- The paper demonstrates that adaptive LLM traversal over mention graphs significantly enhances retrieval gains, particularly when evidence is scattered across multiple chunks.
- It employs a two-phase system that combines deterministic offline graph construction with online LLM-driven multi-hop exploration to balance breadth and depth.
- The approach distinctly separates candidate discovery from ranking, offering a pathway to hybrid systems that optimize cost efficiency and evidence integration.
Adaptive LLM Control in Retrieval over Mention Graphs: An Expert Analysis of "RLM-on-KG"
Introduction and Motivation
The paper "RLM-on-KG: Heuristics First, LLMs When Needed: Adaptive Retrieval Control over Mention Graphs for Scattered Evidence" (2604.17056) investigates when it is advantageous to deploy a LLM as an active controller for knowledge graph (KG) traversal in retrieval-augmented QA settings. The study targets a nuanced comparison: LLM-driven recursive traversal versus rule-based (heuristic) and standard GraphRAG retrieval pipelines, controlling for graph construction, tools, and ranking. The central hypothesis is that LLM control provides conditional gains, particularly in scenarios where the necessary evidence is structurally scattered.
System Description: RLM-on-KG Architecture
RLM-on-KG implements a two-phase pipeline: deterministic offline graph construction and online LLM-driven multi-hop exploration.
- Offline Phase: Documents are segmented into overlapping chunks; entities are extracted with spaCy NER and linked using surface form, forming a bipartite mention graph encoded in RDF and indexed with all-MiniLM-L6-v2 embeddings.
- Online Phase: At query-time, the LLM (e.g., Gemini, Claude) uses a fixed tool API (nine graph operations, including entity/neighbor expansion, vector search, and summarization) to adaptively traverse the mention graph, balancing breadth and depth to maximize evidence retrieval.
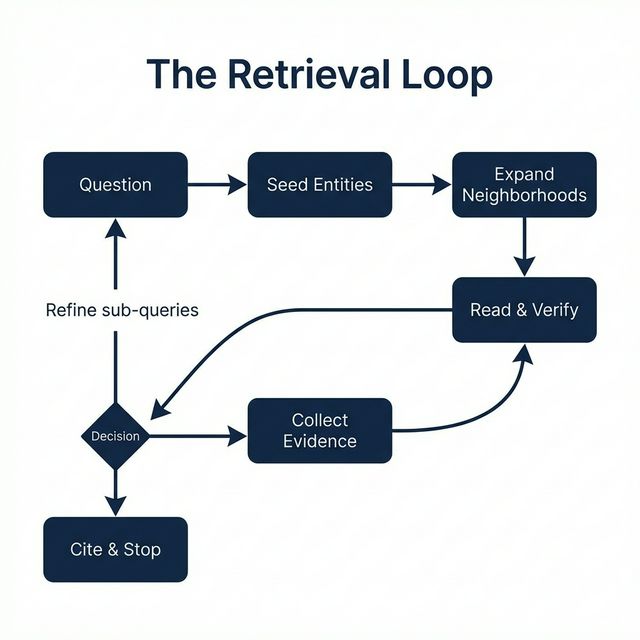
Figure 1: The RLM-on-KG retrieval loop, highlighting seed entity selection, graph expansion, evidence verification, and citation as successive optimization stages.
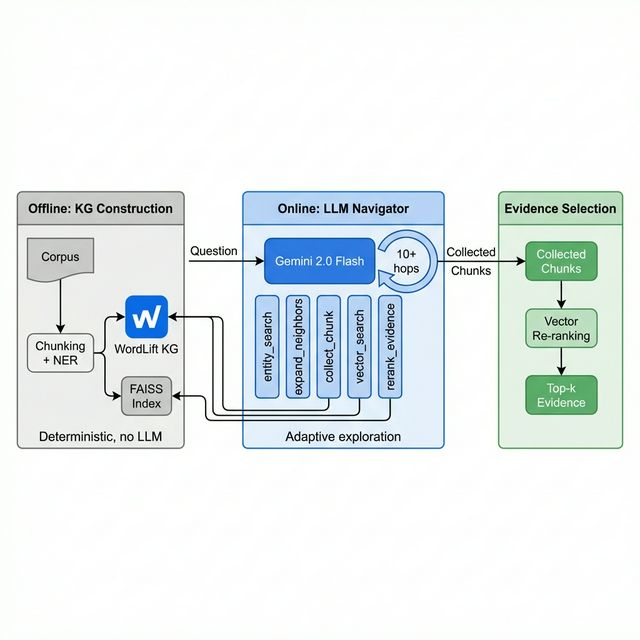
Figure 2: RLM-on-KG system architecture, showing the offline chunk/entity pipeline and the online LLM tool-based navigation.
The LLM's traversal policy is structured in explicit phases: seed entity identification (entity_search), neighborhood expansion (expand_neighbors, get_chunks_for_entity), relevance marking (collect_chunk), and recursive verification (sub_query). The ranking stage is decoupled: after exploration, all collected chunks are re-ranked purely by vector similarity.
Experimental Design and Baselines
The primary evaluation sets RLM-on-KG against:
- Heuristic RLM: Identical tools and graph, but driven by fixed BFS with stopping rules.
- GraphRAG-local variant: Purely deterministic, single-hop entity expansion + vector re-ranking.
- Dense vector-only: No graph features, only top-k embedding retrieval.
All experiments use identical mention graphs and scoring. The main testbed is GraphRAG-Bench Novel (519 questions from five fiction novels), with cross-scale checks on MuSiQue (multi-hop QA with smaller graphs).
Core Empirical Results
On the 519-question set, the Gemini LLM controller yields a marginal F1 improvement over GraphRAG-local (45.8% vs 45.6%), not statistically significant overall, but achieves a significant +2.47pp F1 over the heuristic RLM baseline (p < 0.0001):
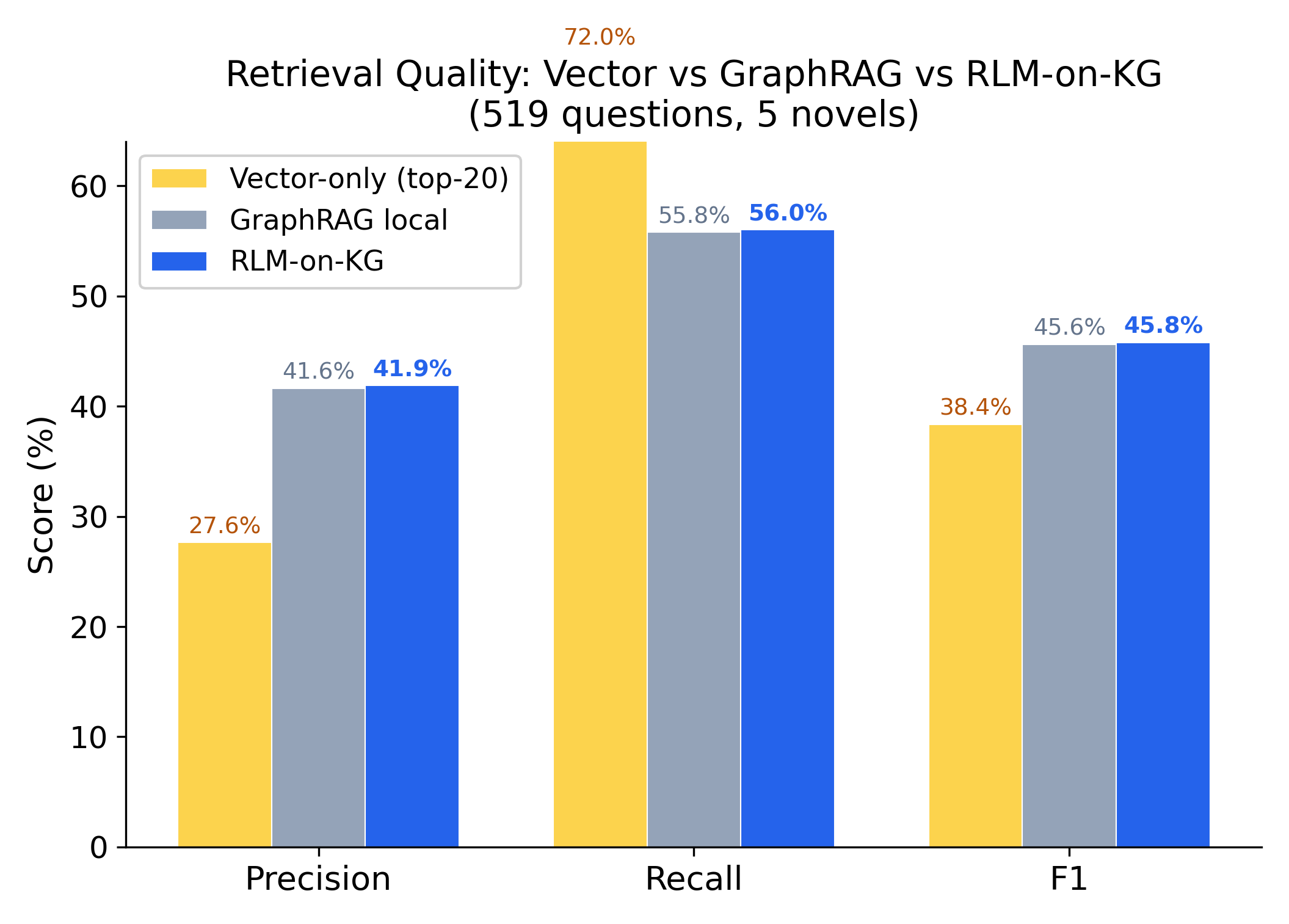
Figure 3: Direct retrieval F1 comparison for RLM-on-KG and GraphRAG-local, near parity at the aggregate level.
A more capable controller (Claude Haiku 4.5) achieves a statistically significant +2.42pp F1 gain over GraphRAG-local (p < 0.001) and +4.37pp over the heuristic, representing the first significant improvement over single-hop expansion baselines at this scale.
Localizing the LLM Advantage: Evidence Scatter
The LLM controller's benefit is sharply modulated by evidence scatter:
- For questions with evidence scattered across 6-10 chunks, Gemini yields +3.21pp over heuristic; this rises further in high-scatter regimes and for stronger controllers.
- For concentrated evidence (1-5 chunks), the advantage drops to +1.85pp and can even turn negative for complex reasoning.
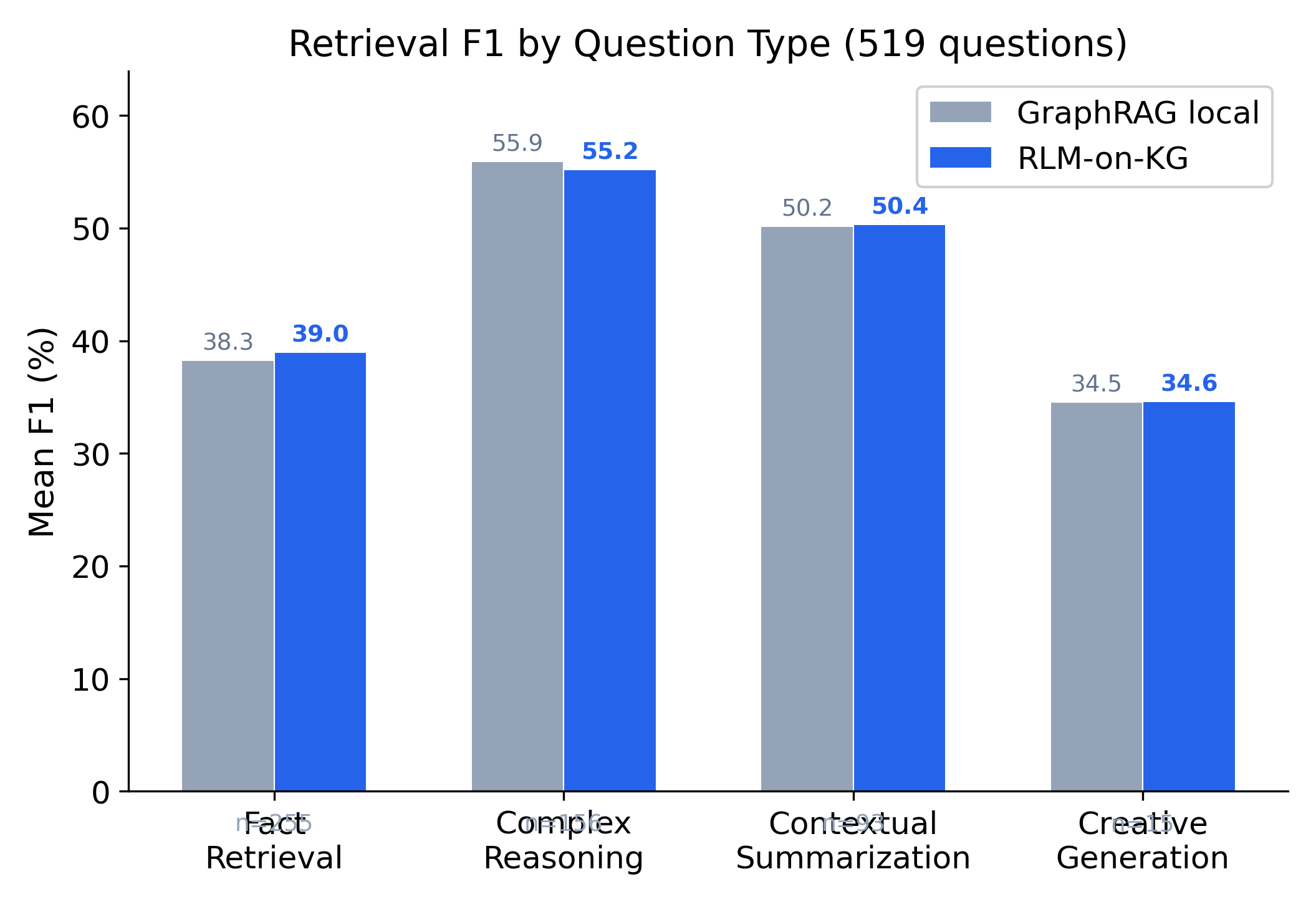
Figure 4: F1 by question type. RLM-on-KG leads in Fact Retrieval; GraphRAG has a marginal advantage for Complex Reasoning.
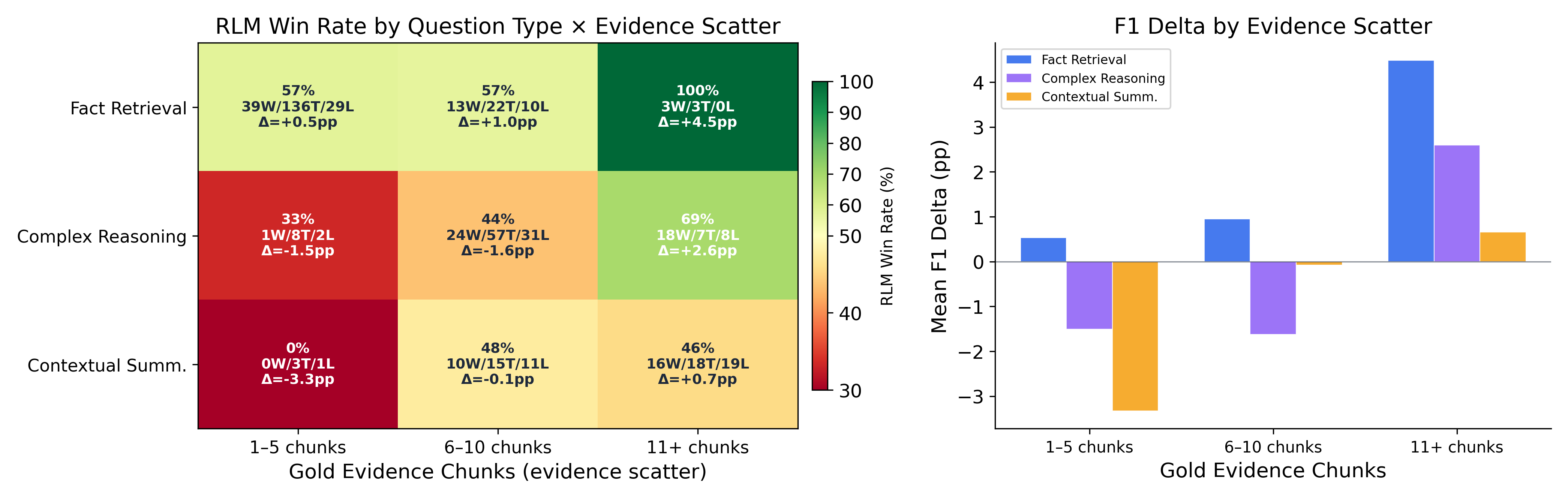
Figure 5: Win rate heatmap by question type and evidence scatter. RLM-on-KG's largest margin appears with Fact Retrieval at high scatter.
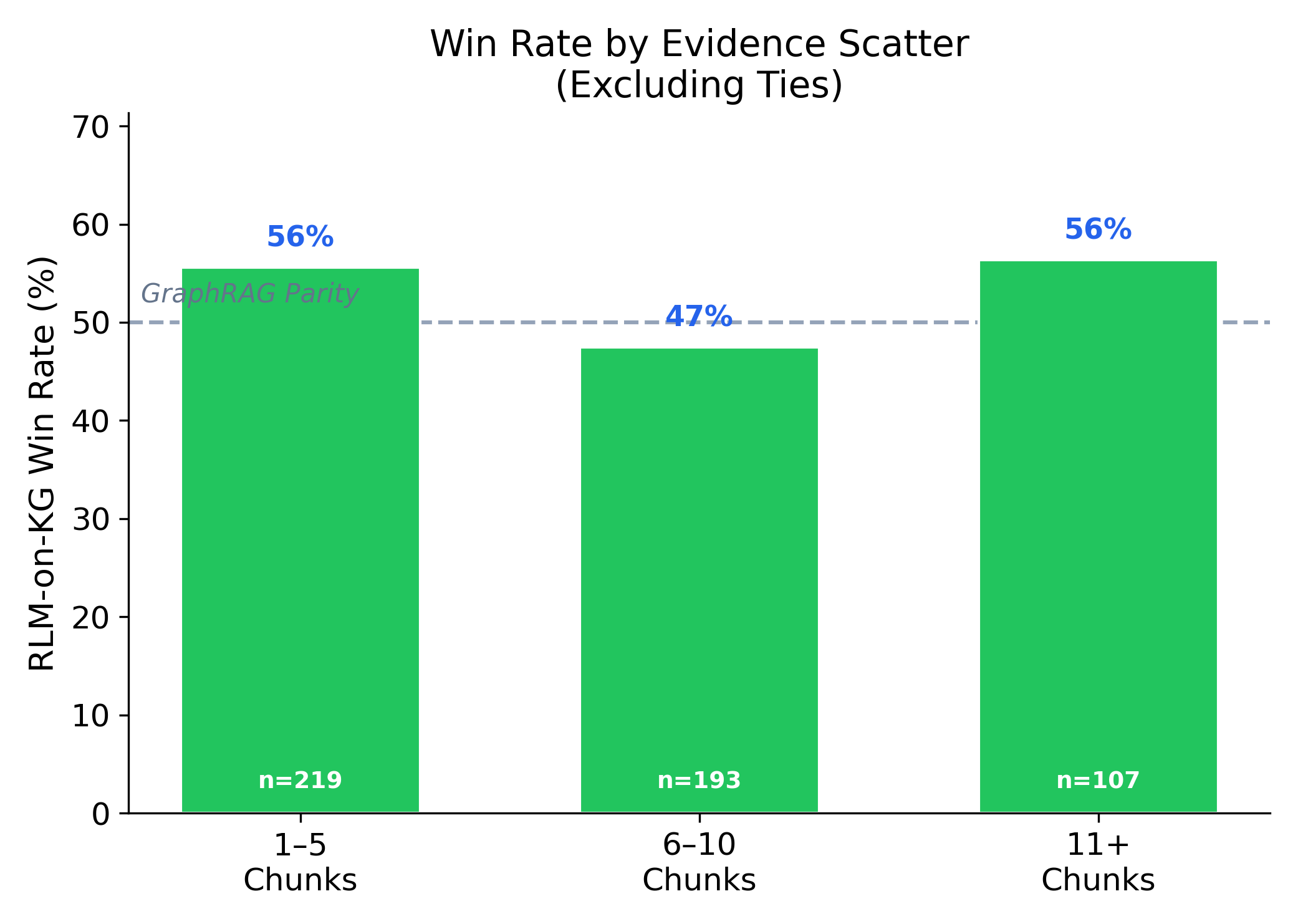
Figure 6: Win rate improvement as a function of required evidence chunk count, peaking at 56% for 11+ chunk cases.
This conditional nature is foundational: adaptive (LLM) control adds value only when structural complexity—multiple relevant nodes, variable distance—creates exploration choices non-trivial for greedy or BFS traversal.
Win/Loss Distribution
The gain is not due to a small set of outliers; the per-question F1 delta distribution is symmetric, with a positive tail attributed to hard scattered-evidence instances.
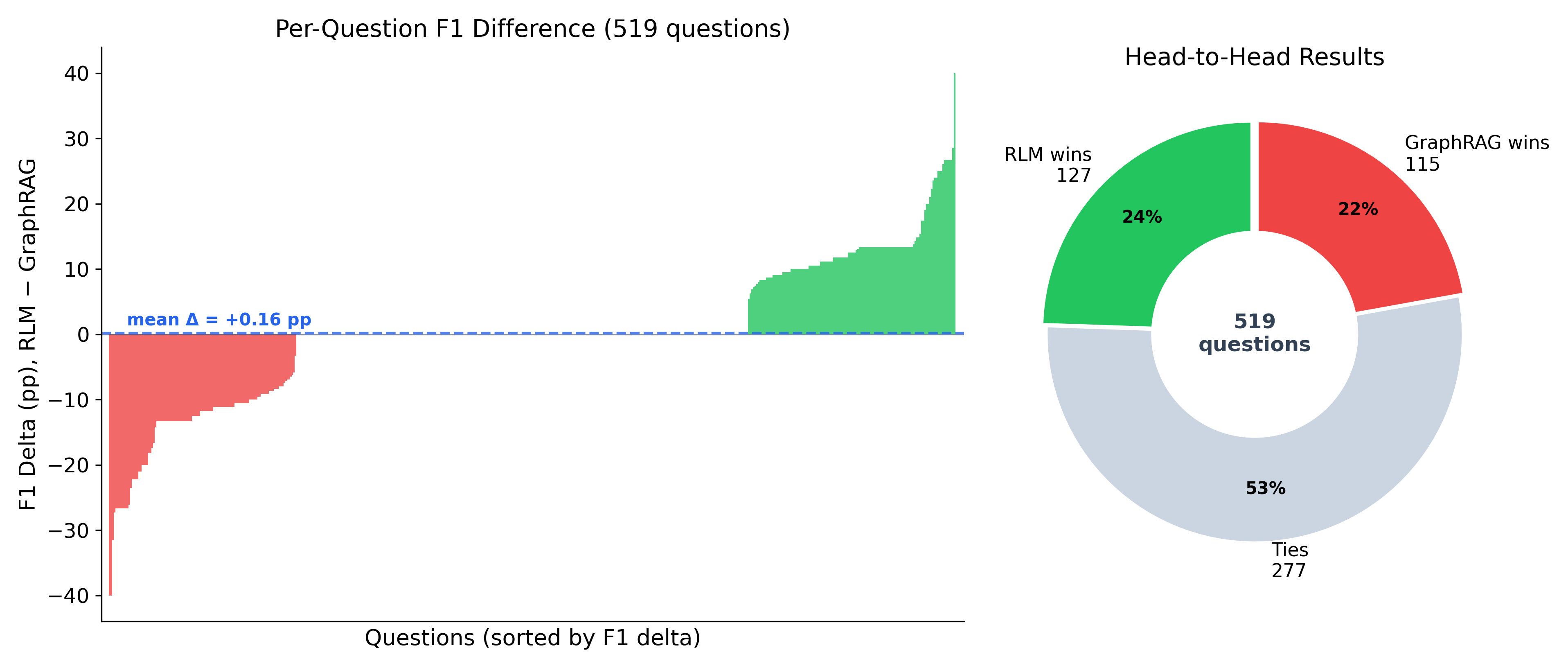
Figure 7: Per-question F1 delta (RLM minus GraphRAG); distribution centered at zero with slight positive skew.
Exploration Efficiency and Failure Modes
Optimal results are achieved with moderate exploration (~20-30 entities per query), with deeper exploration sometimes reducing precision due to off-topic drift.
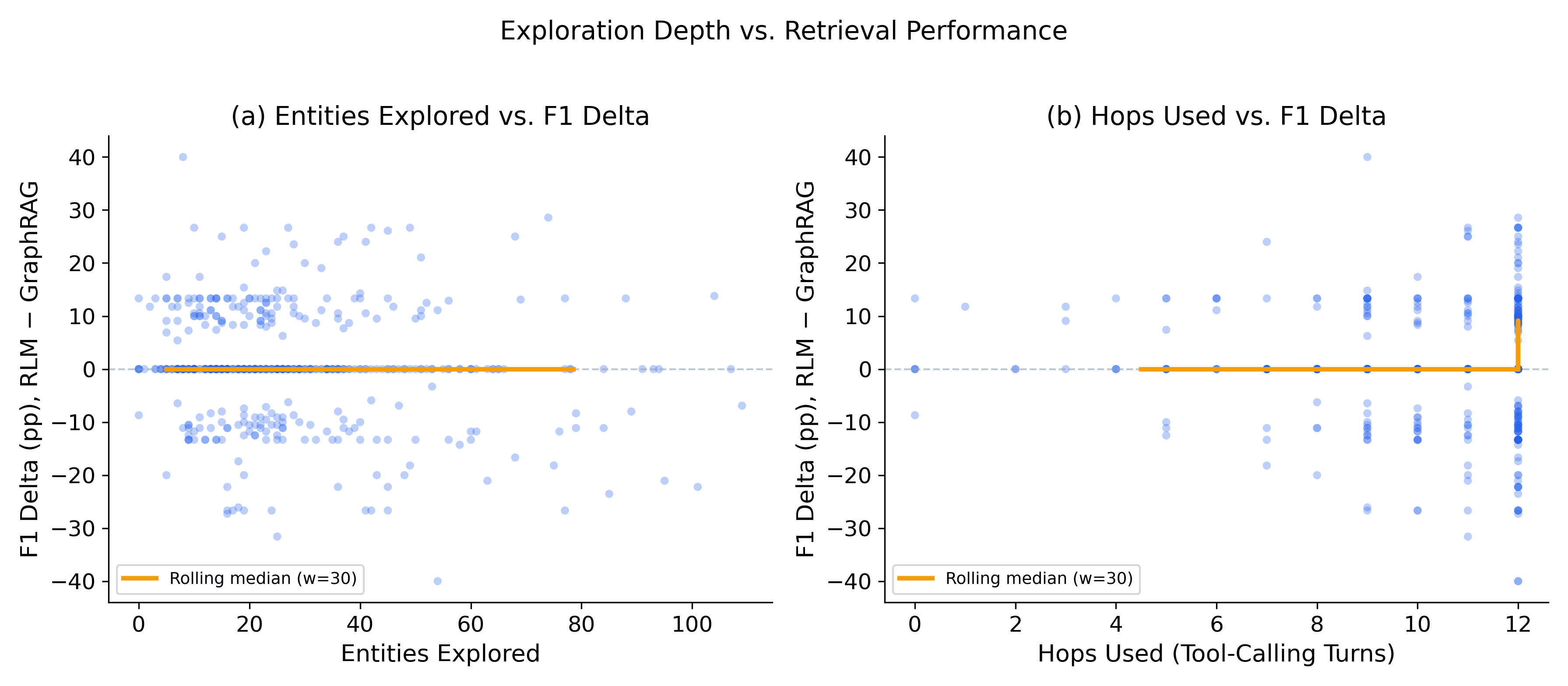
Figure 8: Exploration breadth vs. F1; optimal retrieval is reached at moderate entity-visit counts.
Qualitative case study confirms: LLM exploration often surfaces distant, otherwise unreachable chunks in high-scatter queries, but can dilute results in concentrated settings.
Model Scaling and Cross-Benchmark Generalization
Cross-model: The LLM-over-heuristic delta is a monotonic function of tool-calling strength: Claude > Gemini > Gemma. Gemma 4 E2B matches the heuristic in behavior (83% tie rate, no F1 gain), establishing a distillation target for future low-resource deployment.
On MuSiQue (smaller, distractor-rich graphs), the LLM-over-heuristic margin attenuates to +1.67pp (Claude), supporting the theoretical prediction that the LLM controller’s advantage scales with structural opportunity.
Architectural Insights
A key result is the separation of discovery and ranking: All F1 gain stems from improved chunk discovery through adaptive graph traversal—not from judgment or scoring. Pure vector similarity outperforms composite or entity MMR-based reranking at the candidate ranking stage, even for candidates surfaced via multi-hop exploration.
Practical Implications
- Efficiency: For real-time, cost-sensitive applications, GraphRAG-local or BFS traversal remain sufficient and are orders of magnitude faster and cheaper (sub-second, negligible tokens). LLM control (as currently implemented) incurs ~50K tokens/query and 2-5 minutes latency.
- Selective Escalation: A hybrid system can first attempt static single-hop expansion, invoking LLM navigation only when features (evidence scatter, low initial recall) predict potential gain. This minimizes cost while capturing LLM benefits for complex queries.
- Knowledge Graph QA: The traces from LLM navigation constitute valuable supervision data. They can train smaller models (e.g., Gemma) to emulate adaptive policies via reinforcement learning (TRL), potentially closing the deployment gap for local, privacy-preserving QA agents.
- Diagnostics: Exploration logs also stress-test KG quality, highlighting missed aliases, coverage/connectivity gaps, and index inefficiencies—enabling datasets and graph improvements.
Limitations
- All benchmarks involve fiction; evidence mapping uses the same embedding model as retrieval, muddying absolute F1 interpretation (but not head-to-head comparisons).
- GraphRAG-global modes (community detection, precomputed summaries) are not directly benchmarked.
- The current graph is a mention/association graph (no typed or directed relations), so results may understate potential LLM gains in semantically richer graphs.
- Latency and token cost preclude interactive use without targeted optimization.
Speculation on Future Directions
LLM-driven traversal is likely to become the dominant approach in domains requiring synthesis across dynamically evolving, structurally complex corpora, especially as high-quality local LMs are distilled with exploration traces. Hybrid orchestration based on instance-level difficulty predictors is a promising path for production systems. Advances in open-source model tool APIs will likely close the gap, making LLM-over-heuristic gains more widely accessible.
Conclusion
"RLM-on-KG" (2604.17056) conclusively demonstrates that LLM controllers provide significant retrieval gains over heuristic traversal and even over one-hop expansion pipelines, but only where the answer is structurally scattered and the controller supports robust tool use. The architectural separation of candidate discovery (via adaptive graph exploration) from ranking (via simple vector similarity) is empirically validated. Practically, hybrid systems, trace-driven distillation, and continuous KG diagnostics emerge as direct applications. As model APIs and open-source LMs improve in function-calling and reasoning depth, these findings are expected to generalize, situating adaptive LLM control as the principled choice where evidence integration over semantically-connected graphs is required.

