- The paper introduces a decode-verify-rollback (DVR) protocol that decouples high-throughput token generation from selective deterministic verification.
- It demonstrates minimal overhead, retaining over 94% throughput even with up to 50% deterministic traffic through grouped verification strategies.
- The approach reconciles reproducibility with hardware efficiency, optimizing kernel operations while maintaining low rollback and recomputation rates.
Deterministic LLM Inference via Verified Speculation: An Analysis of LLM-42
Introduction and Motivation
LLM-42 introduces a scheduling-based protocol for deterministic inference in LLMs, motivated by the inherent non-determinism in modern deployment pipelines. This non-determinism arises from floating-point non-associativity in core operators (GEMMs, attention, normalization) and the dynamic batching strategies of serving systems. Prevailing approaches to ensure determinism—batch-invariant computation—impose significant performance and engineering burdens by requiring kernel redesign and universally enforcing a single reduction strategy, thereby restricting hardware parallelism and penalizing throughput even when determinism is required only for select workloads.
LLM-42 rethinks this paradigm, drawing on speculative decoding structures. Instead of constraining all operator executions, it decouples fast token generation from determinism enforcement, using a decode-verify-rollback (DVR) protocol that executes high-throughput, (potentially) non-deterministic decoding followed by light-weight verification under a fixed reduction schedule. Determinism is enforced only selectively, and the overhead is proportional to the deterministic request fraction.
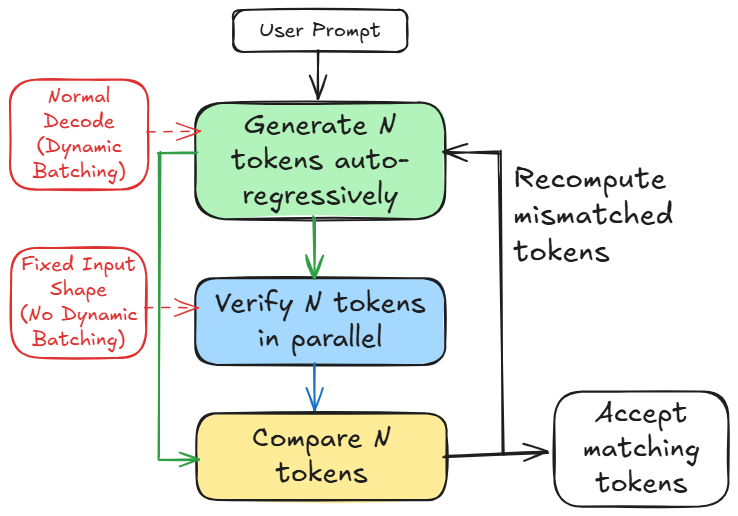
Figure 1: Overview of LLM-42.
Non-Determinism in LLM Systems and Limitations of Existing Solutions
Transformer-based LLMs execute massive parallel arithmetic under finite precision. Dynamic batching causes varying batch sizes across runs, and GPU kernels optimize their reduction orders for each batch, leading to inter-run output drift. Operators such as GEMM, attention, and normalization are especially susceptible due to their reliance on parallel reductions and split-K strategies (which increase hardware utilization but alter result orderings).

Figure 2: High-level architecture of LLMs.
Batch-invariant computation, e.g., as adopted in SGLang or vLLM, mandates uniform reduction scheduling across all requests. This negates scheduling flexibility, disables optimizations like split-K, and requires a parallel stack of deterministic kernels—substantially impairing throughput and requiring ongoing engineering effort as kernel and hardware features evolve.
Benchmarks demonstrate a deterministic GEMM kernel incurs up to 63% throughput loss compared to vendor-optimized cuBLAS (Torch mm) due to the absence of split-K and advanced hardware features. Similar slowdowns for RMSNorm are observed when comparing batch-invariant Python and Triton implementations to optimized CUDA kernels (up to 7× and 50% slower, respectively).
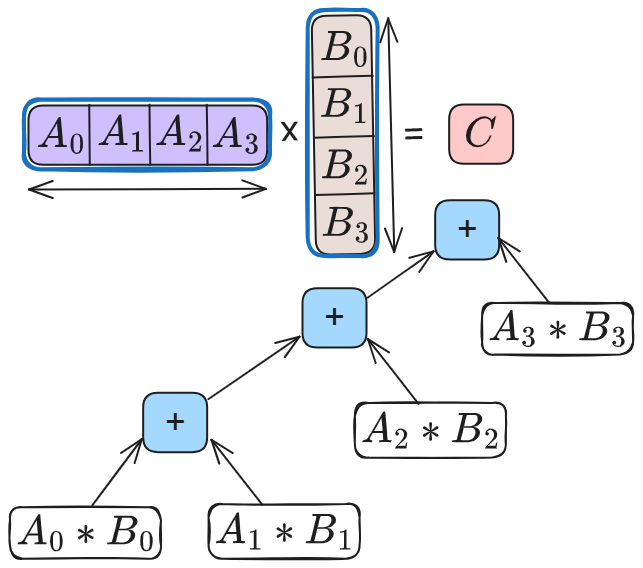
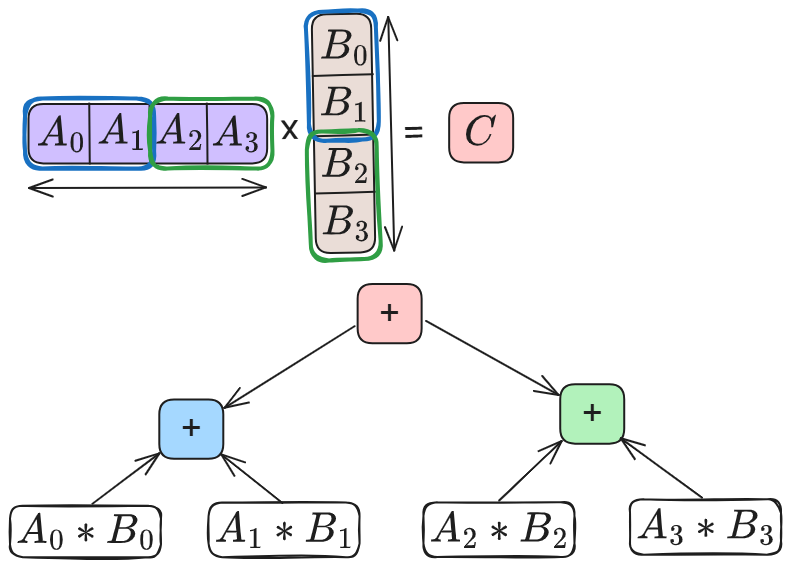
Figure 3: Without split-K.
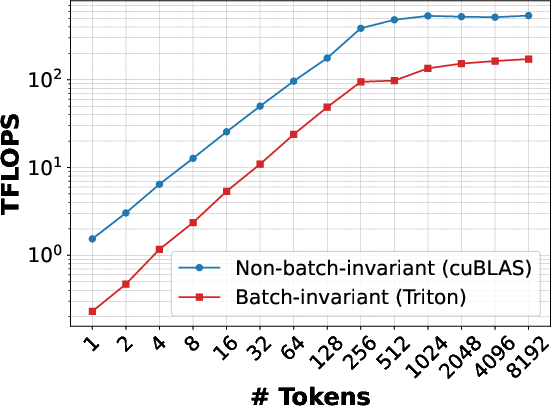
Figure 4: GEMM.
Decode throughput is penalized for all requests once a single deterministic request is introduced in batch-invariant mode—a flaw for many practical LLM workloads where only a subset of requests require traceability or reproducibility.
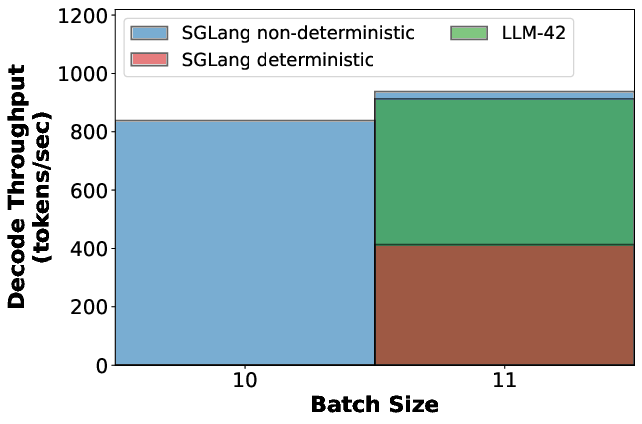
Figure 5: Decode throughput under different scenarios.
Empirical Observations Motivating the LLM-42 Approach
Extensive experiments reveal key properties:
- Token-level output drift is rare until a boundary-crossing event, after which autoregressive decoding quickly amplifies divergence.
- Most kernels are position-invariant within a fixed batch shape, enabling inference about deterministic scheduling without full batch invariance.
- Determinism is only required at the level of specific token positions across runs, not for all positions or batches.
- Real-world LLM serving requires selective inference determinism for auditing, testing, and reproducibility, not for interactive or creative workloads.
Consistency in initial token spans is observed empirically; divergence is isolated and amplifies quickly past the first inconsistency.
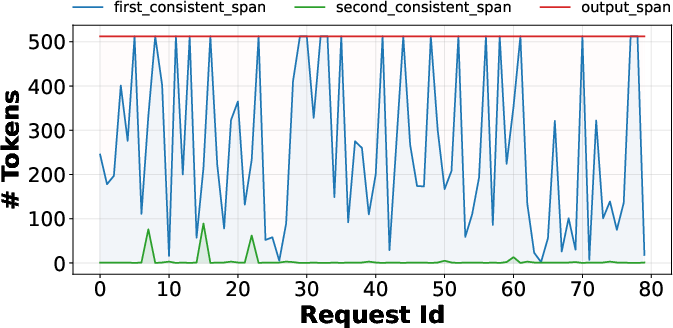
Figure 6: Length of the first and second consistent span for requests under dynamic batching.
The analysis rolls out position-invariant scheduling properties, evidencing that for fixed batch sizes, computation shaders yield consistent results for a given token position, independent of its batch ordering.

Figure 7: Position-invariant kernel output consistency.
DVR Protocol and Grouped Verification
LLM-42 operationalizes determinism using the DVR protocol: requests are decoded speculatively, then verified (replayed) under a fixed schedule. Tokens that match are committed; mismatches trigger rollback and recomputation using the verifier, which guarantees deterministic output by operating under statically scheduled batch shapes. KV cache corrections prevent downstream drift.
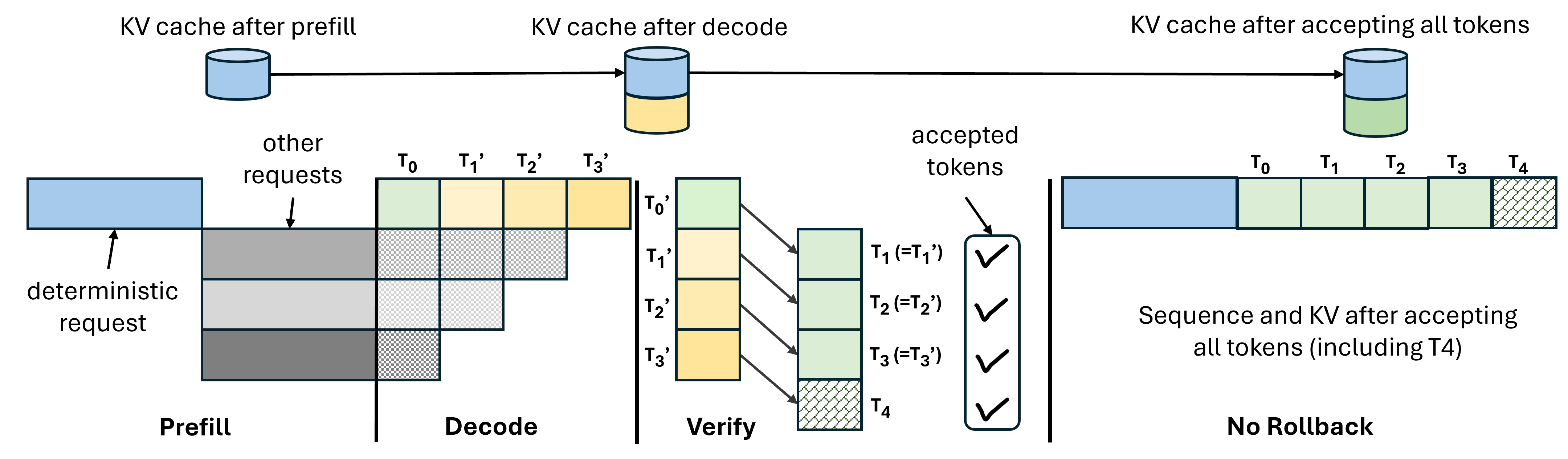
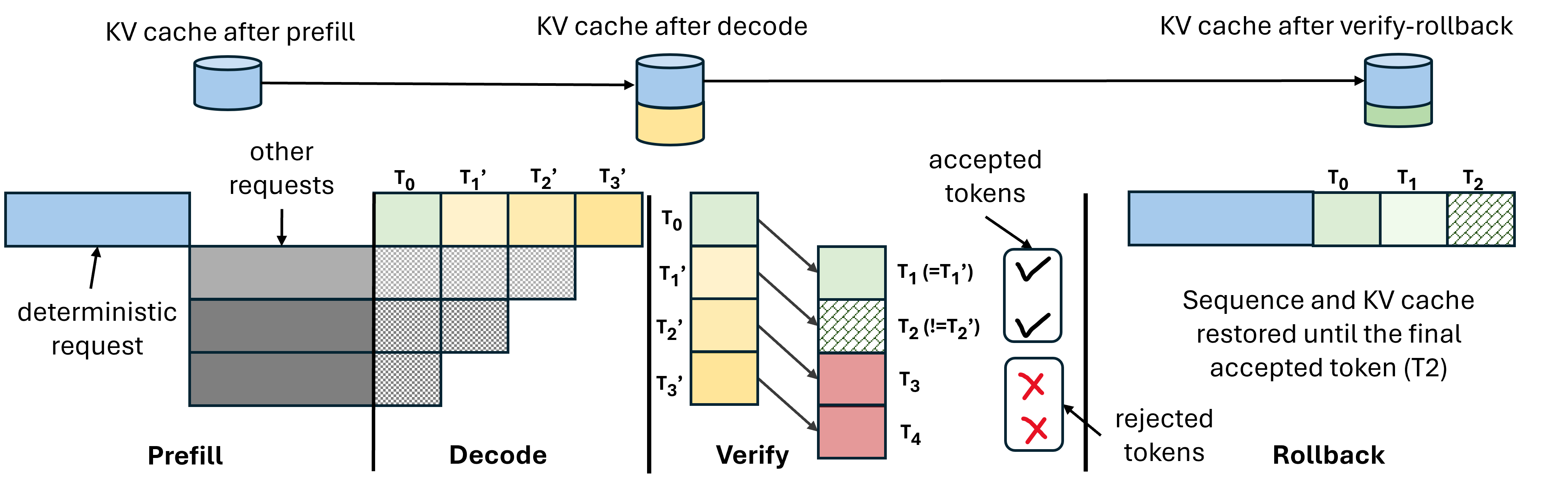
Figure 8: DVR without rollbacks.
Verification incurs negligible overhead per token for moderate-sized windows, benefiting from compute-bound kernels, whereas smaller verification windows inflate memory-bound costs. Rollback and recomputation rates are empirically low across workloads, with more than half of requests completing without rollback.
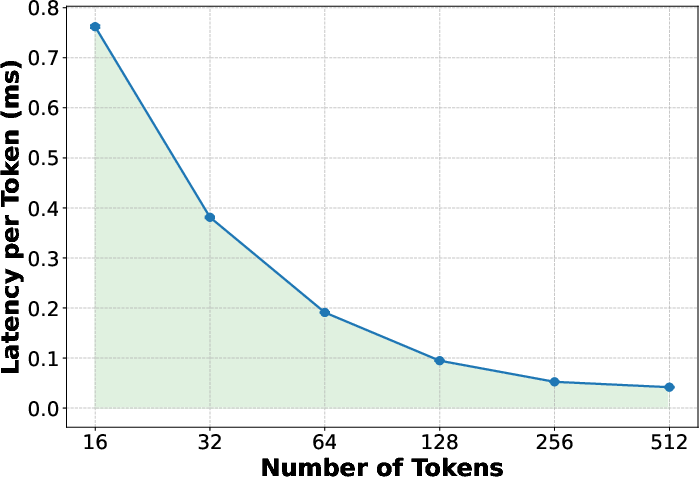
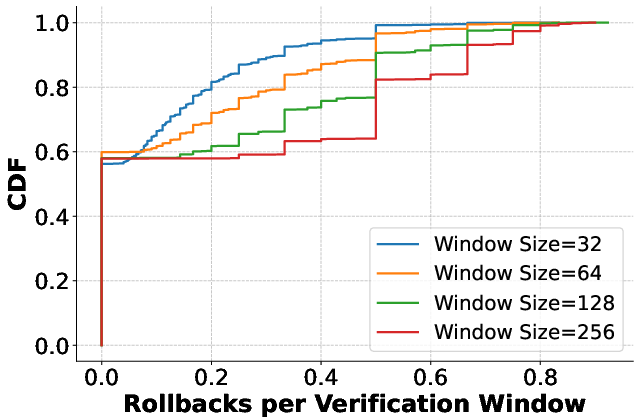
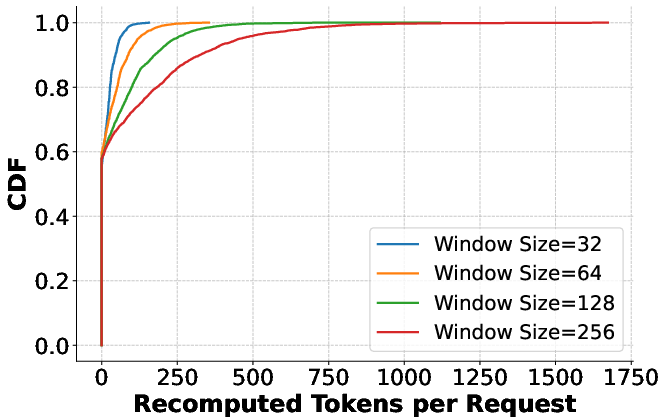
Figure 9: Verification latency.
Grouped verification further amortizes verification and recomputation overheads: rather than large windows per request (expensive on recomputation), small windows across multiple requests enable high utilization with low recomputation penalties.
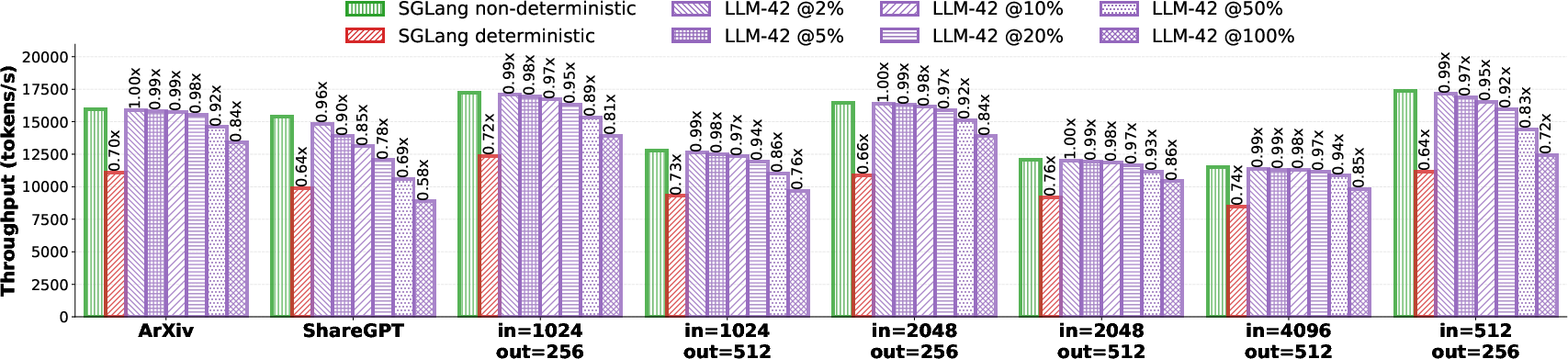
Figure 10: Throughput in offline inference under selective determinism.
System Evaluation and Numerical Results
Comparative experiments using the Llama-3.1-8B-Instruct model benchmark LLM-42 against SGLang baselines:
- Enabling determinism in SGLang (batch-invariant) reduces throughput by 24–36%, but LLM-42 retains >94% performance for up to 50% deterministic traffic.
- At 10% deterministic request ratio, LLM-42 outperforms SGLang-Deterministic by up to 48% throughput.
- Rollback and recomputation rates are modest: even at 100% deterministic traffic, average recomputation rarely exceeds 10.97%, and rollbacks per request are less than one across 4096-request workloads.
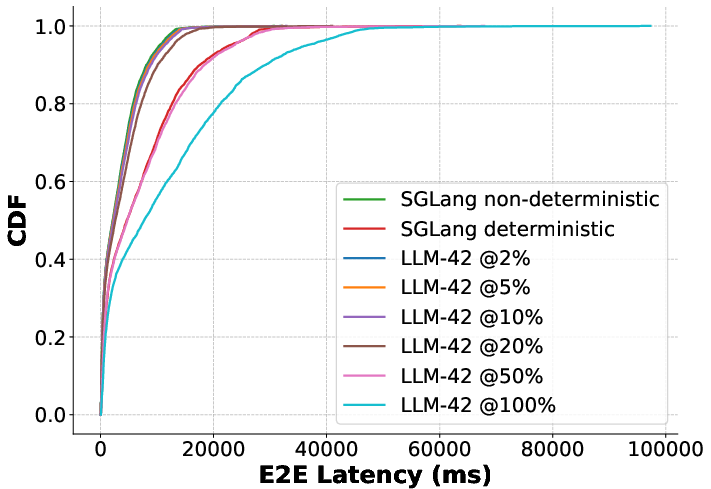
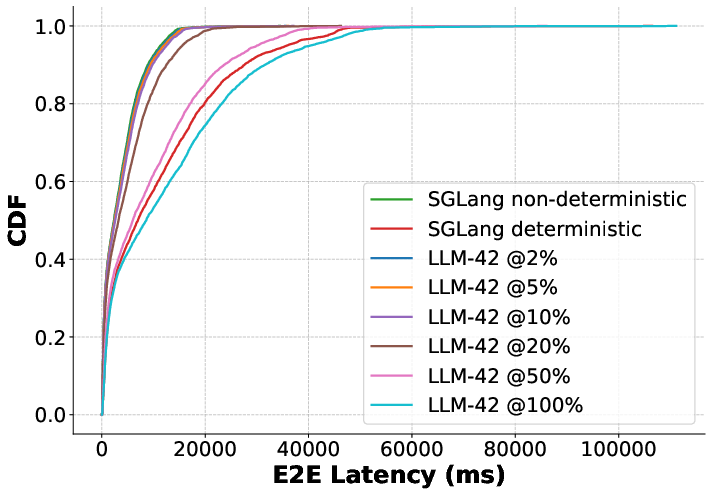
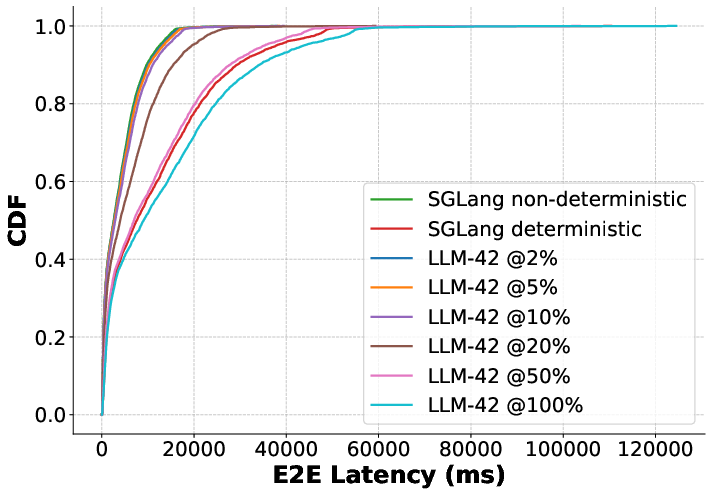
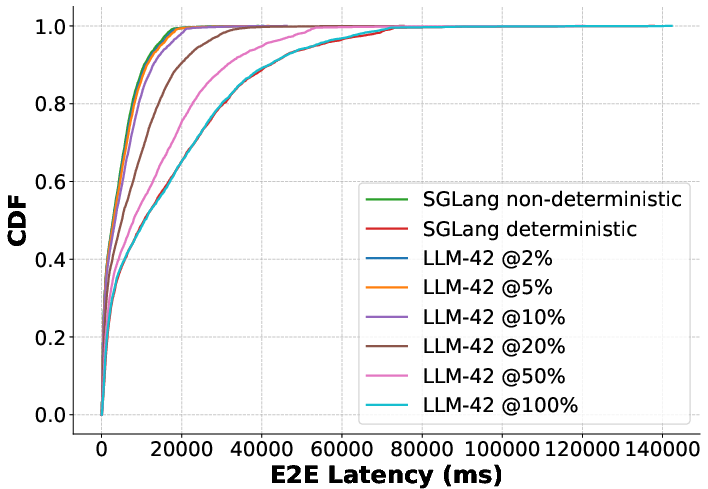
Figure 11: QPS=12.
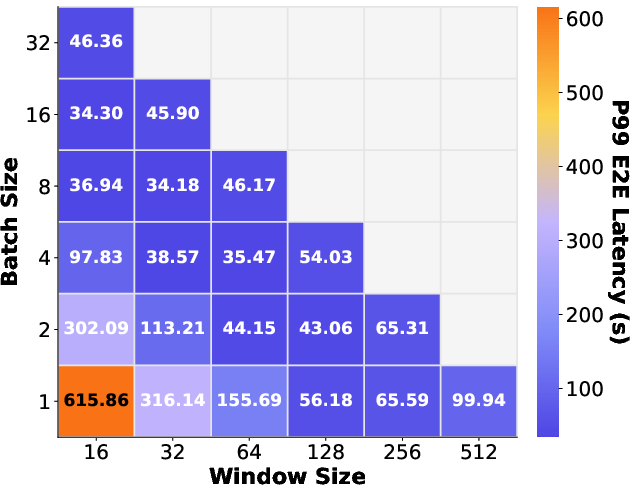
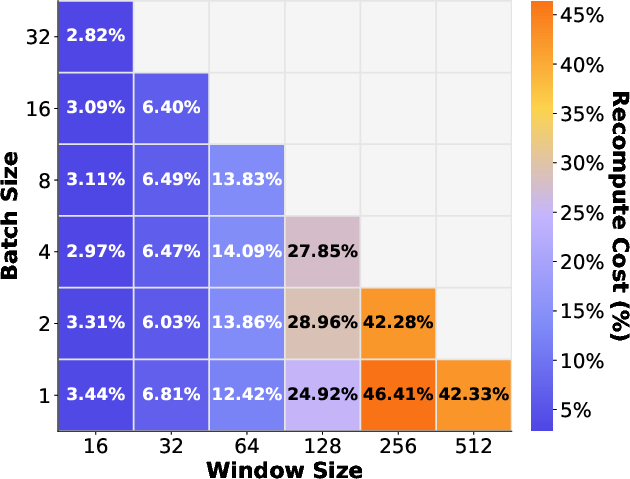
Figure 12: P99 latency in online inference.
In online (real-time) inference, delay penalties in LLM-42 scale monotonically with deterministic request fraction—at low ratios, median latency remains nearly optimal; even with 100% deterministic traffic, tail latencies remain substantially lower than baseline batch-invariant strategies.
Group verification parameters (window size and batch count) are ablated, demonstrating optimal P99 latency and recomputation trade-off with moderate (not maximal) window sizes and multi-request batching.
Practical and Theoretical Implications
LLM-42 demonstrates that deterministic inference can be reconciled with maximal throughput for LLM serving. By leveraging existing kernel optimizations, it avoids costly rewrites and supports selective, workflow-appropriate determinism. The protocol is compatible with advanced attention implementations (e.g., FA-3), contemporary sampling strategies, and KV cache management schemes.
Theoretically, this approach redefines the determinism efficiency frontier for LLM inference architectures, suggesting future systems can enforce reproducibility without disabling hardware or software optimizations.
Further research should consider hardware-aware verifier scheduling, integration with speculative decoding acceleration techniques (e.g., token trees or multi-headed prediction), and extending prefix cache invariance.
Conclusion
LLM-42 proposes an efficient, minimal-overhead protocol for deterministic LLM inference by leveraging speculative decoding principles and separating fast-path token generation from deterministic verification. The protocol enables selective, workload-driven determinism, retaining hardware efficiency and minimizing engineering overhead. Empirical results establish that throughput and latency penalties scale with deterministic traffic fraction, not globally, and are dominated by parameters of grouped verification. LLM-42 extends the state-of-the-art in reproducible, traceable LLM deployment, reconciling practical system constraints with scientific demands for reproducibility (2601.17768).