- The paper introduces F2C, a training-free framework that selects temporally coherent clips by leveraging semantic relevance and diversity in anchor key frame selection.
- It adapts clip length and resolution to maintain a fixed token budget while preserving vital temporal information for improved video understanding tasks.
- Experimental results demonstrate up to 10.3% performance gains on benchmarks, highlighting more effective context construction over uniform frame sampling.
Introduction
The paper "From Frames to Clips: Efficient Key Clip Selection for Long-Form Video Understanding" (2510.02262) addresses the context management bottleneck in Video LLMs (VLMs) for long-form video understanding. The central challenge is the "needle in a haystack" problem: the massive number of visual tokens generated from raw video frames far exceeds the context window of current VLMs, making it difficult to identify relevant content and reason about temporal dynamics. Existing solutions typically rely on uniform frame sampling or keyframe selection, but these approaches either waste context on irrelevant frames or lose essential temporal continuity, resulting in suboptimal performance on tasks such as video question answering (VQA).
The proposed Frames-to-Clips (F2C) framework introduces a training-free, adaptive strategy that selects temporally coherent key clips—short video segments centered around relevant frames—while dynamically balancing spatial resolution and clip length to maintain a fixed token budget. This approach preserves both semantic relevance and local temporal continuity, enabling more effective context construction for VLMs.
Motivation and Empirical Analysis
Uniform frame sampling in long-form videos leads to large temporal gaps, often missing critical motion cues and event progression. For example, sampling 32 frames from a 30-minute video yields gaps of over 50 seconds, making it impossible to answer motion-related questions (Figure 1).

Figure 1: Motivation for key clip selection—uniform sampling yields large gaps, losing temporal continuity necessary for motion reasoning.
Empirical studies on the Ego4D-Haystack dataset demonstrate that human-annotated key frames significantly outperform uniform sampling, even with fewer frames. Augmenting key frames and uniformly sampled frames with their temporal neighbors (forming key clips and uniform clips) further improves VQA accuracy, highlighting the importance of local temporal continuity (Figure 2).
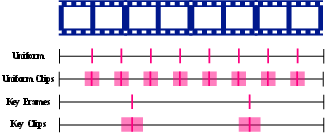
Figure 2: Comparison of uniform sampling, key frames, and their clip-augmented variants; clips preserve temporal context and improve accuracy.
F2C Framework: Methodology
Anchor Key Frame Selection
F2C decomposes key clip selection into two subtasks: (1) selecting Kanchor anchor key frames as clip centers, and (2) determining the clip length Li for each anchor. Anchor selection is guided by two principles: semantic relevancy (using a vision-language encoder to compute frame-query similarity) and diversity (using watershed segmentation and K-means clustering to avoid redundancy).
Adaptive Clip Length and Resolution Trade-off
To maintain a fixed token budget, F2C introduces an adaptive resolution strategy. The trade-off is formalized as:
L=Kanchors2⋅K
where L is clip length, s is the downsampling factor, K is the total frame budget, and Kanchor is the number of anchors. Longer clips require lower spatial resolution or fewer anchors. F2C optimizes clip-specific lengths li for each anchor, balancing average relevancy, redundancy, and a temporal reward term. Overlapping clips are merged to avoid redundant encoding.
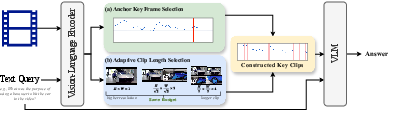
Figure 3: Overview of F2C—anchor selection, adaptive clip length, and resolution balancing under a fixed token budget.
Experimental Results
Benchmarks and Baselines
F2C is evaluated on Video-MME, LongVideoBench, and MLVU, covering diverse domains and long-form video tasks. Baselines include uniform sampling, Top-k similarity selection, BOLT (inverse transform sampling), Q-Frame (multi-resolution frame selection), and watershed-based selection.
F2C consistently outperforms all baselines across benchmarks, with improvements up to 8.1%, 5.6%, and 10.3% on Video-MME, LongVideoBench, and MLVU, respectively. Gains are most pronounced under small frame budgets, where uniform sampling fails to capture relevant content. F2C's advantage narrows as the frame budget increases but remains significant.
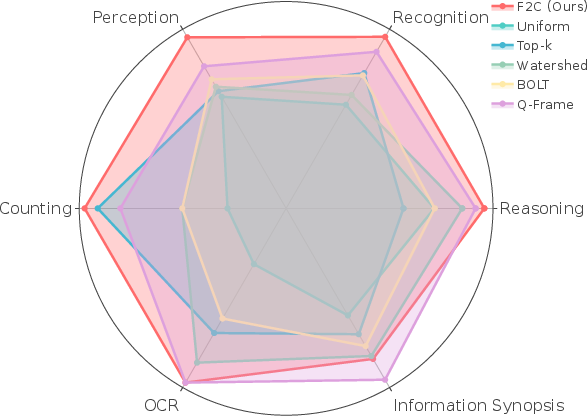
Figure 4: Performance breakdown by question type on Video-MME; F2C excels in tasks requiring temporal reasoning and continuity.
Ablation studies show that adaptive key clip selection yields the highest accuracy, outperforming both fixed-length clips and frame-based selectors. Temporal continuity in key clips provides richer context than simply increasing frame count (Table: Comparison of temporal modeling).
Selector and Parameter Sensitivity
F2C improves performance regardless of the anchor selection strategy, but diversity and semantic relevance in anchor frames are crucial. The optimal Kanchor/K ratio balances diversity and temporal coverage. Computational analysis reveals that F2C achieves similar or lower token counts compared to frame-based methods, especially as the budget grows.
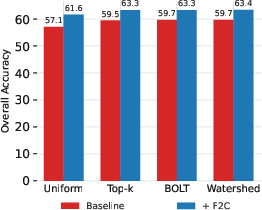
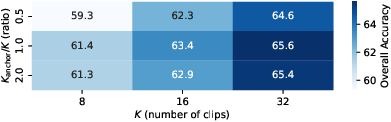
Figure 5: Impact of different anchor selectors on Video-MME; F2C consistently improves upon all selectors.
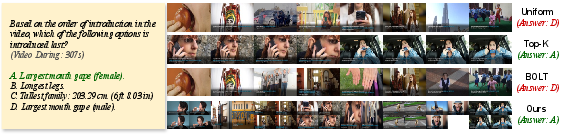
Figure 6: Visualization of selected frames—F2C captures relevant events with temporal continuity, unlike uniform or Top-Li0 sampling.
Implementation Considerations
- Vision-Language Encoder: F2C leverages CLIP or SigLIP2 for frame-query similarity computation. The choice of encoder has marginal impact on performance.
- Token Budgeting: Adaptive resolution and clip length ensure that the total visual token count remains within hardware constraints.
- Training-Free: F2C does not require additional model training, making it practical for deployment with existing VLMs.
- Computational Efficiency: Overlapping frames in clips are encoded only once, improving efficiency.
- Scalability: F2C is robust to long videos and large frame budgets, with performance upper-bounded by the downstream VLM's capabilities.
Implications and Future Directions
F2C demonstrates that context management via temporally coherent key clips and adaptive resolution is critical for scaling VLMs to real-world long-form video understanding. The framework is complementary to advances in VLM architectures and can be integrated with future models featuring longer context windows or improved temporal reasoning. The results suggest that further research should focus on joint optimization of context selection and model architecture, as well as dynamic adaptation to diverse video domains and tasks.
Conclusion
Frames-to-Clips (F2C) provides a principled, training-free solution for efficient context construction in long-form video understanding. By replacing isolated keyframes with temporally coherent clips and introducing adaptive trade-offs between resolution and clip length, F2C consistently improves VLM performance across multiple benchmarks. The approach highlights the importance of temporal continuity, diversity, and resolution balancing in context management, offering a scalable pathway for future video-language research and applications.