- The paper presents Q-Gate, a training-free, query-aware MoE framework that dynamically selects keyframes to capture both visual and narrative details in long videos.
- It leverages parallel expert streams for visual grounding, global matching, and contextual alignment to adaptively suppress modal noise and enhance relevance.
- Empirical evaluations on Video-MME and LongVideoBench demonstrate significant accuracy gains with minimal latency overhead, validating its efficiency and robustness.
Query-Modulated Multimodal Keyframe Selection for Long Video Understanding
Long video understanding with Multimodal LLMs (MLLMs) is fundamentally limited by computational and context window constraints. Prior approaches for keyframe selection typically rely on static multimodal heuristics or vision-centric similarity metrics, but these fail in queries requiring nuanced narrative understanding or in the presence of modal noise from irrelevant subtitles. The critical question is: How can systems dynamically and efficiently select the most semantically salient frames for diverse user queries, ensuring maximal relevance across both visual and narrative dimensions?
Q-Gate Framework: Dynamic MoE Query Routing
The work introduces Q-Gate, a training-free, plug-and-play framework that reframes keyframe selection as a zero-shot mixture-of-experts (MoE) routing problem. Rather than statically fusing visual and textual features, Q-Gate deploys parallel expert streams for three distinct evidence granularities:
- Visual Grounding (object-level, fine-grained, YOLO-World-based)
- Global Matching (scene/semantic, BLIP2-based)
- Contextual Alignment (dialogue-driven, sentence embedding)
A LLM, acting as a query-aware gating module, performs in-context reasoning on the user query, dynamically allocating attention weights to each expert stream (Figure 1).
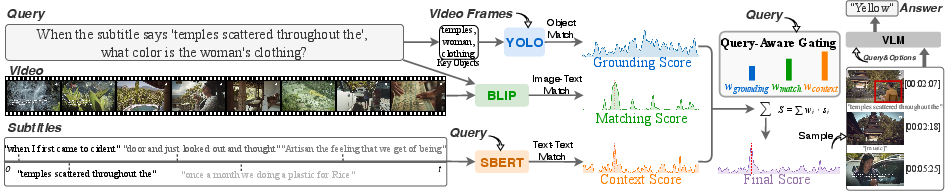
Figure 1: Overview of the Q-Gate framework, illustrating expert stream fusion modulated by query semantics to optimize modality selection for keyframe sampling.
Crucially, a unified scoring and normalization pipeline ensures comparability among modalities, with a masked temperature softmax suppressing spurious activations—especially critical in sparse narrative streams. The output is a relevance-ranked score distribution used to select temporally-aligned keyframes and, optionally, their associated subtitles for downstream VLM processing.
Empirical Evaluation and Numerical Findings
Q-Gate is benchmarked on LongVideoBench and Video-MME, two challenging long video QA datasets with dense scene and subtitle annotation, across GTP-4o and Qwen3-VL-32B-Instruct backbones. The evaluation is controlled for frame budget (K = 8, 32) and compared against strong single-modality and logic-driven baselines such as AKS, VSLS, and iterative search (T).
Key results:
- On Video-MME (Long), Q-Gate achieves 61.19% accuracy with K=32 on Qwen3-VL, outperforming AKS* by +6.40%—a decisive margin and consistent across budgets and backbones.
- On LongVideoBench (Long), Q-Gate reaches 59.40% (K=32), rivaling or exceeding large-scale 72B parameter models (e.g., LLaVA-OneVision-72B with 256 frames).
- Ablation shows that removal of the Contextual Alignment stream induces a sharp performance collapse (e.g., from 59.40% to 54.08%), verifying that existing static visual methods are insufficient for narrative reasoning.
- Replacing dynamic LLM gating with static fusion causes up to 14.92% accuracy loss on visually anchored tasks, confirming strong negative cross-modal transfer if modal noise is not actively suppressed.
Analysis of Gating Behavior and Interpretability
Q-Gate's LLM reasoning is shown to be highly interpretable and matches human cognitive patterns:
- For detail-sensitive queries (object counts, attributes), the gating module allocates maximal weight to Visual Grounding.
- Thematic or action-centric queries (scene understanding) elicit weight shifts toward Global Matching.
- Subtitle-anchored or causal queries prompt a dominant allocation to Contextual Alignment, in some settings exceeding 50% stream allocation (Figure 2).
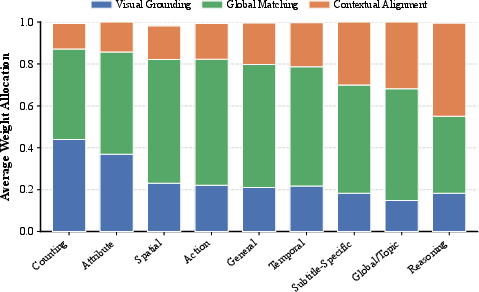
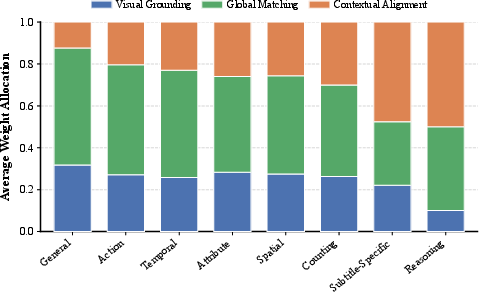
Figure 2: Q-Gate adaptively shifts modal attention from visual granularity to narrative context as query abstraction and reasoning demand increases.
Qualitative cases illustrate this dynamic adaptation with clear evidence suppression of irrelevant modalities (Figure 3).
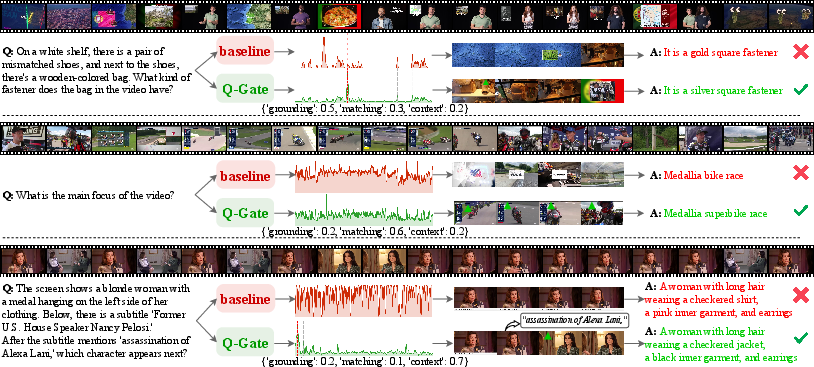
Figure 3: For object-centric questions, Q-Gate elevates the grounding stream, for thematic questions it promotes global matching, and for dialogue-driven queries it prioritizes narrative context.
Robustness, Ablations, and Efficiency Trade-Offs
Q-Gate's gating strategy is model-agnostic: Open-source LLMs (Qwen3) can be substituted for GPT-4o with negligible loss for larger frame budgets, making the framework practical and privacy-preserving.
Ablative analyses show the necessity of every scoring stream—removing any stream yields significant loss. The softmax temperature τ for normalization is optimal at 0.5: lower values induce one-hot bias (reducing temporal coverage), higher values over-smooth (diluting critical signals).
Efficiency analysis demonstrates a new Pareto frontier in accuracy vs. latency: Q-Gate adds only 1.35% overhead versus the strongest baseline while delivering substantial accuracy gains for small K, directly addressing the primary bottleneck in long video MLLMs.
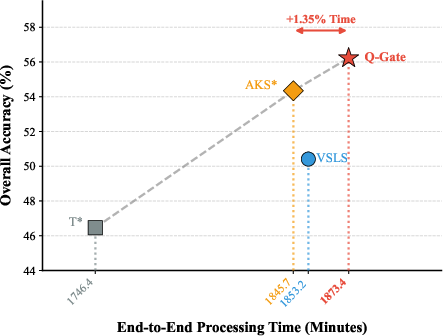
Figure 4: Q-Gate significantly pushes the accuracy/latency Pareto frontier with minimal computational cost.
Practical and Theoretical Implications
Pragmatically, Q-Gate offers:
- Robust, interpretable, and dynamic modality selection for video QA and reasoning, outperforming both visual-only and static fusion baselines, especially in complex, narrative-heavy data regimes.
- Plug-and-play design with immediate applicability to existing MLLM workflows without retraining or architecture modification.
- Flexibility for inference-time trade-offs (accuracy, latency, privacy).
Theoretically, the framework demonstrates:
- The necessity and tractability of decoupling multimodal evidence at multiple granularity scales, with LLM-driven intent understanding outperforming both rule-based and fixed-weighted approaches.
- That static multimodal fusion, even with strong backbones, remains sub-optimal; adaptive, context-driven routing is indispensable for maximizing long video comprehension.
Future Directions
The proposed approach is a stepping stone to more general dynamic multimodal selection architectures, including:
- Integration of auxiliary modalities (audio, dense event streams).
- Joint refinement of keyframe selection and narrative segmentation in a closed-loop.
- Exploring reinforcement learning or memory-augmented agents for iterative or continual adaptation, potentially leveraging Q-Gate's weight allocation as meta-data for further alignment.
Conclusion
Q-Gate reframes long video keyframe selection as a query-modulated, training-free mixture-of-experts routing problem, capitalizing on LLM-based in-context reasoning to adaptively select the most relevant modalities per query. Strong empirical results, transparent analysis, and favorable efficiency-positioning establish Q-Gate as a robust solution for scalable, multimodal long video understanding (2604.17422).