- The paper introduces HFS, a query-aware and differentiable frame selection mechanism that mitigates redundancy in video reasoning.
- It employs Chain-of-Thought query generation and online teacher-student mutual distillation to optimize frame selection for relevance, coverage, and diversity.
- Experimental evaluations on benchmarks like Video-MME and NExT-QA demonstrate significant accuracy improvements over traditional top-K and uniform sampling methods.
Holistic Query-Aware Frame Selection for Efficient Video Reasoning
Introduction
The paper "HFS: Holistic Query-Aware Frame Selection for Efficient Video Reasoning" (2512.11534) addresses critical bottlenecks in video understanding for Multimodal LLMs (MLLMs), particularly the challenge of selecting informative frame subsets from long, temporally redundant videos while honoring task specificity. Traditional frame selectors employing top-K relevance or uniform sampling are hampered by frame clustering, redundancy, and task agnosticism. Moreover, existing protocols leveraging offline pseudo-labels lack adaptability during selector learning. This work introduces a holistic, differentiable, task-adaptive mechanism, producing superior reasoning efficiency and strong empirical gains.
Framework Overview
The proposed HFS framework consists of a student Small LLM (SLM) as the key frame selector and a teacher MLLM as a video reasoner. The architecture is composed of three core stages:
- Chain-of-Thought (CoT)-Guided Query Generation: The SLM employs CoT prompting to yield a set of implicit, task-adaptive query vectors, encapsulating diverse facets of the reasoning trace.
- Differentiable Set-Level Frame Selection: Frame candidacy is scored contextually, followed by Gumbel-TopK sampling based on a submodular, continuous objective tied to relevance, coverage, and redundancy.
- Teacher-Student Mutual Learning: Selected frames are fed to the teacher MLLM, with KL divergence enforcing alignment between internal student and teacher frame importance distributions, enabling fully end-to-end optimization unrestricted by static pseudo-label supervision.
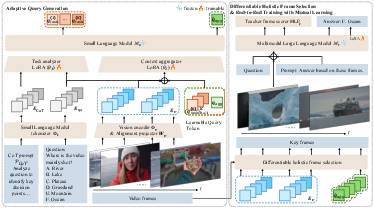
Figure 1: The HFS framework for frame selection, integrating CoT query generation, set-level selection, and teacher-student co-training.
Holistic Frame Selection Objective
HFS departs from myopic independent scoring by introducing a set-level differentiable objective F(m), comprising:
- Relevance: Prioritizing frames most germane to the query.
- Coverage: Ensuring the selected set spans critical events, approximated via log-sum-exp for smooth global maximization.
- Redundancy Penalty: Enforcing temporal and content diversity through a similarity kernel penalizing temporally proximate selections.
Gumbel-TopK sampling provides a differentiable mask over frames, supporting smooth optimization via backpropagation.
End-to-End Online Distillation
A teacher-student architecture enables online mutual distillation. The SLM (student) selects frames, with its scoring distribution KL-aligned to the teacher (MLLM) operating on the chosen set. This online distillation circumvents brittle supervision by pseudo-labels, allowing selector adaptation in response to downstream reasoning loss.
Experimental Results
HFS demonstrates robust gains on Video-MME, LongVideoBench, MLVU, and NExT-QA, outperforming both heuristic and pseudo-label-driven baselines. Key findings include:
Ablation and Efficiency Analysis
Multiple ablations reveal the incremental benefit of each submodule:
- Increasing the number of query vectors K from static (K=0) to K=3 yields consistent performance improvements, capturing richer task intent.
- Inclusion of coverage and redundancy terms in F(m) substantially increases benchmark scores, emphasizing the value of holistic optimization.
- KL-distilled online supervision outperforms both pseudo-label based and single-loss setups.
Latency analysis shows marginal overhead for HFS relative to uniform sampling, justified by significant accuracy gains.
Qualitative Analysis
HFS outstrips uniform and top-K selectors in "needle-in-a-haystack" settings—critical for scenarios where task-relevant events are temporally sparse or visually transient. In egocentric reasoning, HFS not only localizes targets but accurately represents state (e.g., distinguishing “TV on” vs. “off”).
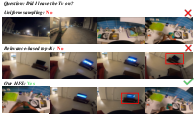
Figure 3: Egocentric task comparison—HFS picks frames displaying the causally necessary “TV on” event, while baselines either miss the object or select misleading states.

Figure 4: Visualization of frame distribution over a video question answering scenario, contrasting the selection patterns of uniform, top-K, and HFS methodologies.

Figure 5: Additional qualitative example demonstrating HFS’s frame selection efficacy for task-centric reasoning.

Figure 6: Visualization showing HFS's superior coverage of event sequences essential for answering temporal queries.

Figure 7: Qualitative example highlighting HFS’s suppression of redundant frame selection in complex video segments.

Figure 8: Side-by-side frame selection analysis for HFS and baselines in a multi-step video question answering task.
Practical and Theoretical Implications
HFS sets a new paradigm for reasoning-aware video frame selection in MLLM architectures:
- Practical Efficiency: By filtering out redundant frames and dynamically contextualizing queries, HFS enables long-form, multi-task video analysis using existing MLLMs with fixed token budgets.
- Generalization: The end-to-end and online distillation mechanisms enable fast adaptability to novel downstream objectives and evolving task formats.
- Theoretical Direction: Set-level optimization for multimodal frame selection motivates further study in joint submodular representations, task-adaptive selection in sequential data, and dynamic cross-modal information bottlenecks.
- Future Trends: Extensions include more granular spatiotemporal selection, active learning loops for continual adaptation, and hierarchical multi-resolution reasoning combining frame, clip, and scene-level cues.
Conclusion
The HFS framework (2512.11534) introduces a principled, task-adaptive, and differentiable protocol for video frame selection in multimodal reasoning pipelines. Through joint CoT-driven query design, set-level submodular optimization, and teacher-student mutual learning, HFS consistently yields superior empirical results and more informative frame subsets for downstream video reasoning. This approach redefines selection protocols for efficient long-context video understanding and sets an advanced baseline for future MLLM-driven systems.
