- The paper introduces a hardware-software co-design that leverages compute-in-memory to optimize the GEMV-dominated decoding phase in small language models.
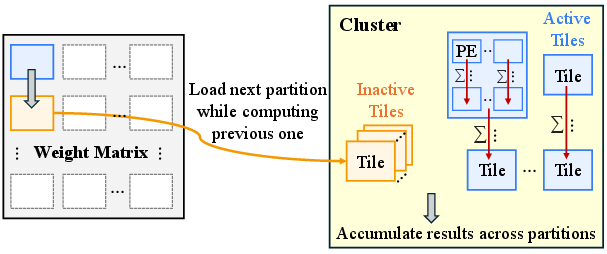
- It employs an active-tile pipelined mapping strategy and a genetic DSE framework to balance memory transfers with computation, significantly improving throughput.
- Experimental results show up to 9.95× throughput gains and 49.59× energy efficiency improvements over conventional edge accelerators.
EdgeCIM: A Hardware-Software Co-Design Approach for Compute-in-Memory Acceleration of Small LLMs on the Edge
Introduction and Motivation
Deployment of Small LLMs (SLMs) on resource-constrained edge devices necessitates significant advancements in hardware acceleration, particularly for decoder-only transformer architectures employed in interactive inference workloads. The bottleneck stems from the GEMV-dominated autoregressive decoding phase, where memory bandwidth and energy consumption overshadow matrix-matrix multiplication-dominated prefill stages. Conventional accelerators—GPUs/NPUs—offer insufficient GEMV throughput and poor energy scaling due to underutilization and frequent DRAM accesses. "EdgeCIM: A Hardware-Software Co-Design for CIM-Based Acceleration of Small LLMs" (2604.11512) introduces a novel, end-to-end CIM-based accelerator architecture and a hardware-software co-optimization framework primarily designed to optimize decoder-only SLM inference on edge platforms.
Decoder-Only Inference Characteristics
Autoregressive SLMs divide inference into two distinct phases: a GEMM-heavy prefill and a memory-bound, sequential GEMV-based decoding. Profiling demonstrates that, under typical edge scenarios (batch size = 1), the decoding phase can account for more than 70–96% of the total inference latency. This is a direct result of recurring off-chip Key-Value (KV) cache fetches, minimal data reuse, and the inherently sequential nature of token generation.
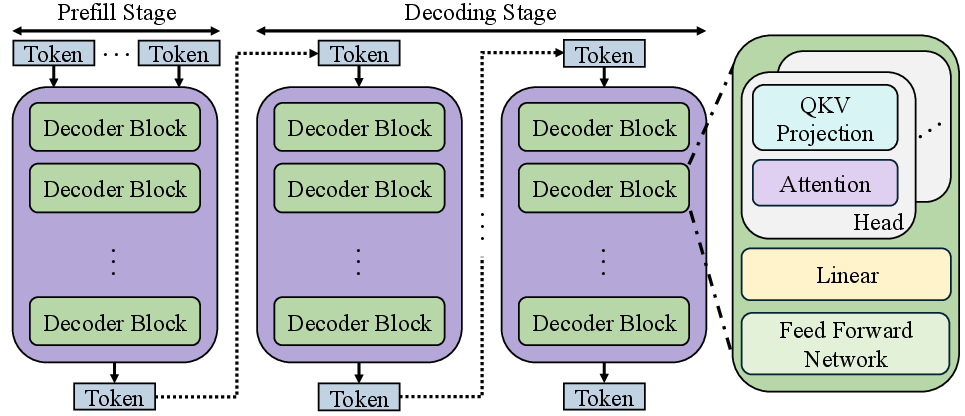
Figure 1: Inference process in decoder-only SLMs, highlighting the sequential decoding bottleneck.
CIM Accelerator Architecture and EdgeCIM Framework
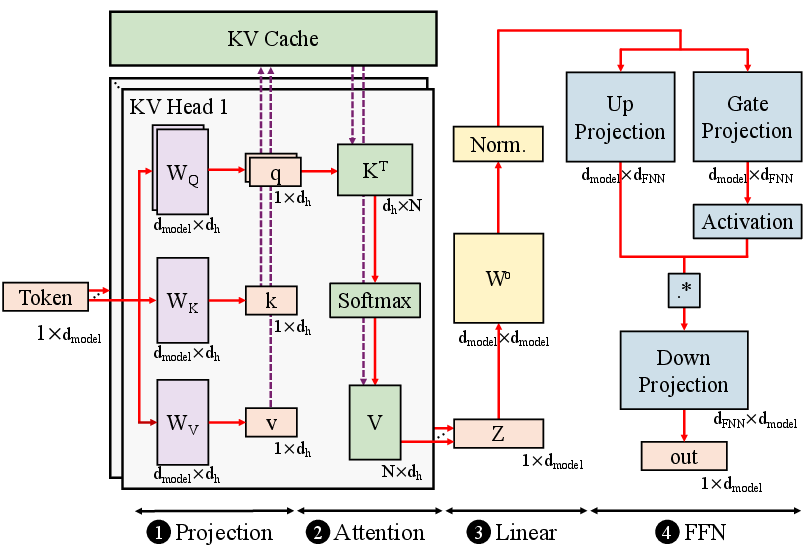
The core of the EdgeCIM system is a hierarchical, tiled digital SRAM-based DCIM macro array. The macros operate in bit-serial input mode, supporting flexible INT4/INT8 quantization to maximize energy efficiency and maintain accuracy, exploiting the robustness of transformer quantization. The accelerator design incorporates several architectural features:
- Tiled hierarchy consisting of clusters, tiles, and PEs, with a configurable number of elements exposed to design space exploration (DSE).
- Weight-stationary mapping to optimize for MAC operation reuse and minimize costly data movement.
- Dedicated functional units for auxiliary operators (activation, normalization, quantization, Softmax).
- Hierarchical 2D mesh interconnect for scalable intra- and inter-tile/cluster data traffic.
- Partitioned on-chip buffering and prefetching, explicitly addressing the DRAM bandwidth bottleneck.
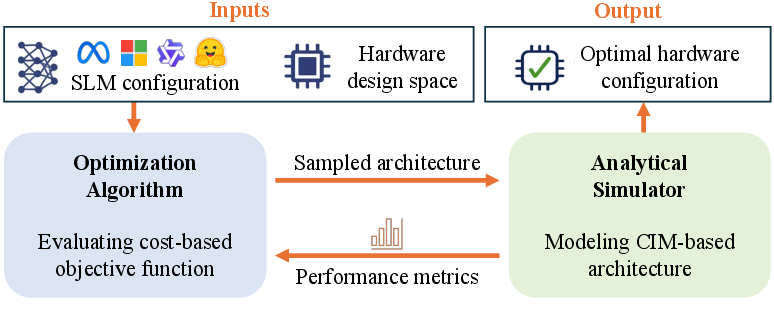
Figure 3: The EdgeCIM co-design framework encompassing optimization and simulation.
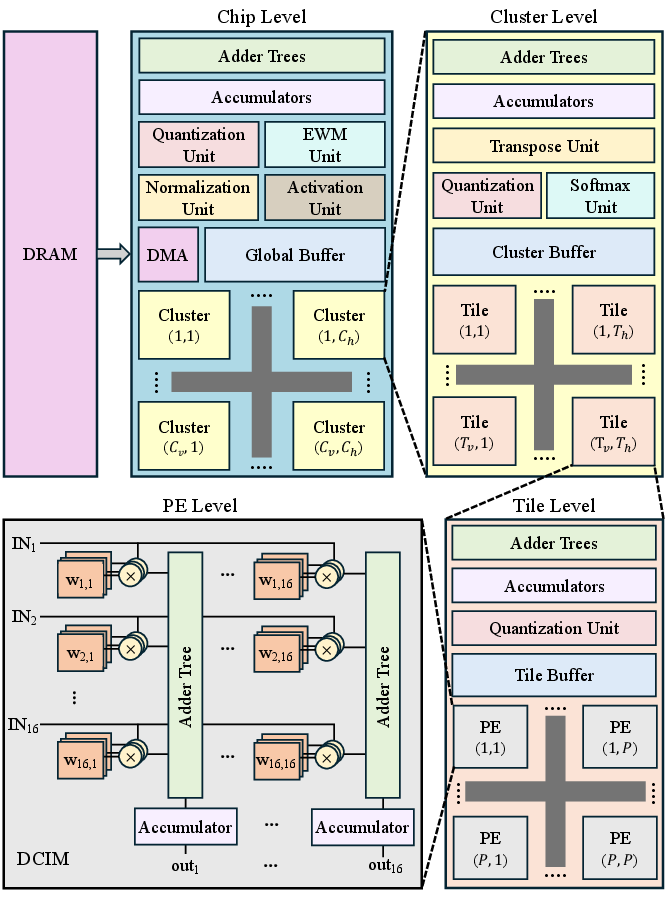
Figure 2: High-level architecture of EdgeCIM, illustrating hierarchical clusters, tiles, and specialized units.
SLM Dataflow Mapping and Pipeline Optimization
EdgeCIM introduces an active-tile pipelined mapping strategy. Here, only a tunable subset of tiles participates in computation per partition, allowing memory transfers (preloading of weights/KV cache) for inactive tiles to overlap with GEMV stages, thus balancing parallelism against off-chip bandwidth.
Hardware-Software Co-Optimization and Genetic DSE
A genetic algorithm-based DSE framework is used to automatically select optimal architectural parameters based on a weighted energy-latency cost function:
h∈HminL(h)α⋅E(h)1−α
where L and E represent latency and energy, and α controls the trade-off. The design space is parametrized over cluster, tile, PE counts, active tiles, and bus widths. The DSE leverages analytical models calibrated with CACTI and HSPICE (65nm), and extensive cross-layer modeling of data movement.
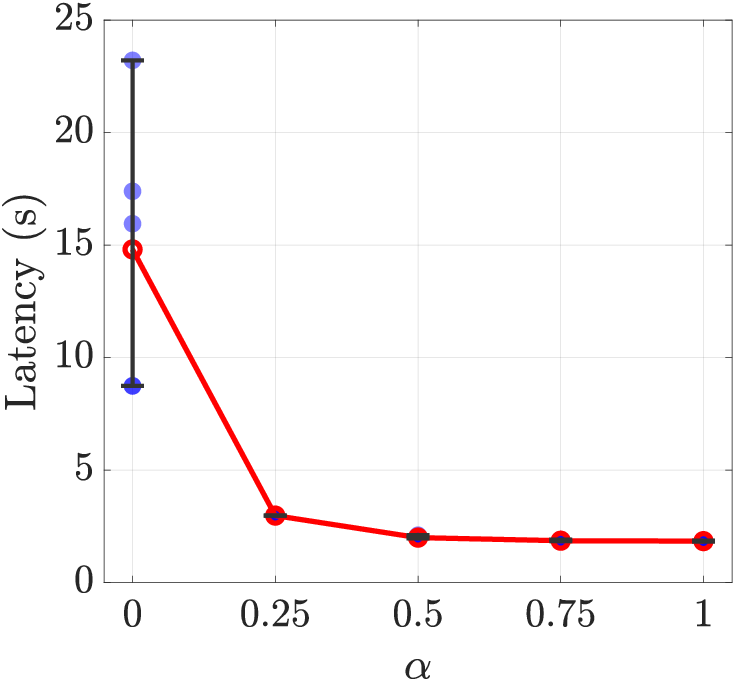
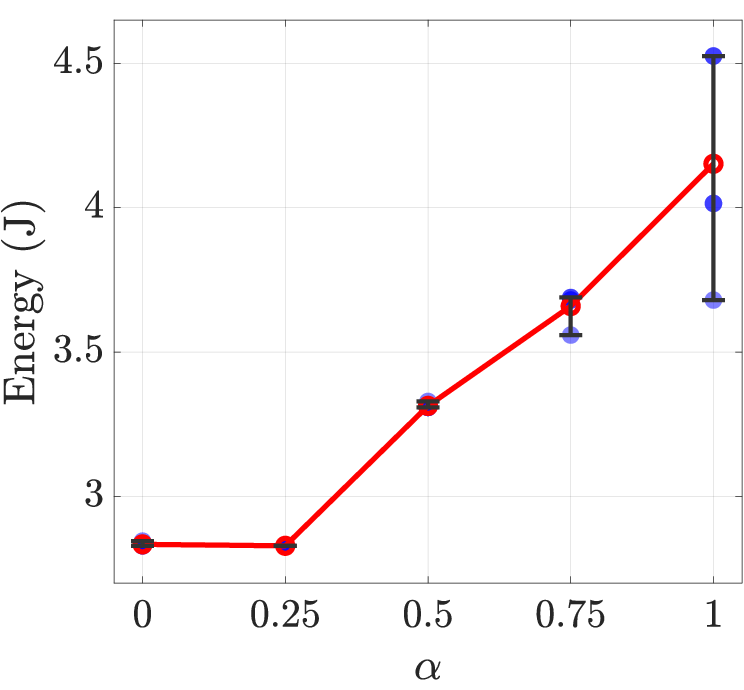
Figure 6: Energy-latency trade-off curve for LLaMA3.2-3B under varying α (cost function emphasis).
Experimental Results and Benchmarking
EdgeCIM was evaluated on a diverse suite of SLMs (e.g., TinyLLaMA-1.1B, LLaMA3.2-1B/3B, Phi-3.5-mini-3.8B, Qwen2.5-0.5B/1.5B/3B, SmolLM2-1.7B, SmolLM3-3B, Qwen3-0.6B/1.7B/4B) at INT4/INT8 precisions.
Key numerical results:
- Under INT4 quantization, average throughput of 336.42 tokens/s and 173.02 tokens/J across models.
- On LLaMA3.2-1B, throughput improvements of 7.3× and energy efficiency improvements of 49.59× over NVIDIA Orin Nano.
- On LLaMA3.2-3B, achieves 9.95× the throughput of Qualcomm SA8255P.
- For smaller SLMs (Qwen2.5-0.5B), exceeds 1000 tokens/s at over 600 tokens/J.
Throughput and energy efficiency versus sequence length and prefill tokens are characterized, showing the expected cost scaling for increasing output sequence length due to sequential autoregressive generation.
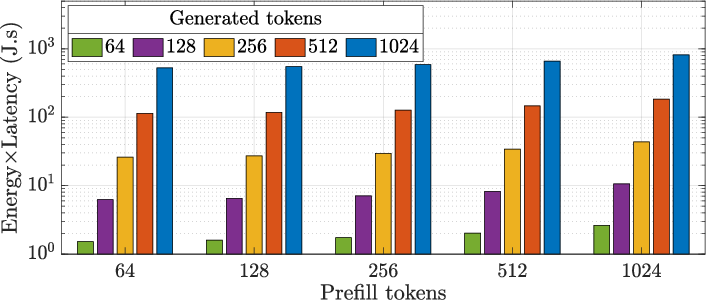
Figure 7: Decoding energy-latency product scaling with prefill/generated tokens.
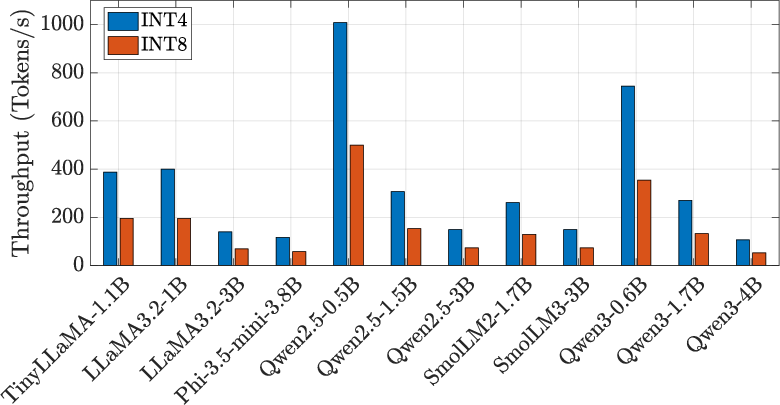
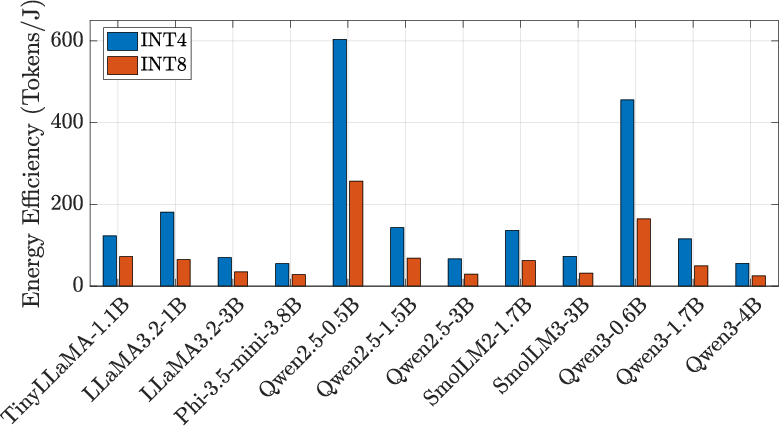
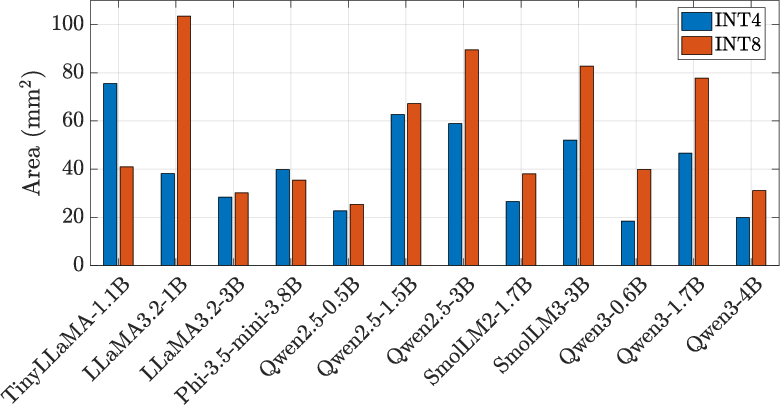
Figure 8: Throughput, energy efficiency, and area results for a range of SLMs under INT4/INT8 precision.
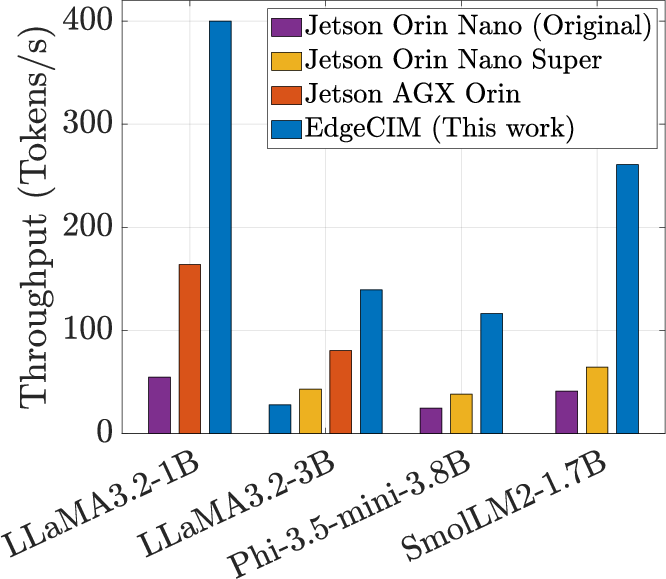
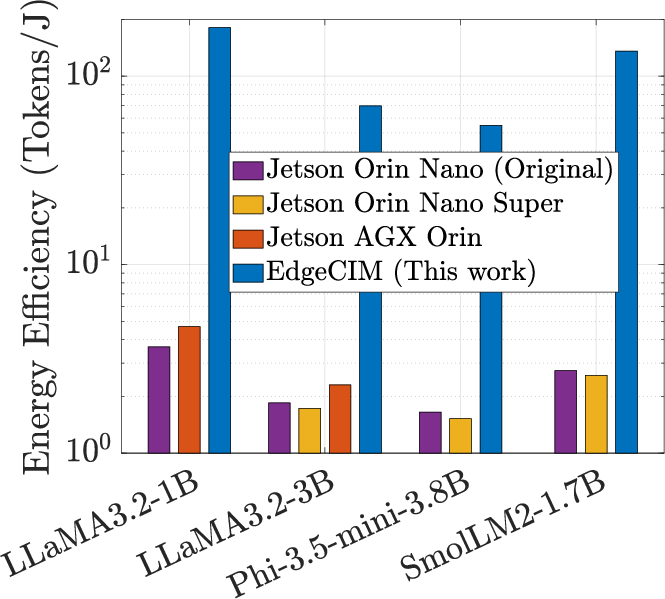
Figure 9: Comparative throughput and energy efficiency for EdgeCIM versus NVIDIA Jetson GPUs (INT4).
Comparison with Prior Work and Architectural Implications
Unlike previous CIM accelerators (X-Former, TranCIM, ReTransformer, iMTransformer) that targeted encoder-style kernels or isolated attention submodules, EdgeCIM is explicitly designed and optimized for end-to-end decoder-only, GEMV-dominated pipelines as deployed at the edge. The co-design and DSE framework yield normalized efficiency as high as 7.03 TOPS/W/mm²—substantially higher than prior CIM architectures supporting only partial or encoder-based inference paths.
The systematic pipeline and partitioning design, active-tile pipelining, and bandwidth-latency optimization are essential for sustaining high throughput/efficiency in a setting where DRAM bandwidth is the principal limiting factor. Area results (18.4–103.6 mm² for optimal configs) are well within the constraints of commodity edge silicon.
Implications and Future Directions
The study demonstrates that targeted co-design approaches—where both the SLM dataflow and the hardware microarchitecture are jointly optimized—yield significant gains under edge localization, energy, and latency constraints. This work provides strong evidence for a migration away from general-purpose NPU/GPU fabrics toward CIM-centric, fine-grained pipelined architectures for edge NLP inference. The active-tile and partition-based mapping can be generalized to other non-GEMM, memory-bound workloads that emerge in transformer and non-transformer models.
Future avenues involve: extending the framework to multi-modal SLMs, supporting incremental/on-device training, applying similar DSE-driven co-design to encoder-decoder or multi-batch inference, and integrating adaptive runtime scheduling for variable precision and dynamic memory-aware execution.
Conclusion
EdgeCIM establishes a systematic, co-designed methodology and hardware architecture for maximizing both throughput and energy efficiency for decoder-only SLMs on edge platforms. By explicitly focusing on GEMV-dominated phases, employing highly-configurable DCIM macros, and thoroughly exploring the latency-energy-area optimization space, substantial gains over state-of-the-art edge GPUs and prior CIM accelerators are demonstrated. These findings pave the way for highly performant and energy-scalable edge SLM deployments across a range of resource-constrained environments.