- The paper demonstrates that context-dependent control is achieved by applying context-indexed interventions on a shared recurrent state, eliminating the need for explicit memory growth.
- Experimental results show that the intervention model attains near-perfect success rates and measurable conditional contextual information, rivaling traditional memory-based architectures.
- The study validates information-theoretic predictions and highlights the practical benefits of lightweight, interpretable modulation mechanisms for sequential decision-making.
Intervention-Based Contextual Control Without Memory Growth in Context-Switching Tasks
Problem Setting and Motivation
The study addresses the challenge of context-dependent decision making under partial observability, focusing on how agents can express contextual dependence without explicit context input or increasing recurrent memory. In typical POMDP settings, context is handled either by providing explicit context tokens as input or by expanding the recurrent state to encode contextual information, both of which have architectural and efficiency trade-offs.
The authors propose an alternative: context-dependent control realized via context-indexed intervention on a shared recurrent latent state, avoiding increases in recurrent dimensionality. This premise is motivated by recent information-theoretic work on contextuality and resource requirements in single-state models (Kim, 3 Feb 2026), illuminating the non-necessity of state-space growth for maintaining contextual dependence at the level of observable outcomes.
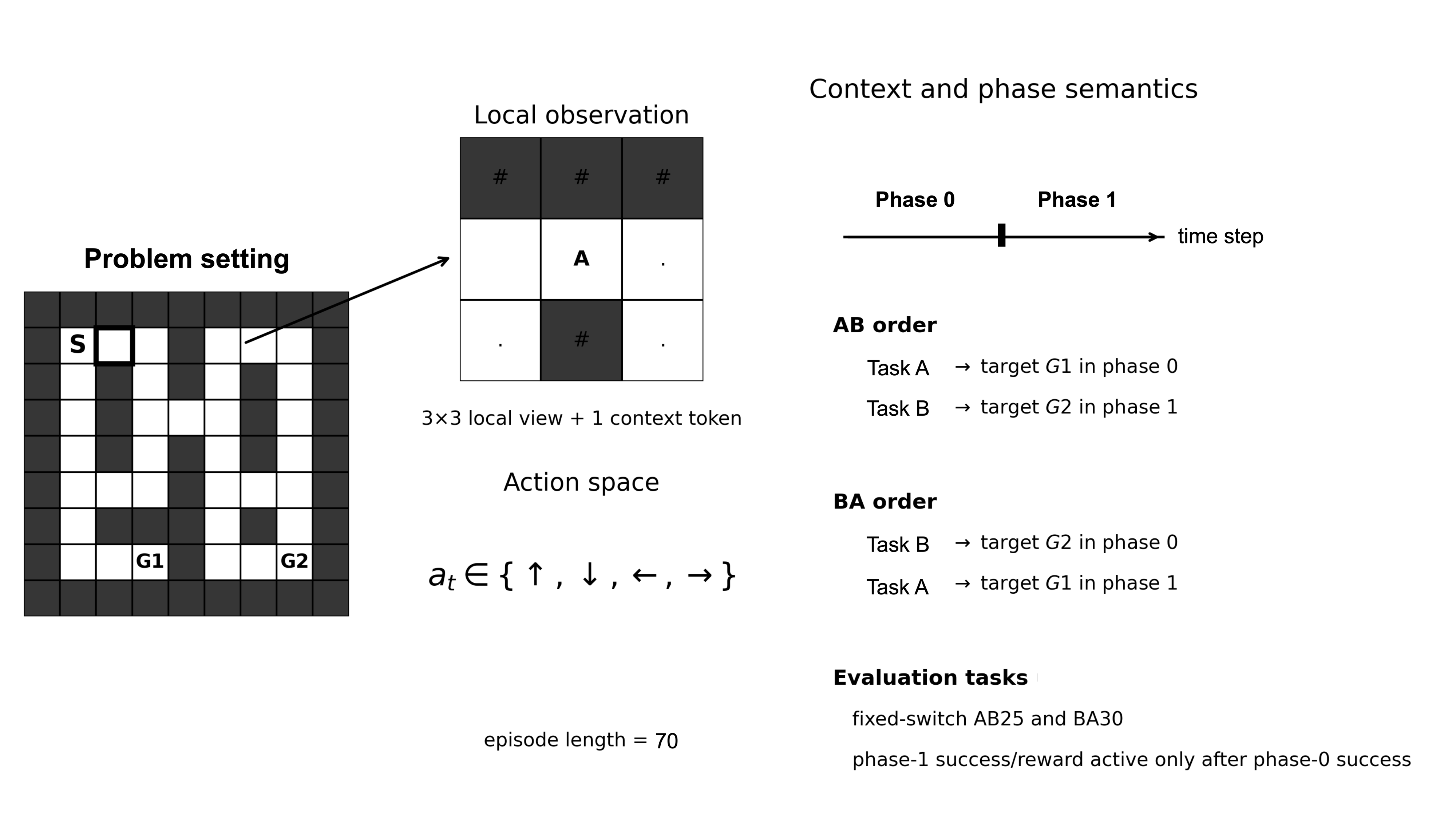
Figure 1: Problem setup illustrating phase-dependent goal switching in a partially observable maze, with agent observations limited to a 3×3 field of view and context signaled via a token.
Architectural Approaches and Model Families
Three model families are compared within a minimal partially observable gridworld benchmark that imposes a within-episode context switch dictating different goal targets for each phase:
- Label-Assisted Baseline (L): Direct context concatenation as input; serves as an upper-bound oracle.
- Memory Baseline (M): No direct context input; recurrent latent state enlarged (dim(zt)=d+m) to carry context implicitly.
- Intervention Model (I): Context is withheld from the recurrent core; instead, a residual, context-indexed linear operator perturbs the recurrent latent state: zt′=zt+αDct(zt), where Dct is a learned, bias-free linear map.
The agent must adapt its policy to target G1 or G2 depending on both phase and condition (AB or BA order).
Figure 2: Architectural diagram of the three model families, highlighting the separation of context access and memory growth mechanisms.
Experimental Results
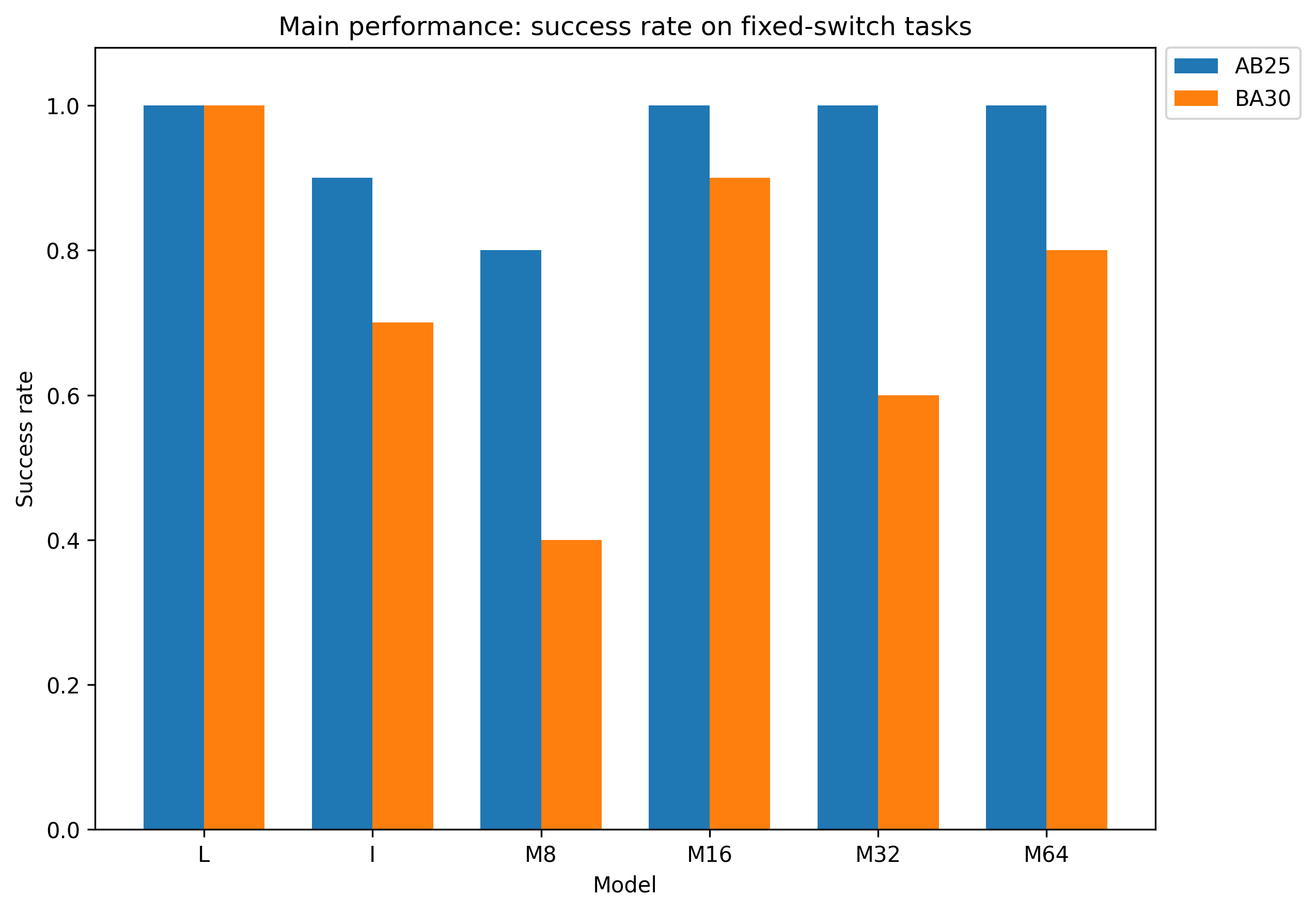
Performance is evaluated on benchmark conditions AB25 and BA30, measuring the fraction of seeds that successfully solve both task phases and analyzing phase-specific success rates. The training protocol ensures matched base recurrent dimensionality, differing only in how context is integrated.
Key empirical findings:
These results challenge the sufficiency of naive memory growth for robust contextual dependency, supporting the intervention architecture as a competitive, parameter-efficient solution in this setting.
An operational probe, dim(zt)=d+m3, quantifies context dependence at fixed recurrent latent state dim(zt)=d+m4. Estimators use counterfactual distributions over context to compute conditional mutual information for task-relevant outcomes (e.g., hitting the context-appropriate target).
- Positive dim(zt)=d+m5 is observed in all models for phase-1 goal-related outcomes, with the intervention model matching or exceeding memory and label-assisted baselines within sampling error:
- For AB25 (target_hit): L: dim(zt)=d+m6, I: dim(zt)=d+m7, M16: dim(zt)=d+m8 bits.
- For BA30 (goal3): I: dim(zt)=d+m9 bits.
- Primitive-outcome definitions (one-step actions) yield much lower estimates, highlighting that context-driven distinctions manifest primarily at abstract, goal-level events.
Thus, context remains observable in the outcome distribution even after conditioning on latent state, consistent with the theoretical expectation that contextuality can be preserved without explicit memory extension (Kim, 3 Feb 2026).
Implications, Limitations, and Future Directions
The findings have practical and conceptual implications:
- Architectural Efficiency: Contextual dependence can be achieved without explicit context input or increased recurrent state, suggesting recurrent architectures with intervention-based modulation could offer a scalable alternative to ever-larger recurrent cores.
- Interpretability and Modularity: Context-indexed interventions produce interpretable, structured modulation of latent representations, potentially benefiting factorization of roles such as phase-switching, task selection, or tool reuse in larger agentic systems.
- Theoretical Alignment: Positive zt′=zt+αDct(zt)0 values support recent information-theoretic theorems about contextuality, though the empirical setting does not instantiate all formal assumptions of those results.
Limitations include restriction to a controlled, two-phase benchmark, limited generalization claims to unseen switch times, and a focus on a simple residual linear intervention. Broader evaluation across richer context structures, more complex environments, modulation schemes beyond linearity, and tighter empirical estimators would clarify the generality and limitations of these findings.
Future research should explore:
- Application of intervention-based modulation mechanisms in large-scale RL/sequence models.
- Analysis of latent geometry before and after intervention across tasks with hierarchical or compositional context.
- Direct comparisons with alternative conditional architectures, such as FiLM [Perez et al., AAAI 2018] or hypernetwork-style modulation, for contextuality expressiveness and efficiency.
Conclusion
This study demonstrates that context-dependent control in sequential decision tasks can be realized by intervention on a shared recurrent latent state, obviating the need for recurrent memory growth or direct context concatenation. The intervention model matches the best memory-based baseline in benchmark performance and exhibits measurable conditional contextual information, supporting both practical efficacy and alignment with information-theoretic predictions of contextual dependence. These results argue for the utility of intervention-based architectures as a lightweight, interpretable primitive in both compact and scalable agent designs.