Bit-Flip Vulnerability of Shared KV-Cache Blocks in LLM Serving Systems
Abstract: Rowhammer on GPU DRAM has enabled adversarial bit flips in model weights; shared KV-cache blocks in LLM serving systems present an analogous but previously unexamined target. In vLLM's Prefix Caching, these blocks exist as a single physical copy without integrity protection. Using software fault injection under ideal bit targeting, we characterize worst-case severity and identify three properties: (1) Silent divergence - 13 of 16 BF16 bit positions produce coherent but altered outputs, indistinguishable from legitimate responses without a clean baseline. (2) Selective propagation - only requests sharing the targeted prefix are affected. (3) Persistent accumulation - no temporal decay occurs, so cumulative damage grows linearly with subsequent requests. Together, these constitute a threat profile distinct from weight corruption: silent divergence and selective propagation enable detection evasion; persistent accumulation then proceeds unchecked, yielding damage amplification bounded only by how long the block remains cached. A checksum-based countermeasure detects any single-bit corruption at scheduling time, bounding cumulative damage to one batch independent of the block's cache lifetime, with negligible overhead. These results argue for integrity protection of prefix blocks before end-to-end exploitation is demonstrated.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at a hidden weakness in how LLMs are run on servers. To answer people faster, these systems save some “memory notes” from the start of the prompt (called a prefix) in the GPU’s memory, so they don’t have to redo work for every user. The authors show that if a tiny change (a single “bit flip,” like toggling a microscopic on/off switch in memory) happens in those shared notes, it can quietly make some answers wrong—without looking obviously broken—and keep doing so for a long time. They also suggest a simple fix that catches these tiny changes before they hurt many users.
The questions the researchers asked
The paper asks, in simple terms:
- If a single tiny piece of data (one bit) in the shared “prefix memory” gets flipped, what happens to the model’s answers?
- Who gets affected—everyone, or only users who share the same starting prompt (prefix)?
- Does the damage fade over time, or does it keep affecting more and more requests?
- Can we add a lightweight safety check to catch these flips before they spread?
How they tested it (explained simply)
Think of the LLM’s “KV cache” as a set of organized sticky notes the model keeps to remember earlier parts of the conversation. When many users share the same starting text (like a standard system prompt), the server stores one shared set of these notes—called “prefix blocks”—and reuses them to save time.
- The team simulated tiny memory errors by deliberately flipping one bit in these shared notes. A “bit” is the smallest data unit in a computer—just 0 or 1—like a tiny light switch.
- They used a common number format called BF16 (bfloat16), which packs each number into 16 bits. Different bits matter more or less for the number’s value. Flipping some bits barely changes the number; flipping others can break it badly.
- After flipping one bit, they compared the model’s answers before and after the flip across many trials, different bit positions, and two 8B models. They looked for:
- Whether any answers changed
- How much text changed
- Whether the text still made sense (coherent) or became obvious nonsense (collapsed)
- Because doing real hardware attacks (like “Rowhammer,” a way to induce bit flips in memory) is complex and risky, they safely simulated the flips in software to see worst-case effects first.
- Finally, they built a simple “checksum” check—think of it like a short fingerprint of the data—to detect if any prefix block had changed, and measured the speed cost.
What they found and why it matters
Here are the main results, presented clearly:
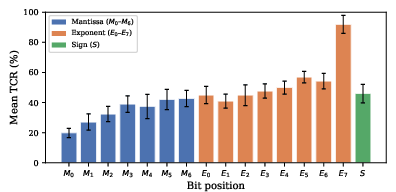
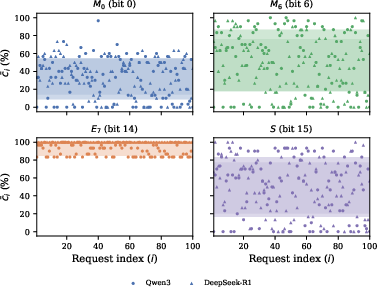
- Silent divergence (most flips look normal but are wrong):
- In 13 out of 16 bit positions, flipping a single bit made the model produce answers that were still fluent and on-topic, but different from the clean answers.
- This is dangerous because nothing looks obviously broken, so normal quality filters won’t catch it.
- Selective propagation (only some users are affected):
- Only users whose requests reuse the same shared prefix block are affected.
- Other users, with different starting prompts, are perfectly fine.
- This makes the problem harder to notice, because only a subset of users see changes.
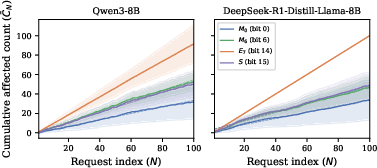
- Persistent accumulation (the problem keeps going):
- Once a shared prefix block is corrupted, the bad effect doesn’t fade on its own.
- Every new request that uses that shared block can be affected, so the total “damage” grows steadily over time, as long as the block stays cached.
- Not all bit flips are equal:
- Most bit flips cause “silent divergence” (coherent but altered answers).
- A few flips in very important bits (especially a top “exponent” bit, called bit 14 in BF16) can make the model output collapse into gibberish or repetitive symbols—these are obvious and easy to detect.
- The majority, however, are subtle and hard to detect.
- A simple fix works with tiny overhead:
- Their checksum-based integrity check detects any single-bit change in the shared prefix block before the block is reused.
- That limits the damage to at most one batch of requests, instead of letting it grow with every future request.
- They measured the speed impact and found it to be negligible.
Why this matters: Without integrity protection, a single tiny memory error in a shared block can quietly steer some users’ answers off course for a long time. Because it affects only users who share a prefix and often stays fluent, it can slip past monitoring. That’s a very different and trickier problem than if model weights are corrupted, which tends to affect everyone and is easier to spot.
What this could mean going forward
- Operators should add integrity protection for shared prefix blocks. The proposed checksum approach keeps the speed benefits of caching while catching silent corruption.
- Simple text-quality checks (like spotting repetition) help only when outputs collapse into nonsense; they won’t catch the far more common “silent but wrong” changes.
- If checksums aren’t possible yet, time-limiting (TTL) how long a shared block lives reduces how long the damage can accumulate—but costs extra compute.
- Even though the experiments simulated bit flips, real hardware faults (like Rowhammer or random memory errors) can happen—especially on GPUs without full error-correcting protection—so it’s better to secure this now rather than wait.
In short: The paper shows that shared “prefix memory” in LLM servers is a special weak spot. A tiny, hidden memory change can quietly affect some users’ answers for a long time. A small integrity check can catch this with almost no performance cost, making systems safer and more reliable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper surfaces several unresolved issues that future work should address to fully understand and mitigate bit-flip vulnerability in shared KV-cache blocks.
- End-to-end feasibility of physical attacks
- Demonstrate a complete Rowhammer-based exploitation chain that targets a specific vLLM prefix block in multi-tenant settings, including: (1) locating long-lived shared prefix blocks (cache-presence detection), (2) mapping virtual-to-physical GPU addresses for those blocks, and (3) inducing flips in targeted rows under real scheduling and isolation constraints (ECC on/off, MIG, virtualization).
- Quantify achievable bit-flip control (directionality, spatial locality, rate) on production GPUs and how it constrains targeting of particular BF16 bit positions observed to cause high impact (e.g., ).
- Assess whether attackers can time flips to precede large batches (maximizing “one batch” damage before detection) and characterize the practicality of such timing in shared clusters.
- Coverage of attack surface beyond current SFI scope
- Key-side corruption: systematically evaluate bit flipping in key tensors (not only values) to quantify “attention misrouting” failure modes and whether they differ in selectivity, divergence patterns, or detectability.
- Multi-bit and repeated flips: measure how multiple flips within the same block (or across layers/heads) compound effects versus single flips, including ECC-correctable vs. uncorrectable patterns and whether small, repeated flips can evade checksum schedules.
- Data types and formats: extend analysis to KV caches stored in FP16, FP8, mixed-precision, or quantized formats (e.g., INT4/INT8) increasingly used in serving, and re-derive bit-position sensitivity maps for each.
- Boundary and partially shared blocks: evaluate corruption of prefix–suffix boundary blocks that are intermittently shared, and study how variability in reuse influences propagation and detection.
- Cross-layer/head sensitivity: produce fine-grained maps of layers, heads, and channel positions most likely to cause severe divergence or collapse when flipped, to inform targeted defenses.
- Generality and external validity
- Model and workload diversity: validate results on larger models (e.g., 34B/70B+), instruction-tuned and safety-aligned models, and non-chat tasks (summarization, RAG, tool use, long-context) to assess how impact scales with architecture, size, and task distribution.
- Non-deterministic decoding: re-evaluate “silent divergence” under typical serving (sampling with temperature/top-p) where baseline outputs are non-unique; determine if corruption-induced changes remain distinguishable from normal stochasticity and how to measure effect sizes reliably.
- Multi-GPU serving: examine tensor/pipeline parallelism, offloading (KV paging to CPU/NVMe), and distributed caches to see how corruption propagates across devices and whether communication patterns introduce or mask temporal persistence.
- Realistic residency and reuse: measure prefix-block lifetimes and reuse frequencies in production-like traffic to estimate expected cumulative damage without defenses (risk quantification), including eviction dynamics under heavy load.
- Impact on safety and application-level risks
- Safety prompt degradation: specifically test corruption of widely shared system/safety prompts to determine whether bit flips cause safety guardrail bypasses, content policy violations, or targeted jailbreak-like behavior distinct from weight attacks.
- Downstream utility metrics: go beyond ROUGE/BERTScore to quantify factuality, toxicity, instruction-following, and task success rates under corruption to translate token-level changes into user-facing harm.
- Defense design and residual risks
- TOCTOU windows: precisely measure the time-of-check-to-time-of-use exposure in the proposed checksum scheme (deferred sealing and pre-attention windows) and quantify how many requests can slip through under different batch sizes and schedulers.
- GPU-side integrity checks: design and benchmark on-GPU hashing/CRC kernels (or per-page checksums) to eliminate PCIe round trips and narrow TOCTOU gaps; compare cryptographic vs. fast non-cryptographic digests for single- vs. multi-bit protection.
- High-throughput overheads: evaluate checksum overhead under realistic concurrency (large batches, many cache hits per step), discrete GPUs with PCIe, multi-GPU deployments, and larger per-block KV volumes to establish worst-case service SLO impacts.
- Robustness to multi-bit flips: verify detection efficacy for correlated multi-bit errors and partial-line corruptions; assess collision risks for non-cryptographic digests if adopted for performance.
- Denial-of-service vectors: analyze how repeated adversarial flips can trigger frequent evictions/recomputations, causing latency spikes or throughput collapse, and design scheduling/backoff mechanisms to limit DoS amplification.
- Selective invalidation strategies: explore finer-grained verification (e.g., per-layer/per-head sub-block checksums) to reduce recomputation cost and blast radius when only parts of a block are corrupted.
- System and deployment considerations
- Interplay with ECC and hardware mitigations: quantify how server GPUs with ECC (single- vs. multi-bit coverage), refresh policies, and Rowhammer defenses alter observed bit-flip rates and attack viability on KV caches.
- Memory protection primitives: investigate whether modern CUDA/driver features (e.g., page protection, read-only mappings, memory advise) can enforce immutability of cached blocks at the GPU level and how feasible they are in vLLM’s memory manager.
- Salting and sharing policies: study how various cache-salt configurations (tenant-, org-, model-level) change attack surfaces and performance trade-offs; develop policies that retain sharing benefits while limiting cross-tenant blast radius.
- Monitoring for silent divergence: develop runtime signals beyond surface text quality (e.g., logit-distance monitors, predictive uncertainty, ensemble/teacher agreement) that can flag corruption-induced deviations without a clean baseline.
- Measurement and reproducibility gaps
- Provide full details and artifacts to replicate hashing overheads on discrete PCIe GPUs and multi-GPU setups; report sensitivity of results to hardware (HBM vs. GDDR6), drivers, and vLLM versions.
- Formalize statistical power and confidence intervals for reported TCR/TDR/OCR under different concurrency and request distributions to better support operational risk assessments.
Practical Applications
Immediate Applications
The paper’s findings and checksum-based countermeasure enable several deployable actions across sectors. The following items translate the results into concrete workflows, tools, and policies that can be adopted now, noting assumptions and dependencies.
- Industry (Software/Cloud/AI Serving)
- KV-cache integrity verification in LLM serving stacks
- What: Integrate a scheduling-time checksum over prefix KV-cache blocks (e.g., SHA-256 or xxHash) and evict/recompute on mismatch.
- Where: vLLM forks/plugins, TensorRT-LLM, HuggingFace TGI, custom Triton/PyTorch inference servers.
- Why: Bounds cumulative damage from silent divergence and persistent accumulation to one batch even under undetected bit flips.
- Dependencies: Ability to compute digests on cached blocks; recompute prefills from clean weights; overhead acceptable on target hardware. Assumes BF16 (or similar) KV-cache and shared prefix caching is enabled.
- Potential product: “KVShield” or “CacheGuard” modules offering drop-in integrity checks for KV-cache.
- Operational hardening for multi-tenant deployments
- What: Enable GPU ECC where available; enforce tenant-level cache_salt to prevent cross-tenant sharing; isolate high-risk tenants onto separate salt groups or GPUs.
- Sector: Cloud platforms, MLOps providers.
- Why: Selective propagation means only shared-prefix tenants are affected; isolation reduces blast radius.
- Dependencies: ECC availability and performance budgets; acceptance of reduced caching efficiency with salting.
- SRE monitoring and runbooks for collapse detection
- What: Add repetition-ratio/perplexity alarms to catch collapse-mode (upper-exponent bit flips) outputs; canary requests and blue/green cache refresh workflows to validate caches before mass reuse.
- Sector: SaaS LLM APIs, enterprise LLM services.
- Why: Collapse is overt and detectable; rapid remediation prevents user-visible incidents.
- Dependencies: Deterministic decoding or stable baselines for canaries; observability plumbing.
- Limitation: Silent divergence will evade these detectors; use integrity checks to cover that gap.
- TTL-based cache hygiene
- What: Apply time-to-live or max-reuse counters to prefix blocks, forcing periodic recomputation.
- Sector: General LLM serving.
- Why: Caps linear damage growth when integrity checks are not yet deployed.
- Dependencies: Prefill cost tolerable; cache hit-rate trade-offs understood.
- Security testing with software fault injection (SFI)
- What: Adopt the paper’s bit-flip SFI method (XOR at BF16 positions) to red-team serving stacks; report Token Change Rate (TCR), Token Diff Ratio (TDR), and Output Change Rate (OCR) as service health KPIs.
- Sector: Security engineering, reliability engineering.
- Why: Reproduces worst-case impact to validate defenses before Rowhammer-class exploitation exists.
- Tools: Internal “KV-FI” harnesses targeting value tensors in prefix blocks during test runs.
- Assumptions: Deterministic decoders and repeatable baselines for comparison.
- Regulated Sectors (Healthcare, Finance, Government)
- One-batch quarantine for high-stakes prompts
- What: For critical system prompts (care guidelines, compliance scripts), enable KV integrity checks and/or route first-batch outputs to human-in-the-loop or secondary model verification before releasing.
- Why: Silent divergence risks subtle, coherent but wrong advice; bounding damage to one batch limits harm.
- Dependencies: Human review or automated cross-checks; acceptance of slight latency increases.
- Provider due diligence and SLAs
- What: Require vendors to disclose KV-cache integrity controls, ECC settings, and cache isolation policies; include incident-response SLAs for detected cache corruption.
- Sector: Enterprise procurement, compliance.
- Why: Aligns with the paper’s identified threat chain and practical mitigations.
- Dependencies: Vendor support and auditability.
- Academia and Open-Source
- Benchmarking suites for cache integrity
- What: Release reproducible SFI benchmarks measuring per-bit sensitivity maps, selective propagation, and temporal persistence using TCR/TDR/OCR, ROUGE-L, and BERTScore.
- Why: Standardizes evaluation of cache vulnerabilities and defenses across models and formats.
- Dependencies: Open-weight models, vLLM-compatible testbeds.
- Curriculum and labs on GPU memory integrity
- What: Course modules demonstrating BF16 sensitivity and KV-cache corruption behaviors using SFI.
- Why: Trains practitioners on this distinct threat profile versus weight corruption.
- Daily Life / Self-hosters
- Safe-by-default settings for local LLM servers
- What: Enable KV-cache integrity checking (if available), prefer ECC-capable GPUs, and disable cross-user prefix sharing.
- Why: Reduces risk in homelab or small business deployments that reuse prompts across users.
- Dependencies: Community forks or future upstream support; performance acceptance.
Long-Term Applications
These items require further research, scaling efforts, or ecosystem/standards development to realize.
- Hardware and Systems Innovations
- GPU-side integrity primitives for KV-cache
- What: On-GPU hashing kernels to eliminate TOCTOU windows; memory tagging or lightweight Merkle trees for KV buffers; ECC tuned for multi-bit error resilience in GDDR/HBM.
- Sector: GPU vendors, accelerator startups.
- Why: Moves integrity verification closer to the read path, mitigating post-schedule flips and PCIe overhead.
- Dependencies: Driver/runtime support; negligible impact on attention latency; hardware roadmap changes.
- Rowhammer-aware memory controllers for LLM workloads
- What: In-DRAM refresh policies or guard rows for high-value regions (KV-cache); telemetry exposing row-activation anomalies to the driver.
- Sector: DRAM/GPU vendors.
- Why: Prevents adversarial flips at the physical layer; supports cloud attestation.
- Serving Software and Cloud Services
- End-to-end cache integrity frameworks
- What: Comprehensive cache security layer that combines digesting, tenant-aware salting, TTL, replica cross-checks, and anomaly feedback loops.
- Products: “Secure LLM Serving” SKUs; managed “KV Integrity Guard” add-ons.
- Dependencies: Integration across vLLM/Triton/TensorRT-LLM; cloud scheduler cooperation.
- Fault-tolerant prefix caching
- What: Dual-replica prefix blocks with majority-vote read or periodic cross-hash verification; opportunistic recomputation in background.
- Sector: High-availability AI platforms.
- Why: Maintains cache benefits while resisting undetected single-point corruption.
- Dependencies: Extra memory budget; replica coherence policies.
- GPU/driver APIs for integrity and telemetry
- What: Standardized APIs exposing per-buffer error counts, ECC status, row activation rates; secure enclaves for model-serving memory regions.
- Why: Enables auditable security posture and adaptive defenses.
- Research Directions
- Bridging SFI to physical exploitation
- What: Map address translation and access patterns for KV-cache; demonstrate or refute feasibility of Rowhammer targeting of long-lived shared prefix blocks.
- Why: Validates real-world risk and prioritizes defenses.
- Dependencies: Ethical constraints, vendor cooperation.
- Robust representations and defenses
- What: Explore KV-cache formats resilient to single-bit flips (e.g., parity-augmented BF16, lightweight error-correcting codes), or encoding schemes that bound perturbation impact.
- Sector: ML systems research.
- Trade-offs: Memory/latency overhead vs. model throughput.
- Detection of silent divergence
- What: Post-hoc detectors using ensemble consistency, cross-decoder agreement, or latent embedding drift to flag coherent-but-altered outputs caused by cache faults.
- Why: Complements checksums in settings where hashing is impractical.
- Dependencies: Additional compute; acceptable false-positive rates.
- Broader scope evaluations
- What: Extend sensitivity maps to FP8/INT4 KV-caches, key-side flips, multi-GPU sharding, larger models (70B+), and diverse tasks (e.g., safety prompts, code).
- Why: Generalizes risk profiles and guides defense parameterization.
- Standards and Policy
- Best-practice baselines for AI serving integrity
- What: Industry guidance (e.g., from NIST/ISO/ENISA) recommending ECC default-on, KV-cache integrity verification for multi-tenant serving, cache isolation across tenants, and incident-reporting requirements.
- Sector: Regulators, standards bodies, cloud trust frameworks.
- Dependencies: Consensus-building with vendors and providers.
- Compliance controls and audits
- What: SOC 2/ISO 27001 extensions to include “Model Serving Memory Integrity” controls; customer audit checklists verifying KV-cache protections and ECC settings.
- Why: Aligns operational practices with the paper’s demonstrated risks.
- Safety-Critical Applications (Healthcare, Finance, Robotics)
- Defense-in-depth pipelines for critical prompts
- What: Multi-pass validation where outputs generated from cached prefixes are periodically recomputed from scratch (no-cache) and compared; discrepancies trigger re-issuance.
- Why: Addresses silent divergence without continuous hashing on every hit.
- Dependencies: Extra latency budget; reconciliation logic.
Assumptions and dependencies across applications:
- Risk is highest when: prefix caching is enabled and widely shared; multi-tenant GPUs are in use; ECC is absent or insufficient; KV-cache uses BF16; long-lived system prompts are common.
- Performance impacts: The paper’s “negligible overhead” was measured in a specific environment (batch size 1, unified memory); PCIe round trips and high concurrency may increase costs.
- Security gaps: Scheduling-time hashing leaves a short TOCTOU window; GPU-side hashing and replication can mitigate this in future work.
- Trade-offs: Salting and TTL reduce cache efficiency; integrity checks add minimal compute and possible data transfer overhead; replication increases memory usage.
Glossary
- BF16 (bfloat16): A 16-bit floating-point format (1 sign, 8 exponent, 7 mantissa bits) commonly used to store LLM KV-cache tensors while retaining FP32 range. "The bfloat16 (BF16) format~\cite{kalamkar2019bfloat16} is the standard storage format for KV-cache tensors in current LLM serving systems."
- BERTScore: A semantic similarity metric for text based on contextual embeddings. "BERTScore~(F1)~\cite{zhang2020bertscore} for semantic similarity."
- Bonferroni correction: A multiple-comparisons adjustment controlling family-wise error rates in statistical tests. "after Bonferroni correction"
- cache_salt: A per-request salt value that partitions cache keys and isolates sharing across groups. "per-request cache_salt"
- Chain hash: A hash constructed by chaining the previous block’s hash with current tokens (and extras) to require exact prefix matches. "indexes them by a chain hash."
- Checksum-based countermeasure: A runtime integrity-check mechanism that hashes cached blocks and rejects corrupted ones. "A checksum-based countermeasure detects any single-bit corruption at scheduling time"
- Deterministic decoding: Inference with fixed randomness (e.g., temperature 0) that yields repeatable outputs. "Decoding is deterministic (temperature=0)"
- ECC (error-correcting code): Memory protection that detects and corrects certain bit errors in hardware. "Hardware ECC mitigates single-bit errors"
- GDDR6 memory: A graphics DRAM standard used on GPUs, susceptible to Rowhammer bit flips. "GPU GDDR6 memory is no exception:"
- GPU DRAM: Dynamic RAM on GPUs that can experience disturbance-induced bit flips. "Rowhammer on GPU DRAM has enabled adversarial bit flips in model weights"
- GPU-side hashing kernel: A device-side routine to compute hashes on GPU buffers, reducing verification windows. "A GPU-side hashing kernel would narrow both gaps."
- Integrity protection: Mechanisms (e.g., checksums or ECC) that ensure data has not been silently modified. "without integrity protection."
- Key–value (KV) tensors: Attention cache tensors storing per-token key and value vectors for reuse. "caching key--value (KV) tensors in GPU memory"
- Kruskal–Wallis test: A nonparametric statistical test for differences across groups. "Kruskal--Wallis tests show no significant effect"
- KV-cache: The memory cache of attention key and value tensors used to accelerate generation. "vLLM~\cite{kwon2023pagedattention} manages KV-cache memory using a block-based scheme."
- LoRA: Low-Rank Adaptation technique; identifiers tag adapter configurations affecting cache keys. "LoRA identifiers"
- LRU replacement: Least-recently-used eviction policy for managing cache contents. "evicted by LRU replacement."
- Output Change Rate (OCR): Across-trial indicator that any request in a batch changed after corruption. "OCR aggregates across trials"
- PCIe: The host–device interconnect used for data transfers between CPU and discrete GPU. "each verification requires a PCIe round trip"
- Prefix block: A cached KV-cache block corresponding to a shared prompt prefix reused across requests. "We refer to these shared blocks as prefix blocks"
- Prefix Caching: An optimization that reuses cached KV blocks for identical prompt prefixes across requests. "Prefix Caching in vLLM"
- Prefill pass: The initial forward pass that builds the KV-cache for prefix tokens before generation. "a single prefill pass"
- ROUGE-L: A surface-level textual similarity metric based on longest common subsequence. "We report ROUGE-L~(F1 with stemming)"
- Rowhammer: A DRAM disturbance attack that induces bit flips via rapid row activations. "Rowhammer~\cite{kim2014rowhammer} is a DRAM vulnerability"
- Selective propagation: Corruption affects only requests that read the targeted shared prefix, not co-located others. "Selective propagation---only requests sharing the targeted prefix are affected."
- SHA-256: A cryptographic hash used here as a block digest for integrity verification. "We adopt SHA-256"
- ShareGPT: A conversational dataset used to supply diverse user-query suffixes in experiments. "drawn from the ShareGPT conversational dataset"
- Silent divergence: Coherent but altered outputs that differ from clean responses without obvious errors. "Silent divergence---13 of 16 BF16 bit positions produce coherent but altered outputs"
- Single-barrier salting: A vLLM configuration that isolates cache sharing by salt group boundary. "vLLM's single-barrier salting"
- Softmax normalization: The attention step that converts scores into a probability distribution. "passes through softmax normalization"
- Software fault injection (SFI): Emulating hardware faults in software to study their impact on system behavior. "software fault injection (SFI) under an ideal bit targeting assumption"
- Spearman rank correlation: A nonparametric measure of monotonic association used to test trends. "compute the Spearman rank correlation"
- Temporal persistence: The continued effect of corruption across many subsequent requests. "Temporal Persistence"
- Time-of-check-to-time-of-use (TOCTOU): The window between verification and use during which state can change. "time-of-check-to-time-of-use (TOCTOU) windows"
- Time-to-live (TTL): An expiry policy that forces recomputation after a set duration to cap damage. "TTL-based block recomputation."
- Token Change Rate (TCR): The fraction of concurrent requests whose token sequences change after injection. "Token Change Rate (TCR)"
- Token Diff Ratio (TDR): The per-request fraction of token positions that differ post-injection. "Token Diff Ratio (TDR)"
- Unified GPU memory: A GPU memory configuration presenting a unified pool accessible across devices. "unified GPU memory"
- vLLM: An open-source LLM serving engine implementing block-based KV-cache and Prefix Caching. "vLLM~\cite{kwon2023pagedattention}"
- XOR masking: Flipping a specific bit by XORing with a single-bit mask to inject faults. "via XOR masking."
Collections
Sign up for free to add this paper to one or more collections.