- The paper demonstrates that targeted bit-flips in GPU GEMM kernels disrupt LLM training, particularly affecting backward-pass operations.
- It employs controlled fault injection and monitors gradient norms and RMS update spikes to precisely identify fault-induced anomalies.
- A lightweight recomputation mechanism with dynamic thresholding effectively restores baseline performance with minimal overhead.
Silent Data Corruption in LLM Training: Reliability Risks, Characterization, and Detection
Introduction
The continuous growth in scale and complexity of LLMs has heightened the sensitivity of their pretraining pipelines to non-algorithmic failures, with silent data corruption (SDC) emerging as a significant threat to reliability. The paper "Exploring Silent Data Corruption as a Reliability Challenge in LLM Training" (2604.00726) systematically characterizes the manifestation and impact of SDC at the level of GPU matrix-multiply operations (GEMMs) during LLM pretraining and proposes a lightweight detection and recomputation strategy to mitigate disruptions. The work utilizes controlled, fine-grained fault injection to dissect the effects of SDC, offering insights into fault propagation and actionable methodology for robust LLM training.
Motivation and Context
LLM training infrastructures routinely involve thousands of accelerators operating at scale for protracted durations, which exposes them to a non-negligible risk of SDC arising from both transient (e.g., cosmic radiation, workload-induced) and permanent (e.g., manufacturing defects, component aging) faults. While ECC mechanisms can detect and correct many DRAM and register bit errors, operational experience and the literature indicate that several critical SDC root causes evade ECC and propagate to computation-level anomalies. Notably, industry-scale LLM training (e.g., Gemini, Llama 3) has reported SDC-induced interruptions, with individual events leading to divergence, progress stalls, and costly rollbacks.
Prior work has primarily focused on inference-level SDC impacts or application-specific ABFT protocols, which do not generalize to the dynamically heterogeneous tensor operations or non-linearities central to LLMs. Existing kernel-level SDC detection and checkpoint-based recovery approaches introduce high costs and typically over-trigger on benign anomalies. This paper operationalizes the exploration of SDC in the training phase, precisely interrogating the sensitivity of LLM training to low-level faults and the effectiveness of runtime detection mechanisms.
Controlled Fault Injection and Sensitivity Analysis
The authors employ a custom NVBit-based fault injection framework to flip targeted bits at the SASS instruction level (specifically, within HMMA instructions of GEMM kernels) during LLM pretraining. Models of 60M, 350M, and 1.3B parameters based on LLaMA serve as tractable yet representative experimental settings, with deterministic seeding ensuring grounded comparisons. Faults are injected into exponent and sign bits of bfloat16-packed registers at controlled rates and durations, and multiple metrics—evaluation loss, parameter divergence, gradient norms, and attention logits—are measured.
A core empirical result is the finding that only exponent (and to some extent sign) bits produce observable corruption in training, manifesting as increased evaluation loss, NaN propagation, loss spikes, or persistent parameter divergence. The impact of a given fault is highly kernel- and context-dependent. For instance, the same bit position in different GEMM kernels (forward vs. backward) results in markedly distinct effects:
- Backward-pass faults are acutely disruptive, producing catastrophic spikes in gradient norms and parameter updates, sometimes triggering infinite moment estimates in adaptive optimizers and leading to optimizer freezes.
- Forward-pass faults are generally masked, except when they perturb attention logits before softmax, which can transiently disrupt attention mechanisms.

Figure 1: Evaluation loss, parameter difference, gradient norm, and maximum attention logits as a function of bit position and kernel, exposing the heightened sensitivity to exponent bits in specific GEMM callsites.
No kernel-localization is observed for effect severity within lanes or SMs, and both the temporal density (injection rate) and duration of faults strongly modulate the magnitude and persistence of the impact on training dynamics.
Fault Propagation Through the Optimizer
The analysis links the manifestation of SDC in the backward pass to the adaptive dynamics of AdamW. Corrupted gradients, especially those manifesting as high-magnitude or infinite values, lead to abrupt spikes in the RMS magnitude of parameter updates (Rt), which in turn precipitate pronounced bumps in the loss trajectory. The interplay between gradient norm clipping and the optimizer is revealed: norm clipping typically blocks the most extreme parameter updates, but certain infinity-triggering events reduce all gradients to zero, resulting in momentum-only updates, and may stall training.
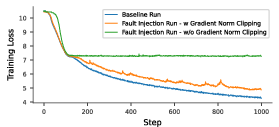
Figure 2: Training loss trajectories for fault-injection runs with and without gradient norm clipping; norm clipping attenuates most spikes, but can be defeated by infinite second moment estimates that stall optimization.
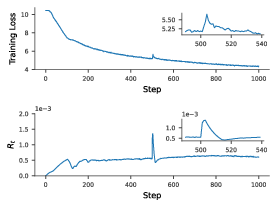
Figure 3: A single fault with length 3 causing a sharp spike in Rt, followed by a pronounced loss bump and eventual stabilization at a higher loss than the pre-fault level, illustrating the optimizer’s sensitivity to SDC-triggered outliers.
The experiments collectively demonstrate that not all SDC leads to immediate divergence; certain corruption events induce less obvious yet persistent deviation in model parameters and final performance. This observation challenges the sufficiency of naive statistical or interval-based outlier detection for effective mitigation.
Detection and Recomputation Mechanism
Building on the empirical signatures of SDC-induced harmful updates (i.e., spikes in Rt and associated loss bumps), the authors propose a simple, statistics-driven anomaly detector. This detector monitors the per-iteration RMS update magnitude and the gradient norm, flagging steps as anomalous when the change in Rt exceeds a dynamic, warm-up-calibrated threshold (parameterized by sensitivity factor α) adjusted for concurrent gradient norm spikes. If a step is flagged, it is recomputed; deviation from the original (due to non-deterministic hardware scheduling) confirms SDC and allows immediate correction without checkpoint rollback.
The sensitivity parameter α mediates the trade-off between precision and recall: higher sensitivity boosts detection rates but increases unnecessary recomputations, and vice versa.
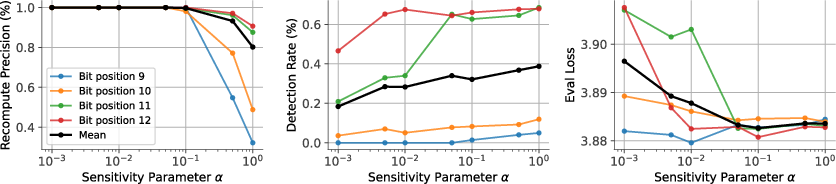
Figure 4: Influence of the detector sensitivity parameter α on recomputation precision, detection rate, and evaluation loss; optimal α balances false positives and detection coverage.
Across all model scales tested, recomputation of corrupted steps (guided by the detector) restores evaluation loss curves to baseline performance, while naive training under SDC leads to persistent and significant loss degradation. The approach introduces minimal runtime overhead (approximately 1%), while the cost of undetected faults is substantial—each fault translates to an effective rollback of 30–40 optimization steps.
Implications and Future Directions
The findings establish that SDC-induced disruptions, even those that evade system-level ECC, can materially degrade LLM training, and that lightweight, optimizer-statistics-based runtime detection with recomputation is a practical mitigation. This framework is compatible with both single- and distributed-worker settings, as the detector can operate on local or aggregated optimizer states.
Integrating model-internal metrics with hardware-level signals (temperature, power, utilization) could further sharpen detection and attribution capabilities. Additionally, the synergy between momentum resets, invariant checks in attention, or other proactive mechanisms and recomputation-based mitigation remains an open area for practical system design targeting SDC resilience. The study’s focus on matrix-multiply operations motivates investigation into SDC effects in other non-linear or custom fused kernels and validation in even larger distributed setups.
Conclusion
This paper provides a rigorous characterization of the propagation and impact of silent data corruption in LLM training and demonstrates that targeted, per-iteration detection and recomputation is a feasible and effective strategy for mitigating these reliability risks. The work points toward a future where robustly trained foundation models require joint statistical, architectural, and systems-level defenses against hardware-induced SDC, ensuring the integrity of extensive and costly pretraining workflows.