- The paper introduces a data-dependent, fine-grained rotation optimized for MXFP4 quantization to precisely counter intra-block outlier effects.
- It achieves lower quantization error and improved end-to-end performance on LLaMA models by reducing perplexity and increasing accuracy compared to baseline methods.
- The method leverages hardware-native 32-element blocks to enhance computational efficiency, facilitating low-memory, high-efficiency deployment of large language models.
DuQuant++: Fine-grained Rotation Enhances Microscaling FP4 Quantization
Background and Motivation
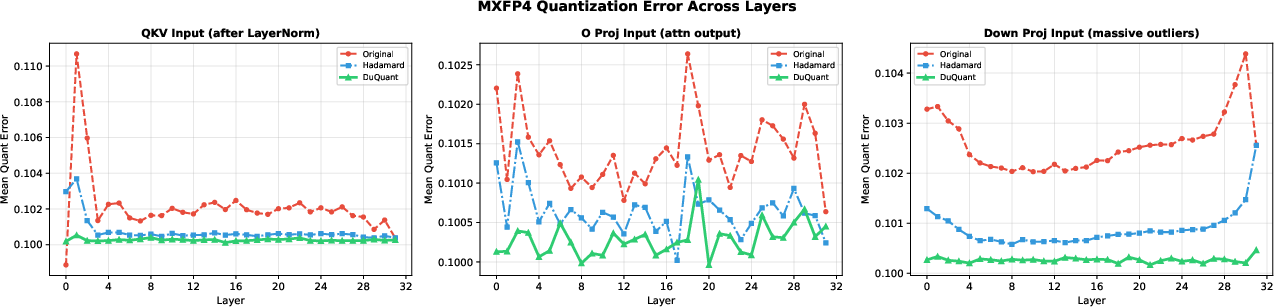
As LLM deployment grows, inference-time memory and computational constraints necessitate aggressive post-training quantization (PTQ) strategies to reduce model footprints while maintaining accuracy. Floating-point microscaling formats such as MXFP4, which partition tensors into 32-element blocks each with a shared E8M0 scaling factor, are gaining traction due to native hardware support (e.g., NVIDIA Blackwell Tensor Cores) and superior tradeoffs compared to traditional uniform integer schemes. However, these formats are susceptible to intra-block outliers: a single large-magnitude value can inflate the block scaling factor and compress effective dynamic range for the remaining elements, resulting in significant quantization error.
Prior proposals for mitigating group-wise outlier effects in low-bit quantization have relied on randomized or learnable rotation matrices, either at the block or global level. These approaches, which include randomized Hadamard (as in MR-GPTQ and BRQ) or global/learned rotation (QuaRot, FlatQuant), are data-agnostic and cannot directly address the outlier concentration patterns that dominate quantization error in MXFP4 blocks.
DuQuant++: Methodology
DuQuant++ introduces a data-dependent, outlier-aware fine-grained rotation specifically optimized for the MXFP4 format. The central insight is to match the rotation block size exactly to the MXFP4 group size (B=32), such that each rotation acts locally within a single microscaling block—a natural fit enabled by the group-wise independent scaling structure of MXFP4. The method is adapted from DuQuant's original fine-grained block-diagonal rotation, but streamlined by:
- Single Outlier-Aware Rotation: MXFP4's independent scaling per group obviates the cross-block variance problem present in integer quantization, eliminating the necessity for both dual rotations and interleaving permutations.
- Data-Dependent Construction: The rotation matrices are constructed to specifically deflate the directions of maximum outlier concentration in the activation or weight tensors, rather than distributing energy arbitrarily as with random rotations.
- Integration with Smoothing: DuQuant++ optionally employs a SmoothQuant-like channel-wise scaling step as a precursor, reducing normal outliers and relegating the hardest tails (i.e., massive outliers) to be handled by the targeted block rotation.
- Joint Rotation of Activations and Weights: The rotation is simultaneously applied to both activations and weights; the orthogonal inversion can be folded into the weight representation, incurring negligible online overhead.
This method, by design, halves the online rotation cost relative to the original dual-rotation DuQuant pipeline and achieves greater hardware-amenability due to its alignment with MXFP4 block sizes.
Empirical Analysis
DuQuant++ is evaluated extensively on both pre-trained and instruction-tuned LLaMA-3 models (8B and 3B scales), under the aggressive W4A4 (weights and activations at 4-bit) MXFP4 quantization regime. The key empirical observations are the following:
Implications and Future Directions
DuQuant++ presents a highly format-aware quantization intervention, leveraging the hardware-exposed groupwise scaling of MXFP4 to target activation outliers at the right granularity with minimal overhead. This design closes the gap to full-precision accuracy at aggressive quantization settings, providing a clear path for deployment of large LLMs in low-memory, high-efficiency contexts.
Beyond immediate practical implications, this work implies several directions for future research:
- Automated Format-Aware Rotation for Emerging Microscaling Types: As alternate floating point and microscaling formats are introduced (e.g., NVFP4), custom-fitted data-dependent transformations can be architected for each case, potentially formalized as a class of hardware-aware post-training quantization operators.
- Adaptive Calibration and Online Fine-Tuning: While DuQuant++ relies on calibration sets for block-wise rotation construction, online observability or data-driven adaptation could further boost generalization or mitigate rare-event outlier issues.
- Low-Bit Quantization Beyond LLMs: Extensions to vision transformers and multimodal architectures, or adaption to sub-4-bit configurations, could further broaden the impact of block-wise data-dependent rotations in resource-constrained inference.
Conclusion
DuQuant++ demonstrates that block-aligned, data-dependent rotations offer superior performance for MXFP4 quantization by precisely neutralizing intra-group outliers, all while maintaining computational efficiency. It consistently outperforms both randomized and global rotation baselines, establishes new benchmarks on multiple LLaMA-3 variants, and suggests that hardware- and data-aware methods are essential for scaling aggressively quantized models to real-world deployment.