- The paper introduces ProVCA, a progressive video condensation agent that iteratively selects query-relevant frames, significantly reducing computational load.
- It employs a three-stage process—segment localization, snippet selection, and keyframe refinement—to improve zero-shot accuracy on benchmarks such as NExT-QA, EgoSchema, and IntentQA.
- Experimental results demonstrate that ProVCA outperforms state-of-the-art methods in both precision and efficiency, marking a paradigm shift in long-form video understanding.
Introduction
Long-form video understanding necessitates effective extraction of query-relevant information from large, high-dimensional, and temporally extended input sequences, imposing significant computational and modeling challenges. Recent advances in multimodal LLMs (MLLMs) have enabled direct joint processing of text and visual modalities, offering the potential for fine-grained video reasoning. However, naively applying video-based MLLMs with dense frame sampling is computationally prohibitive, while alternative LLM agent pipelines that convert frames to captions and filter with VLMs such as CLIP are prone to discarding essential, nuanced visual cues.
This work introduces ProVCA, a progressive video condensation agent engineered to iteratively and hierarchically locate frames most relevant to the user query. ProVCA leverages the semantic and cross-modal reasoning capabilities of MLLMs to condense videos from coarse segment selection, through semantically-aware snippet retrieval, to final keyframe identification, thereby striking a balance between reasoning accuracy and computational efficiency.
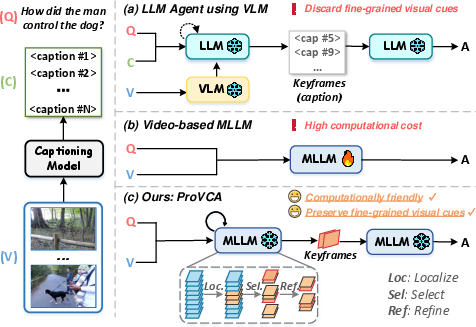
Figure 1: Schematic comparison between (a) direct video-based MLLMs, (b) caption-based LLM agent pipelines, and (c) ProVCA’s progressive MLLM-guided condensation strategy.
Methodology
ProVCA operates via a three-stage, query-driven selection mechanism utilizing the MLLM for all major decision points:
- Segment Localization: The video is initially divided into coarse segments, with the MLLM referencing sparsely sampled global frames to select the segment most aligned with the input query. This significantly prunes the temporal search space.
- Snippet Selection: Within the selected segment, frames are captioned, and semantic similarity (via cosine distance) between sequential captions informs temporally coherent clustering into snippets. Each snippet is represented by its initial frame. The MLLM, provided with representative frames and the query, then assesses snippet relevance and confidence.
- Keyframe Refinement: For snippets where the MLLM confidence is low, all constituent frames are fed (in sequence, with structure-providing prompts) to the MLLM for detailed joint analysis, allowing for pinpointing of the most critical keyframes.
This results in a condensed video representation tailored per query, dramatically reducing redundant input while maintaining the essential evidence required for high-precision reasoning.
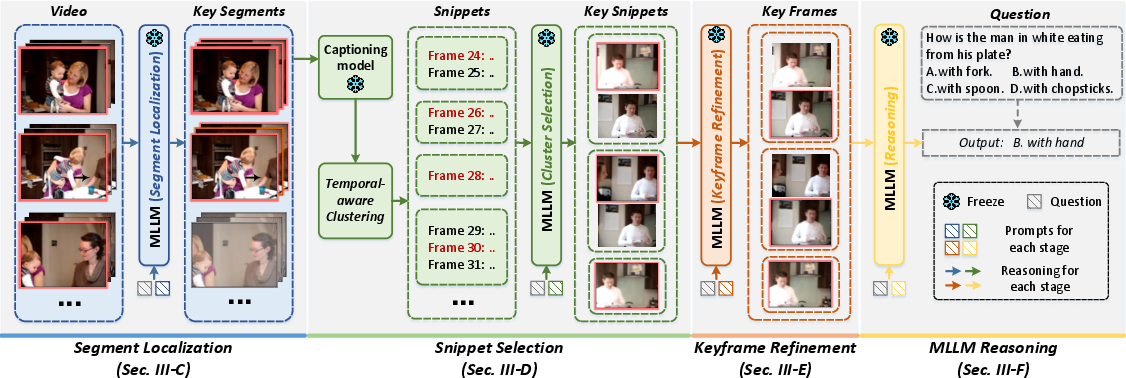
Figure 2: Detailed system overview—ProVCA hierarchically localizes the query-relevant segment, partitions it into snippets via caption-level similarity, and then refines to keyframes for downstream MLLM reasoning.
Experimental Results
Benchmarks on three leading long-form video QA datasets—NExT-QA, EgoSchema, and IntentQA—demonstrate ProVCA’s consistent and significant performance advancements over state-of-the-art training-free agents, both in zero-shot accuracy and in frame efficiency.
- NExT-QA (Zero-shot): 80.5% accuracy, improving by 4.9% over the best baseline (VideoTree with GPT-4) while employing only ∼4.2 frames/video.
- EgoSchema: 69.3% (subset) and 74.2% (full test, +8.2% over VideoTree), using only 7.3 frames/video.
- IntentQA: 77.7% accuracy (+6.0% over LVNet), with merely 4.9 frames/video required.
In ablations, removing any component—segment localization, snippet selection, or keyframe refinement—leads to measurable performance and efficiency degradation, empirically justifying the progressive design. Combining image and caption modalities for MLLM input further boosts accuracy (to 85.2% on NExT-QA). Global, temporally-ordered keyframe refinement evidences superior yield compared to independent or sequential approaches.
Comparative Analysis
ProVCA diverges from prior agent-based approaches in its query-specific, progressively refined temporal sampling. Contrasted with uniform or heuristic frame selection (e.g., IG-VLM, LVNet) and with tree-based clustering (e.g., VideoTree), ProVCA’s design enables superior focus on query-relevant evidence while minimizing MLLM compute.
Key strong results:
- ProVCA outperforms VideoTree, LVNet, and Tarsier family models—even with fewer frames and using the same MLLM (GPT-4o).
- The combination of image and caption features maximizes MLLM reasoning capacity within a reduced context.
- The condensation mechanism is demonstrably the critical driver of the observed performance gains, not merely model scaling or MLLM input format.
Theoretical and Practical Implications
ProVCA offers a paradigm shift for MLLM-based video reasoning: it frames long-form video understanding as a cognitively motivated, hierarchical, and query-aware reading comprehension task in the visual modality. The progressive condensation approach sets a precedent for using agentic, multimodal selection strategies that align with both the intrinsic locality of video semantics and with the computational constraints imposed by current MLLM architectures.
Practically, ProVCA enables scalable deployment of video reasoning agents on real-world long-form video content, with broad applicability for video surveillance, human activity analysis, and content retrieval. Theoretically, the approach suggests that MLLM-based pipelines may generally benefit from tight integration of progressive, semantic content selection and cross-modal abstraction routines.
Future Directions
Future development may explore end-to-end optimization of condensation and reasoning steps, integration with memory-augmented MLLM architectures, adaptation to streaming or incrementally growing video contexts, and joint modeling of query, video, and answer spaces for more general instruction-following agents. Extensions to multi-agent collaboration and open-ended instruction sets based on dynamic progressive condensation frameworks are also promising research avenues.
Conclusion
ProVCA substantiates a robust and efficient new baseline for long-form video understanding with MLLMs, advancing both state-of-the-art zero-shot accuracy and compute efficiency. By directly leveraging the reasoning capabilities of advanced MLLMs through progressive segment, snippet, and keyframe condensation, the framework enables scalable, high-fidelity video QA and sets a solid foundation for future multimodal agent research in long-context spatiotemporal understanding (2604.02891).