- The paper introduces TAG, a training-free control stack that enforces applicability control for memory-augmented inference without modifying model weights.
- It employs uncertainty-based routing and confidence-gated selective acceptance across multiple memory banks, yielding performance gains up to +7.67 points on benchmarks like ASDiv and SVAMP.
- The approach includes explicit rollback and evidence-based governance that retire harmful memory entries, ensuring robust and efficient performance improvement.
Training-Free Control Architecture for Memory-Augmented Inference
This paper investigates the applicability control problem in prompt-injected, training-free memory augmentation. Unlike architectures that optimize model parameters, this paradigm treats memory—prompt-injected rules or exemplars—purely as a contextual resource for model inference. The principal challenge addressed is determining not only what to retrieve but when and how to apply retrieved memory content, as improper exposure can degrade performance and increase computational cost.
The authors operationalize applicability control as a sequence of discrete control decisions: (i) when to trigger a memory-assisted second pass, (ii) when to trust its output sufficiently to override the baseline, and (iii) how to govern the memory bank via explicit entry retirement. This is formalized as stagewise control optimizing task utility under compute constraints and without any weight adaptation.
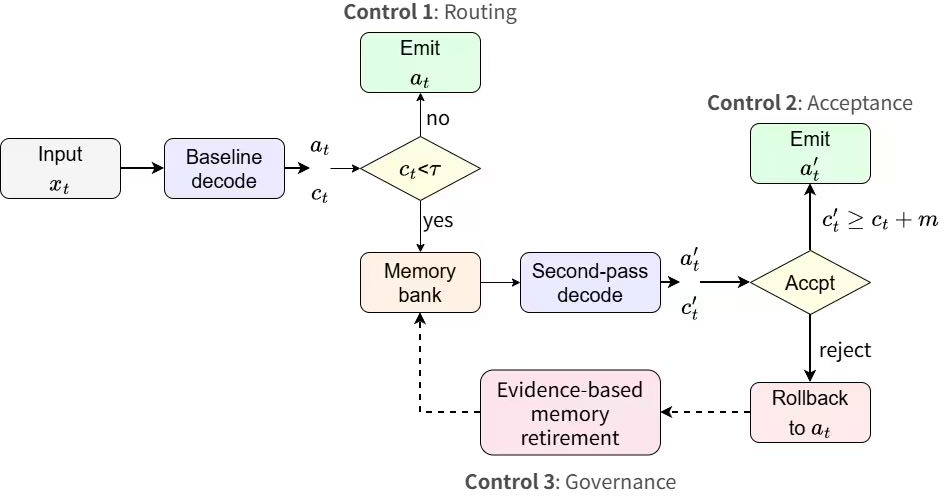
Figure 1: TAG decision flow. The system decodes a baseline action and only consults memory via a structured second pass when baseline confidence is low, gating acceptance via confidence improvement and structural guards, while harmful memory entries are retired over time.
Architecture and Methodology
The main contribution is TAG, a training-free control stack for applicability-mediated memory use. The architecture comprises four coordinated control mechanisms:
- Uncertainty-Based Routing: Memory retrieval and a second-pass inference are triggered only if baseline model confidence falls below a learned threshold. This exploits the empirical concentration of most memory injection gains in low-confidence instances, maximizing compute efficiency and reducing potential exposure to harmful interventions.
- Confidence-Based Selective Acceptance: The memory-conditioned second-pass output is accepted only if it exceeds the baseline by a required confidence margin and passes deterministic structural guard checks (e.g., answer format validity, progress, contract adherence). Otherwise, the system rolls back to the baseline output, preventing errors propagated by overzealous memory application.
- Bank Selection and Multi-Bank Policy: The system distinguishes between rule banks and exemplar banks, allowing for task- and instance-specific routing across multiple memory sources. Bank preference is governed by empirical help/hurt asymmetry and evaluated per benchmark.
- Evidence-Based Governance: Each memory entry accrues paired utility observations across fit/dev episodes. Entries with non-positive upper confidence bounds on utility are retired according to a UCB-style rule, thus gradually pruning persistently harmful content and enhancing test-time robustness. All control thresholds and the memory bank are frozen before test.
This unified controller aims to approximate the sign of the latent intervention utility at each instance, factorizing the applicability control into discrete, diagnostically separable stages: route, accept, retire.
Empirical Results
Arithmetic Reasoning
Experiments on SVAMP and ASDiv arithmetic reasoning benchmarks demonstrate significant performance gains: TAG improves accuracy by +7.0 and +7.67 points, respectively, over baseline inference and compute-matched non-memory second passes. Notably, performance improvements are not attributable to mere exposure to memory or an additional decode attempt but result from explicit applicability control. Retry-based and always-retrieve controls yield negligible or inferior gains, while TAG remains robustly superior.
Ablations and Mechanistic Analysis
Ablation studies isolate each control stack component. The results confirm that benefit localization varies by task: for SVAMP, rule-based gating and multi-bank composition are essential, whereas ASDiv is driven by exemplar-based routing and the selective acceptance mechanism. Relying solely on routing or non-selective acceptance substantially diminishes gains.
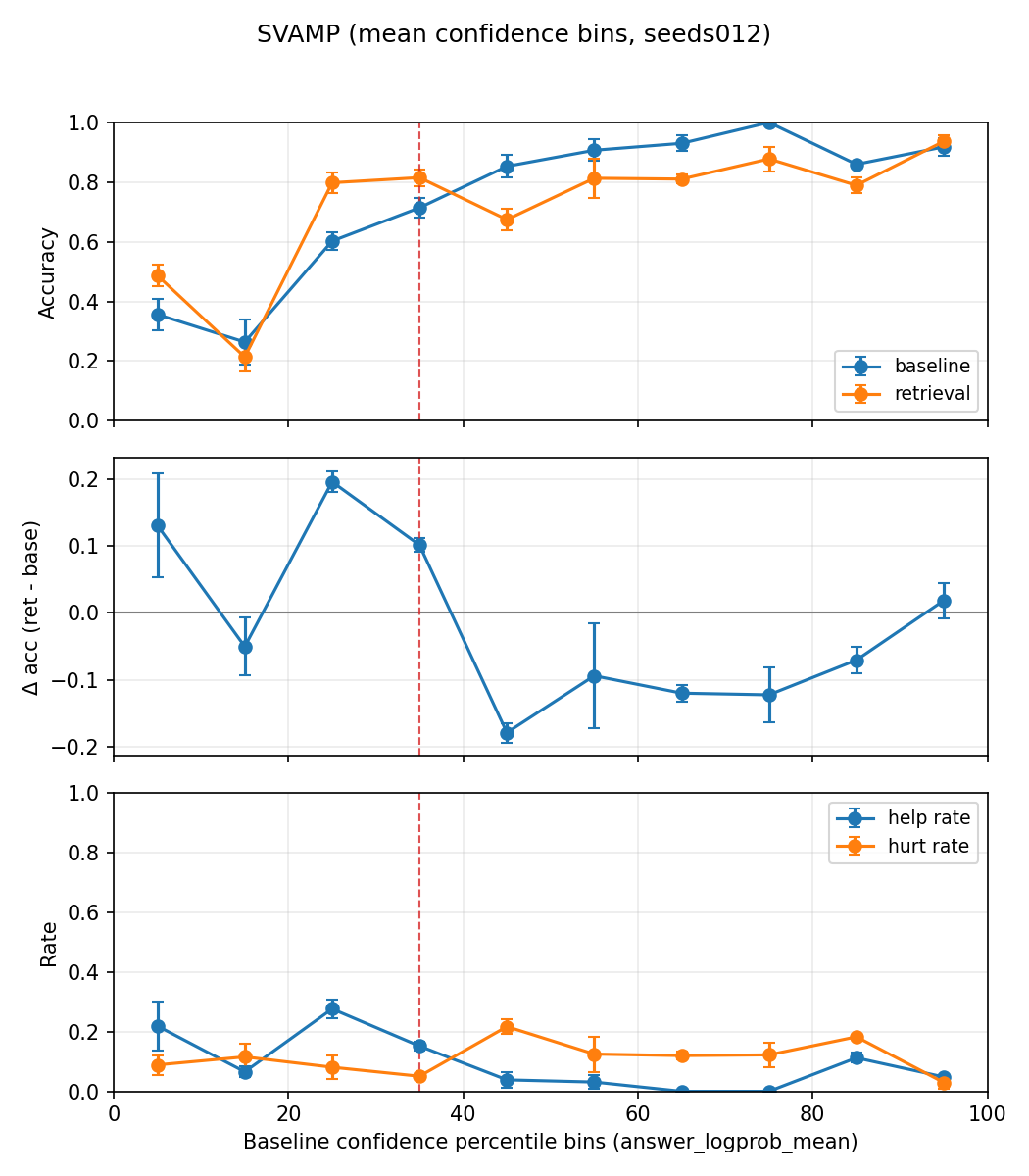
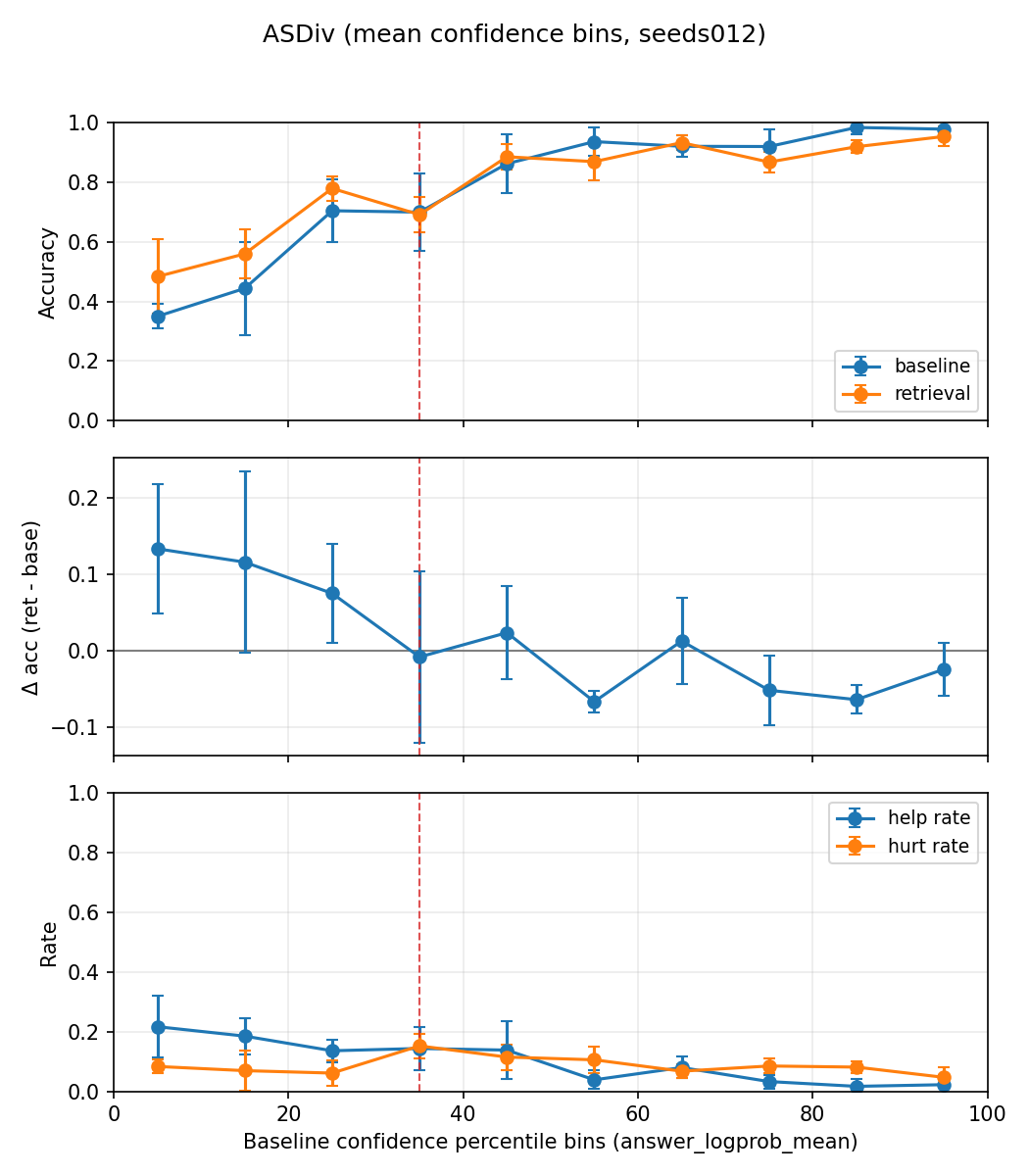
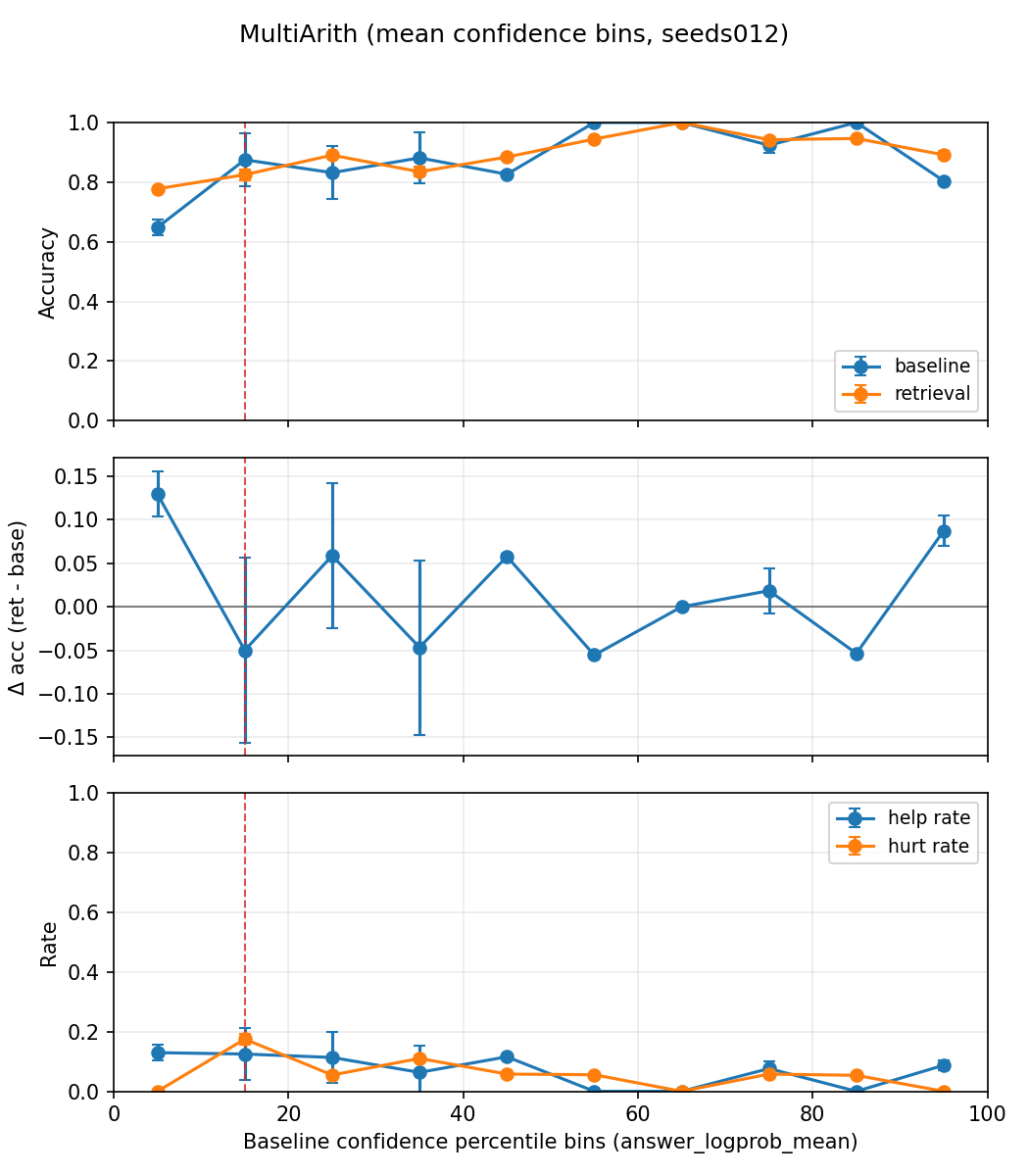
Figure 2: Performance on SVAMP demonstrates the efficacy of the control stack over fixed- and always-retrieve alternatives.
Applicability diagnostics strongly support the theoretical underpinnings: memory-augmented accuracy gains cluster in low-confidence buckets, as expected from the routing policy. Bank-specific confidence further separates helpful from harmful interventions, and the bank with the strongest help-minus-hurt count aligns with the empirically preferred bank.
Counterfactual analyses under fixed-retrieval identity isolate the intervention effect from retrieval drift, showing that gains concentrate on examples where the retrieved set contains edited memory entries—the improve/corrupt contrast is negligible elsewhere. This reinforces the claim that precise applicability control, not mere exposure, is driving the observed improvements.
Transfer to QA and Agent Benchmarks
TAG generalizes positively to QA tasks (OpenBookQA, ARC) and agentic benchmarks (WebShop, ScienceWorld), albeit with smaller effect sizes. In QA tasks, gated acceptance recovers or improves baseline accuracy compared to retrieval-only policies, even when retrieval exposure degrades it. In agents, TAG achieves improved accuracy and score/cost trade-offs, with significant reduction in harmful interventions relative to uncontrolled retrieval-exposure policies.
Implications, Limitations, and Future Directions
The results delineate a clear separation between retrieval utility and applicability control in training-free, memory-augmented inference. TAG provides a rigorous, operational pathway for safe and effective prompt-memory deployment in scenarios where weight updates are infeasible or undesirable. The stratified control mechanisms—especially explicit rollback and evidence-based governance—are critical for extracting positive signal from prompt memories and avoiding negative transfer.
However, the most consistent wins are concentrated in arithmetic-style reasoning. Confidence is a serviceable control signal only when help-vs-hurt separability is strong within a bank, and sensitivity to the quality and coverage of the memory bank remains to be thoroughly analyzed. Broader evaluation across more diverse domains, integration with more sophisticated retrievers, and automated bank construction are necessary for full assessment and continued progress.
Conclusion
This paper presents a rigorous formulation and empirical validation of applicability control in training-free memory-augmented inference. TAG's combination of uncertainty-based routing, confidence-gated acceptance, structured bank selection, and explicit governance establishes performance improvements unattainable by exposure or retry alone. The theoretical and practical separation of content and policy achieved here defines robust operating points for LLMs augmentable by prompt memory, clarifying the route toward more reliable and efficient inference under training-free constraints.