- The paper introduces a co-optimized weight pooling approach that achieves over 14.8x compression while preserving near-lossless accuracy.
- It employs algorithm-hardware co-design with structured error correction and efficient permutation scheduling to effectively map weights onto SRAM arrays.
- Empirical results on ResNet and CIFAR benchmarks demonstrate significant area (up to 62.3% reduction) and energy savings (3.24x reduction) for diverse models.
CIMPool: Scalable Neural Network Acceleration for Compute-In-Memory using Weight Pools
Problem Statement and Motivation
Contemporary SRAM compute-in-memory (CIM) accelerators alleviate the Von Neumann bottleneck by colocating memory and computation, thus enabling efficient neural network inference. However, the inherent area limitations of SRAM restrict the on-chip deployment of modern, large-scale neural networks. Existing compression techniques such as quantization and pruning, even when CIM-aware, remain limited in achievable compression ratio and often introduce untenable hardware overheads. The CIMPool framework introduces a structurally co-optimized compression and acceleration paradigm, leveraging weight pooling with algorithm- and hardware-level enhancements, to address memory constraints without sacrificing accuracy or throughput.
Weight Pool Compression and Optimizations
The core compression technique in CIMPool is weight pool-based sharing, wherein a set of quantized prototype vectors form a codebook from which the model weights are derived by reference, leading to substantial redundancy removal and associated compression benefits.
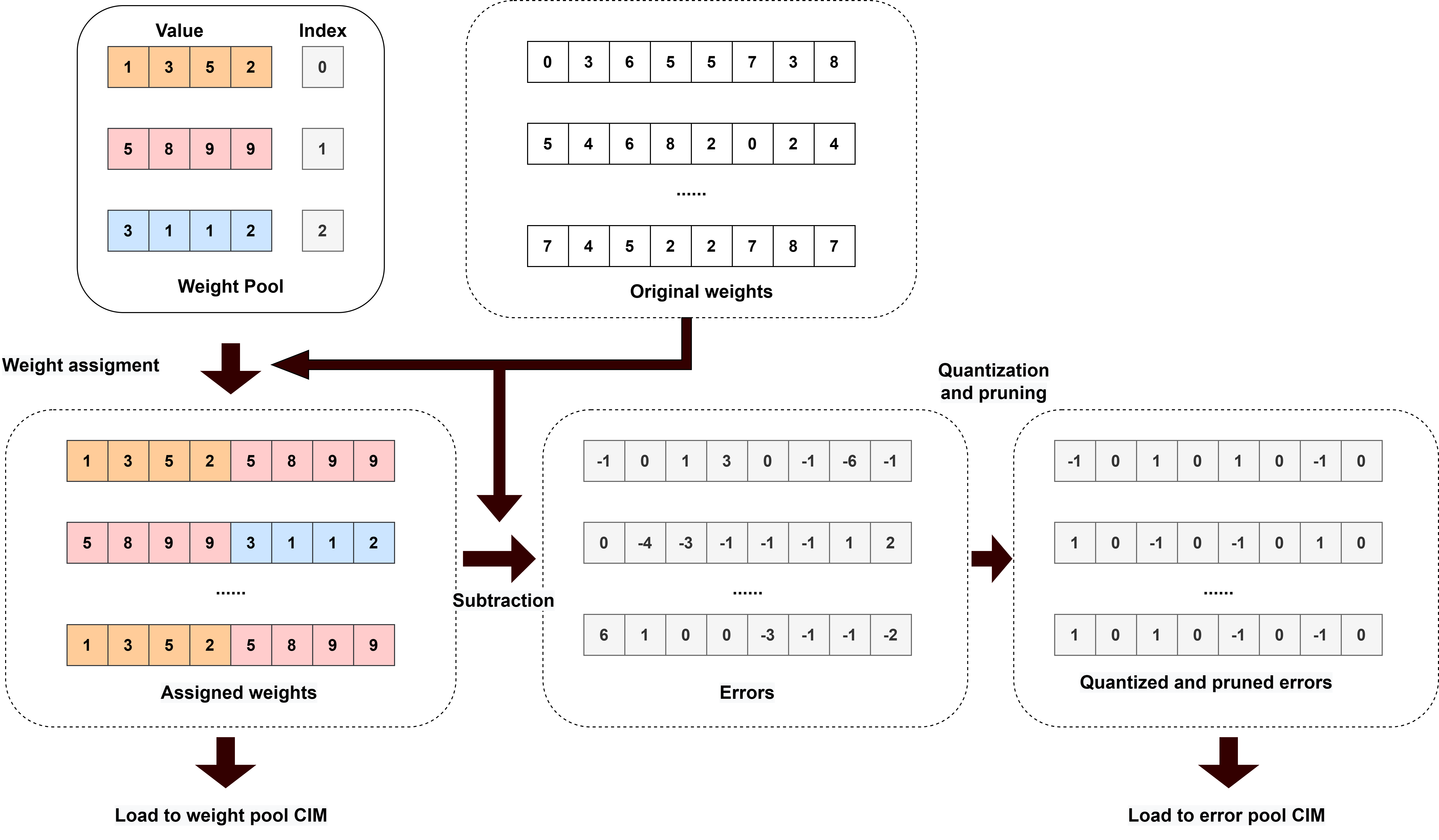
Figure 1: Visualization of weight pool compression, demonstrating the remapping of model weights to shared vectors for highly efficient representation.
This weight pool mechanism is CIM-optimized by setting both the vector dimension and the pool size to match typical SRAM array dimensions (e.g., 128×128), ensuring full array utilization.
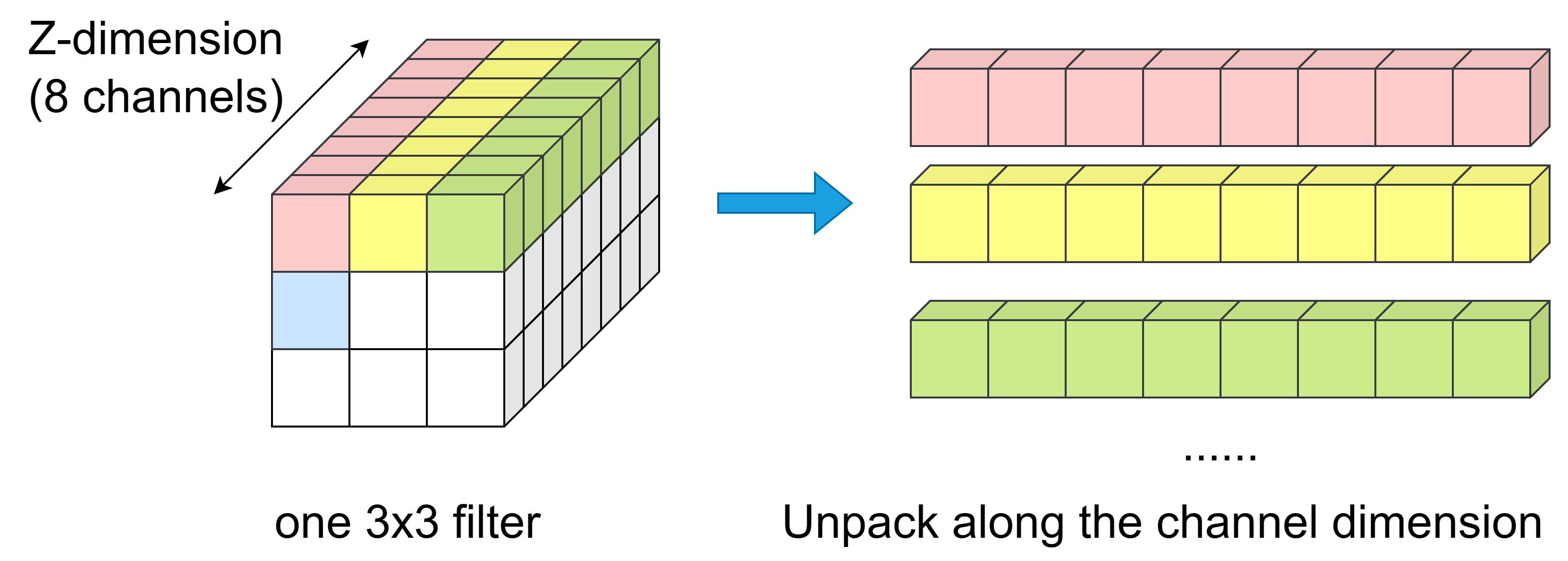
Figure 2: Weight vectors are formed by packing original neural weights along the channel (Z) dimension, ensuring efficient mapping onto CIM architecture.
A naïve increase in vector size degrades accuracy substantially. CIMPool introduces a residual error term to overcome this:
- Each original weight is reconstructed as Wrc=Wwp+Eq, where Wwp is the quantized weight-pool vector, and Eq a robust, quantized error term.
- With statistical tuning, a single-bit representation (with scaled magnitude) for each error term retains accuracy with minimal storage.
- Error pruning is performed structurally: only selected error locations retain a residual, with the pattern fixed per layer, eliminating per-weight masks and further minimizing hardware costs.
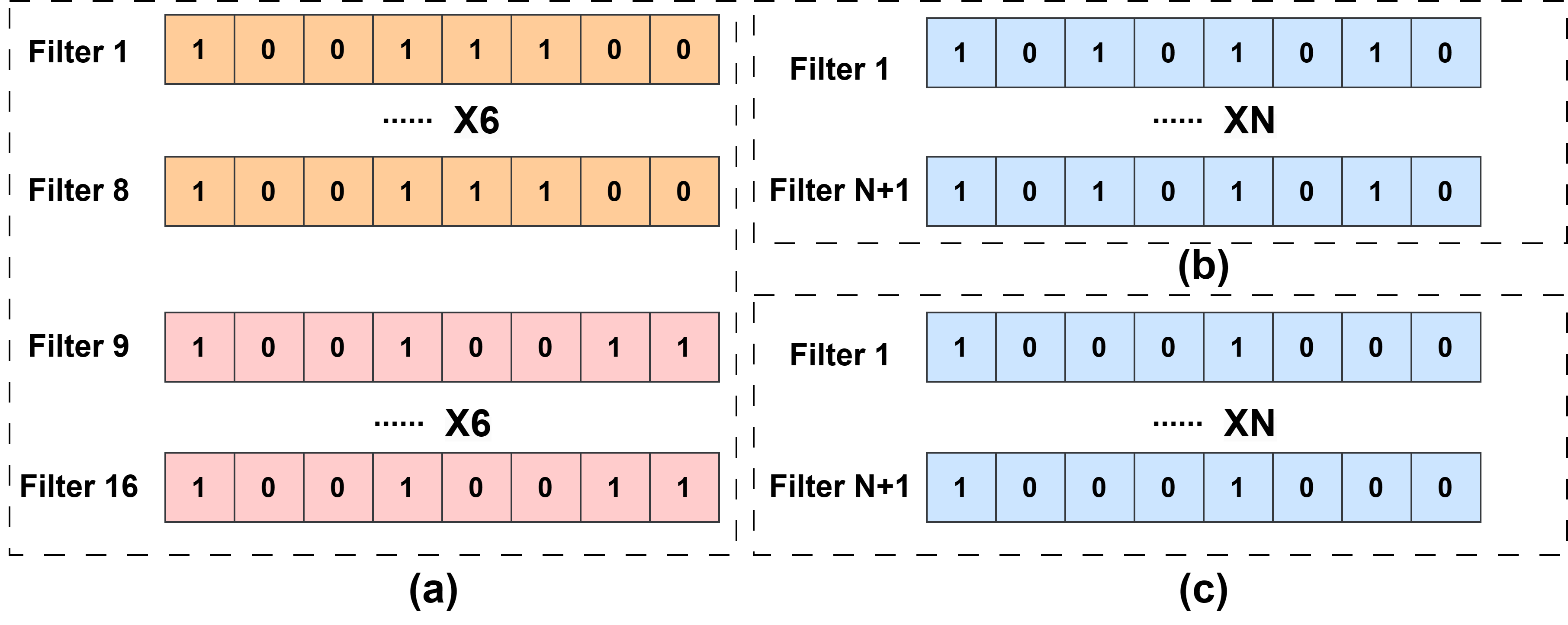
Figure 3: (a) Conventional semi-structured pruning introduces non-uniform zero masks and hardware overhead; (b,c) CIMPool adopts highly regular, structured pruning patterns, facilitating efficient hardware realization.
Notably, the co-design ensures that in CIMPool, every group of weights scheduled together is mapped to a unique prototype vector, preventing array underutilization.
System Co-Design: Dataflow, Hardware Scheduler, and Permutation
Critical to deploying weight-pool-compressed models on CIM is the restoration of data ordering post computation, as weight pooling disrupts the canonical correspondence between logical and physical indices.
- CIMPool’s architecture involves two SRAM CIM arrays (weight-pool and error arrays), and a streamlined hardware permutation scheduler.
- The hardware scheduler leverages the bit-serial processing nature of SRAM CIM: output permutations are performed in parallel across buffered output vectors, enabling cycle-efficient reordering.
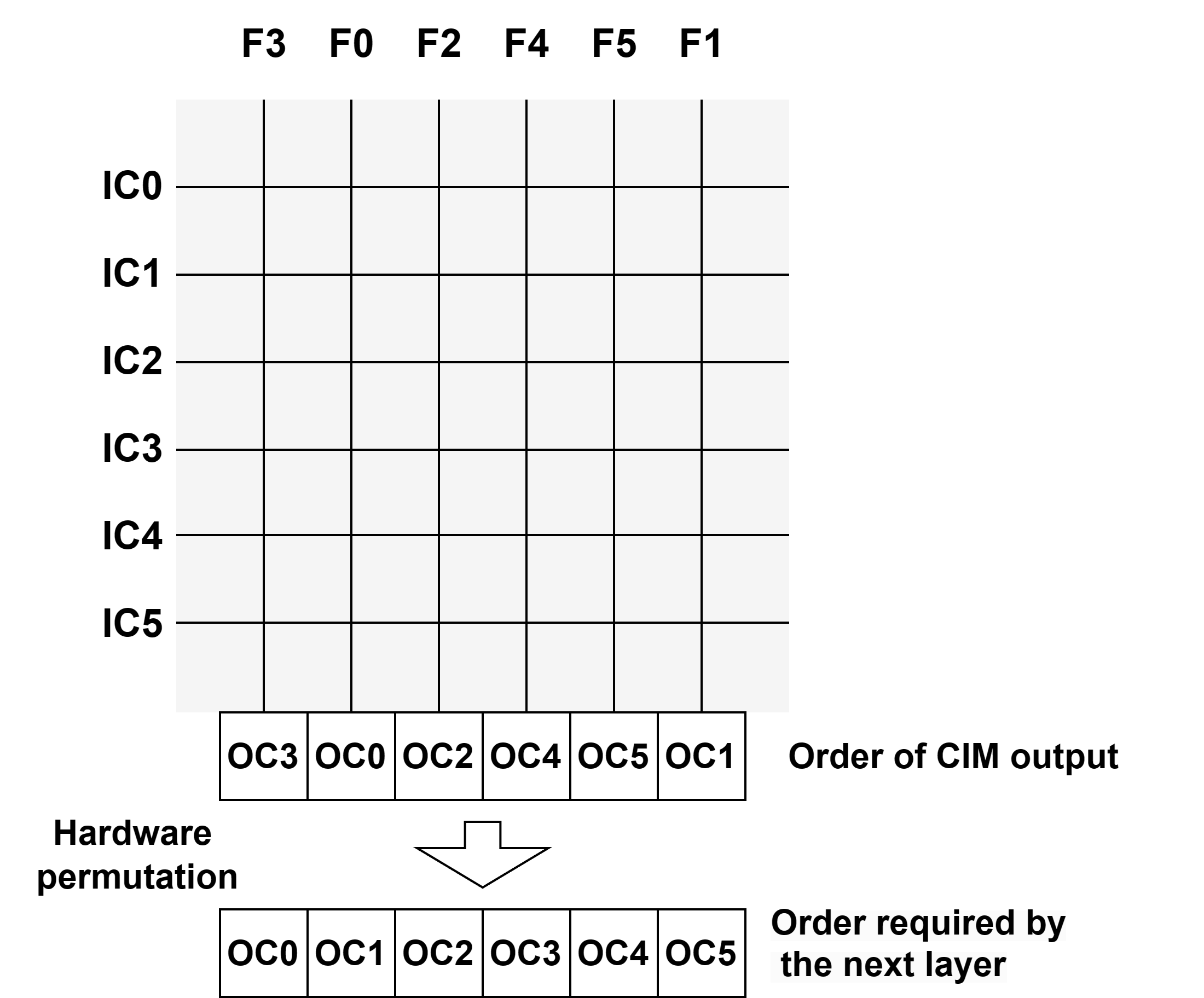
Figure 4: The necessity and mechanism of permuting CIM outputs to restore correct inter-layer channel connectivity post weight-pool assignment.
- Output buffers and channel grouping further optimize permutation overhead, significantly reducing area and initialization delay, with careful group size selection balancing accuracy and system performance.
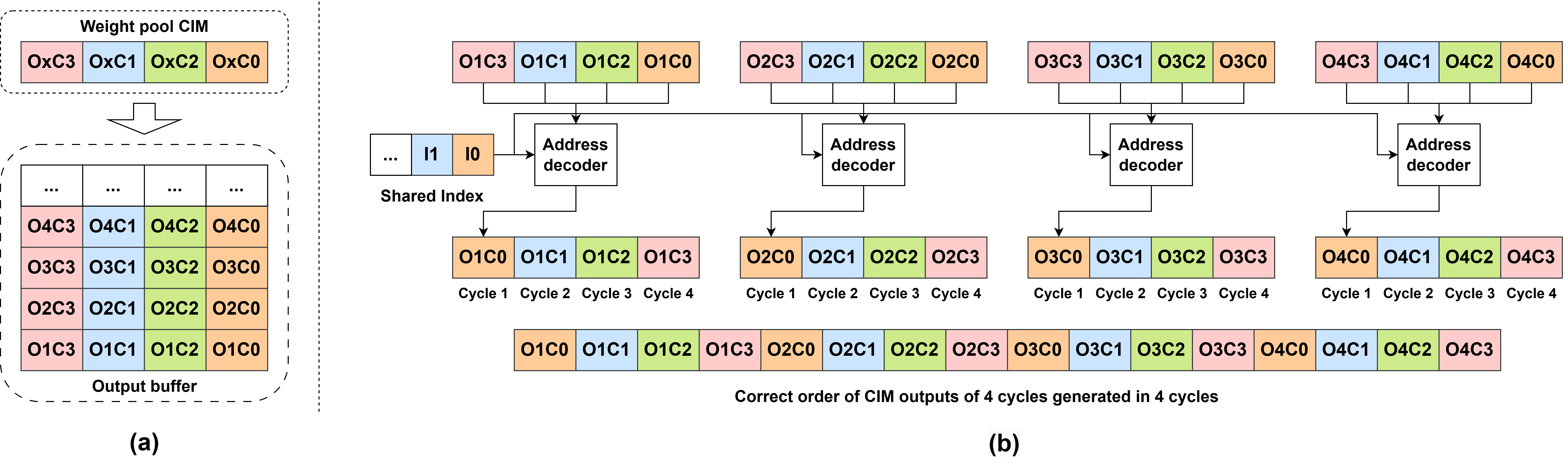
Figure 5: Parallel scheduling and permutation using grouped output buffers ensure throughput is preserved during the hardware permutation process.
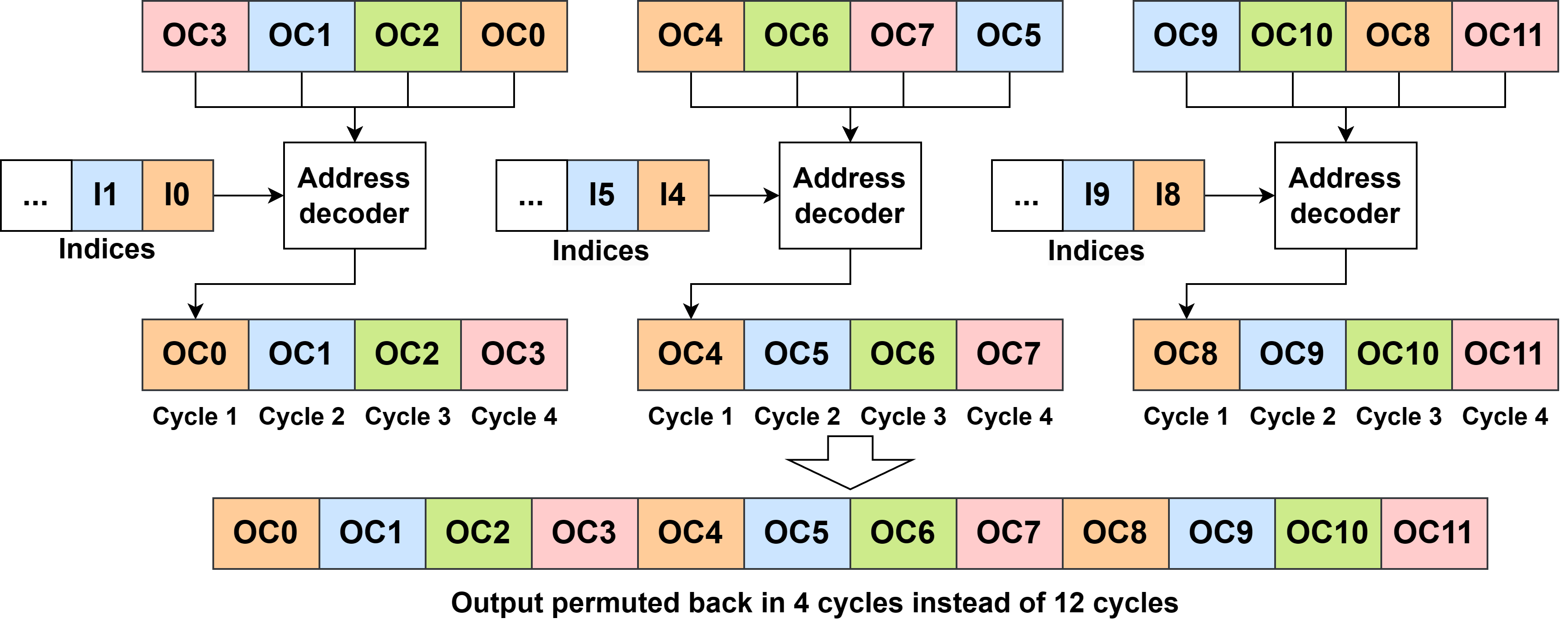
Figure 6: Circuit-level illustration for grouped permutation, facilitating efficient realization for wide weight-pool arrays.
Through these mechanisms, CIMPool systematically addresses the principal CIM implementation bottlenecks arising from compression-induced output disorder.
Empirical Evaluation
CIMPool is evaluated on ResNet-18 and ResNet-34 across CIFAR-10, CIFAR-100, and Food-101. The framework demonstrates:
- Near-lossless accuracy at compression ratios exceeding 14.8× (w.r.t. 8-bit models), outperforming prior structured/compressed CIM baselines.
- With Food-101, 8-bit quantization accuracy is matched with 27.7× compression; further compression (up to 48.8×) is feasible with minimal accuracy penalty.
- Significant reduction in chip area: for ResNet-18, area is reduced by 62.3% versus iso-accuracy 4-bit baselines. For fixed area budgets, supported model sizes scale nearly an order-of-magnitude larger.
- When weights reside in DRAM, inference energy is reduced by 3.24× due to reduced traffic and computation costs.
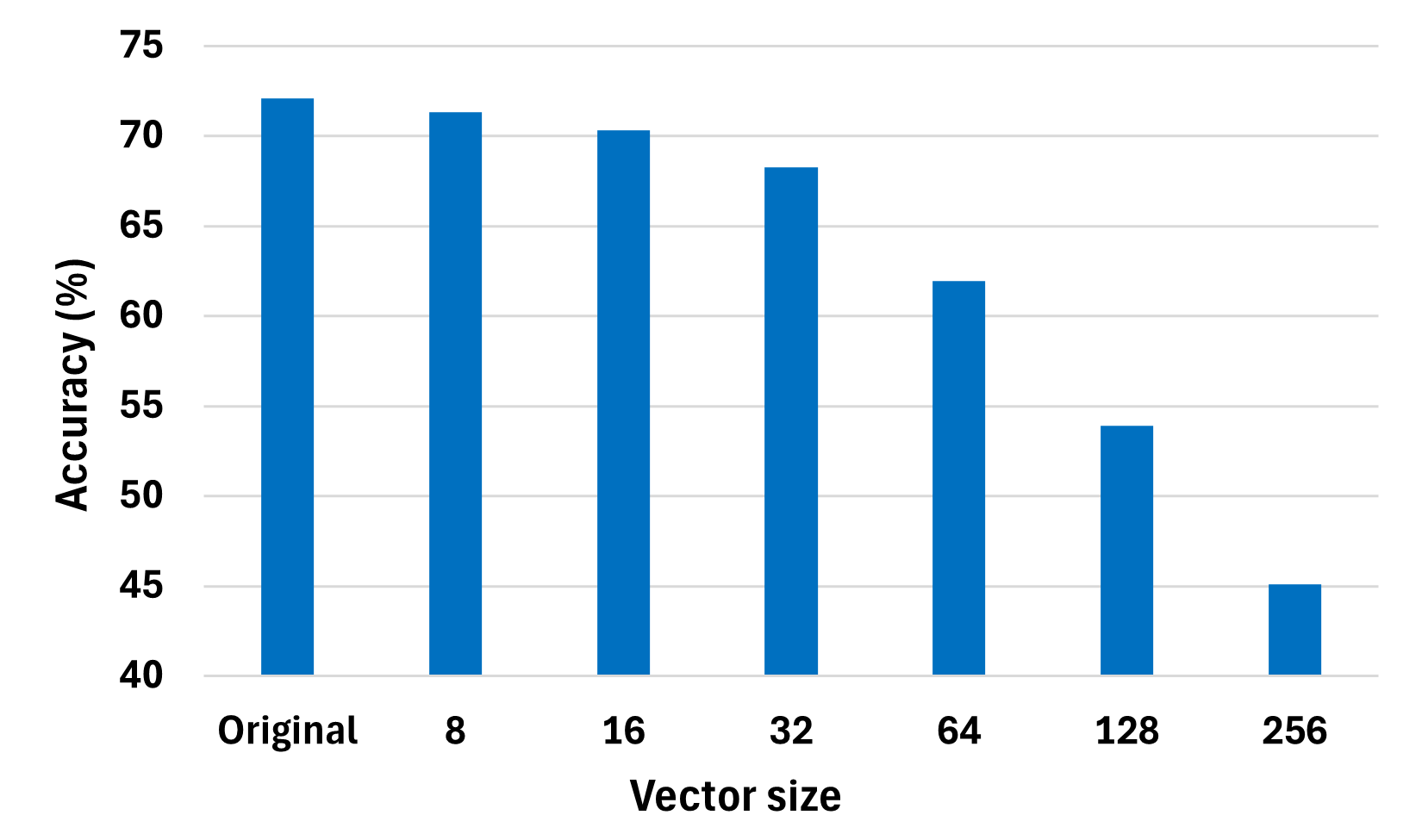
Figure 7: Empirical accuracy vs. vector size of weight pool compression on ResNet-18/CIFAR-100, demonstrating how aggressive pooling degrades accuracy without corrective error terms.
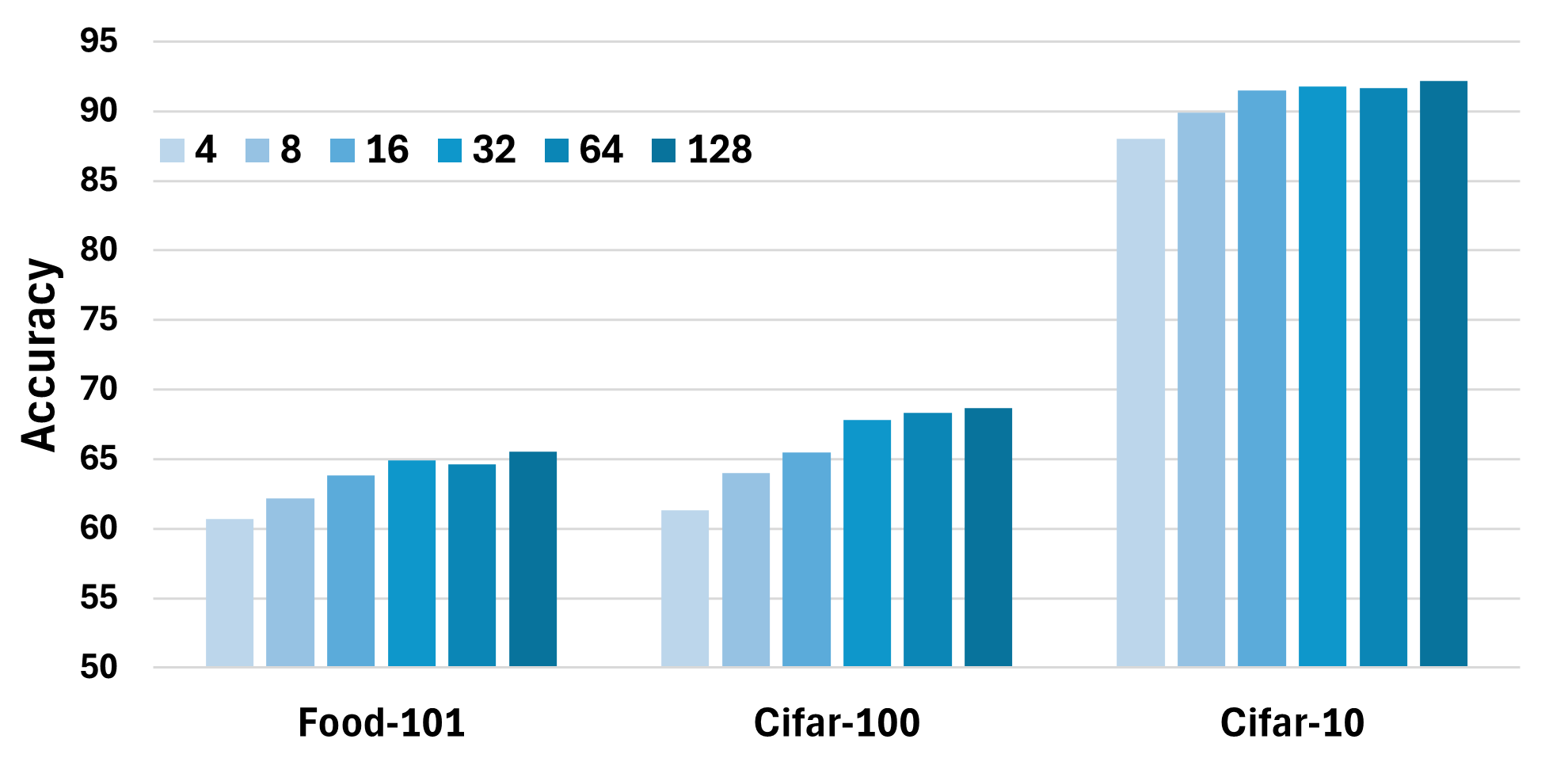
Figure 8: Accuracy as a function of group size and error term sparsity, evidencing optimality at moderate grouping with negligible accuracy impact at high compression.
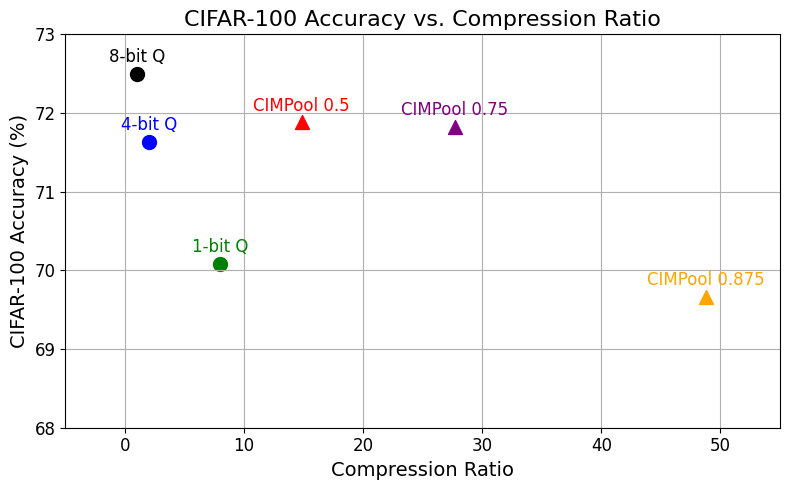
Figure 9: CIFAR-100/ResNet-34 accuracy versus compression ratio, showing CIMPool’s dominance over quantization and earlier compression schemes for a broad spectrum of accuracy targets.
Theoretical and Practical Implications
CIMPool advances the state of CIM-aware neural network compression:
- By algorithm/hardware co-design, array underutilization, hardware permutation, and dataflow inefficiencies are systematically mitigated.
- The method’s area, energy, and performance gains position CIMPool as a practical enabler for on-chip deployment of large-scale DNNs, previously excluded due to SRAM constraints.
- The fixed, binarized nature of weight pools further opens deployment avenues on emerging non-volatile CIM substrates, contingent on an SRAM-based error array.
- The observed empirical resilience to aggressive compression (via structural error pruning and vector sharing) suggests new research directions in overparameterized, ultra-compact neural architectures for embedded inference.
Conclusion
CIMPool establishes a scalable, efficient framework for deploying large neural networks in compute-in-memory inference hardware by unifying weight-pool-based compression and hardware-conscious design. Significant compression ratios and strong accuracy retention are demonstrated, along with dramatic area and energy reductions. CIMPool’s mechanisms—weight pooling with integrated error correction, structured pruning, and optimized hardware permutation—define a robust, extensible template for future CIM accelerators targeting edge and low-power inference applications. The approach sets a new reference point for the combined model/hardware co-optimization in SRAM CIM research.

