SAW-INT4: System-Aware 4-Bit KV-Cache Quantization for Real-World LLM Serving
Abstract: KV-cache memory is a major bottleneck in real-world LLM serving, where systems must simultaneously support latency-sensitive small-batch requests and high-throughput concurrent workloads. Although many KV-cache compression methods improve offline accuracy or compression ratio, they often violate practical serving constraints such as paged memory layouts, regular memory access, and fused attention execution, limiting their effectiveness in deployment. In this work, we identify the minimal set of 4-bit KV-cache quantization methods that remain viable under these constraints. Our central finding is that a simple design--token-wise INT4 quantization with block-diagonal Hadamard rotation--consistently achieves the best accuracy-efficiency trade-off. Across multiple models and benchmarks, this approach recovers nearly all of the accuracy lost by naive INT4, while more complex methods such as vector quantization and Hessian-aware quantization provide only marginal additional gains once serving compatibility is taken into account. To make this practical, we implement a fused rotation-quantization kernel that integrates directly into paged KV-cache layouts and introduces zero measurable end-to-end overhead, matching plain INT4 throughput across concurrency levels. Our results show that effective KV-cache compression is fundamentally a systems co-design problem: under real serving constraints, lightweight block-diagonal Hadamard rotation is a viable method that delivers near-lossless accuracy without sacrificing serving efficiency.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tackles a very practical problem in running LLMs: they need a lot of memory to store their “notes” while thinking. These notes are called the KV cache (short for Key–Value cache). As conversations get longer, this KV cache grows fast and can become the main thing slowing systems down.
The authors ask: can we shrink these notes to 4-bit size (very small) without breaking the model’s smarts or slowing down real-world servers? They show that a simple trick—mixing the numbers a bit before saving them (called a block-diagonal Hadamard rotation) and then using 4-bit integers—keeps the models accurate and fast in real deployments.
What questions did the researchers try to answer?
- Which KV cache compression methods actually work in real, production LLM servers (not just in lab tests)?
- How simple can an effective solution be?
- Can we get 4× smaller KV cache (using 4-bit integers) while keeping accuracy close to full precision?
- Can we implement it so it adds basically zero extra delay when the model is responding?
How did they approach it? (With simple explanations)
First, a few key ideas in everyday terms:
- KV cache: Think of it as the model’s running notes or bookmarks about what’s already been said, so it can pay attention properly as it generates new words.
- Quantization: Like storing numbers with fewer digits to save space. Here, “INT4” means each number uses only 4 bits, which is very compact (about 4× smaller than typical formats).
- Rotation (Hadamard rotation): Imagine shuffling and mixing the parts of a vector so that any one “spiky” value gets spread out. This makes it easier to store in fewer bits without losing important information.
- Block-diagonal: Instead of mixing all parts at once (which can be slow), you split the vector into chunks and mix each chunk separately—faster and friendlier for GPUs.
- System constraints: Real LLM servers use paged memory (fixed-size blocks) and highly optimized kernels (like FlashAttention). Any method that needs messy memory access or extra lookup tables tends to slow servers down.
What they did:
- They tested several KV compression methods that could fit into real serving systems:
- Naive token-wise INT4 (simple but often breaks accuracy)
- Vector quantization (cluster-based codebooks)
- Hessian-aware quantization (uses statistics to guide rounding)
- Rotation-based quantization (mix numbers first, then compress)
- They focused on “token-wise” methods (compress each token independently) because that matches real server layouts and speeds.
- They built a fast, fused GPU kernel that combines the rotation and quantization in one pass, fitting neatly into paged memory and FlashAttention, so it doesn’t add extra overhead.
- They measured both accuracy on many benchmarks and real serving throughput/latency on production-style workloads.
What did they find? (Main results and why they matter)
Big picture: A simple, system-friendly recipe works best.
- The recipe: Do a block-diagonal Hadamard rotation, then apply token-wise INT4. That’s it.
- Naive INT4 often collapses accuracy on some models (scores near zero). Adding rotation recovers almost all of that loss.
- More complex methods (like vector quantization with large codebooks or Hessian-aware techniques) gave only tiny extra gains once rotation was used—but they were harder to deploy and often slower under real constraints.
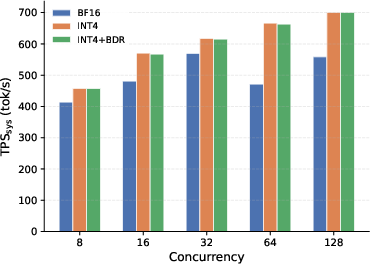
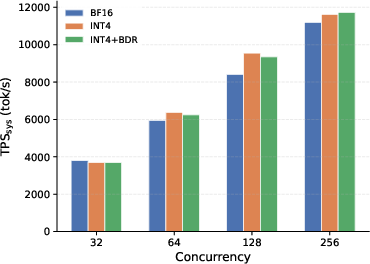
- The fused rotation+INT4 kernel had essentially zero measured end-to-end overhead compared to plain INT4. In other words, it’s as fast as the simple approach, but with much better accuracy.
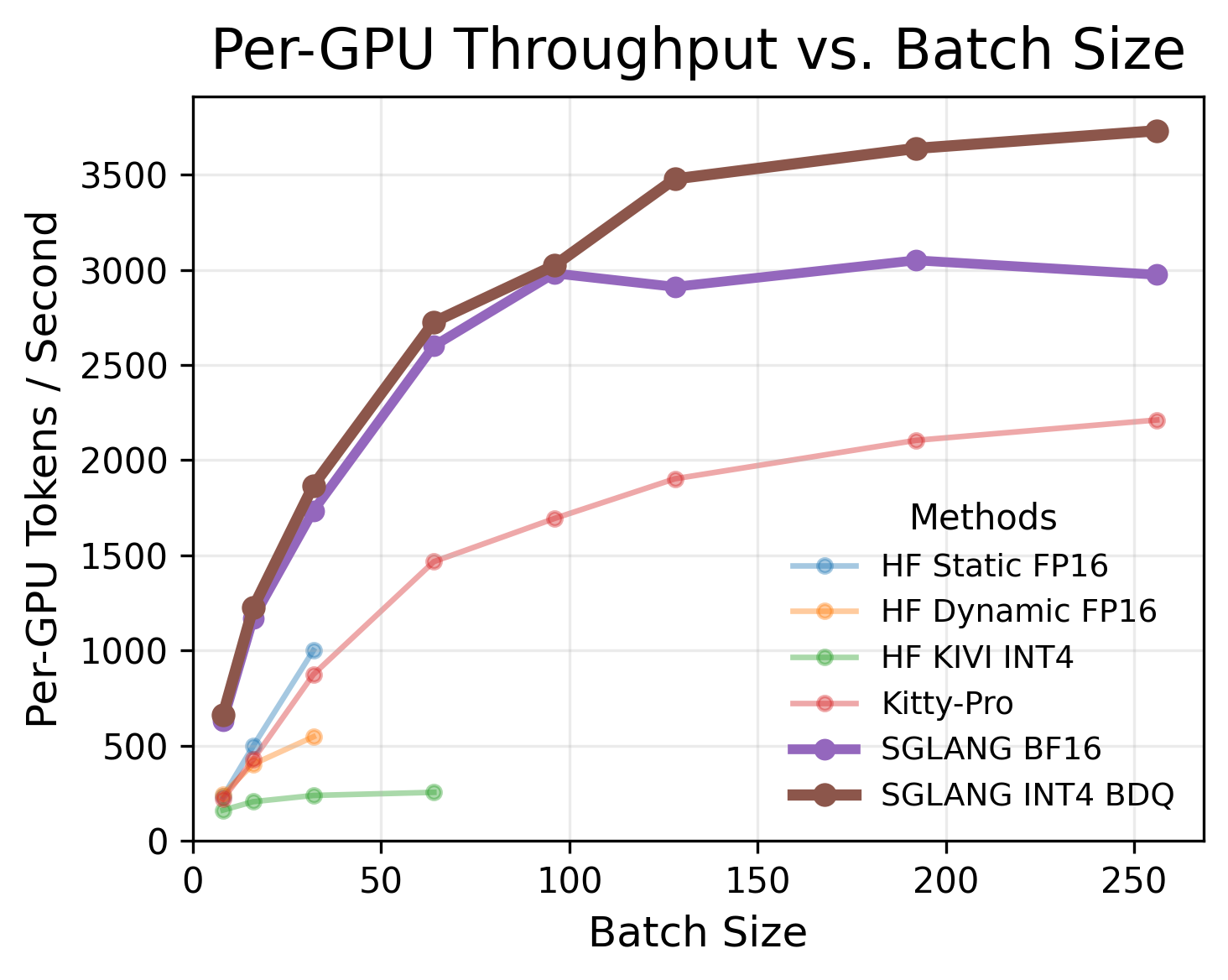
- On multiple models (e.g., Qwen3-4B, Qwen3-8B, Qwen3-32B, GLM-4.7), across tasks like coding and math, rotation+INT4 kept accuracy close to full precision (BF16) while keeping the 4× memory savings and high throughput.
- In many cases, rotating just the “keys” (K) was enough to get most of the benefits (even simpler and faster).
A concrete example (simplified):
- For Qwen3-4B:
- Full precision (BF16): good accuracy.
- Naive INT4 (no rotation): accuracy ~0 on tested tasks.
- INT4 + rotation: accuracy climbs back close to BF16, while keeping speed and memory benefits.
- Throughput: INT4 + rotation matched plain INT4 speed (within measurement noise) and was faster than full precision because the cache is smaller.
Why this matters:
- You can serve more users or longer contexts on the same GPUs (because the KV cache is 4× smaller).
- You don’t have to accept big accuracy losses to get those savings.
- The method is simple enough to fit into real, optimized servers without slowing them down.
Why not the fancy stuff?
- Vector quantization (with codebooks) and Hessian-aware methods can look good in isolated tests, but they often need irregular memory lookups or extra passes that don’t fit well with paged memory and fused attention kernels. This hurts real-world speed.
- Once you add the simple rotation, the extra accuracy gains from complex methods are small and usually not worth the added complexity and deployment cost.
What does this mean for the future?
- Effective KV cache compression isn’t just a math problem—it’s a systems co-design problem. You have to make the method fit cleanly into how real servers manage memory and run attention kernels.
- A practical guideline:
- Use token-wise INT4 for KV cache (4× smaller).
- Add block-diagonal Hadamard rotation (block sizes around 64–128 often work well).
- Fuse rotation into the existing attention path so there’s no extra pass over memory.
- Consider rotating only the keys (K) for a simpler, near-equal win.
- This makes long-context and high-concurrency LLM serving more affordable and scalable, helping bring better AI experiences to more users without huge hardware costs.
In short: By mixing the numbers a little before compressing them, you can keep the model smart, make it fast, and save a lot of memory—all in a way that actually works on real servers.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, written to guide concrete next steps for future research.
- External validity across broader model families: Results are limited to Qwen3 (4B/8B/32B) and GLM-4.7; robustness on other architectures (e.g., Llama, Mistral, Phi, Mixtral/MoE, encoder–decoder models) is untested.
- Attention variants and architectural diversity: Compatibility and efficacy with MLA, GQA variants beyond those implicitly present, KV-sharing, mixture-of-experts routing, and transformer hybrids (e.g., state space models) are not evaluated.
- Ultra-long context operation: Accuracy and throughput are not measured at 1M–10M token contexts where KV-cache pressures are most extreme; interactions with RoPE scaling, QK-norm, and long-range outliers remain uncharacterized.
- Decoding regime coverage: Experiments use temperature T=0.6 and specific “thinking mode”; impact under greedy decoding, beam search, diverse sampling temperatures, and speculative decoding remains open.
- Task breadth and real-world workloads: Benchmarks focus on five reasoning/coding tasks; generalization to instruction-following, dialogue, multilingual tasks, long-form summarization, RAG with long contexts, or tool-use workflows is unknown.
- Tail-latency and P99 behavior: Throughput is reported, but latency distributions (e.g., P95/P99) under continuous batching and variable loads are not analyzed.
- Hardware generality: Results on H100 GPUs may not transfer to A100, L40/L40S, consumer GPUs, AMD MI series, or TPUs; sensitivity to NVLink vs. PCIe and MIG partitioning is unmeasured.
- Serving-engine portability: Integration is described in a Triton/FlashAttention-style kernel; viability and maintenance burden across vLLM, SGLang, TensorRT-LLM, and PyTorch SDPA kernels are not demonstrated.
- Multi-node and 3D parallelism: Behavior with pipeline/tensor parallelism across multiple nodes (NVLink/InfiniBand/PCIe interconnects) and communication overheads for rotated/dequantized paths are not studied.
- Offloading and tiered memory: Interactions with CPU/NVMe KV offloading and prefetching (compression/decompression costs, bandwidth constraints) are unexplored.
- Page layout and fragmentation: Effects of page sizes, fragmentation, and allocator policies on the proposed token-wise INT4 + BDR method (especially at extreme sequence lengths) are not quantified.
- Small-batch, latency-sensitive scenarios: Claims of “zero measurable overhead” need validation under very small batch sizes and single-request latency-critical settings common in production.
- Cost of per-token scales/zero-points: The overhead of computing/storing asymmetric per-token, per-head scales and zero-points (min/max reductions, packing) is not isolated or stressed across high-concurrency settings.
- Determinism and reproducibility: Sensitivity to randomized Hadamard sign patterns, block partitioning choices, and seeds is not reported; variance across runs and seeds is not systematically assessed.
- Block-size selection strategy: No principled or hardware-aware method is provided to choose per-layer/per-head block sizes (e.g., adaptive auto-tuning to maximize accuracy–throughput on a given platform).
- Layer/head selectivity: Whether only a subset of layers/heads require rotation to recover accuracy (to save compute) is not explored; fine-grained sensitivity analysis is missing.
- K-only vs. K+V rotation/quantization: While K-only rotation can be sufficient in some cases, a systematic assessment of when to rotate/quantize V (and at what precision) across tasks/models is lacking.
- Lower-bit regimes: Applicability of BDR to INT3/INT2 (or mixed 2–4-bit) KV-cache compression is untested; how far bit-width can be pushed without violating serving constraints remains open.
- Composability with other compression: Interactions with low-rank KV, eviction at page granularity, entropy coding, or dynamic precision scheduling under load are not evaluated.
- Vector-quantization feasibility under fused kernels: The paper assumes codebook lookups are prohibitive; it does not test optimized fused VQ kernels (e.g., codebook in shared/constant memory, warp-synchronous lookups) as a potential path to make VQ system-compatible.
- Error accumulation over long horizons: Whether quantization noise compounds over tens/hundreds of thousands of decode steps (e.g., long chain-of-thought) is not assessed.
- Theoretical characterization: There is no formal analysis or bounds on quantization error with block-diagonal rotations, nor criteria predicting when naïve INT4 collapses and BDR succeeds.
- Model robustness factors: GLM-4.7 is robust to naïve INT4 while Qwen3 is fragile; root causes (activation/attention statistics, normalization schemes, training recipes) are not analyzed.
- RoPE and position encoding interactions: Potential position-dependent outliers at large positions and their interaction with BDR + INT4 are not quantified.
- Fairness of throughput comparisons: Some baselines (e.g., Kitty, KMeans) are measured in non-paged engines (Hugging Face generate) while others use optimized engines (SGLang), muddying apples-to-apples comparisons.
- Energy efficiency and cost: Power consumption, joules/token, and cost-per-token under BDR vs. baselines are not reported.
- Multimodal KV caches: Efficacy of BDR on vision/audio/token-fused caches with different statistics is untested.
- Robustness to distribution shift: The effect of training vs. serving distribution mismatch on Hessian-aware or rotation-based schemes is not studied; calibration dependence is only briefly touched.
- Online/adaptive strategies: The paper does not explore dynamic block sizes/rotations or online scale adaptation based on runtime statistics or load conditions.
- Deployment maintainability: Kernel complexity, integration effort, and long-term maintainability across rapidly evolving serving stacks are not discussed.
- Open-source availability and reproducibility: End-to-end code, kernels, and calibration pipelines are not explicitly released/validated for community reproduction.
Practical Applications
Practical Applications of SAW-INT4 (System-AWare 4-Bit KV-Cache Quantization)
SAW-INT4 demonstrates that token-wise INT4 KV-cache quantization combined with block-diagonal Hadamard rotation (BDR) and a fused rotation–quantization kernel can yield near-BF16 accuracy while preserving INT4-level serving efficiency under real-world constraints (paged memory, fused attention, continuous batching). Below are actionable applications, grouped by deployment timeline, with sector links and feasibility notes.
Immediate Applications
These can be deployed now with modest engineering effort on modern serving stacks (e.g., vLLM, SGLang, TensorRT-LLM) that use paged KV layouts and FlashAttention-style kernels.
- AI infrastructure and cloud (Serving engines, MLOps)
- Drop-in 4× KV-memory reduction for higher concurrency and longer contexts
- Use case: Increase request concurrency and/or context length without adding GPUs by replacing BF16 KV-cache with INT4+BDR.
- Tools/workflows:
- Engine plugins for paged KV with fused rotation–dequant (Triton/CUDA kernels).
- Capacity planners: recompute max-batch and context budgets with 4× smaller KV pages.
- Autoscaling policies tuned to new memory/throughput envelopes.
- Assumptions/dependencies:
- Requires a fused dequant+rotation decode kernel integrated with FlashAttention/PagedAttention.
- Works best on NVIDIA-class GPUs with high memory bandwidth; tested on H100 in paper.
- Per-token, per-head scales/zero-points metadata must be stored alongside KV.
- Cost and energy savings in multi-tenant LLM services
- Use case: Lower /user by packing more tenants per GPU with minimal Quality-of-Service impact.
- Tools/products: “INT4-KV” SKUs in model-as-a-service; green-ops dashboards tracking memory bandwidth/energy per token.
- Assumptions/dependencies:
- Quality verified via A/B tests; some models (e.g., Qwen3) need rotation to avoid quality collapse, while robust models (e.g., GLM-4.7) tolerate INT4 better.
- SLA-preserving latency for latency-sensitive, small-batch workloads
- Use case: Maintain sub-100 ms/token latencies for chat, copilots, and agentic tools while increasing concurrency.
- Tools/workflows: SLO-aware routing rules favor INT4+BDR for decode; canary deploy and automatic rollback.
- Assumptions/dependencies:
- The fused kernel must avoid extra global-memory passes; otherwise latency increases.
- Enterprise applications (SaaS, support, analytics)
- Long-context chat and support agents at lower cost
- Sectors: Customer support, HR, legal; Contact centers.
- Use case: Sustain 32k–256k+ token sessions with better user density per GPU.
- Tools/products: SaaS chat platforms offering “extended context” tiers powered by INT4+BDR.
- Assumptions/dependencies:
- Realized gains depend on the app’s typical context lengths and decode-dominated workloads.
- High-throughput document and email summarization
- Sectors: Legal, media, operations.
- Use case: Process larger batches or documents per GPU-hour.
- Assumptions/dependencies:
- Prefill stages may still be compute-bound; the biggest gains appear in memory-bound decode phases.
- Developer tools and software engineering
- Scalable code copilots and CI assistants
- Use case: Maintain project-scale context (multi-file, long history) for more users per GPU without latency penalties.
- Tools/workflows: Integrate INT4+BDR into serverless functions backing IDE extensions; usage-based throttling updated for new capacity.
- Assumptions/dependencies:
- Quality-sensitive tasks (e.g., exact code generation) should be validated per model with benchmark suites (HumanEval, LiveCodeBench).
- Healthcare and finance (privacy-sensitive deployments)
- On-prem long-context assistants with smaller GPU footprints
- Use case: Hospitals/financial institutions deploy on fewer GPUs while supporting longer EHR timelines or case histories.
- Tools/products: “Compliance-ready” on-prem bundles (vLLM/SGLang + fused INT4+BDR).
- Assumptions/dependencies:
- Regulatory validation; local A/B testing to ensure no material task degradation.
- Education and knowledge management
- Course-long tutoring sessions and large knowledge-base assistants
- Use case: Institutions offer longer, more contextual tutoring without expanding hardware.
- Assumptions/dependencies:
- Ensure dialog quality under longer contexts remains near BF16-level for the specific model.
- Research operations (Academia/industry R&D)
- Serving-aware benchmarking and baselines
- Use case: Adopt SAW-INT4 as the baseline for “serving-compatible” KV compression in evals, replacing offline-only methods.
- Tools/workflows: Standardized evaluation pipelines that measure both task accuracy and end-to-end throughput on paged engines.
- Assumptions/dependencies:
- Access to fused kernels; comparable decode settings across methods.
- Sustainability and policy
- Immediate carbon and energy reductions in LLM inference
- Use case: Report lower energy per token by reducing memory traffic via 4-bit KV packs.
- Tools/workflows: Carbon accounting frameworks incorporate “KV bitwidth” and memory-traffic metrics.
- Assumptions/dependencies:
- Actual savings depend on workload mix (decode-heavy tasks see the largest benefit) and data center PUE.
Long-Term Applications
These require further research, engineering, or ecosystem changes (standardization, hardware support) to realize.
- Hardware–software co-design for KV quantization
- In-hardware support for Hadamard/block rotations and 4-bit dequant
- Sectors: Semiconductor, systems.
- Potential products: GPU/AI-accelerator instructions or tensor cores optimized for Hadamard-like orthogonal transforms and INT4 dequant in attention.
- Dependencies/assumptions:
- ISA extensions and vendor adoption; compatibility with existing paged-attention kernels.
- Standardization of paged KV formats with quantization metadata
- Interoperable KV-cache formats across serving engines
- Sectors: AI infrastructure standards bodies, ONNX community.
- Potential outcomes: ONNX/MLIR extensions for paged KV with per-token scale/zero-point; engine-agnostic checkpoints.
- Dependencies/assumptions:
- Agreement on metadata schemas; backward compatibility paths.
- Adaptive, model-aware quantization policies
- Dynamic block sizes and key-only rotation per layer/model
- Use case: Online adaptation of BDR block size (e.g., 64 vs. 128) based on observed activation statistics and SLOs.
- Tools/workflows: Runtime policies that adjust quantization knobs per layer/model family; telemetry-driven controllers.
- Dependencies/assumptions:
- Low-overhead statistics collection; careful guardrails to prevent jitter in latency.
- Extending accuracy–efficiency frontier beyond 4 bits
- Robust 3-bit/2-bit KV with serving compatibility
- Research direction: Combine BDR with selective outlier handling that preserves paged-uniform precision (e.g., page-level, not mixed within page).
- Dependencies/assumptions:
- Avoid cross-token/channel dependencies; preserve coalesced access patterns. Requires new kernels and rigorous E2E validation.
- Multi-modal and streaming applications
- Long-context VLMs and speech agents with compressed KV
- Sectors: Media, automotive, robotics.
- Use case: Support longer video/audio contexts for reasoning and summarization; on-vehicle assistants with constrained GPUs.
- Dependencies/assumptions:
- Verify robustness for modality-specific KV statistics; adapt rotation/packing for heterogeneous heads.
- Memory-tiering and scheduling synergy
- Better GPU–CPU/NVMe KV paging using quantized pages
- Use case: Smaller 4-bit pages reduce PCIe/NVLink bandwidth and paging overhead, enabling deeper contexts with memory tiering.
- Tools/workflows: Schedulers that prefetch and evict quantized pages; policies tuned to page sizes and attention access patterns.
- Dependencies/assumptions:
- Engine support for quantized page management; careful handling of fragmentation and QoS.
- Regulatory and procurement guidance for “serving-aware efficiency”
- Policy frameworks that encourage system-compatible compression
- Sectors: Public sector IT, enterprise procurement.
- Outcomes: RFP criteria that require system-aware evaluations (paged memory compatibility, fused kernels) rather than offline metrics alone.
- Dependencies/assumptions:
- Consensus on evaluation benchmarks and reporting; vendor transparency.
- Consumer and edge AI
- On-device or near-edge long-context assistants
- Use case: Phones, AR/VR, vehicles benefit from lower KV bandwidth and memory footprints.
- Dependencies/assumptions:
- Efficient INT4 kernels on NPUs/edge accelerators; model sizes and contexts tailored to device constraints.
Notes on Feasibility and Assumptions Common Across Applications
- Serving constraints are non-negotiable: paged memory layouts and fused attention kernels must be preserved; methods with codebook lookups or mixed-precision pages harm E2E throughput.
- The proposed method is calibration-light: randomized block-diagonal Hadamard rotations avoid heavy data-driven calibration; “key-only rotation” often suffices.
- Gains are model-dependent: some models (e.g., Qwen3) require rotation to avoid collapse; others (e.g., GLM-4.7) are more tolerant even with naive INT4.
- Throughput improvements are realized at the system level: kernel microbenchmarks may show small overheads, but fused rotation removes additional passes over KV memory, keeping E2E performance in line with plain INT4.
- Hardware/engine availability: Results assume modern GPUs and serving engines with PagedAttention/FlashAttention and the ability to integrate a fused kernel.
Glossary
- Activation outliers: Extremely large activation values in a few channels that distort low-bit quantization and degrade accuracy. "A central challenge is activation outliers:"
- Asymmetric INT4: A 4-bit quantization scheme using per-vector scale and zero-point to represent signed ranges without symmetry around zero. "We adopt an asymmetric token-wise INT4 scheme"
- Autoregressive decoding: Generating tokens sequentially where each step depends on previous outputs, stressing memory bandwidth. "Because autoregressive LLM decoding is predominantly memory-bandwidth-bound"
- Basis-Transforms: Linear transforms of feature space (e.g., PCA/SVD) used as a basis change; often expensive at inference time. "Basis-Transforms: PCA/SVD methods require on-the-fly matrix-vector multiplications, inflating register pressure and destroying kernel tiling efficiency."
- BF16: Brain floating point 16-bit format used as a common “full precision” baseline for activations in serving. "BF16 denotes the full-precision KV cache"
- Block-diagonal Hadamard rotation: Applying Hadamard transforms in independent blocks to spread energy across dimensions and reduce outliers efficiently. "token-wise INT4 quantization with block-diagonal Hadamard rotation"
- Block-Diagonal Rotation (BDR): An orthogonal rotation applied per block along the head dimension before quantization to mitigate outliers. "Block-Diagonal Rotation (BDR) is the key enabler; complexity yields diminishing returns."
- Channel-Wise Scaling: Using scaling factors per channel that can cause cross-block memory access issues in paged layouts. "Channel-Wise Scaling: Because tokens span non-contiguous blocks, computing shared scaling factors across channels \citep[e.g.,] []{kivi} requires highly inefficient cross-block memory access."
- Codebook Lookups: Fetching centroid vectors during dequantization in vector quantization, which creates irregular memory access. "Codebook Lookups: Vector quantization \citep[e.g.,] []{commutative-vector-quantization} requires global memory lookups during dequantization, increasing latency and bandwidth pressure."
- Continuous batching: Dynamically batching multiple requests to improve throughput in serving engines. "lacks continuous batching and PagedAttention"
- Dequantization: Converting low-bit integers back to higher-precision values, ideally fused within the attention kernel. "dequantization must be fused in-kernel"
- FlashAttention: A memory-efficient attention kernel family that streams K/V tiles to maximize throughput. "FlashAttention style kernels that read directly from the paged buffer"
- Fused rotation--quantization CUDA kernel: A single GPU kernel that applies rotation and quantization together to avoid extra memory passes. "We develop a fused rotation--quantization CUDA kernel"
- Grouped-query attention (GQA): An attention variant that groups heads to reduce KV memory footprint. "grouped-query attention (GQA)"
- Hadamard matrix: A structured orthogonal matrix with entries ±1 used for efficient rotations. "where is a Hadamard matrix."
- Hadamard transforms: Fast orthogonal transforms using Hadamard matrices to redistribute energy and suppress outliers. "randomized Hadamard transforms"
- Head dimension: The dimensionality of each attention head’s key/query/value vector. "Let be the head dimension."
- Hessian-aware quantization: Quantization guided by second-order (Hessian or covariance) information to reduce error in sensitive directions. "Hessian-aware quantization performs markedly worse than BDR-128"
- INT4: 4-bit integer quantization format for activations, offering 4× memory reduction compared to BF16. "INT4 denotes uniform 4-bit quantization."
- Kernel tiling efficiency: The effectiveness of processing data in tiles within a GPU kernel; poor layouts can degrade it. "destroying kernel tiling efficiency."
- Key–value (KV) cache: Stored past keys and values enabling attention over prior tokens during autoregressive decoding. "KV-cache memory is a major bottleneck in real-world LLM serving"
- KMeans vector quantization: Using KMeans-learned centroids to encode vectors (often with residuals) instead of scalar quantization. "vector quantization (KMeans)~\citep{flashkmeans2026,xi2026quantvideogen}"
- Low-rank decomposition methods: Techniques that project K/V into lower-dimensional subspaces to reduce memory and compute. "low-rank decomposition methods"
- Memory coalescing: Aligning memory accesses so adjacent threads read contiguous addresses, critical for GPU efficiency. "destroying the memory coalescing required by GPU attention kernels."
- Memory-bandwidth-bound: A regime where performance is limited by memory transfer speed rather than compute. "predominantly memory-bandwidth-bound"
- Mixed-Precision: Using different bit-widths for different data parts to balance efficiency and accuracy. "Mixed-Precision: Methods using varying bit-widths \citep[e.g.,] []{xia2025kittyaccurateefficient2bit} break the uniform layout required for efficient page table indexing."
- Multi-head attention (MHA): Standard attention mechanism with multiple parallel heads. "standard multi-head attention (MHA)"
- Multi-head latent attention (MLA): An attention variant designed to reduce per-token KV memory. "multi-head latent attention (MLA)"
- Orthonormal transform: A transformation by an orthogonal matrix that preserves norms while redistributing energy. "we apply an orthonormal transform to rotate the KV-cache"
- Orthogonal rotation: A rotation by an orthogonal matrix used to reduce quantization sensitivity to outliers. "orthogonal rotation is the single most important ingredient for effective INT4 KV-cache quantization"
- Outlier-aware encoding: Encoding schemes that handle rare large magnitudes explicitly to improve low-bit fidelity. "outlier-aware encoding to achieve 2–4 bit compression with minimal quality loss."
- Paged memory layouts: Organizing KV cache in fixed-size non-contiguous blocks to support dynamic batching. "paged memory layouts"
- PagedAttention: A serving primitive that manages KV in pages to enable dynamic batching with high throughput. "PagedAttention manages cache memory in fixed-size, uniform-type blocks"
- PCA/SVD: Dimensionality-reduction transforms (Principal Component Analysis/Singular Value Decomposition) used as basis changes. "PCA/SVD methods require on-the-fly matrix-vector multiplications"
- Pre-softmax logits: The raw attention scores computed before applying softmax. "The pre-softmax logits are computed as"
- Quantization grid: The discrete set of representable values after quantization defined by scale and bit-width. "expand the quantization grid"
- Residual buffer: A companion buffer storing unquantized recent K/V pairs alongside quantized ones. "maintain a fixed-length residual buffer of unquantized key--value pairs"
- Scale and zero-point: Parameters mapping real values to integers in asymmetric quantization. "using a per-token and per-head scale and zero-point."
- Scalar quantization: Quantizing each scalar independently, as opposed to vector or codebook-based methods. "Scalar quantization methods"
- Stiefel manifold: The space of orthonormal matrices; some methods learn rotations constrained to this manifold. "SpinQuant~\citep{spinquant} learns optimal rotations on a Stiefel manifold"
- TensorRT-LLM: An optimized LLM serving framework by NVIDIA focusing on high-throughput inference. "TensorRT-LLM~\citep{trtllm}"
- Token eviction: Removing selected tokens from the KV cache to save memory based on heuristics like attention scores. "Token Eviction: Evicting ``unimportant'' tokens"
- Token-wise quantization: Quantizing per token (and head) independently to preserve paged layouts and access patterns. "Token-wise quantization naturally operates independently on each token"
- Triton decode kernel: A GPU kernel written in Triton used to implement efficient decode-time attention. "In a Triton decode kernel, each program processes one query"
- Vector quantization: Encoding vectors using indices into a learned codebook, often with residuals. "Vector-quantization-based approaches~\citep{commutative-vector-quantization,kv-1bit}"
- vLLM: A production LLM serving engine optimized for paged attention and dynamic batching. "vLLM~\citep{vllm}"
Collections
Sign up for free to add this paper to one or more collections.