Recurrence-Complete Frame-based Action Models
Abstract: In recent years, attention-like mechanisms have been used to great success in the space of LLMs, unlocking scaling potential to a previously unthinkable extent. "Attention Is All You Need" famously claims RNN cells are not needed in conjunction with attention. We challenge this view. In this paper, we point to existing proofs that architectures with fully parallelizable forward or backward passes cannot represent classes of problems specifically interesting for long-running agentic tasks. We further conjecture a critical time t beyond which non-recurrence-complete models fail to aggregate inputs correctly, with concrete implications for agentic systems (e.g., software engineering agents). To address this, we introduce a recurrence-complete architecture and train it on GitHub-derived action sequences. Loss follows a power law in the trained sequence length while the parameter count remains fixed. Moreover, longer-sequence training always amortizes its linearly increasing wall-time cost, yielding lower loss as a function of wall time.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a big question: are today’s popular “attention-based” AI models (like Transformers) enough for tasks that require careful, step-by-step understanding over long periods of time? The authors argue that for many real-world, long-running tasks—especially those done by software agents—models need true recurrence, which means they must process information in strict order, one step after another, because each step depends on the previous ones. They present theory, tests, and a new model showing why and how serial, non-parallel computation is important.
Goals and Questions
- Explain what “true depth” and “recurrence-complete” mean, and why they matter for long sequences.
- Show that models which do everything in parallel (like constant-layer Transformers, some state-space models, and scan-style RNNs) can’t handle certain step-by-step problems well.
- Create tests that force models to think in strict order and check which models succeed.
- Build a practical setup using “frames” of a terminal/editor plus the next action, and test a new model that combines attention inside each frame with an LSTM over time.
- Study how training on longer sequences affects performance and training time.
Methods and Approach
Key ideas in simple terms
- True depth: Think of it as the number of steps a model must do one after another, where each step depends on the last. If the story gets longer, a truly serial model’s depth grows with it.
- Recurrence-complete: A model is recurrence-complete if it can update its memory using its previous memories and the new input in any complicated way, not just by simple sums or scans. This makes it able to handle tasks where order and exact dependencies matter.
- Input aggregation: To make a prediction at time t, a model must combine everything it has seen up to t into a compact “state.” If that combining can be done in parallel, the model may be fast—but it may miss tasks that require strictly following dependencies in order.
- Input-length proportionality: Some tasks demand doing about one real sequential step per input item. No shortcut or parallel trick helps, because each step’s outcome depends on the previous steps.
Synthetic benchmarks that force serial thinking
- Forward-Referencing Jumps Task (FRJT): Imagine a list of instructions where whether you run step t+1 depends on what happened at step t. You can’t skip ahead; you must resolve each step in order. This setup blocks parallel shortcuts.
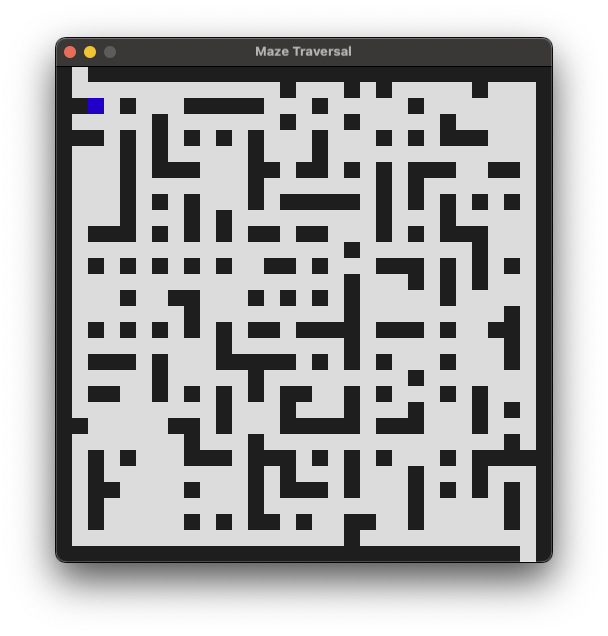
- Withheld Maze Position Tracking: A fixed maze, a sequence of moves, and sometimes the outcome of a move is hidden. The model must keep careful track of position over time, even when feedback is missing. Counting alone won’t solve it; you need the step-by-step history.
Practical, “frame-based action” setup
- The authors reconstruct realistic coding sessions from Git histories. Each time step has:
- A frame: a full snapshot of what the terminal/editor looks like (like a small image of text).
- The next action: keystrokes or control codes.
- They store this as “text-video with actions,” then train models to predict actions from frames.
The proposed model
- Inside each frame: a small transformer head summarizes the 2D text layout (attention is great within a frame).
- Over time: a stack of LSTM cells that process frames one-by-one, keeping a memory of what happened before (this is the serial part).
- Training: full backpropagation through time with a streaming schedule that recomputes activations on the fly, so memory stays roughly constant as sequences get longer. This matches the serial nature of the task.
Main Findings and Why They Matter
Before the list below, note that the authors compare time-parallel models (like constant-layer Transformers and state-space/scan models such as Mamba) against truly serial models (like LSTMs).
- On the synthetic, serial-required tasks:
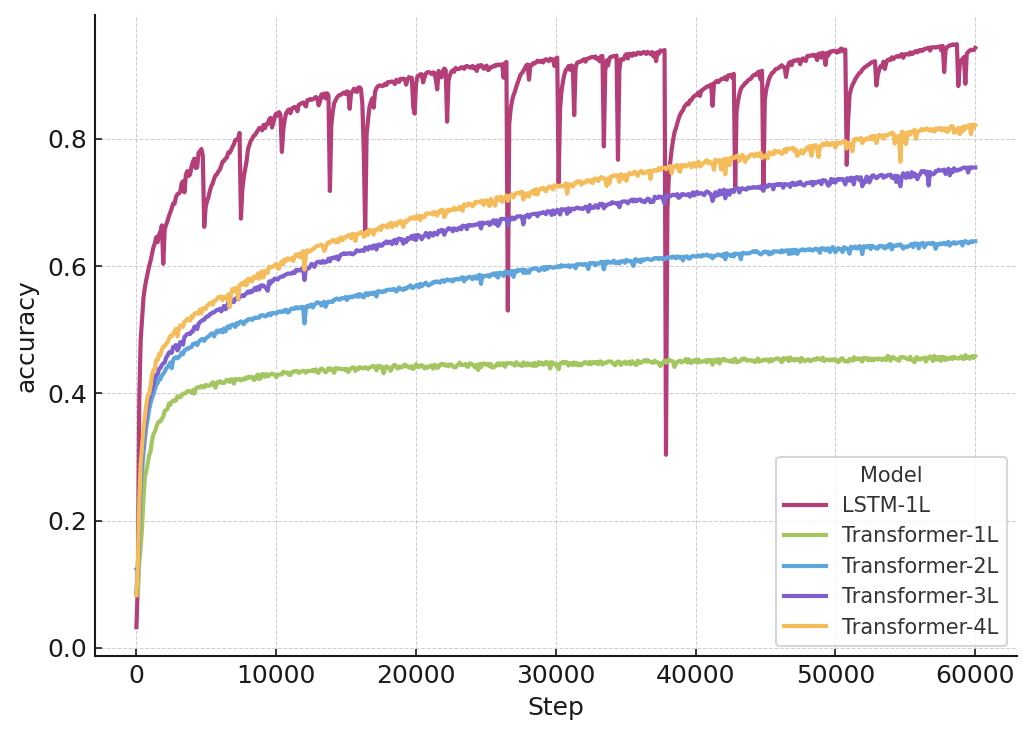
- Time-parallel models do okay at short depths but hit “accuracy cliffs” as depth increases.
- A simple 1-layer LSTM generalizes much further, keeping higher accuracy at larger depths. This supports the argument that strict serial processing is needed for these tasks.
- On the frame-based action data from coding sessions:
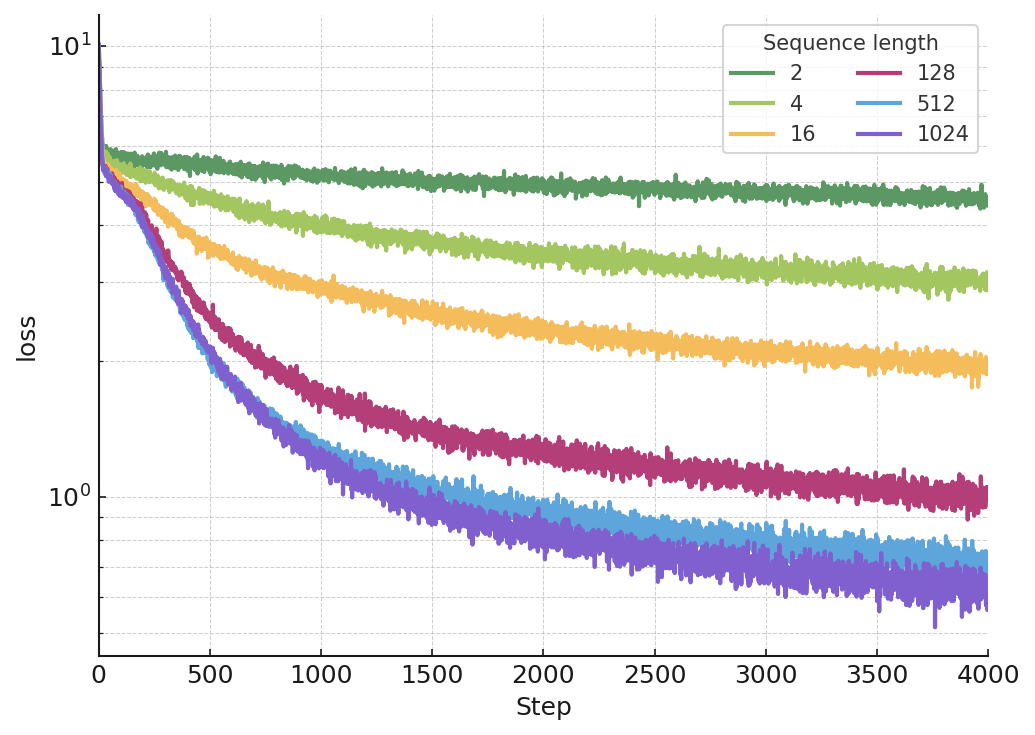
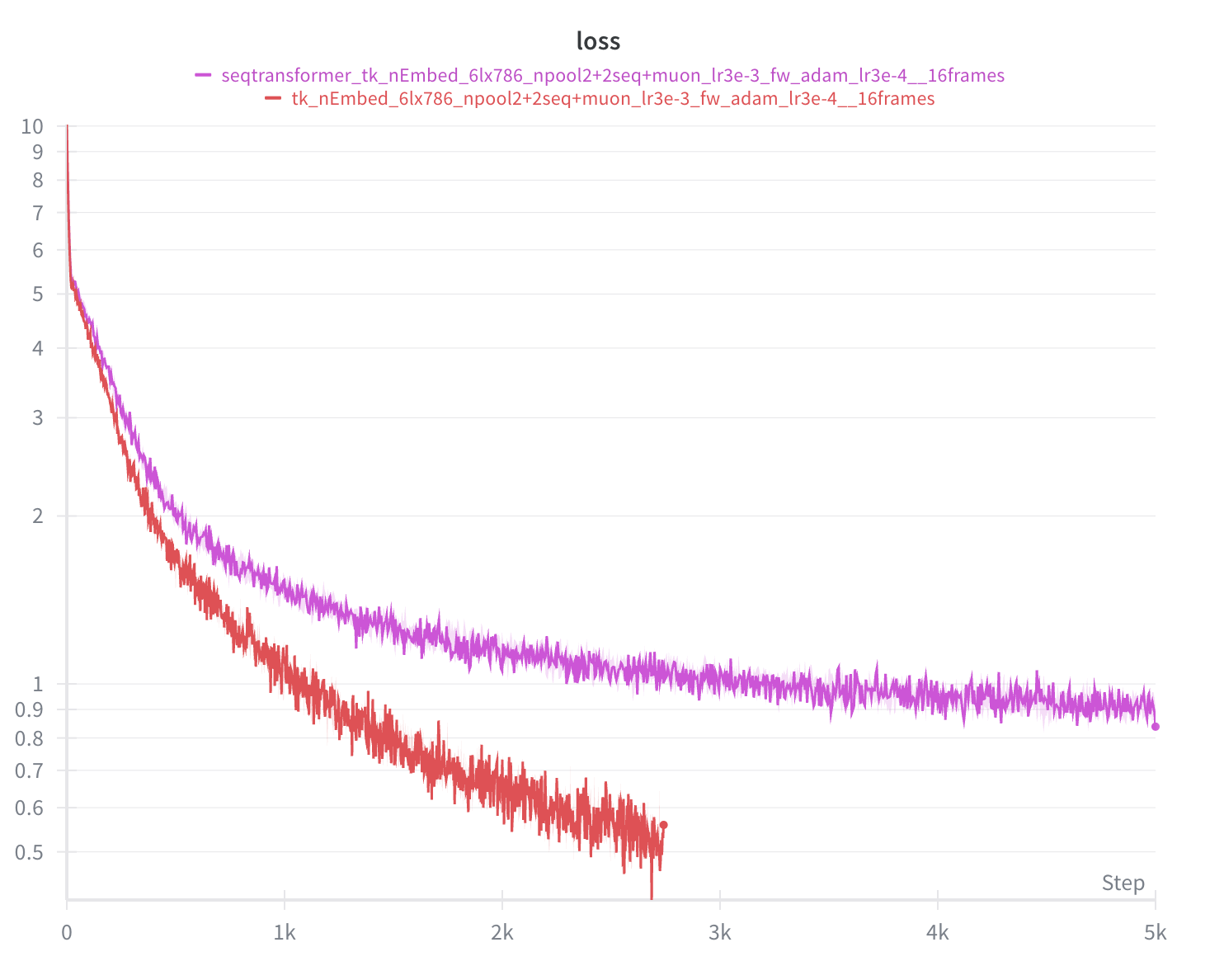
- Holding the number of parameters fixed, training on longer sequences reliably lowers the loss (error), following a power law: as sequence length L grows, loss decreases roughly like L raised to a negative power.
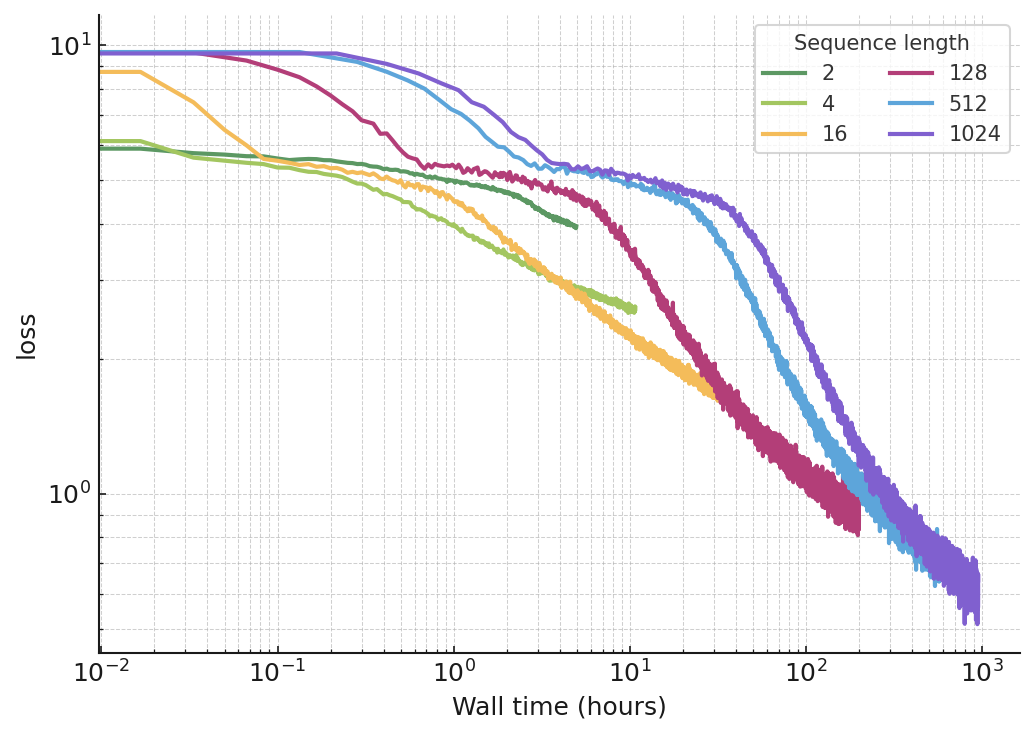
- Even though longer sequences cost more time per step, the extra cost “pays for itself”: after a certain point, longer-sequence training wins on loss-versus-wall-time and stays ahead.
- Improvements show up across early and late positions in the sequence, not just at the end. That suggests the model is building a better overall “state of mind,” not just using extra context opportunistically.
- Theoretical consequences:
- If a model’s forward or backward pass is fully parallelizable, it cannot be recurrence-complete. In plain terms: you can’t have both perfect parallel speed and perfect serial reasoning capability at the same time.
- Models that aggregate inputs using parallel scans (like prefix-sum-style reductions) also can’t be recurrence-complete for tasks where order and non-associative updates matter.
- Many popular architectures—constant-layer Transformers and several state-space or “parallelizable RNN” variants—lack the serial depth needed for worst-case long-horizon problems.
- Practical motivation:
- Real agent tasks (like coding in an editor, managing files, navigating UIs) produce partial, side-effect-rich streams. Important facts aren’t always visible right away. Keeping a faithful internal state often means strict serial bookkeeping.
- Video and large text-video streams emphasize a memory and compute constraint: you often must process things in order because you can’t load all frames at once at full size. Streamable recurrence fits this reality.
Implications and Impact
- For building long-horizon agents: Attention is powerful, but “attention is all you need” isn’t always true. When the task has non-scannable, order-dependent computations—like forward-jump logic, hidden outcomes, or side effects—you need some truly serial component. LSTMs or similar recurrences can be a necessary complement to attention.
- Model design: A hybrid approach makes sense—use attention within a time step (to read a complex frame) and use recurrence across time (to maintain consistent memory). This can better handle tasks where the next action depends on a carefully built internal state.
- Training strategy and hardware: Longer sequences can improve performance even at fixed parameter counts, and the extra wall-time can be amortized. Streamed backpropagation through time with recomputation can keep memory under control while still learning long dependencies.
- Limits of chain-of-thought: Writing out steps (scratchpads) can help, but the model still has to correctly integrate long streams into a coherent internal state at decision time. Externalizing state doesn’t remove the need for proper serial perception.
- Future directions: Explore more “frame plus action” datasets across different tools and UIs; refine theory to map which tasks guarantee input-length proportional dependencies; and develop efficient training schedules and hardware mappings that embrace serial recurrence where needed.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps, limitations, and unresolved questions that emerge from the paper, organized by theme to guide follow-up research.
Theory and formal guarantees
- Precisely formalize the computational model and assumptions behind “true depth” and “recurrence completeness,” including gate sets, fan-in/fan-out, permissible nonlinearity, precision, and uniformity conditions; clarify how these map to realistic floating-point hardware and training procedures.
- Rigorously prove (with explicit assumptions) that models with parallelizable forward or backward passes cannot be recurrence-complete; the current “trivial” argument via contradiction needs a complete formalization in a well-specified computational framework.
- Characterize the exact boundary between “parallelizable input aggregation” and “recurrence completeness” for architectures that mix scan-like operations with non-associative nonlinearities or feedback (e.g., SSMs with nonlinear readouts and temporal residual feedback).
- Provide lower and upper bounds for the number of inherently sequential steps required by input-length-proportional tasks beyond informal “pointer-chasing” intuition; connect these bounds to concrete architecture constraints (e.g., bounded fan-in, memory bandwidth, random access assumptions).
- Clarify whether the AC0/TC0 characterizations for constant-layer Transformers (under constant-precision softmax/activations) extend to practical floating-point regimes (bfloat16/FP16/FP32), mixed precision, and attention variants that deviate from these assumptions.
- Specify the conditions under which “depth as a function of sequence length” is equivalent to recurrence completeness for finite-width/finite-precision models; quantify how hidden-state capacity and nonlinearity affect this equivalence in practice.
- Analyze hybrid or adaptive-depth architectures (e.g., ACT/pondering, halting, chunk-recurrent Transformers, streaming attention with state, hierarchical recurrence) to determine when partial non-parallelizable components suffice for recurrence completeness.
- Formalize “input aggregation criticality” by providing a method to estimate the constant c in n_taskops > c·L for different architectures and tasks, and prove conditions under which this threshold predicts observed failure cliffs.
- Examine whether training parallelism vs inference parallelism are separable in the “No Free Lunch for Parallelism” claim—can non-parallelizable inference coexist with partially parallel training (e.g., RTRL/UORO variants), and does that affect recurrence completeness?
- Extend the theory to memory-augmented models (e.g., differentiable stacks, external KV stores, retrieval, episodic memory): are there constructions that restore recurrence completeness without sacrificing all parallelism?
Experimental design and comparability
- Establish compute- and parameter-matched comparisons across architectures; current comparisons vary layer counts and likely parameter counts without reported normalization, making attribution to “true depth” ambiguous.
- Report multiple random seeds, error bars, and statistical significance for all curves (FRJT, Maze tasks, GitHub/terminal data, Diff-Inflate-Bench); current results lack variance quantification and sensitivity analysis.
- Perform systematic hyperparameter sweeps (optimizer, LR schedules, initialization, dropout, normalization, sequence length schedules) to ensure observed differences are not artifacts of suboptimal configurations for some architectures.
- Validate that “accuracy cliffs” persist when Transformers and SSMs are given depth proportional to sequence length (i.e., L ∝ n), or when given architectural adaptations (e.g., gating, recurrence wrappers) designed to increase true sequential depth.
- Provide ablations demonstrating that the LSTM performance advantage is due to serial computation rather than dataset-specific inductive biases (e.g., test GRU, xLSTM variants, RetNet with state carry, transformer-with-recurrence hybrids).
- Quantify the effect of truncated BPTT vs full BPTT on long-horizon generalization for the proposed LSTM backbone; measure gradient stability (vanishing/exploding), memory usage, and wall time across horizons.
- Verify robustness of the FRJT and Maze benchmarks with alternative randomness, instruction sets, branching distributions, maze topologies, and noise injection; assess whether “shortcuts” (heuristics) exist that erode the intended strict sequentiality.
- Measure how performance scales with hidden-state size independently from depth to disentangle “capacity bottlenecks” from “sequential computation bottlenecks.”
Data, benchmarks, and measurement validity
- Release the FRJT and Maze benchmark generators with fixed seeds and full specifications; provide canonical test splits to enable reproducibility and fair comparisons.
- Precisely document the Git-derived frame/action data generation (editor reconstruction, terminal rendering, termstreamxz encoding), including potential reconstruction errors, ambiguity resolution, and labeling noise; quantify error rates introduced by heuristic reconstruction steps.
- Evaluate the generality of the frame-based action setting beyond terminal/editor workflows (e.g., GUI environments, mixed-modality UIs, web browsing) to test whether the conclusions generalize to more diverse agentic interfaces.
- Provide diagnostics verifying that the frame/action data actually require input-length-proportional aggregation (e.g., presence of withheld/latent state, side effects not trivially observable in subsequent frames) rather than being solvable via parallelizable heuristics.
- Validate that “uniform improvement across early and late positions” under longer sequence training is not an artifact of loss weighting, curriculum, or teacher forcing; include position-wise loss curves with confidence intervals and ablations.
- In Diff-Inflate-Bench, clarify sample sizes per patch-count, judge consistency, inter-judge agreement, and robustness; the current reliance on a single LLM judge and small sample sets risks evaluation bias.
- Expand Diff-Inflate-Bench beyond a single repository (tinygrad) and report performance stratified by repo characteristics (patch overlap, code density, language, churn); disentangle “guessable-by-priors” vs “requires serial reconstruction.”
- Replace or augment LLM judging with programmatic or test-suite-based functional equivalence checks to reduce evaluation noise and subjective bias; quantify false positives/negatives for the judge.
- Isolate the effect of context leakage in diffs (e.g., U1/U0) more rigorously by controlling prompt length, truncation, and tokenization artifacts; verify that degradation is not driven by context-window limits or prompting artifacts.
Model architecture and training methodology
- Provide a complete specification of the proposed Recurrence-Complete Frame-based Action Model (exact frame encoder, pooling strategy, temporal LSTM configuration, normalization, gating, residual connections), and release ablations (e.g., replacing LSTM with SSM/Transformer, changing pooling).
- Benchmark the proposed model against strong streaming baselines (e.g., structured SSMs with feedback, RetNet with state carry, chunk-recurrent Transformers, Hyena with recurrent state, RWKV variants) under matched compute and memory.
- Demonstrate scalability of the “O(1) memory via recomputation” training to very long sequences on commodity hardware; report throughput, wall-time scaling, activation recompute overhead, and distributed training strategies.
- Provide learning-curve and “exponent α(s)” estimates with confidence intervals, show stability across datasets/seeds, and test whether the power law persists at larger scales and different parameter counts.
- Study the trade-off between hidden-state size and sequence length for the LSTM backbone (compute-optimal width-depth trade-offs); identify regimes where depth vs width is the limiting factor for input-length-proportional tasks.
- Investigate hybrid attention–recurrence designs: quantify how much serial compute (layers or steps) is minimally sufficient when combined with attention/retrieval to avoid aggregation criticality for representative agent tasks.
Applicability to long-horizon agentic systems
- Empirically validate that the identified “input aggregation criticality” manifests in real agent pipelines (coding agents, browser agents, data wrangling) by measuring degradation vs interaction length and comparing serial vs time-parallel backbones.
- Quantify the extent to which chain-of-thought or tool-augmented scratchpads can externalize necessary state to offset non-recurrence completeness; characterize when scratchpads fail (e.g., bandwidth, latency, or attention bottlenecks).
- Measure how often real environments induce unobserved side effects that force strict serial state tracking (e.g., filesystem, process state, network state), and build benchmarks that explicitly require reconstructing such latent variables.
- Explore error accumulation and recovery in streaming settings: how do recurrent models handle missing frames, out-of-order observations, or partial corruption compared to time-parallel models?
- Assess generalization across tasks and domains when training with longer horizons: do longer-horizon runs produce better few-shot tool-use, robustness to distribution shift, or improved planning without increased prompt engineering?
Scope, claims, and generality
- Clarify the scope of the non-recurrence-completeness claim for specific families (e.g., S4/Mamba, RetNet, RWKV, Min-RNNs): under what concrete instantiations and training regimes do these remain non-recurrence-complete, and are there variants that recover recurrence completeness?
- Reconcile the claim that residual networks act like “unrolled gated recurrences” with the assertion that constant-layer Transformers lack sufficient true depth; define when residual stacking confers effective serial depth for sequence tasks versus feedforward depth for per-token processing.
- Determine whether partial serial processing (e.g., small recurrent cores interleaved with parallel blocks) suffices in practice for long-horizon tasks, and quantify the necessary ratio of serial to parallel computation.
Reproducibility and releases
- Release code, data, and detailed configs for all experiments (synthetic tasks, frame/action modeling, Diff-Inflate-Bench) to enable independent replication and scrutiny.
- Provide licensing, privacy, and provenance documentation for the Git-derived datasets; clarify any deidentification procedures and redistribution rights.
These gaps collectively outline the theoretical clarifications, empirical controls, dataset rigor, and architectural ablations needed to solidify the paper’s claims and translate them into reliable, scalable practices for long-horizon agentic systems.
Glossary
- AC0: A circuit complexity class of constant-depth, polynomial-size circuits with unbounded fan-in Boolean gates. "Under finite/constant precision and a constant number of layers, time-parallel architectures such as Transformers instantiate constant-depth circuit families; prior work placed such families in and, under stronger assumptions, in \citep{merrill2025illusionstatestatespacemodels,li2024chainthoughtempowerstransformers}."
- agentic systems: Systems that autonomously act and interact with tools or environments to achieve goals. "We further conjecture a critical time beyond which non-recurrence-complete models fail to aggregate inputs correctly, with concrete implications for agentic systems (e.g., software engineering agents)."
- backpropagation through time: A training method for recurrent models that computes gradients across sequential time steps. "We train with full backpropagation through time using a streaming, recompute-on-the-fly schedule that keeps activation memory effectively in sequence length (at the cost of wall-time), aligning compute with the serial nature of the problem."
- bounded fan-in: A circuit property where each gate has a limited number of input connections. "Pointer chasing admits round lower bounds in parallel models with bounded fan-in and limited random access, matching our true-depth lower bounds."
- computation DAG: A directed acyclic graph representing the dependencies among operations in a computation. "Formally, true depth is the length of the longest directed path in the computation DAG (unit-cost primitive gates, including elementwise nonlinearities and non-associative mixing ops)."
- Constant Error Carousel: A mechanism in LSTMs that preserves gradient flow over time, aiding long-term dependencies. "In such regimes, serial integration (e.g., LSTMs with Constant Error Carousel) may be a necessary complement to attention."
- constant-bit precision: Using a fixed, limited number of bits for numeric representations (e.g., activations/softmax) during computation. "and later work refined the upper bound to \citep{li2024chainthoughtempowerstransformers} under constant-bit precision for the activations/softmax."
- constant-depth circuit families: Families of circuits whose depth does not grow with input size. "Transformers with a constant number of layers (true depth ) and finite/constant-precision arithmetic form DLOGTIME-uniform constant-depth circuit families."
- DLOGTIME-uniform: A uniformity condition where circuit descriptions can be generated efficiently (in deterministic logarithmic time) relative to input size. "Transformers with a constant number of layers (true depth ) and finite/constant-precision arithmetic form DLOGTIME-uniform constant-depth circuit families."
- Forward-Referencing Jumps Task (FRJT): A synthetic benchmark that enforces strictly serial evaluation by allowing only forward jumps in a straight-line program. "The Forward-Referencing Jumps Task (FRJT) forces strictly serial evaluation of a straight-line program with forward jumps; whether an instruction executes cannot be known until the previous instruction resolves."
- frame-based action modeling: A formulation where each time step provides a complete interface frame paired with the next action. "we introduce a frame-based action modeling setting: each time step provides a frame---a complete, fixed-size 2D view of the interface (e.g., a terminal grid)---paired with the next low-level action (keystrokes or control sequences)."
- frame buffer: A memory representation of the current frame’s pixel grid. "by reconstructing plausible editor sessions and capturing the resulting terminal frame buffer with a compact, lossless termstreamxz format"
- input aggregation: The process of compressing all observations up to time t into a fixed-size latent representation. "Once again it can be trivially shown that any model with parallelizable input aggregation cannot be recurrence-complete"
- input aggregation criticality: The maximal sequence length beyond which a non-recurrence-complete model fails to correctly aggregate inputs for an input-length proportional task. "We define the term ``input aggregation criticality'' to refer to the maximum sequence length after which a non-recurrence-complete model can no longer correctly aggregate the input data provided"
- input-length proportionality: A property of tasks where the required number of truly sequential steps scales linearly with input length. "We then identify a task property that makes these limits operational: input-length proportionality."
- No Free Lunch for Parallelism: The claim that models with parallelizable forward or backward passes cannot be recurrence-complete. "A model with a parallelizable forward or backward pass cannot be recurrence-complete (a ``No Free Lunch for Parallelism'' \cite{zhang2024autoregressivechainthought})."
- Parallel Sequential Duality: A theoretical notion relating parallelizable computations to sequential ones, highlighting trade-offs. "This coincides with the definition of ``Parallel Sequential Duality'' as defined in \cite{yau2025sequentialparalleldualityprefixscannable}."
- prefix-scan-like reductions: Parallel aggregation operations that use associative scans to combine inputs across time. "Architectures with parallelizable input aggregation (prefix-scan-like reductions) also cannot be recurrence-complete."
- pointer chasing: A computation pattern where each step depends on the result of the previous pointer dereference, making parallelization hard. "Pointer chasing admits round lower bounds in parallel models with bounded fan-in and limited random access, matching our true-depth lower bounds."
- recurrence-complete: Capable of realizing general recurrent updates that depend on past hidden states through non-associative functions. "we say an architecture is recurrence-complete if it can realize recurrent updates of the form
for general (including non-associative) ."
- residual stack: A series of layers with residual connections, here applied to LSTM cells for temporal integration. "temporal integration is performed by a residual stack of LSTM cells, deliberately embracing non-parallelizable serial computation."
- scan-style aggregation: Aggregating sequence information via associative scans to enable time-parallel computation. "which trade strict hidden-state dependencies for scan-style aggregation."
- state--space models: Sequence models that parameterize dynamical systems with state evolution and inputs, often enabling parallelization. "including state--space models and ``parallelizable RNNs'', which trade strict hidden-state dependencies for scan-style aggregation."
- TC0: A circuit complexity class with constant depth and polynomial size that includes threshold (majority) gates. "prior work placed such families in "
- teacher forcing: A training technique that feeds ground-truth intermediate outputs back into the model to stabilize learning. "This is intentional to include short programs to achieve a similar result as teacher forcing a target program state at each point in time \citep{williams1989learning}."
- termstreamxz format: A compact, lossless format introduced to capture terminal frames and actions. "capturing the resulting terminal frame buffer with a compact, lossless termstreamxz format"
- true depth: The number of inherently sequential, non-parallelizable operations in a model’s computation trace. "we define true depth as the number of inherently sequential (non-parallelizable) operations in the computation trace of a model."
Practical Applications
Immediate Applications
The following items translate the paper’s findings into deployable use cases, tools, and workflows across sectors. Each item notes assumptions or dependencies that could affect feasibility.
- Recurrence-complete agent backbones for terminals and IDEs (software, devtools)
- Build coding and ops agents that perceive “text-video with actions” and integrate state serially using a frame head (intra-frame transformer) plus an LSTM temporal backbone.
- Products/workflows: IDE/terminal plugins that stream terminal frame buffers and keystroke/control events; agents that reliably track cursor position, editor state, filesystem mutations, and shell side-effects over long sessions.
- Assumptions/Dependencies: Availability of a terminal frame capture pipeline (e.g., termstreamxz); willingness to trade training parallelism for serial compute; LSTM stability (e.g., Constant Error Carousel or similar gating).
- Git-history-to-action-stream dataset generation (software, research tooling)
- Adopt the paper’s pipeline that reconstructs plausible editor sessions from Git histories and renders them into terminal frames with action logs (“text-video with actions”).
- Tools: termstreamxz format; session reconstruction scripts; dataset publishing and benchmarking harnesses.
- Assumptions/Dependencies: Licensing and privacy constraints in using Git histories; quality of reconstruction heuristics; reproducible environment to render frames deterministically.
- Long-sequence training schedules with streaming BPTT (ML engineering across domains)
- Use full BPTT with recompute-on-the-fly to keep activation memory ~O(1) while increasing trained sequence length; exploit observed power-law loss improvements vs. sequence length and the amortization crossover in loss vs. wall time.
- Tools/workflows: Training recipes that steadily increase sequence length; activation recompute schedulers; curriculums that interleave short/long sequences.
- Assumptions/Dependencies: Acceptance of longer wall-time per step; careful optimizer/learning-rate schedules to preserve serial gradient flow; numerical stability under longer horizons.
- Diagnostics for “input aggregation criticality” (ML evaluation in industry/academia)
- Use the FRJT and Withheld Maze Position Tracking benchmarks to detect when time-parallel models hit depth-dependent cliffs and to quantify a model’s true serial capacity.
- Tools: Benchmark suites; dashboards that monitor validation accuracy vs. task depth; rule-of-thumb metric n/L (sequence length over layer count) to track risk of criticality.
- Assumptions/Dependencies: Synthetic task competence is predictive of target workload demands; depth definitions are aligned with application dynamics.
- Diff-Inflate-Bench for code perception (software engineering, model evaluation)
- Evaluate code models on reconstructing final file states from sequences of diffs (including minimal-context U0 and low-context U1 variants) to assess long-horizon aggregation ability without relying on externalized chain-of-thought.
- Workflows: Pre-deployment testing of coding assistants; gating models based on degradation curves vs. number of patches.
- Assumptions/Dependencies: Bench reflects real agent perception demands; fair judging (function-equivalence checks) and reproducible diff settings; minimal context tests to reduce “leaked” state.
- Streamable recurrence for video analytics (media/security analytics, sports, retail)
- Deploy serial, streamable RNN-based temporal integration to process high-resolution video without storing entire sequences in memory, aligning model compute with video decoding.
- Products/workflows: On-device or edge analytics that perform left-to-right processing; camera-CCTV pipelines; sports moment detection; retail flow analysis.
- Assumptions/Dependencies: Efficient video decode and frame-to-embedding interfaces; latency budgets compatible with serial inference; training infrastructure for long sequences.
- Hybrid attention-in-frame, recurrence-across-time for GUI RPA (enterprise automation)
- Build RPA agents for legacy terminals and GUIs that use attention for per-frame spatial parsing and LSTM for temporal state tracking (pointer-chasing, withheld events).
- Products: GUI/desktop automation agents robust to partial observability and side-effects; compliance-friendly logs of internal state reconstruction.
- Assumptions/Dependencies: Screen/frame capture with low overhead; robust OCR/structured extraction for GUI elements; policy-compliant logging.
- Operational safeguards for Transformer agents (operations, platform engineering)
- Monitor signs of aggregation criticality (e.g., rising error with horizon) in deployed Transformer agents; add guardrails that force explicit state externalization or switch to recurrent backbones beyond a horizon threshold.
- Workflows: Horizon-aware routing of tasks; automatic truncation plus state summarization; hybrid model fallback policies.
- Assumptions/Dependencies: Accurate early warning metrics; compatible interfaces between attention-only and recurrent agents; reliability of scratchpad/state externalization when used.
- Curriculum designs for serial reasoning (education technology, ML training)
- Build curricula mixing short and long sequences (teacher-forced intermediates) to train transition functions that generalize to longer horizons, as shown in FRJT setup.
- Tools: Data pipelines that generate mixed-depth sequences; evaluation on withheld transitions.
- Assumptions/Dependencies: Transfer from synthetic to real tasks; careful avoidance of overfitting at shallow depths.
- Procurement and risk review checklists (policy, governance, safety)
- Update model procurement guidelines for agentic systems to require evidence of recurrence completeness (or adequate mitigations) for tasks with input-length proportionality (e.g., long-horizon ops, compliance monitoring).
- Workflows: Model cards report aggregation criticality thresholds; audits include depth diagnostics and diff-inflate tests.
- Assumptions/Dependencies: Organizational readiness to run technical evaluations; sector-specific definitions of “long-horizon” and acceptable error.
Long-Term Applications
These applications require further research, scaling, engineering, or policy development before routine deployment.
- Recurrence-optimized hardware and runtimes (semiconductors, systems software)
- Design accelerators and kernels optimized for low-latency serial recurrence and long-horizon BPTT (e.g., recurrent-friendly memory hierarchies, gradient checkpointing primitives, sequence streaming operators).
- Potential tools: CUDA/ROCm kernels for RNN stacks with recompute; scheduling libraries for serial compute; interleaved decode–embed–infer pipelines.
- Assumptions/Dependencies: Sufficient demand to justify hardware changes; integration with major frameworks; co-design with compression/decompression pipelines.
- Scalable recurrence-complete generalist agents (software engineering, IT operations)
- Build “OS copilots” that operate for days/weeks, tracking latent OS/app/file states, interpreting partial observations, and safely executing sequences of actions with strict serial dependencies.
- Products: Enterprise-grade software operators; incident response copilots; CI/CD shepherds that carry context over long sessions.
- Assumptions/Dependencies: Strong sandboxing and rollback; provenance and explainability for actions; reliable recurrent memory (catastrophic forgetting mitigation).
- Frame-based action modeling beyond terminals (GUI automation, robotics, AR)
- Extend frame+action modeling to full desktops, mobile UIs, and robot sensors (2D/3D frames). Use within-frame attention and across-time recurrence for long-horizon control with partial observability and side-effects.
- Products: Universal GUI assistant; household robots with robust latent-state tracking; AR assistants that persist user/task context across sessions.
- Assumptions/Dependencies: Accurate, privacy-preserving frame capture; robust perception modules; task simulators for safe training.
- Standardization of “input aggregation criticality” benchmarks (industry consortia, regulators)
- Establish sector-specific criticality tests (pointer-chasing, withheld-transition tasks) as pre-deployment requirements for autonomous systems dealing with safety or compliance.
- Tools: Open benchmark suites; reporting standards; certification processes tied to depth robustness.
- Assumptions/Dependencies: Consensus across stakeholders; validated links between benchmark performance and real-world safety.
- Hybrid serial–parallel architectures and theory (academia, foundation model labs)
- Develop models that combine attention’s breadth with recurrence’s depth, including theoretical bounds for average-case regimes and training algorithms that retain serial depth while exploiting hardware parallelism where safe.
- Research directions: New gating mechanisms (CEC variants), implicit memory with guaranteed serial dependency, layer-tying to emulate “virtual depth,” stable long-range credit assignment.
- Assumptions/Dependencies: Advances in optimization and stability at scale; formal results that connect worst-case limits to typical workloads.
- Privacy-preserving action-stream capture ecosystems (platforms, policy)
- OS/IDE-level APIs to record frame+action streams with on-device anonymization and selective redaction for dataset creation and agent supervision.
- Tools: Differential privacy modules; developer-consent mechanisms; secure data escrow for research.
- Assumptions/Dependencies: Regulatory alignment (GDPR/CCPA); developer trust and incentives; robust de-identification for screens and logs.
- Longitudinal assistants in healthcare and finance (healthcare IT, compliance/surveillance)
- Recurrence-complete assistants that integrate years of EHR events (with missing/withheld data) or compliance logs, performing pointer-chasing across fragmented records and side-effect-laden updates.
- Products: Patient longitudinal state trackers; AML/KYC surveillance copilots; audit-ready compliance monitors.
- Assumptions/Dependencies: Clinical/financial validation; rigorous safety, bias, and privacy controls; integration with legacy systems.
- Video-centric foundation models with streamable training (media, autonomous vehicles)
- Train video models on long, continuous footage using streamable recurrence to avoid memory blow-ups and to learn long-term dependencies (e.g., intent prediction, rare-event detection).
- Products: Smart dashcams; traffic management analytics; sports strategy analysis.
- Assumptions/Dependencies: Scalable data ingestion; synchronized decode–train pipelines; evaluation methods for rare, long-range dependencies.
- Education: long-horizon tutoring systems (edtech)
- Tutors that maintain a recurrent latent model of a learner’s evolving knowledge and behavior, inferring withheld states (e.g., misconceptions) from partial signals over months.
- Products: Course copilots; personalized practice schedulers with robust state tracking.
- Assumptions/Dependencies: Ethical data retention policies; robust longitudinal evaluation; guardrails against overfitting to spurious sequences.
- Policy frameworks for agent reliability over time (regulators, standards bodies)
- Require disclosure of model serial depth properties, aggregation criticality thresholds, and mitigation plans; define acceptable horizons and failure modes for critical deployments.
- Tools: Model cards with depth and horizon metrics; continuous monitoring protocols.
- Assumptions/Dependencies: Agreement on measurable proxies for “true depth”; capacity to audit proprietary systems.
Cross-cutting Assumptions and Dependencies
- The core theoretical limits use constant/finite precision and constant layer count; some claims concern worst-case tasks with non-scannable dependencies.
- Serial recurrence sacrifices time-parallel training (“No Free Lunch”): organizations must plan for greater wall-time, though activation memory can remain low with recompute.
- Empirical gains from longer sequence training at fixed parameters may vary by domain; power-law behavior should be validated per task.
- Data capture (frames/actions) raises privacy, licensing, and reproducibility issues; robust anonymization and consent are prerequisites.
- Hybrid approaches (attention + recurrence) often work best in practice: attention for within-frame/spatial aggregation, recurrence for across-time integration.
Collections
Sign up for free to add this paper to one or more collections.