- The paper demonstrates that single-layer transformers struggle with associative recall compared to state-space models.
- It details how learning rate sensitivity and scaling differences between depth and width impact overall model performance.
- The research explores induction-like training phenomena in shallow transformer architectures, suggesting benefits from hybrid designs.
Transformers and State-Space Models: In-Context Recall Limitations
Introduction
The research scrutinizes the performance of transformers in associative recall (AR) contexts, contrasting them with state-space models (SSMs), notably in recurrent model architectures. The study illuminates discrepancies in learning rate sensitivity, scalability in depth versus width, and reveals a novel induction-like training phenomenon in 1-layer transformer models.
Optimization Challenges in Recurrent Models
The study underscores a pivotal observation that recurrent models, unlike transformers, display notable sensitivity to learning rate choices. Poor tuning leads to suboptimal task performance or failure to solve tasks like AR, highlighting the necessity for meticulous learning rate optimization to fully harness these model architectures' capabilities. As illustrated in Figure 1, there exists a marked performance disparity, where transformers maintain robust performance across diverse learning rates, whereas recurrent models such as Hyena and Mamba depict a performance spike only at certain optimal rate settings. This has implications for the perceived performance efficacy of recurrent models vis-a-vis attention-based counterparts, necessitating deeper exploration into improving optimization strategies.
(Figure 1)
Figure 1: Sensitivity of recurrent models to learning rate variations compared to transformers.
Scaling Behaviors: Depth vs. Width
In examining the scaling properties of these models, the paper reveals contrasting behaviors between depth and width scaling. Recurrent models improve significantly with increased width, reflecting a true need for larger hidden states to retain information during sequential processing. This aligns with the provided empirical results (Figure 2).
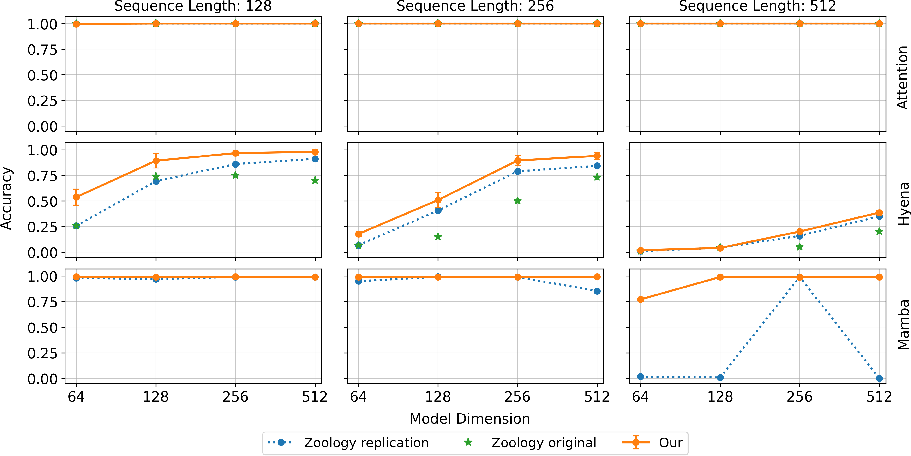
Figure 2: Performance of 2-layer models emphasizing improvements with increased width for recurrent models.
Conversely, transformers struggle in single-layer configurations; their typical strengths in multi-layer settings are absent here, as seen in Figure 3. Transformers' inabilities in isolated single-layer settings (without inter-layer communication) highlight their inherent dependence on multi-layer architectures for efficiently tackling AR tasks.
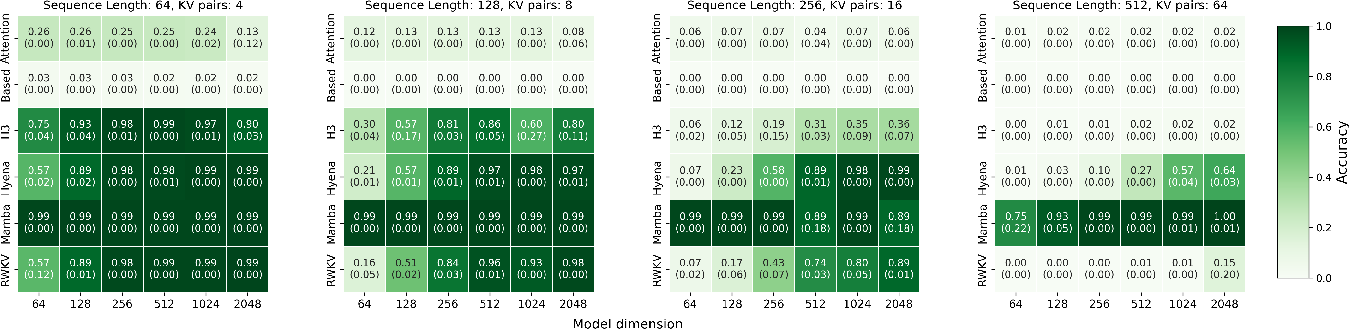
Figure 3: 1-layer architecture scaling showcasing the necessity of multi-layer constructs for effective tasks in transformers.
Training Dynamics and Induction Heads
In single-layer attention models, a training dynamic reminiscent of induction heads is observed—a phenomenon previously identified in deeper transformer architectures. However, contrary to multi-layer models where this leads to improved performance, single-layer models fail to capitalize on this, as evidenced by their performance charts (Figure 4). On the other hand, Mamba models exhibit this induction-like dynamic while maintaining task-solving capacity, indicating a unique convergence dynamic possibly resultant from their architecture.
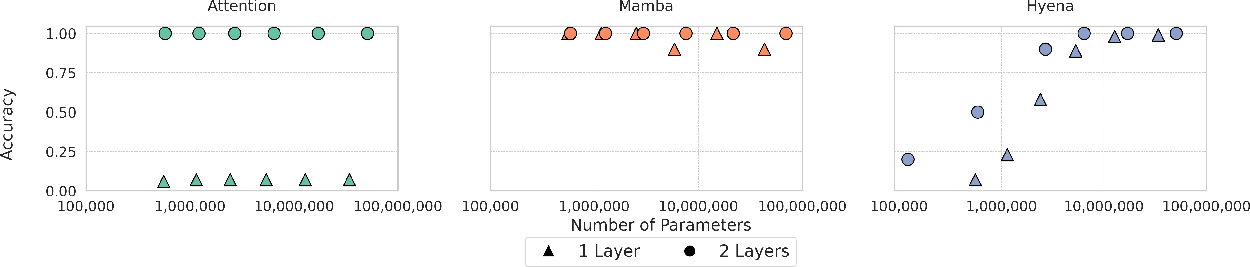
Figure 4: Induction-like phenomena normalization over training metrics for single-layer models.
Architectural Differences and Ablations
Ablation studies conducted various “Mamba-like” alterations to Transformers by integrating convolutional layers, leading to conditions where tasks like MQAR are solvable with single-layer configurations (Table 1). These experiments suggest convolutional integrations enhance AR performance, bridging some expressivity gaps between architectures.
Conclusions and Future Directions
This research elucidates that while there are underlying similarities between SSMs and transformers in structure, expressivity, and dynamics, significant differences influence their performance in AR contexts. Recurrent models require refined optimization practices for effective deployment. Moreover, understanding and exploiting 1-layer induction-like phenomena presents potential for optimizing transformer architectures. Further exploration into hybrid models or improved recurrent model stability could lead to better-performing architectures in contexts requiring extended memory and complex reasoning capabilities.