- The paper introduces CodeQuant, a unified framework combining learnable rotation-based activation smoothing with permutation-invariant grouping to mitigate outlier issues in MoE post-training quantization.
- It employs adaptive K-means clustering with centroid fine-tuning alongside a specialized LUT kernel to achieve significant reductions in latency and quantization error.
- Empirical evaluations demonstrate up to 22.8% accuracy gains and 2.63×–4.15× speed improvements, establishing a new standard for low-bit quantization in large-scale MoE models.
CodeQuant: Unified Clustering and Quantization for Enhanced Outlier Smoothing in Low-Precision Mixture-of-Experts
Introduction
This paper introduces CodeQuant, a unified quantization and clustering strategy specifically engineered for post-training quantization (PTQ) of Mixture-of-Experts (MoE) architectures in LLMs (2604.10496). CodeQuant addresses the critical limitation of activation and weight outlier management in sub-8-bit PTQ, which remains a principal source of degradation in accuracy and hardware efficiency for MoE-based models. The methodology integrates learnable rotation-based smoothing of activations, permutation-invariant weight grouping, and clustering-based quantization, jointly targeting both algorithmic robustness and hardwae-aligned deployment through lookup table (LUT)-optimized kernels.
MoE models have become a de facto paradigm for scaling LLMs, facilitating conditional computation via expert specialization. However, the prevalence of activation and weight outliers strongly impedes the feasibility of low-bit quantization, especially in settings where only four bits are available for each parameter. Classical outlier-aware PTQ techniques either utilize explicit isolation and mixed-precision schemes or structure-preserving transformations such as rotations and permutations. Recently, clustering-based quantization with LUT deployment has demonstrated hardware alignment and efficacy, as seen in works such as SqueezeLLM, QLoRA, and LUT-GEMM. Nevertheless, these methods suffer degradation under the extreme dynamic range of MoE and do not synergistically combine activation smoothing with robust non-uniform quantization.
CodeQuant fundamentally advances this line of research by embedding smoothed activation distributions into downstream row-wise clustering, followed by centroid refinement and system-level LUT acceleration.
Methodology
CodeQuant establishes a four-stage pipeline: (1) Activation smoothing via learnable rotations, (2) permutation-invariant outlier grouping (POG) for reordering weights, (3) adaptive clustering with centroid fine-tuning (ACCF), and (4) hardware deployment via a specialized LUT kernel. The design leverages the rotation and permutation invariances of self-attention and FFN blocks in MoE models, facilitating lossless transformation prior to quantization.
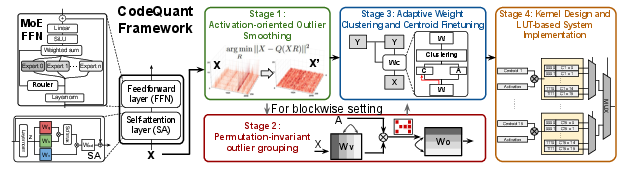
Figure 1: Overview of the CodeQuant framework for MoE models, with structural integration of learnable rotations, weight permutation, clustering, and LUT-based deployment.
Activation-Oriented Outlier Smoothing (AOS)
AOS introduces an orthogonal rotation matrix, parameterized and fine-tuned via the Cayley transform, that is applied to all activations entering the MoE block. This rotation is optimized to minimize the quantization error on the activation domain, explicitly translating the high-magnitude outliers into the weight space, which is subsequently handled by clustering. Empirically, this step ensures reduction in quantization error over random or fixed rotations and generalizes robustly beyond calibration data.
Permutation-Invariant Outlier Grouping (POG)
Clustering efficacy is highly dependent on the variance within block-wise partitions. POG reorders the columns of the rotation-adjusted weight matrix, grouping high-variance sub-blocks with low-variance ones to reduce clustering error. This operation—formulated as a permutation matrix—maintains computational invariance and is absorbed into the model at deployment, thus incurring no runtime cost.
Adaptive Weight Clustering and Centroid Finetuning (ACCF)
Weights are clustered on a per-row basis via a groupwise K-means algorithm with custom assignment and centroid update rules. The centroids are optimized by minimizing the output difference to the original matrix product via a partially diagonalized gradient approach, and in the MoE router and up-projection layers, a KL divergence penalty is imposed to regularize token–expert affinity and maintain consistent routing. This objective formulation preserves original model semantics and stabilizes routing in quantized deployment.
Specialized LUT Kernel and Deployment
The quantized model is materialized via a specialized LUT GEMM kernel, which precomputes the possible product outputs between activation and weight centroids and performs direct table lookups at inference, thereby obviating expensive dequantization and multiplications.
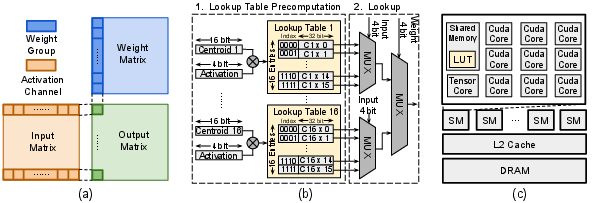
Figure 2: Execution steps of the CodeQuant kernel: block tiling, LUT precomputation, and shared memory lookup for each matrix tile on GPU.
Experimental Evaluation
Comprehensive benchmarks on diverse MoE models—Phi-mini-MoE-Instruct, Qwen3-30B-A3B, DeepSeek-V2-Lite, and Mixtral 8×7B—demonstrate CodeQuant's effectiveness on both language modeling (WikiText2, C4) and downstream QA and reasoning tasks (ARC, HellaSwag, MMLU, PIQA, WinoGrande, GSM8K, MATH500).
Accuracy and Robustness
- A4W4 embedding-wise quantization: CodeQuant outperforms state-of-the-art methods such as SqueezeLLM and QuaRot, with lower perplexity (up to 16 points vs. QuaRot) and higher average accuracy (up to 22.8% absolute over SmoothQuant and 11.3% over QuaRot).
- Mathematical reasoning: On GSM8K and MATH500, CodeQuant exhibits minimal degradation (≤3.4%) from full-precision baselines and robustly outperforms uniform and rotation-based quantization methods in reasoning-heavy evaluation.
- Block-wise partitioning: POG consistently yields improvements when quantization is block-wise but exhibits no effect in embedding-wise clustering due to K-means order invariance.
- Rotation fine-tuning: Learned rotations via AOS boost accuracy by up to 1.4% over random rotations.
- KL regularization: Augmenting the centroid objective with a KL divergence penalty stabilizes router output and further mitigates expert assignment perturbation.
Hardware and Latency
- On simulated A100 GPUs with the LUT-optimized kernel, CodeQuant achieves a 2.63× latency reduction over BF16 baselines and significant gains over SqueezeLLM and QuaRot.
- Real-CPU deployment (T-MAC kernel, Llama.cpp) demonstrates up to 4.15× speedup with substantial reductions in memory footprint.
- The LUT kernel strategy yields clear hardware efficiency advantages, particularly for deployment on architectures with constrained memory bandwidth and limited vectorization support.
Discussion and Implications
CodeQuant provides a comprehensive PTQ framework for MoE models that demonstrates resilience against activation/weight outliers and delivers accuracy–efficiency tradeoffs in extreme compression settings. The method's success is grounded in the combination of differentiable activation rotation, permutation-based clustering preparation, rigorous objective-driven centroid refinement, and hardware-optimized deployment.
The theoretical contribution lies in establishing a rigorous, rotation- and permutation-invariant pathway from model training to post-training quantization, while the practical import is evidenced by empirical results and hardware acceleration applicability. The demonstrated efficacy on reasoning benchmarks indicates that robust quantization need not come at the expense of complex compositional abilities, a critical consideration for real-world LLM deployment.
Future Directions
- Broadening to other MoE architectures: The methodology is directly extensible to other block-sparse and conditional computation models.
- Hardware co-design: Further exploration of native LUT primitives and banked shared memory system design will likely yield additional efficiency.
- Dynamic and mixed-precision settings: Combining CodeQuant's approach with learnable mixed-precision and dynamic quantization for task-adaptive inference is a promising line.
- Joint training-clustering paradigms: Integrating CodeQuant schemes into quantization-aware training may further improve robustness and accuracy.
Conclusion
CodeQuant advances the state of the art in PTQ for MoE-based LLMs by synergistically combining learnable activation smoothing, outlier-aware weight permutation, clustering-centric quantization, and hardware-aligned LUT kernels. The framework offers significant improvements in numerical robustness, accuracy, and system efficiency over prior methods. This establishes a new baseline for post-training quantization in high-parameter-count LLMs and provides a blueprint for future research at the intersection of quantization, clustering, and systems co-design for scalable AI.