- The paper introduces LLM-PRISM, a comprehensive hardware-software fault injection methodology that characterizes silent data corruption from permanent GPU defects during LLM training.
- It employs RTL simulation and a seven-dimensional fault site tuple to map error signatures, revealing distinct failure modes such as spike-and-recover and silent degradation.
- Empirical analysis across FP16, BF16, and FP8 formats demonstrates critical trade-offs between crash risk and silent errors, influencing model convergence and reliability.
Characterizing Silent Data Corruption from Permanent GPU Faults in LLM Training: The LLM-PRISM Methodology
Motivation and Problem Statement
The LLM-PRISM study systematically investigates the resilience of LLM training to silent data corruption (SDC) from permanent and intermittent GPU hardware faults. Unlike transient faults arising from single bit-flips, permanent hardware defects—arising from test escapes, early-life failures, or silicon aging—can persist or intermittently corrupt values during extensive training runs, introducing subtle or catastrophic numerical errors. In large-scale LLM training infrastructure, where clusters employ tens of thousands of GPUs for weeks or months, the aggregate probability of encountering such faults is significant.
Permanent and intermittent SDC present unique threats: they may not crash the training run or introduce NaNs, and their impact can propagate silently, affecting not just convergence dynamics but downstream LLM behavior and overall reliability. This necessitates a detailed, hardware-grounded investigation of how these faults manifest, propagate, and interact with numerical format and system-level mitigations.
Hardware-Grounded Fault Characterization and Methodology
LLM-PRISM introduces an integrated hardware-software approach by coupling RTL-level GPU fault characterization with a software-level, parameterized fault injection engine deployed in Megatron-LM. The flow, depicted below, involves sampling permanent faults from plausible physical mechanisms (stuck-at and timing-dependent defects) using RTL simulation and mapping them to observable error signatures.
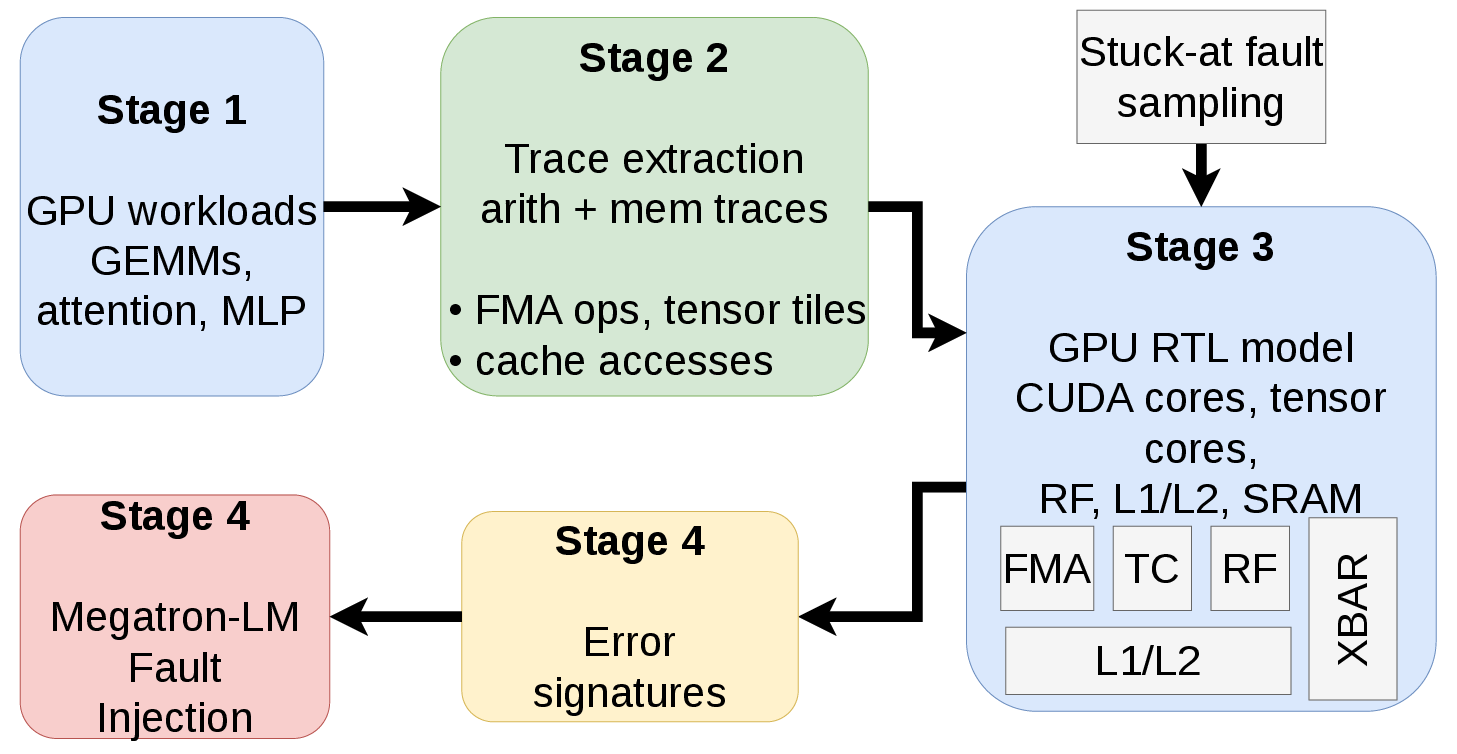
Figure 1: RTL characterization flow for error signature extraction.
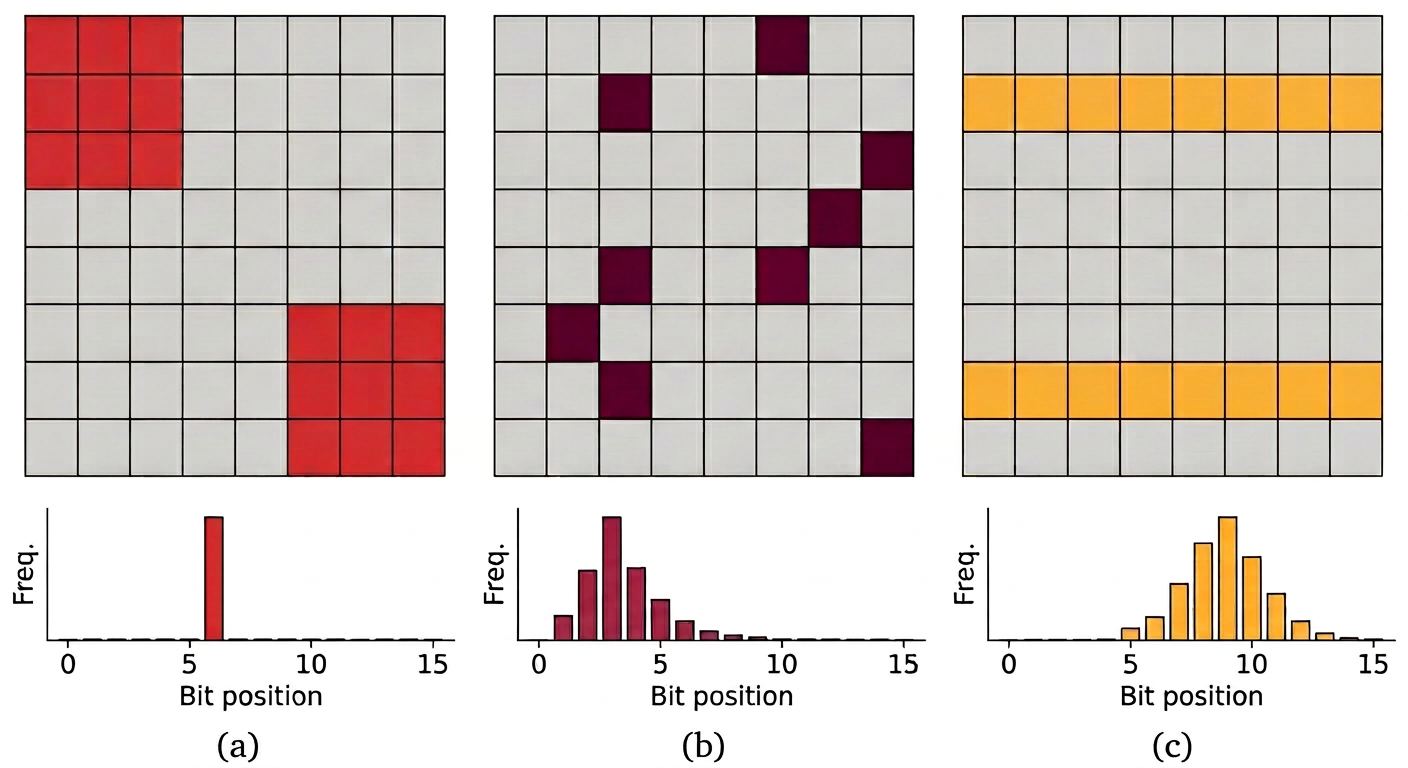
Empirical error signatures—collected from FMA datapaths, tensor cores, register files, and on-chip caches—show characteristic corruption patterns:
These signatures inform a rigorous seven-dimensional software-level “fault site tuple” parameterization, spanning spatial (device rank, layer, sub-module), temporal (injection onset, activation rate), and bit-level (fault density, bit-flip profile) aspects.
Figure 3: Software level fault site tuple characterized with seven parameters, categorizing temporal, spatial/architectural, and intensity/bit-level properties.
A Bernoulli parameter governs intermittent activation, unifying permanent (always-on, r=1) and intermittent (r≪1) defects in a common framework.
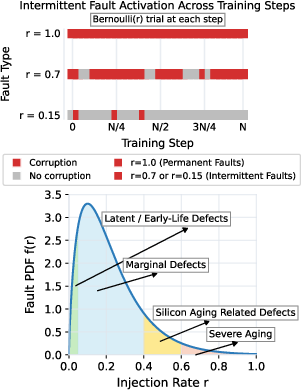
Figure 4: Stochastic Intermittent Fault Activation Model.
Experimental Design
The study executes 7,664 complete fault-injected training runs (4,681 on GPT-2 Small, 2,983 on GPT-2 Medium) using WikiText. The injection campaigns sweep fault types, numerical formats (FP16, BF16, FP8), rates, and target sites. The injection begins at variable checkpoints, affecting forward activations or backward gradients, allowing for fine-grained analysis of perturbation locality and timing.
The campaign rigorously isolates numerical format effects and employs both the model’s perplexity and downstream task scores to assess end-to-end impact.
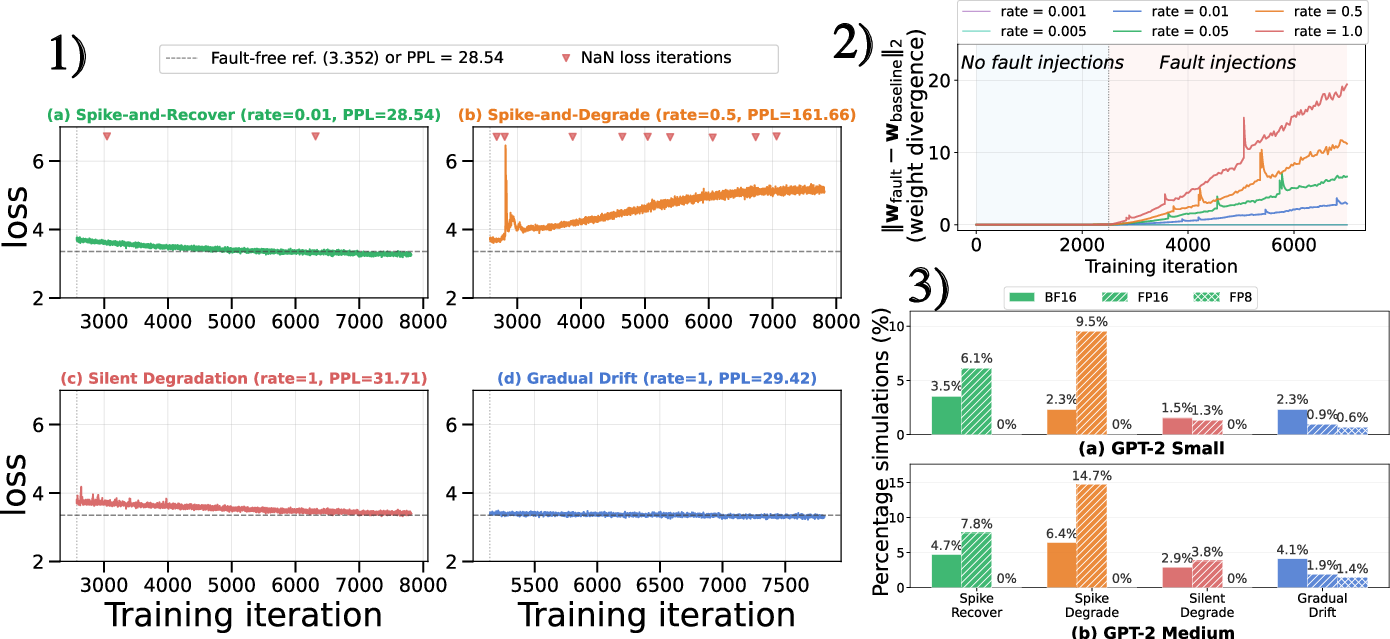
Failure Modes Induced by Permanent and Intermittent Faults
Full pre-training under permanent fault injection uncovers four qualitatively distinct failure modes, with empirical loss trajectories and parameter drift behavior:
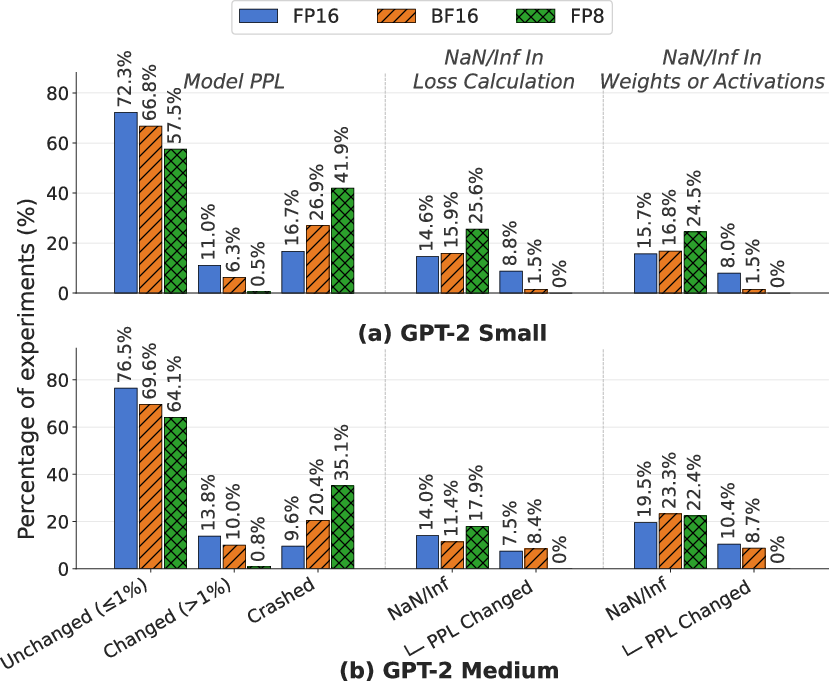
FP8 demonstrates strictly binary outcomes (recovery or crash), while FP16 and BF16 display more diverse modes, including silent degradations.
Analysis of final model quality, training loss anomalies, and NaN propagation reveals nuanced interactions between format, injection phase, and activation rate.
Downstream task evaluation of BF16 GPT-2 Medium runs demonstrates that models classified as silent degradation or gradual drift, despite near-baseline loss, can manifest substantial capability loss relative to fault-free baselines.
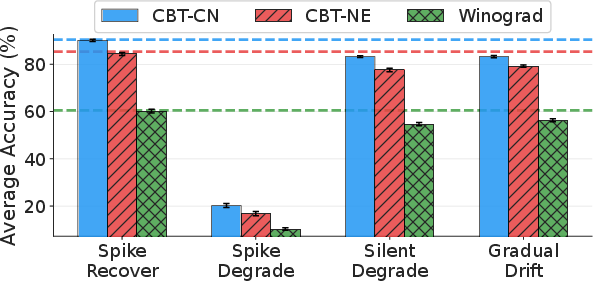
Figure 7: Downstream performance of faulty GPT2-Medium (BF16) models on the Children's Book Test and Winograd Schema.
PPL sensitivity analysis shows that higher fault rates, earlier injection points, and forward/input-gradient phase targeting increase the likelihood of observing degraded convergence.
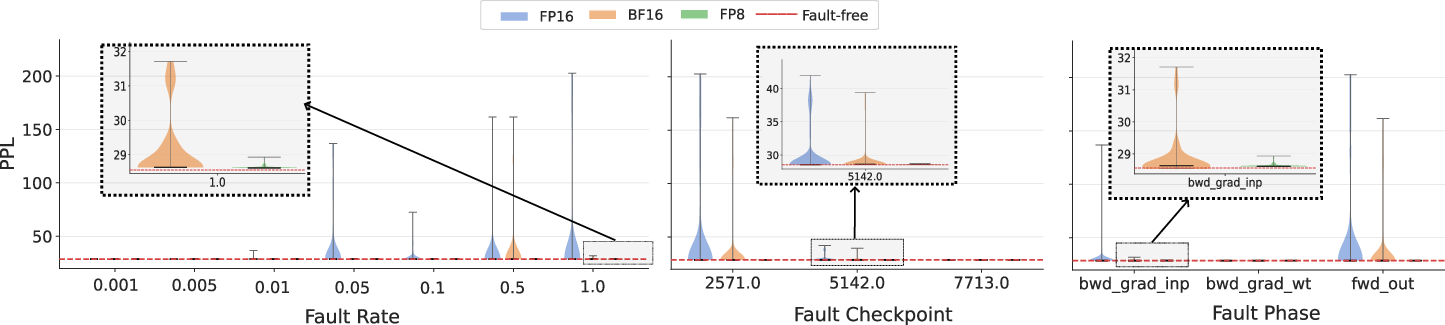
Figure 8: Variation in PPL with fault rate, injection checkpoint, and injection phase.
Effectiveness and Limitations of Runtime Safeguards
The efficacy of runtime NaN checks is format-dependent. For FP16 and BF16, the check converts a substantial portion of crashes to spike-and-recover events but does not eliminate silent degradations. For FP8, most outcomes are unaffected as the format’s narrow dynamic range enforces binary (saturating or crashing) outcomes.
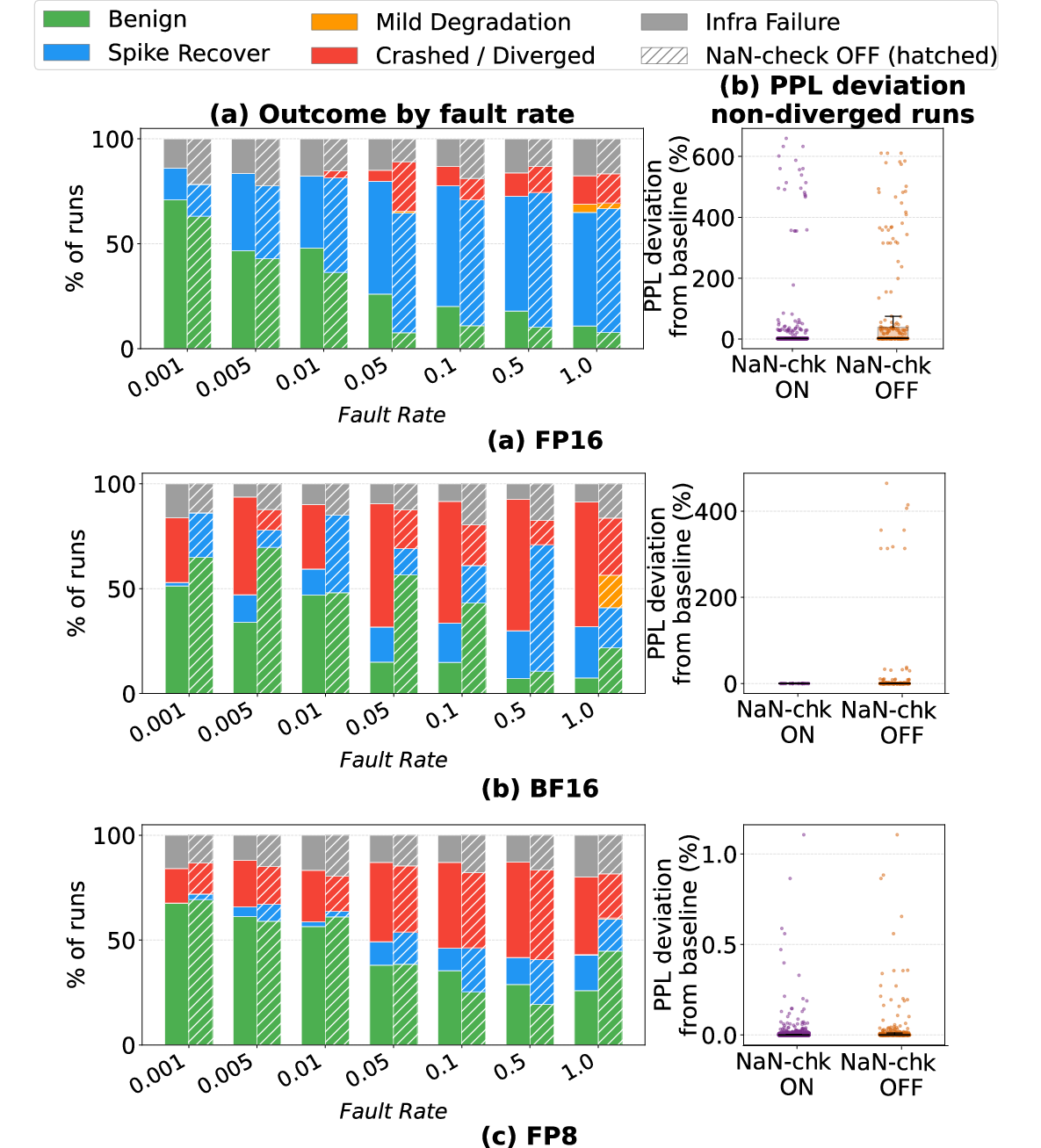
Figure 9: Impact of loss NaN-checks on outcome distributions and silent degradation across formats.
Limitations and Future Directions
LLM-PRISM's evaluation leverages hardware-aware software injection but is constrained to the GPT-2 scale for campaign feasibility. Hardware-model realism is key, and the fidelity of the injected error signatures must match observed silicon fault modes for transferability to larger foundation models. Additionally, alternate parallelism strategies and multi-defect interactions require further investigation to assess resilient system-level designs.
Conclusion
LLM-PRISM establishes the first comprehensive, hardware-grounded empirical baseline for silent data corruption resilience during LLM pre-training (2604.10390). Strong claims substantiated by this work include:
- Standard metrics and loss traces are unreliable SDC detectors: Substantial parameter and capability divergence can occur with no NaN/Inf or loss anomaly.
- Numerical format selection imposes critical trade-offs: FP16 is susceptible to persistent silent degradation; BF16 and FP8 trade off higher outright crash risk for reduced silent error rates.
- System and algorithm co-design is imperative: Effective SDC detection must go beyond NaN guards, integrating hardware-aware monitoring and possibly fault-tolerant optimization routines.
Practically, this work motivates deployment of hardware-health monitoring, SDC-aware redundancy, and adaptive runtime error handling. Theoretically, it frames the need for statistical and numerical analysis of optimizer dynamics under persistent, structured perturbations. Future developments should address real-time detection of silent SDCs, resilience scaling with massive transformer sizes, and co-designed mitigation across the hardware-software stack.