- The paper quantifies that rule files boost agent pass rates by 7–14 percentage points by leveraging structural context rather than detailed content.
- It employs a robust experimental framework using over 5,000 agent runs and a corpus of 679 GitHub rule files to classify rule effects.
- The study reveals that negative constraints reliably improve performance while positive directives often harm it, underscoring the value of ensemble resilience.
Do Agent Rules Shape or Distort? Guardrails Beat Guidance in Coding Agents
Introduction
The paper "Do Agent Rules Shape or Distort? Guardrails Beat Guidance in Coding Agents" (2604.11088) delivers a comprehensive empirical and theoretical analysis of how natural language rule files, increasingly authored for LLM-based coding agents, impact agent performance on complex software engineering tasks. The central investigation quantifies not only the aggregate efficacy of such rule files but also the nuanced interaction between rule type (negative constraints vs. positive directives), content specificity, and compositional effects. The study employs a large-scale, methodologically rigorous experiment suite (over 5,000 agent runs), leveraging SWE-bench Verified, to isolate and probe the mechanisms by which these rules either facilitate or undermine agent effectiveness.
Corpus and Taxonomy of Rule Files
A foundational component involves the creation of a unique corpus: 679 rule files (totaling 25,532 rules) were systematically scraped from GitHub, focusing on prevalent formats such as CLAUDE.md and .cursorrules. Rules were classified using a validated LLM-based taxonomy into six categories—project-specific context (dominant, ~65%), behavior/persona, tool/process, code style, architecture, and safety constraints (negative commands e.g., “do not modify unrelated files”).

Figure 1: Taxonomy of 25,532 rules from 679 GitHub rule files, with project-specific context dominating the distribution.
Interestingly, the landscape reveals developers predominantly use these files for repository-specific context injection, rather than task-agnostic behavioral guidance, motivating the authors to stratify much of their analysis on the more transferable, cross-repository rule categories.
Experimental Framework and Methodology
The empirical setup employs Claude Code (Claude Opus 4.6) integrated with SWE-bench Verified for rigorous, real-world task benchmarking. Rule files are injected persistently per-agent run, paralleling authentic developer workflows. To ensure experimental sensitivity, task selection emphasizes “discriminative” exemplars where agent baseline performance is variable (30–70% pass rates), maximizing statistical power to detect both helpful and harmful effects. All evaluations employ paired designs and exact statistical tests (McNemar, Cochran’s Q) to ascertain the significance of observed effects.
Do Rules Help, and Does Content Matter?
The first suite of experiments establishes that the presence of any rule file reliably boosts agent pass rates 7–14 percentage points above baseline (up to 63.8%), regardless of rule provenance, semantic specificity, or even syntactic coherence.
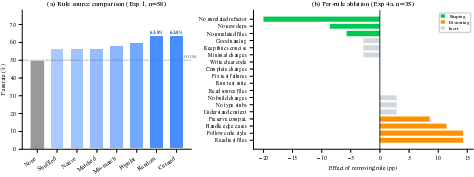
Figure 2: The presence of rules—curated or random—outperforms the baseline by a similar margin, suggesting a dominant context priming effect over content-specific instruction.
The absence of significant differences between curated, random, popular, matched, mismatched, or syntactically shuffled rules strongly supports a context priming hypothesis: the agent’s performance enhancement arises from the structural presence of instructions, not their semantic details.
Rule Quantity, Type, and Scaling Effects
Further analysis tests for phase transitions with increasing rule counts. Contrary to classical expectations of performance degradation from cumulative noisy signals, there is no observed performance decrease even with 50 rules; the effect is marginally positive and robust to sampling variance.
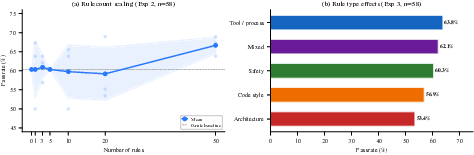
Figure 3: (a) Pass rate remains stable or slightly improved with increasing rule count; (b) Tool/process (state-dependent) rules achieve the highest efficacy, with architecture (state-independent) rules the lowest.
This outcome evidences ensemble resilience: the LLM filters and aggregates rules, dampening individual distortions while retaining a generic behavioral prior.
When controlled for rule type, tool/process (state-dependent) rules—those that condition on agent state, similar to potential-based reward shaping (PBRS) in RL—confer the greatest benefit. In contrast, architecture and stylistic rules (state-independent) are the least effective. However, effect sizes are modest, and differences are often not statistically significant, reinforcing the primacy of rule structure and polarity over content.
Shaping versus Distorting: Rule Polarity and Interaction
Per-rule ablation on a curated set of 18 rules uncovers a critical dichotomy: negative constraints (“do not X”) are the only consistently beneficial type, while positive directives (“do X”) are frequently harmful. Out of 18 rules, three negative constraints are shaping (removal hurts performance), while four positive directives are distorting (removal helps). The remainder are inert in isolation.
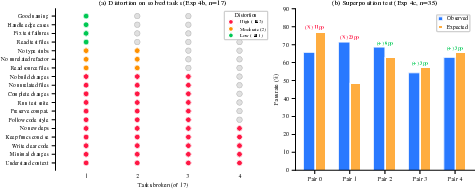
Figure 4: (a) Most individual rules, when applied alone, are harmful to previously-solved tasks—collective effects are required for overall benefit; (b) Rule pair superposition reveals mostly additive effects, but some strongly nonlinear compensation or interference.
Isolated application of individual rules to previously-solved tasks reveals that 14/18 break at least two (out of 17) tasks, with some destructive rules causing up to 24% regression. Still, ensembles of rules are collectively helpful due to averaging out of distortional effects, with negative constraints contributing reliability improvements while much of the positive directive content distracts or overcomplicates the agent’s decision process.
Rule pair experiments suggest partial additivity but notable nonlinear interaction: some harmful rules are fully compensated by others, while some helpful pairs interfere destructively. This underscores limits of linear reward shaping analogies from RL in the LLM context.
Theoretical Implications through PBRS Analogy
Applying the PBRS framework from RL to categorically analyze rule effects is partially validated. State-dependent, constraint-like rules are more effective, paralleling proper reward shaping, but performance resilience to accumulated rules and nonlinear rule interactions highlight substantial mechanistic differences between RL agents and LLM-driven planning.
Broader Implications for Agent Configuration and Safety
The findings carry substantial implications for agent safety, reliability, and the automated optimization of rule files:
- Rule presence, not content, dominates: The specific formulation or project-language match of rules is less important than simply having a rule file.
- Negative constraints as best practice: Rules that eliminate error-prone agent behavior (“do not X”) are safer and more robust than positive directives or procedural instructions.
- Collective effect over individual optimization: Harmful rules can be neutralized or compensated in ensembles, warning against greedy or myopic rule selection processes.
Practically, this motivates a paradigm where rule-file authors and automated optimizers should focus on constraint-based, state-sensitive rules, measure reliability on previously-solved tasks, and deprioritize attempts at micro-optimizing positive directives, which so often degrade base agent efficacy.
Practical Recommendations
The study advises that rule-file authors:
- Emphasize negative constraints over positive directives.
- Avoid removing non-damaging rules for the sake of brevity, as ensemble effects mitigate individual rule harm.
- Do not overfit rule content or style, as the LLM’s in-context learning optimally leverages the presence, not precision, of instructions.
- Audit rules for silent regressions, given their capacity to degrade agent performance in non-trivial portions of the task distribution.
Conclusion
This work provides a rigorous empirical and theoretical foundation for understanding the real impact of natural language rule files in LLM-based coding agents. The results systematically demonstrate the primacy of contextual priming and negative constraints in promoting agent robustness and highlight the reliability risks posed by positive, procedural rules, even when well-intentioned. These insights directly inform best practices for manual and automated rule configuration and clarify how design principles from RL reward shaping only partially generalize to LLM instruction scaffolding.
Future Directions
Critical avenues include extension to weaker (less capable) agent backbones, translation to non-coding agent domains, and mechanisms for converting constraint-style rule files into auxiliary reward signals, thereby potentially integrating the guardrail effect into model pretraining or RLHF pipelines. Additionally, automated systems for rule induction, such as EvolveR and DSPy, can prioritize constraint-centric strategies and ensemble compositionality.
References:
"Do Agent Rules Shape or Distort? Guardrails Beat Guidance in Coding Agents" (2604.11088).