- The paper introduces RUQuant, which leverages a two-stage orthogonal transformation pipeline combining Householder reflections and Givens rotations to align non-uniform activation distributions with uniform quantizers.
- The paper demonstrates high accuracy retention with LLaMA models, achieving up to 99.8% of full-precision performance and fast quantization speeds without requiring model fine-tuning.
- The paper shows practical implications with significant speedup (1.8×–2.1×) and memory reductions (3.3×–3.6×) during inference, highlighting its scalability for commodity hardware deployments.
Introduction and Motivation
The increasing depth and width of LLMs pose substantial challenges for memory and computational efficiency, especially in resource-constrained deployment scenarios. Post-training quantization (PTQ) methods compress LLMs with minimal architectural disturbance by quantizing both weights and activations. Existing uniform quantization approaches, while efficient, suffer from significant performance loss when deployed on real LLMs due to the mismatch between non-uniform activation distributions and rigid, interval-based quantization grids.
RUQuant addresses this activation quantization deficit by theoretically reframing the quantization process with Lloyd-Max optimality analysis. The key insight is that for non-uniform distributions, the centroid of the quantization interval—the Lloyd-Max optimal point—deviates from the interval midpoint assumed by uniform quantization. RUQuant proposes a two-stage orthogonal transformation pipeline to regularize these distributions, effectively reconciling them with uniform quantizers.
Theoretical Framework and Methodology
RUQuant systematically enforces uniformity in both activations and weights using structured orthogonal transforms derived from Householder reflections and Givens rotations. The process consists of two stages:
- Block-wise Orthogonalization: Activations are partitioned into blocks. Within each block, composite orthogonal matrices, constructed from closed-form combinations of Householder and Givens transforms, map non-uniform activation vectors to uniformly-distributed targets. This dramatically reduces the statistical anisotropy and outlier-induced variance pervasive in LLM activations.
- Global Refinement: After block-wise alignment, a trainable Householder reflection is applied globally. Its parameters are optimized to minimize functional discrepancy between Transformer outputs pre- and post-quantization, aligning quantization errors with model loss.
The transformation obeys theoretical guarantees: for activation distributions N(μ,Σ), the composite mappings induce joint mean and covariance homogenization. The orthogonal rotation ensures the transformed mean and covariance satisfy
Qμ≈u,E[QΣQ⊤]=dtr(Σ)I
where u is a uniformly sampled target vector. Equivalent results hold for weights under the same transformation, smoothing the entire projection operation.
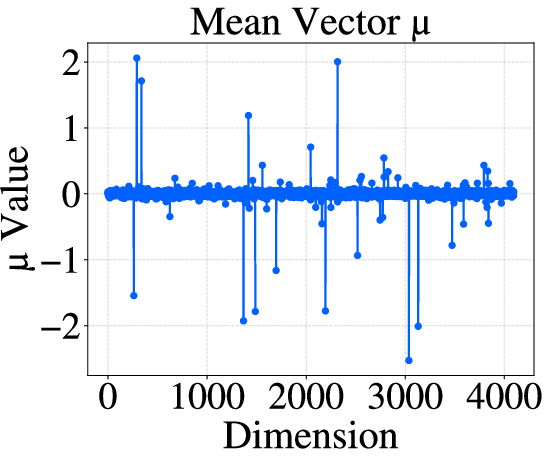
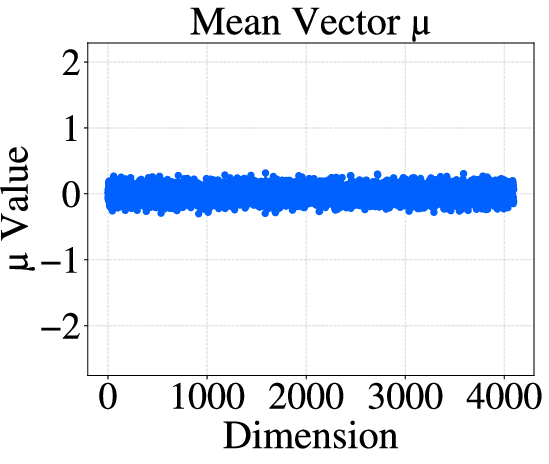
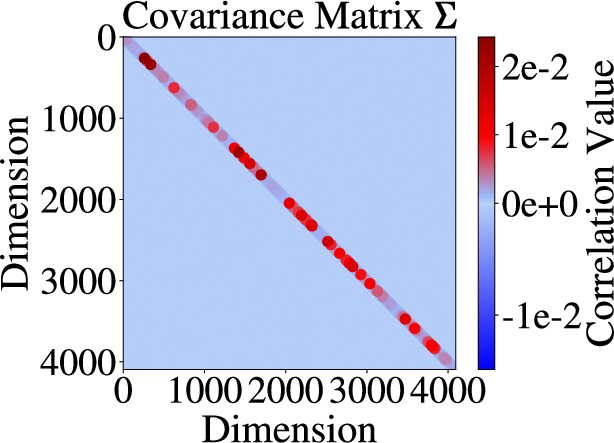
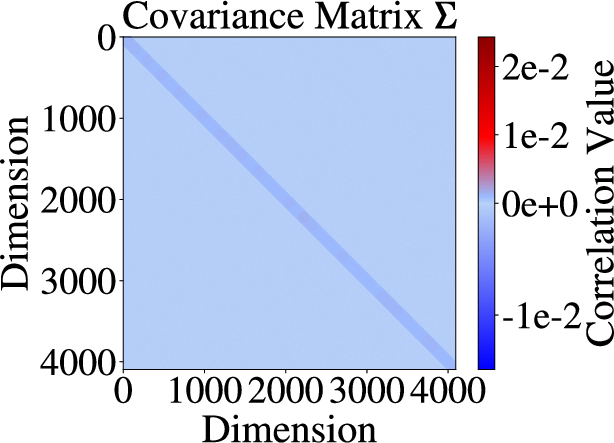
Figure 1: Mean vector and covariance matrix visualizations of activations before (a, c) and after (b, d) RUQuant processing, illustrating distributional homogenization.
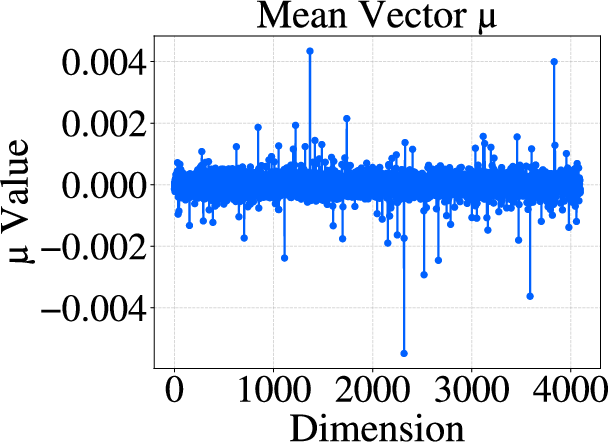
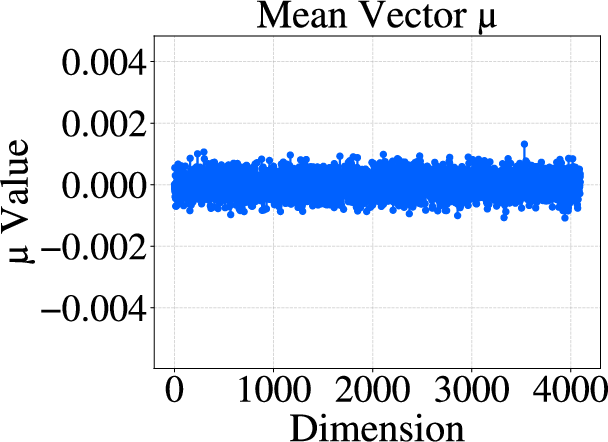
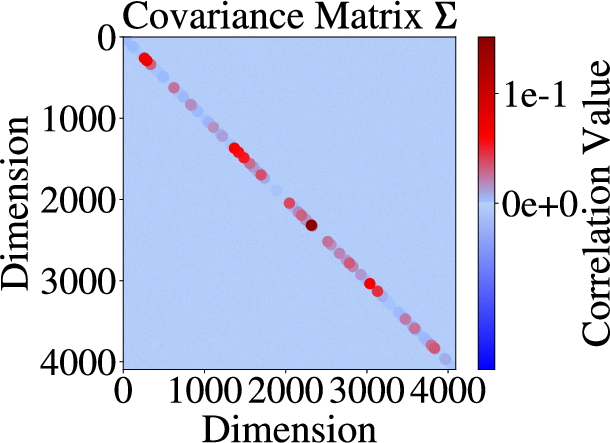
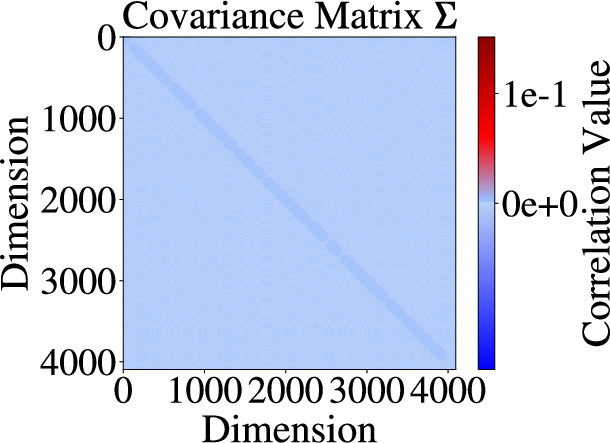
Figure 2: Effect of RUQuant on LLM weights, with post-processing means and covariances exhibiting strong isotropy and reduced variance.
Implementation Pipeline
RUQuant is deployed per-transformer-block, alternating orthogonal mapping and zigzag permutation steps to disrupt residual block correlations and maximize distribution uniformity. The pipeline is:
- Reshape activations into blocks.
- Apply block-wise Householder and iterative Givens rotations.
- Perform zigzag permutations for block decorrelation.
- Train a final Householder reflection, using loss computed as the squared Frobenius distance between output activations before and after quantization-induced mapping.
The orthogonal transformations are formulated to be computationally efficient. Block structure reduces per-layer overhead to O(BdN) with B≪d, while the closed-form Householder/Givens routines introduce negligible parameter and runtime cost.
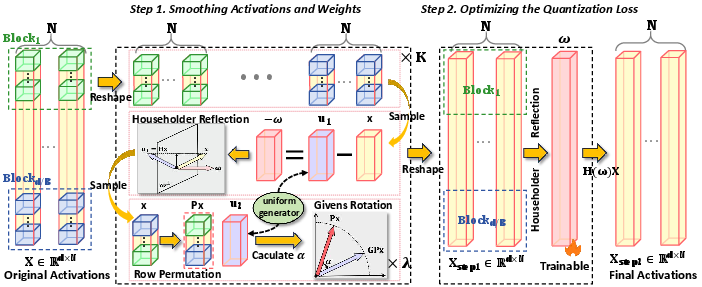
Figure 3: RUQuant framework overview, showing block-wise transformation and zigzag permutation modules (zigzag details omitted for brevity).
Empirical Evaluation
RUQuant is evaluated on several LLM architectures (LLaMA1, LLaMA2, LLaMA3; 7B--30B parameter scales) across perplexity, zero-shot classification, and MMLU benchmarks under challenging W4A4 and W6A6 quantization regimes.
Key findings include:
- Accuracy Retention: For LLaMA-13B, RUQuant achieves 99.8% of the full-precision baseline with W6A6 and 97% with W4A4 quantization, without model fine-tuning.
- Compression Speed: Quantization of a 13B parameter model is completed in approximately one minute, matching alternative approaches such as DuQuant in runtime but exceeding them in accuracy.
- Speedup and Efficiency: RUQuant consistently yields 1.8×–2.1× prefill inference speedup and 3.3×–3.6× reduction in peak memory usage at batch size 1, without additional storage or inference-time latency penalties.
- Ablation Results: Removal of Householder steps destroys quantization fidelity (perplexity diverges), while removing Givens rotations yields modestly higher error. The final learnable Householder step can be omitted in latency-critical settings with minor loss (<0.01 perplexity increase).
Strong, consistent outperformance is observed against SmoothQuant, OmniQuant, QLLM, and DuQuant baselines across model classes and quantization levels.
Implications and Future Directions
RUQuant demonstrates that blending PTQ with problem-structured orthogonal transformations produces an efficient, scalable, and near-optimal quantization pipeline for LLMs. The approach operates fully post-training, eschewing additional model adaptation and sidestepping calibration or retraining constraints.
Theoretically, RUQuant’s Lloyd-Max-based analysis sharpens understanding of quantization error sources in deep neural nets, particularly regarding centroid-mismatch in non-uniform distributions. Practically, it enables deployment of high-parameter LLMs on commodity hardware with minimal compromise in effectiveness or speed. The orthogonal transformation paradigm is extensible—future work may integrate codebook-based or structured quantization schemes, targeting sub-4-bit deployments and augmenting memory savings.
Conclusion
RUQuant offers a robust, theoretically-grounded post-training quantization pipeline for LLMs, leveraging targeted orthogonal mappings to reconcile activation and weight distributions with uniform quantization grids. Its empirical results substantiate strong accuracy retention, runtime, and memory efficiency, signifying its applicability to wide-scale LLM deployments. The methodology provides a template for future advances in loss-minimizing, hardware-friendly quantized model architectures.
Reference: "RUQuant: Towards Refining Uniform Quantization for LLMs" (2604.04013)