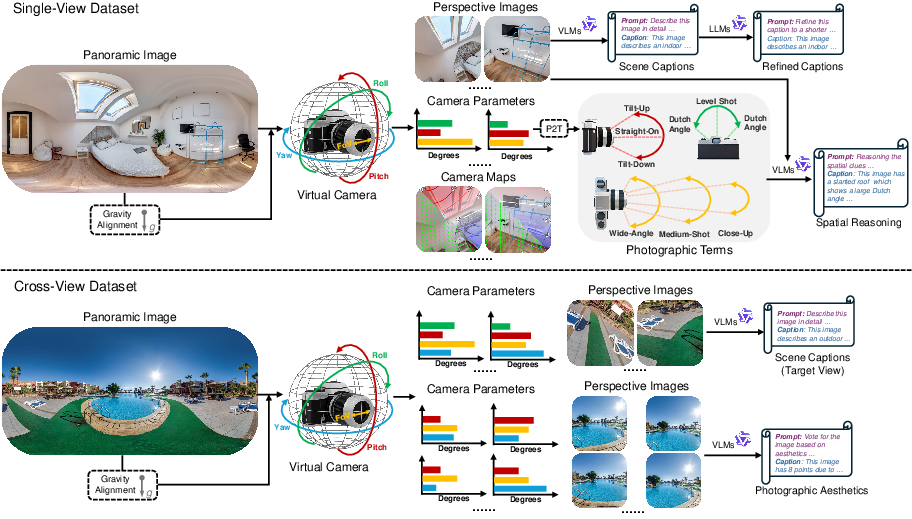
- The “eyes”: a special vision encoder that pays attention not just to objects, but also to geometry—things like horizon lines, verticals (walls), and how sizes change with distance.
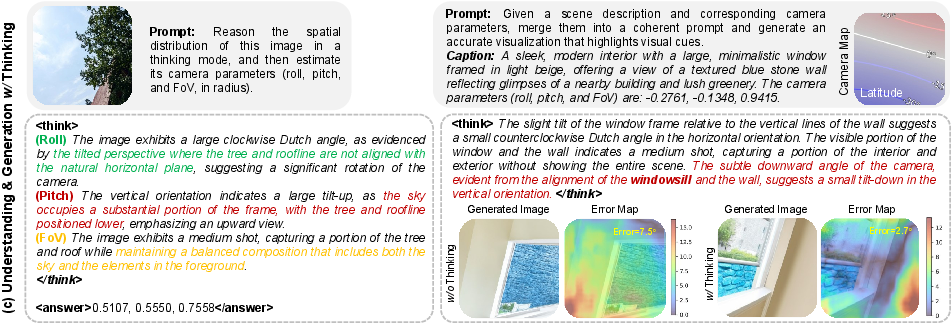
- The “brain”: a LLM that explains and reasons in words. It learns to talk about cameras using photography terms such as “close-up,” “tilt-up,” “Dutch angle,” and “wide angle.”
- The “artist”: a diffusion model that “paints” images step by step, following instructions from the brain to produce pictures that match the requested camera settings.
Two camera ideas are important and are explained in simple terms:
- Roll: how much the camera is rotated left or right (like tilting your phone clockwise or counterclockwise).
- Pitch: how much the camera looks up or down.
- Yaw: turning left or right around you (like spinning in place).
- FoV (Field of View): how wide the camera sees (wide-angle shows more; narrow shows less).
To make generation precise, Puffin uses:
- Camera tokens: the camera’s key numbers turned into “words” the brain can understand.
- Pixel-wise camera maps: a detailed “overlay” for every pixel that tells the artist how each part of the image should be oriented. You can imagine it like a fine-grained guide that says, “this corner points up a bit; that area is farther away,” helping the artist keep the picture consistent.
The core idea—“thinking with camera”—means:
- Translating exact numbers (like “pitch = 15°”) into photography terms (“small tilt-down”).
- Using spatial clues found in the image (sky, floor, walls, horizon, object sizes) to reason about the camera.
- Keeping this same chain of thought for both understanding and generation, so the model stays consistent.
Training and data:
- Puffin-4M: a huge dataset of 4 million examples, each with an image, a caption, and the camera settings used to create it. Many images are made from panoramic photos by “cropping” different views with chosen roll, pitch, yaw, and FoV, then adding detailed captions and spatial reasoning.
- Training happens in stages: align the parts, fine-tune, add “thinking with camera,” and then instruction-tune for extra tasks (like imagining other viewpoints or giving photography advice).
Main Findings and Why They Matter
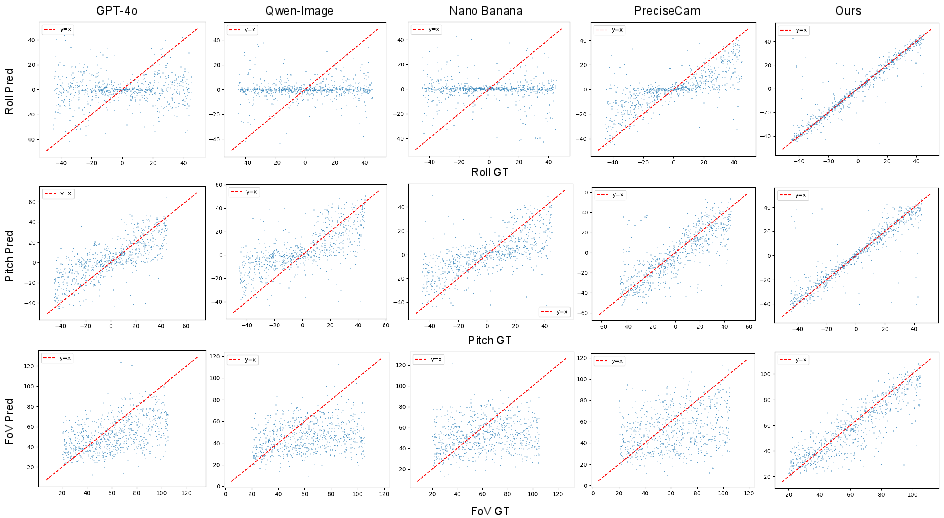
- More accurate camera understanding: Puffin estimates roll, pitch, and FoV more precisely than specialized models on multiple test sets. In simple terms, it’s better at telling how a camera was held and how wide it was zoomed.
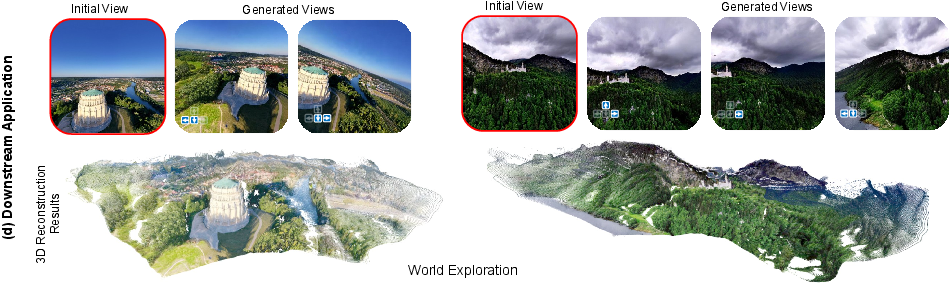
- Better camera-controlled image generation: When you ask for a specific camera setup, Puffin’s images match it more faithfully. The pixel-wise camera maps give the artist fine control, so layouts, horizon, and perspective look right.
- Generalizes to new tasks with instructions:
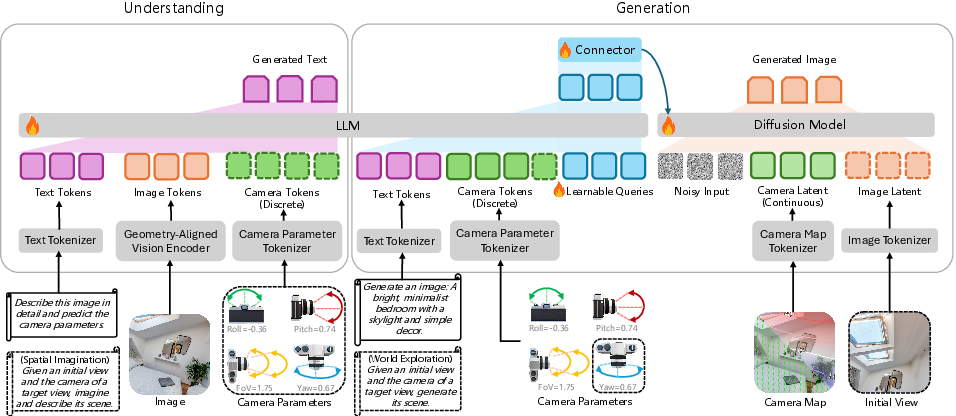
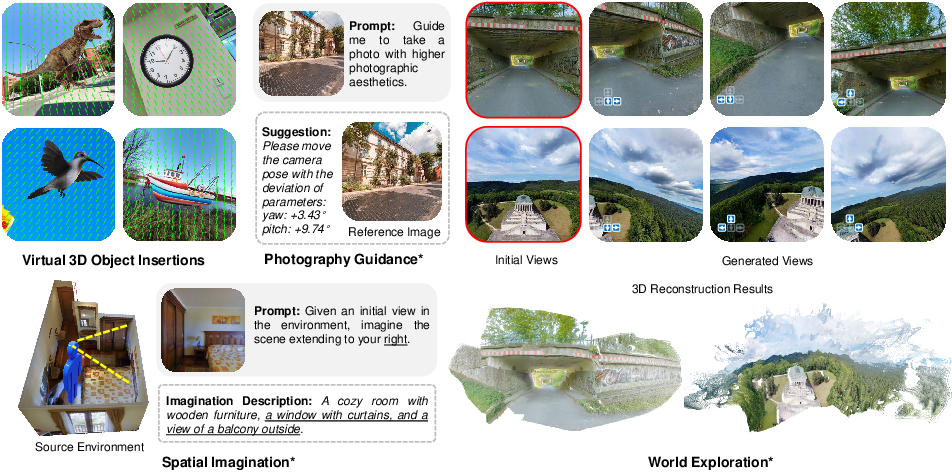
- Spatial imagination: Given one view and target camera settings, Puffin describes or predicts what another view would look like.
- World exploration: It generates images from new viewpoints, helping you “look around” a scene.
- Photography guidance: It suggests camera adjustments (like small tilt or turning angle) to improve the aesthetics of a photo.
Overall, Puffin unifies understanding and generation and does both better than previous single-purpose systems.
Implications and Impact
- More natural controls: Photographers and creators can use everyday terms (“tilt-up,” “close-up,” “wide angle”) instead of raw numbers and still get precise results.
- Stronger spatial intelligence: Robots, AR/VR apps, and autonomous systems can better understand scenes and simulate views from different angles, improving navigation and interaction.
- Creative tools: Artists, game developers, and filmmakers get a powerful way to imagine and render scenes from any viewpoint with realistic perspective.
- Research boost: The team plans to release the code, models, data pipeline, and benchmarks, making it easier for others to build on this work.
In short, Puffin treats the camera like a language the computer can speak and reason about, bringing together the “why” of text with the “where” of geometry to understand and create images more reliably.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future research.
- Camera model coverage is limited to an ideal pinhole with roll, pitch, and vertical FoV; radial/distortion parameters, principal point/skew, rolling shutter, sensor size, and non-linear optics are not modeled or evaluated.
- Single-view understanding does not estimate yaw; downstream tasks that need global heading or azimuthal alignment (e.g., navigation, AR alignment with compass/IMU/GPS) remain unsupported.
- The training ranges for roll and pitch ([-45°, 45°]) and FoV ([20°, 105°]) exclude extreme and common real-world regimes (e.g., fisheye >120°, ultra-telephoto <20°, rotations beyond 45°); generalization to out-of-range settings is untested.
- Photographic-term discretization (parameter-to-term mapping) may lose precision; the mapping thresholds, invertibility back to numeric ranges, and their effect on accuracy/control fidelity are not analyzed.
- The “thinking with camera” chain-of-thought is LLM-generated, but there is no assessment of its factual reliability, robustness to hallucinations, or causal contribution to accuracy (e.g., ablations measuring performance without thinking, or with corrupted reasoning).
- No uncertainty estimates or calibration are provided for predicted camera parameters; downstream consumers cannot gauge prediction confidence or reliability.
- Camera-controllable generation lacks rigorous, standardized geometric faithfulness metrics (e.g., horizon deviation error vs. target pitch/roll, vanishing-point alignment error, projective consistency); evaluation appears primarily qualitative.
- Multi-view geometric consistency of generated images (e.g., epipolar/triangulation consistency across views, 3D reconstruction quality from generated views) is not quantitatively evaluated.
- Cross-view training data is built from panorama rotations (pure rotations around a fixed center); translational motion/parallax is absent, limiting realism for AR/VR and robotics and potentially harming multi-view consistency.
- Domain realism gap: most controllable-generation supervision comes from synthetic perspective crops of panoramas; generalization to native single-shot photographs with real optics and in-camera processing is unquantified.
- The panorama preprocessing and gravity alignment may introduce residual geometric errors; impacts on label noise and the robustness of learned geometry are not measured.
- The camera map (Perspective Field) is encoded with the image VAE; a specialized tokenizer/autoencoder for geometry signals is acknowledged as future work but not explored or compared.
- Sensitivity analyses are missing for key architectural choices (e.g., number of learnable queries, connector design, choice of geometry-aligned vision encoder, contribution of each teacher in distillation).
- Model scale vs. performance trade-offs are unexplored (e.g., varying LLM sizes beyond 1.5B, encoder/diffusion scales); no scaling laws or compute–accuracy curves are provided.
- Inference speed, memory footprint, and deployability constraints (e.g., on-device/real-time for robotics) are not reported; techniques for acceleration or distillation are not investigated.
- Robustness to adverse conditions (night scenes, severe weather, HDR/low light, motion blur, textureless scenes, water/underwater scenes, non-planar horizons like hills) is not systematically evaluated.
- Additional camera controls central to photography (aperture/ISO/shutter, focus distance/depth-of-field/bokeh, lens vignetting) are not modeled or controllable in generation; interactions with geometry remain unexplored.
- The photographic guidance task uses LLM-voted aesthetic labels without human rater validation; the reliability, bias, and correlation with human judgments are unknown.
- Multilinguality and cross-cultural coverage of photographic terminology (and their mappings to numerical parameters) are not considered; performance outside English remains untested.
- The approach depends on parameter inputs and pixel-wise camera maps for fine control; how precisely user-only textual instructions (e.g., “close-up Dutch angle”) map to numeric parameters and spatial priors is not quantified.
- Failure modes and safety risks (e.g., confident but wrong camera estimates, misleading geometry in generated images used for measurement or planning) are not identified or mitigated.
- Data composition and bias (indoor vs. outdoor balance, city/country distribution, architectural styles, scene categories like people/vehicles/nature) are not audited; cross-domain generalization is unreported.
- Integration with SLAM/VO pipelines is not studied: do Puffin’s single-image camera estimates improve multi-view tracking, and how do errors propagate to localization and mapping performance?
- The paper shows 3D reconstruction “from initial and generated views” but does not provide quantitative comparisons against real multi-view captures or report degradation due to generative artifacts.
- Licensing and reproducibility risks exist for Google Street View and web-scraped panoramas; exact data lists, re-download scripts, or legal constraints for dataset reconstruction are not detailed.
Practical Applications
Immediate Applications
Below is a concise set of actionable, real-world uses that can be deployed with the capabilities described (camera understanding, camera-controllable generation, and instruction-tuned extensions). Each item includes sector tags, potential tools/workflows, and feasibility notes.
- Single-image camera calibration and horizon visualization
- Sectors: robotics, AR/VR, autonomous driving, surveying
- Tool/workflow: “Camera-Calib API” that estimates roll, pitch, FoV from an image; “Horizon Visualizer” overlay for capture and post-production
- How it helps: Improves SLAM/SfM initialization, stabilizes navigation and AR anchoring, reduces calibration overhead for heterogeneous cameras
- Assumptions/dependencies: Works best with pinhole-like imaging; domain shift matters (indoor/outdoor/weather); accuracy depends on image quality and scene structure
- Camera-controllable image generation for previsualization and creative workflows
- Sectors: media/advertising, film/TV, game development, digital marketing
- Tool/workflow: “View-Controlled Diffusion” plugin that takes camera tokens and camera maps (FoV, roll, pitch, pixel-wise maps) to produce previews at specified viewpoints; storyboard and shot design
- How it helps: Rapid shot prototyping with explicit spatial control aligned to photographic terms (e.g., tilt-up, Dutch angle)
- Assumptions/dependencies: Requires integration with SD3-like diffusion; realism and spatial fidelity depend on camera maps and prompt quality
- Photography guidance and shot refinement
- Sectors: consumer mobile, professional photography, creator tools
- Tool/workflow: “Smart Horizon Assistant” that suggests small pitch/yaw adjustments to improve aesthetics; live guidance during capture
- How it helps: Real-time hints for more level shots and improved composition; supports novices with professional terminology
- Assumptions/dependencies: Latency and on-device inference constraints; initial release may fix roll at 0° for aesthetic stability
- 3D reconstruction pipeline enhancement (SfM/SLAM bootstrapping)
- Sectors: AR/VR, mapping, surveying, digital twins
- Tool/workflow: “Puffin-to-COLMAP” plugin using estimated intrinsics/extrinsics and horizon cues as priors
- How it helps: Reduces failure modes in feature-sparse scenes (ceilings, sky, ground); improves convergence and scale consistency
- Assumptions/dependencies: Benefits greatest in texture-poor settings; downstream pipeline must consume external camera priors
- Synthetic data augmentation with consistent camera metadata
- Sectors: software/ML, autonomy, robotics
- Tool/workflow: “Camera-Aware Augmenter” that generates images and accurate camera labels for training perception models (depth/pose/geometry)
- How it helps: Scales training sets with controllable viewpoint diversity; reduces manual labeling costs
- Assumptions/dependencies: Label fidelity tied to Puffin’s camera control accuracy; risk of distribution mismatch with real-world sensors
- Spatial imagination for vantage planning (text-only description of alternate views)
- Sectors: robotics, field operations, remote inspection
- Tool/workflow: “View Planner” that, given current view + target camera parameters, produces descriptions of expected scene contents
- How it helps: Supports exploration decisions where physical repositioning is costly; aids mission planning
- Assumptions/dependencies: Hallucination risk; requires basic geometric priors and domain-aligned captions
- Dataset metadata auditing and camera consistency checks
- Sectors: academia, data curation, forensics
- Tool/workflow: “Perspective Consistency Checker” to validate or infer missing camera metadata and flag inconsistencies
- How it helps: Improves dataset reliability for geometry tasks; supports integrity checks in forensics
- Assumptions/dependencies: Confidence calibration needed; may be less reliable for heavily post-processed imagery
- Education and training in photographic composition and camera semantics
- Sectors: education, creator economy
- Tool/workflow: “Camera Thinking Tutor” that explains shots in professional terms (e.g., close-up, tilt-down) and links them to camera parameters
- How it helps: Bridges numerical parameters to practice; accelerates skill acquisition
- Assumptions/dependencies: Requires curated examples; benefits from bilingual/locale support and domain-specific curricula
Long-Term Applications
The following opportunities require additional research, scaling, integration, or validation (e.g., handling radial distortion, multi-sensor domains, real-time constraints, and broader safety/ethics).
- Cross-view “world exploration” and single-shot scene expansion
- Sectors: robotics, real estate, construction, digital twins
- Tool/workflow: “Single-shot Scene Explorer” that predicts/generates plausible target views (including yaw) from a single starting view
- Why it’s long-term: Needs robust geometry-grounded priors to avoid hallucinations; requires multi-view consistency checks and safety guardrails
- Assumptions/dependencies: Accurate camera maps, robust domain generalization; policy constraints around synthetic reconstructions of private spaces
- Embodied agents with camera-as-language reasoning
- Sectors: robotics, drones, autonomous systems
- Tool/workflow: “CamLang Policy Module” integrating Puffin’s chain-of-thought into camera control and path planning
- Why it’s long-term: Must run efficiently on edge hardware; needs tight coupling with control stacks and safety certification
- Assumptions/dependencies: Real-time inference, failure-aware planning, regulatory compliance for autonomous operation
- AR viewpoint optimization and assistive overlays
- Sectors: AR glasses, navigation, tourism
- Tool/workflow: “Viewpoint Optimizer” that proposes next-best camera poses for clearer or more informative views, with live overlays
- Why it’s long-term: Requires persistent spatial models, high-precision tracking, and low-latency camera reasoning
- Assumptions/dependencies: On-device performance; integration with SLAM and sensor fusion; user privacy and consent
- Autonomous cinematography with multi-shot planning
- Sectors: film/TV, virtual production, sports broadcasting
- Tool/workflow: “CineGPT-Puffin” that sequences shots with professional camera terms, simulates previews, and guides rigs/dollies/drones
- Why it’s long-term: Needs temporal reasoning, moving subjects, multi-camera coordination, and safety protocols
- Assumptions/dependencies: Extended datasets with dynamics; integration with motion control hardware; production-grade reliability
- Interoperable camera-language standards and APIs
- Sectors: software/platforms, device ecosystems, academia
- Tool/workflow: “CamLang Schema” and SDK for tokens/maps across tools (capture, edit, generate, reconstruct)
- Why it’s long-term: Requires community and vendor adoption, governance, and backward compatibility
- Assumptions/dependencies: Consensus on tokenization and camera map formats; cross-model interoperability
- Integration with NeRF/3DGS for geometry-aware view synthesis
- Sectors: 3D content, VR/AR, photogrammetry
- Tool/workflow: “Geometry-Aware Gen” that aligns Puffin’s camera tokens/maps with radiance field methods for consistent novel views
- Why it’s long-term: Needs consistent camera priors, multi-view training, and scalable pipelines
- Assumptions/dependencies: Accurate camera calibration under lens distortion; joint optimization across models
- Medical imaging camera calibration and guidance (e.g., endoscopy)
- Sectors: healthcare, medical devices
- Tool/workflow: “ScopePose Assistant” for perspective awareness and operator guidance
- Why it’s long-term: Domain adaptation to specialized optics and safety-critical environments; clinical validation required
- Assumptions/dependencies: Robustness to non-pinhole optics and distortion; regulatory approval; secure data handling
- Smart city camera network planning and coverage optimization
- Sectors: public safety, infrastructure, mobility
- Tool/workflow: “Network View Planner” optimizing FoV, pitch/roll, and placement for minimal blind spots
- Why it’s long-term: Requires integration with GIS, policy frameworks, and public transparency
- Assumptions/dependencies: Accurate urban models; ethics and privacy compliance; stakeholder buy-in
- Responsible AI policy frameworks for camera-aware generative models
- Sectors: policy/regulation, platform governance
- Tool/workflow: “Responsible Camera AI Guidelines” addressing novel-view generation risks, consent, and provenance
- Why it’s long-term: Requires multi-stakeholder process, technical watermarking, and enforcement mechanisms
- Assumptions/dependencies: Standards for disclosure and provenance; dataset licensing and usage agreements; cross-jurisdiction alignment
Cross-Cutting Assumptions and Dependencies
- Camera model coverage: Current training assumes pinhole cameras; robust handling of radial distortion and non-standard optics is pending.
- Data diversity and licensing: Puffin-4M blends public datasets and Street View-like sources; deployments must respect licensing and privacy constraints.
- Compute and latency: Production use on mobile/edge requires model distillation, quantization, or efficient runtimes; training is resource-intensive.
- Safety and reliability: Hallucination risks in cross-view generation demand guardrails (confidence scoring, uncertainty estimates, provenance/watermarking).
- Domain generalization: Performance may vary with texture-less scenes, extreme lighting, motion blur, or non-Euclidean layouts; additional fine-tuning may be needed.
- Integration readiness: Many workflows depend on APIs to connect Puffin with diffusion engines (e.g., SD3), SfM/SLAM stacks (e.g., COLMAP), and capture apps.
Glossary
- Autoregressive: A modeling approach that generates sequences one token at a time, conditioning on previously generated tokens. Example: "Puffin combines autoregressive and diffusion modeling to jointly perform camera-centric understanding and generation"
- Camera calibration: The process of estimating a camera’s intrinsic and extrinsic parameters to relate 3D world coordinates to 2D image coordinates. Example: "Tasks such as camera calibration and pose estimation have long been a central topic in 3D vision"
- Camera-controllable generation: Image synthesis where camera parameters guide viewpoint and spatial layout. Example: "camera-controllable image generation"
- Camera extrinsics: Parameters describing the camera’s position and orientation relative to the world (e.g., roll, pitch, yaw). Example: "extrinsic parameters (roll and pitch)"
- Camera intrinsics: Internal camera parameters governing projection (e.g., focal length or FoV). Example: "intrinsic parameters (vertical FoV)"
- Camera map: A dense, per-pixel representation encoding local camera geometry for conditioning generation. Example: "the camera map as inputs"
- Camera rays: Rays corresponding to pixels that define the mapping from the camera center into 3D space. Example: "camera rays"
- Camera tokens: Discrete tokens derived from numerical camera parameters used as inputs to language or multimodal models. Example: "discrete camera tokens derived from numerical camera parameters"
- Chain-of-thought: An explicit reasoning process modeled in text to improve structured decision-making. Example: "We therefore adopt a shared chain-of-thought mechanism between understanding and controllable generation"
- CFG weight: The classifier-free guidance strength controlling alignment with conditioning in diffusion models. Example: "set the CFG weight as 4.5"
- Connector module: A component that maps language-model features into a form usable by a diffusion model. Example: "a connector module learns to map the hidden states of the LLM (via a set of learnable queries) into conditioning signals"
- Continuous camera latent: A continuous representation derived from camera maps that encodes fine-grained geometry for generation. Example: "we introduce continuous camera latent obtained from pixel-wise camera maps"
- Cross-view: Tasks involving relationships between different camera viewpoints of the same scene. Example: "cross-view understanding and generation"
- Diffusion model: A generative model that learns to denoise data from noise to synthesize images. Example: "guide the diffusion model"
- Diffusion transformer: A transformer-based architecture used within diffusion frameworks for generation. Example: "bridge the LLM and the diffusion transformer"
- Dutch angle: A photographic term for a tilted horizon shot (non-zero roll). Example: "professional photographic terms (e.g., close-up, tilt-up, Dutch angle)"
- Field of view (FoV): The angular extent of the scene captured by the camera. Example: "vertical FoV"
- Geometry-aligned vision encoder: A visual encoder trained or distilled to preserve geometric cues, not just semantics. Example: "we introduce a geometry-aligned vision encoder"
- Geometry fields: Dense representations capturing geometric properties across the image (e.g., perspective or incidence). Example: "a growing body of methods proposes to learn dense geometry fields"
- Incidence fields: Per-pixel fields encoding angles between rays and scene surfaces or reference directions. Example: "or incidence fields"
- Instruction tuning: Fine-tuning a model with instruction-like data to improve its ability to follow tasks and prompts. Example: "With instruction tuning, Puffin generalizes to diverse cross-view tasks"
- KV cache mechanism: A method that caches key/value tensors in transformers to accelerate sequential generation. Example: "The KV cache mechanism is utilized in cross-view generation"
- Learnable queries: Trainable tokens used to extract and transform model representations for downstream modules. Example: "a set of learnable queries"
- Latitude angle: An angular measure per pixel indicating elevation relative to a reference (e.g., gravity). Example: "latitude angle"
- Modality gap: The mismatch between different data modalities (e.g., numeric camera parameters vs. language/vision). Example: "modality gap between cameras and vision-language"
- Multimodal sequence modeling: Modeling sequences that mix modalities (text, images, camera tokens) through next-token prediction. Example: "multimodal sequence modeling paradigm"
- Perspective Field: A per-pixel representation encoding camera orientation cues like the up-vector and latitude for each pixel. Example: "Perspective Field"
- Pinhole camera model: An idealized camera model mapping 3D points to the image plane via a single projection center. Example: "We adopt the pinhole camera model"
- Pixel displacement fields: Dense per-pixel mappings describing geometric warps or displacements. Example: "pixel displacement fields"
- Professional photographic terms: Human-friendly categorical descriptors that abstract numeric camera settings (e.g., close-up, tilt-up). Example: "Professional Photographic Terms."
- Progressive unfreezing: A training strategy that gradually unlocks layers/modules for fine-tuning to stabilize optimization. Example: "via progressive unfreezing and joint fine-tuning"
- Radial distortion: Lens-induced deviation from the pinhole model causing straight lines to appear curved. Example: "radial distortion effects"
- Roll: Camera rotation around the viewing axis affecting horizon tilt. Example: "roll, pitch, and vertical FoV"
- Pitch: Camera rotation around the horizontal axis (tilt up or down). Example: "roll, pitch, and vertical FoV"
- Spatial imagination: Predicting or describing a target view’s content given another view and camera parameters. Example: "spatial imagination"
- Spatial reasoning: Inferring geometric relationships and camera parameters from visual cues and context. Example: "spatial reasoning"
- Up-vector: The per-pixel direction indicating “up” in the image relative to gravity or camera orientation. Example: "up-vector"
- Vanishing point estimation: Detecting convergence points of parallel lines to infer scene and camera geometry. Example: "vanishing point estimation"
- Variational Autoencoder (VAE): A generative model used for encoding/decoding images into a latent space. Example: "the VAE-encoded initial view"
- Vision-language-camera triplets: Training tuples that pair an image, a caption, and corresponding camera parameters. Example: "vision-language-camera triplets"
- Yaw: Camera rotation around the vertical axis (pan left/right) controlling viewpoint direction. Example: "an additional yaw parameter"
Collections
Sign up for free to add this paper to one or more collections.

