- The paper introduces ReSpinQuant, which efficiently merges dense layer-wise rotations into LLM weights for effective low-bit quantization.
- It employs learnable orthogonal rotations and a novel subspace residual approximation to reduce computational complexity from quadratic to linear.
- Empirical results on LLaMA models show lower perplexity and minimal latency overhead, highlighting its practical deployment benefits.
ReSpinQuant: Efficient Layer-Wise LLM Quantization via Subspace Residual Rotation Approximation
Motivation and Context
Quantization is essential for deploying LLMs on resource-constrained hardware. However, activation outliers in Transformer layers lead to large quantization errors, particularly under aggressive low-bit settings (W4A4, W3A3). Prior art addressed this with rotation-based post-training quantization (PTQ), primarily employing either a single, global rotation (enabling offline fusion but with limited expressivity) or full layer-wise rotations (high accuracy at substantial online computational cost). This paper proposes ReSpinQuant, which reconciles the expressivity-efficiency trade-off by permitting full layer-wise rotation fused into weights for negligible inference overhead and resolves basis mismatch in residuals via a novel subspace residual rotation approximation.
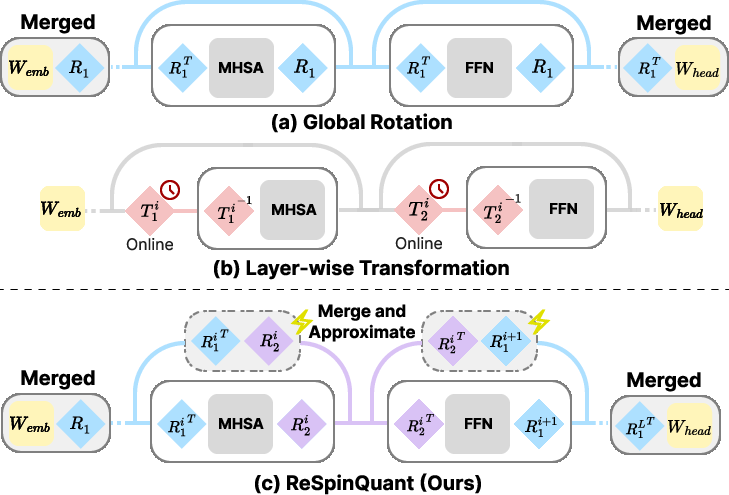
Figure 1: Comparison of rotation paradigms: global rotation (efficiency, limited expressivity), layer-wise rotation (expressivity, high overhead), and ReSpinQuant's solution achieving both.
Methodology
Layer-Wise Rotation with Offline Fusion
ReSpinQuant assigns unique learnable orthogonal rotation matrices to each quantization-sensitive sub-block within each layer (e.g., MHSA, FFN). These rotations are initialized using Hadamard matrices and optimized on the orthogonal manifold via the Cayley optimizer. To maintain inference efficiency, all rotation transformations applicable to linear blocks are fully merged into their corresponding weight matrices before deployment. This strategy retains the parameterization and flexibility of unconstrained, dense layer-wise transformations during the PTQ phase, while reverting the runtime cost to nearly that of global-rotation systems.
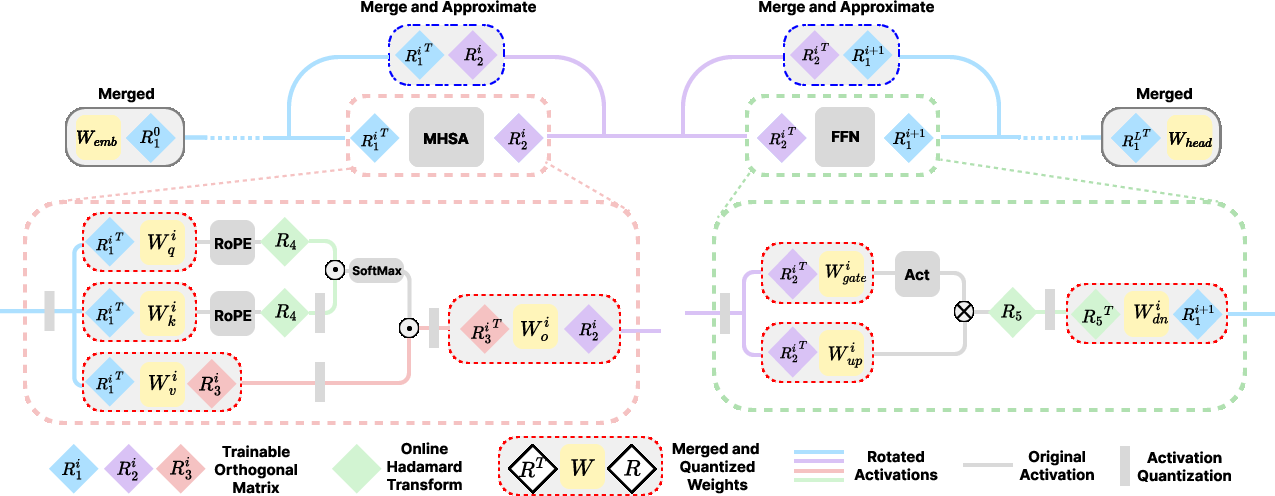
Figure 2: ReSpinQuant architecture, featuring per-layer rotation assignment, offline merging into weights, and subspace approximate rotation for residuals.
Subspace Residual Rotation Approximation
The key technical barrier is the basis mismatch in residual connections when distinct rotations are assigned to different blocks. Direct alignment would incur O(D2) complexity, prohibitive for large D. Empirical evidence shows that post-optimization, the layer-wise rotations deviate minimally from initialization, indicating that the residual misalignment matrix is numerically close to identity and dominated by low-rank structure.
ReSpinQuant exploits this observation by projecting the residual difference into a principal subspace (identified via SVD), performing the rotation only within this subspace, and re-projecting back. The resulting operation is mathematically a low-rank correction, reducing computational complexity from quadratic to linear in D.

Figure 3: Visualization of learned rotation matrix blocks and their relative transformation, displaying strong diagonal structure and low-rank deviation.
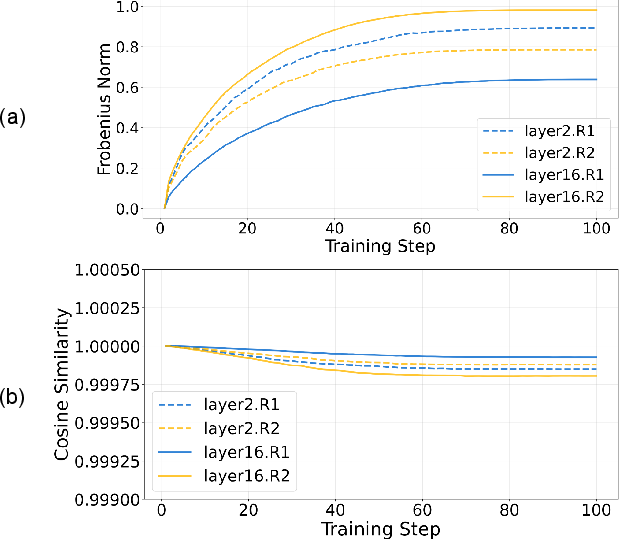
Figure 4: Training dynamics of rotation matrices: Frobenius deviation and cosine similarity confirm small, structured departures from initialization.
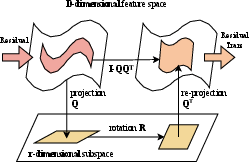
Figure 5: Subspace residual rotation approximation pipeline: project, rotate in subspace, and reproject for basis alignment with O(D) cost.
Empirical Results
Accuracy and Efficiency
ReSpinQuant is evaluated against RTN, GPTQ, QuaRot, SpinQuant, OSTQuant, and FlatQuant on the LLaMA2/3 series. It consistently outperforms the strongest global-rotation baseline (SpinQuant) and matches or exceeds the best layer-wise alternatives in both WikiText-2 perplexity and a nine-task zero-shot accuracy mean.
- On Llama-3 8B (W4A4): SpinQuant PPL is 7.50, while ReSpinQuant achieves 7.24.
- On Llama-3.2 1B (W3A3): SpinQuant PPL is 69.70, ReSpinQuant reduces this to 49.90, demonstrating much-improved robustness under extreme quantization.
The method maximizes train-time parameterization (e.g., $1091$M learnable parameters on Llama3-8B), with <0.1% of these active during inference; online overhead is reduced to ~0.2% of total MACs—comparable to global rotation methods. The reported latency increase versus global rotation is marginal: 1.7% TTIT latency overhead at batch size 16. Calibration completes within an hour even for 8B-scale models.
Ablative and Analytical Findings
An ablation on the subspace approximation rank r reveals that even very low ranks (e.g., r=32, ≪D) recover nearly full performance, supporting the low-rank nature of the basis mismatch. Increasing r yields diminishing returns and minimal accuracy differences (<0.3 PPL) past r=32.
Theoretical and Practical Implications
ReSpinQuant’s methodology demonstrates that fully expressive layer-wise rotation can be merged into static model weights provided that structured, numerically small mismatches are corrected in a principal subspace. Theoretically, this implies that the dominant error structure in rotation-aligned LLM activations is amenable to very efficient approximation. Practically, this design offers a scalable route to high-accuracy, low-bit quantization suitable for edge or low-resource deployment without the severe throughput penalty seen in prior layer-wise quantization schemes.
ReSpinQuant also shows a strong Pareto frontier shift: quantized larger models can exceed both the accuracy and memory footprint of full-precision smaller ones. This will likely enable more widespread adoption of quantized LLMs in bandwidth- and energy-limited applications.
Future Directions
The present work is focused on standard cross-entropy calibration for LLMs up to 13B scale. Integration with advanced, possibly layer-wise, calibration objectives may yield further accuracy improvements. Moreover, the development of dedicated hardware kernels for low-bit, low-rank subspace corrections would realize even greater deployment efficiency. Finally, extension to even larger-scale LLMs and more diverse architectures remains an open avenue.
Conclusion
ReSpinQuant resolves the longstanding expressivity-efficiency trade-off in post-training quantization by merging dense, layer-wise rotations into LLM weights and addressing residual basis mismatch via a subspace rotation approximation. It achieves state-of-the-art quantization performance with negligible inference cost, as experimentally validated across multiple LLM families and challenging quantization settings. This framework sets a new standard for efficient, accurate deployment of LLMs under aggressive resource constraints, with clear avenues for future methodological and practical enhancements.
Reference:
"ReSpinQuant: Efficient Layer-Wise LLM Quantization via Subspace Residual Rotation Approximation" (2604.11080)