Replace, Don't Expand: Mitigating Context Dilution in Multi-Hop RAG via Fixed-Budget Evidence Assembly
Abstract: Retrieval-Augmented Generation (RAG) systems often fail on multi-hop queries when the initial retrieval misses a bridge fact. Prior corrective approaches, such as Self-RAG, CRAG, and Adaptive-$k$, typically address this by \textit{adding} more context or pruning existing lists. However, simply expanding the context window often leads to \textbf{context dilution}, where distractors crowd out relevant information. We propose \textbf{SEAL-RAG}, a training-free controller that adopts a \textbf{``replace, don't expand''} strategy to fight context dilution under a fixed retrieval depth $k$. SEAL executes a (\textbf{S}earch $\rightarrow$ \textbf{E}xtract $\rightarrow$ \textbf{A}ssess $\rightarrow$ \textbf{L}oop) cycle: it performs on-the-fly, entity-anchored extraction to build a live \textit{gap specification} (missing entities/relations), triggers targeted micro-queries, and uses \textit{entity-first ranking} to actively swap out distractors for gap-closing evidence. We evaluate SEAL-RAG against faithful re-implementations of Basic RAG, CRAG, Self-RAG, and Adaptive-$k$ in a shared environment on \textbf{HotpotQA} and \textbf{2WikiMultiHopQA}. On HotpotQA ($k=3$), SEAL improves answer correctness by \textbf{+3--13 pp} and evidence precision by \textbf{+12--18 pp} over Self-RAG. On 2WikiMultiHopQA ($k=5$), it outperforms Adaptive-$k$ by \textbf{+8.0 pp} in accuracy and maintains \textbf{96\%} evidence precision compared to 22\% for CRAG. These gains are statistically significant ($p<0.001$). By enforcing fixed-$k$ replacement, SEAL yields a predictable cost profile while ensuring the top-$k$ slots are optimized for precision rather than mere breadth. We release our code and data at https://github.com/mosherino/SEAL-RAG.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how to make AI systems that answer questions using outside information (called Retrieval-Augmented Generation, or RAG) do a better job on tricky, multi-step questions. The authors say that simply adding more and more documents for the AI to read often makes things worse because important facts get buried. Their solution, SEAL-RAG, keeps the number of documents fixed and swaps out unhelpful ones for better ones, so the AI sees a small, clean set of the most useful evidence.
What questions did the researchers ask?
The paper focuses on a few simple-to-understand questions:
- Why do RAG systems fail on questions that need multiple steps to solve?
- Can we fix these failures without giving the AI a huge pile of text?
- Is it better to carefully replace bad or distracting documents than to just add more?
- Does this “replace, don’t expand” strategy actually improve answers in practice?
How did they do the research?
What is RAG?
RAG is like giving an AI a library pass. When you ask a question, the AI first “retrieves” relevant documents from a big collection (like Wikipedia), then “generates” an answer based on what it found.
What’s the problem with adding more context?
Imagine your backpack has room for only a few books. If you keep stuffing in more, it gets messy. You might pack the wrong books or too many copies of the same one. In AI, this is called “context dilution”—too much or irrelevant text makes it harder for the model to spot the key facts, especially for multi-step questions. For example, if the question needs facts from two different pages that connect through a “bridge” fact, missing that bridge makes the whole answer fall apart.
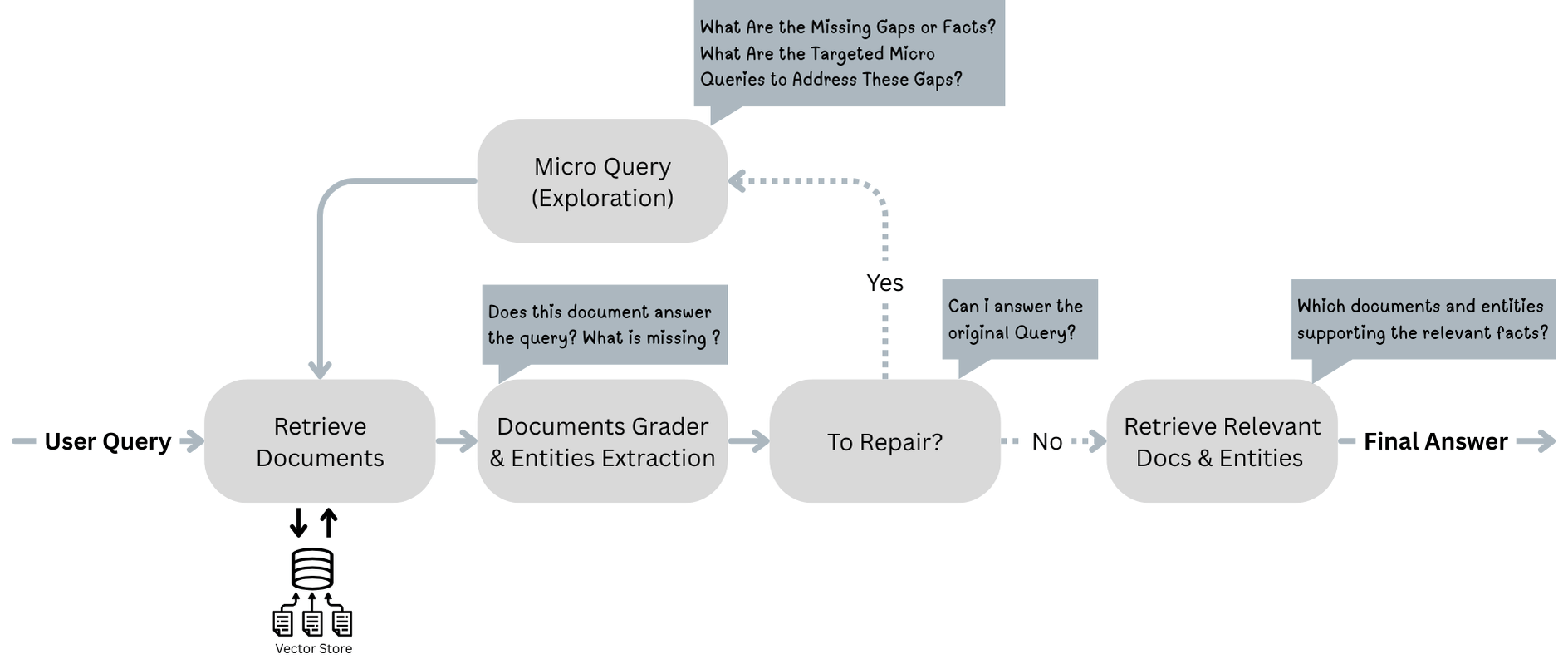
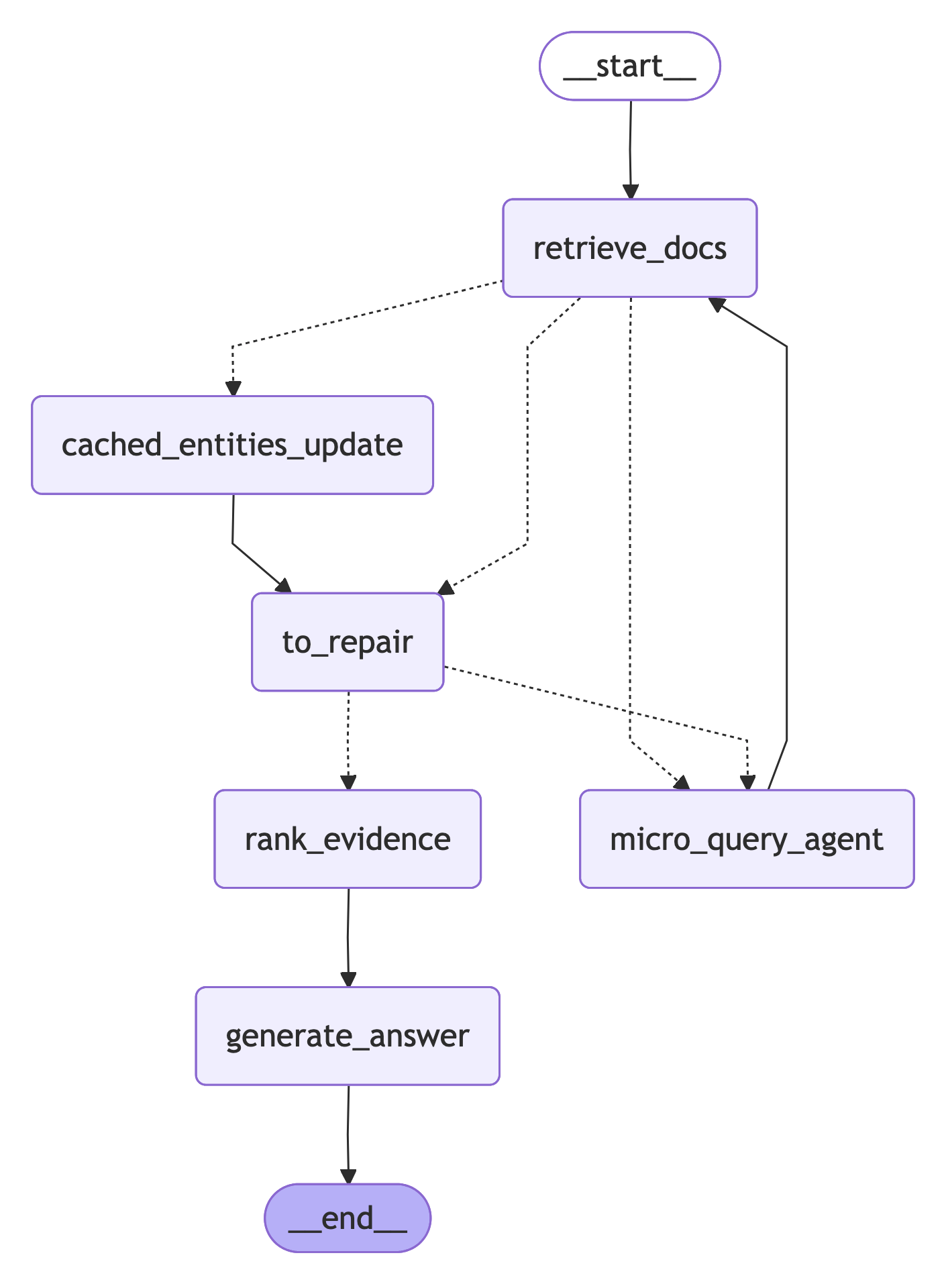
What is SEAL-RAG and how does it work?
SEAL-RAG treats the evidence set like a backpack with fixed slots (say, the top-k documents). It never expands the backpack; it replaces items inside to keep the best mix. It runs a loop with four steps:
- Search: Pull an initial small set of documents (e.g., top 3 or top 5).
- Extract: Read these and list what’s known and what’s missing (the “gaps”). For example: “We know the singer’s name, but we’re missing the album release date.”
- Assess: Decide if there’s enough information to answer now. If not, figure out exactly what’s missing.
- Loop: Ask tiny, targeted “micro-queries” to fetch documents that fill those gaps (like “Blur Parklife release year”). Then swap out the least useful current document with the best new one. Repeat until it’s enough.
Key ideas in everyday language:
- Fixed budget: The AI is only allowed a set number of documents. No cheating by adding more.
- Gap-first thinking: Don’t just search “about” the topic. Search precisely for what’s missing.
- Replace, don’t expand: Keep the small set clean and focused by kicking out distractors and bringing in gap-filling evidence.
What did they find?
They tested SEAL-RAG on two well-known multi-step question datasets: HotpotQA and 2WikiMultiHopQA. They compared it to popular methods that either add more context (Self-RAG, CRAG) or prune a big list (Adaptive-k).
Main results in simple terms:
- On HotpotQA with 3 documents allowed (k=3), SEAL-RAG gave more correct answers and found more precise evidence than Self-RAG, improving correctness by roughly 3–13 percentage points and precision by 12–18 points.
- On 2WikiMultiHopQA with 5 documents (k=5), SEAL-RAG beat Adaptive-k by about 8 percentage points in accuracy and kept evidence very precise (around 96%), while CRAG’s precision dropped low (around 22%), showing how adding lots of extra context can flood the system with distractors.
- Even with only 1 document (k=1), SEAL-RAG performed far better than methods that try to add or prune, because it focuses on finding and keeping the single most useful page.
These gains were statistically significant (meaning it’s very unlikely they happened by chance).
Why this is important:
- It proves that careful replacement can outperform “just add more,” especially for multi-step reasoning.
- It keeps the cost predictable: the AI reads a fixed small set, which is faster and cheaper than reading huge context windows.
- It helps the AI focus on the exact missing facts, instead of getting lost in general pages or duplicates.
What’s the impact of this research?
The paper suggests a shift in how we build practical AI search-answering systems:
- In many real-world apps (like customer support or medical info), time and token budgets are tight. SEAL-RAG shows you can get better accuracy without expanding the amount of text the AI reads.
- For tricky questions that need connecting facts from different sources, this method helps the AI assemble a clean, minimal set of evidence that directly answers the question.
- It’s training-free and works with existing tools, which makes it easier to adopt.
Simple limitations to keep in mind:
- If the missing info is too fuzzy (like “the general mood of the era”), it’s hard to write precise micro-queries.
- If you truly need many documents at once (like listing 20 items) and k is small, replacing won’t “collect” everything at the same time.
- Automatic extraction can sometimes miss rare names or special details, so there’s room for future improvements.
Key takeaways
- More text isn’t always better; it can confuse the AI.
- A small, well-chosen set of documents beats a large, messy one.
- SEAL-RAG’s “replace, don’t expand” approach helps the AI fill knowledge gaps with targeted searches and keeps the evidence clean.
- It improves accuracy on multi-step questions and keeps costs predictable—very useful for real-world systems.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, actionable list of the main knowledge gaps, limitations, and open questions the paper leaves unresolved.
- External validity beyond Wikipedia QA: SEAL-RAG is evaluated only on HotpotQA and 2WikiMultiHopQA slices; it remains unclear how the controller performs on domain-specific corpora (e.g., legal, biomedical), web-scale retrieval, or enterprise knowledge bases with heterogeneous document formats.
- Dependence on proprietary components: Results rely on OpenAI embeddings (text-embedding-3-small), GPT-4-family LLMs, and Pinecone; reproducibility and performance with open-source LLMs (e.g., Llama, Mistral) and alternative retrievers (BM25, Contriever, ColBERT, SPLADE) are not assessed.
- Latency and cost profiling: The fixed-budget claim is not supported by empirical measurements; end-to-end latency, token usage, number of retriever calls per loop, and cost variance across L and k are not reported.
- Sensitivity to hyperparameters: The entity-first utility weights (λ1–λ4), swap threshold ε, dwell-time guard, loop budget L, and fixed depth k lack sensitivity analyses; their impact on performance and stability remains unknown.
- Convergence and thrashing behavior: No analysis of swap dynamics (e.g., oscillations, “thrashing” rate, convergence criteria); how often replacements revert or cycle under different ε/dwell-time settings is not measured.
- Accuracy of the Entity Ledger: The extraction module’s precision/recall (entities, relations, qualifiers) and coreference resolution accuracy are not quantitatively evaluated; error propagation from ledger mistakes is not characterized.
- Robustness to aliasing and entity linking: While alias mismatch is noted, there is no systematic evaluation of alias resolution, canonicalization, and cross-document entity linking under realistic ambiguity (e.g., homonyms, rare aliases).
- Gap identification fidelity: The method assumes a “query schema” to derive information needs; how this schema is produced, its accuracy across question types, and failure cases (implicit/abstract needs) are not examined.
- Micro-query generation details: The algorithm, prompting strategy, and constraints for atomic micro-queries are under-specified; there is no ablation comparing micro-queries to alternative query rewriting strategies (e.g., Self-Ask, iterative reformulation).
- Contradiction handling and conflict resolution: The contradiction signal is scored by the LLM, but the paper does not specify thresholds or resolution policies (e.g., tie-breaking, provenance weighting) nor report metrics on contradiction detection quality.
- Evidence ranking alternatives: The entity-first ranking is only compared to baseline controllers; comparisons against trained cross-encoders, learning-to-rank, or submodular selection baselines (e.g., facility-location objectives) are absent.
- Theoretical guarantees: There is no formal analysis of the replacement policy (e.g., submodularity, approximation guarantees, or optimality bounds) under fixed capacity constraints.
- Large-context regimes: The claim that “more context is worse” is not tested with very large-context models (e.g., 128k/1M tokens); whether replacement remains superior when LLMs can attend over much larger curated contexts is unknown.
- Task generality: The approach is tested on QA only; applicability to other RAG tasks (e.g., long-form summarization, fact-checking, multi-turn dialogue, citation generation) and multi-modal retrieval (tables, images) is unexplored.
- Multilingual robustness: The pipeline’s reliance on English-centric extraction and alias normalization leaves performance in non-English or code-mixed queries unexplored.
- Retrieval index segmentation choice: The “Natural Document Segmentation” strategy is claimed beneficial but not ablated against common chunking/windowing schemes; its contribution to SEAL’s gains is unknown.
- Baseline fidelity vs. training: Self-RAG and CRAG are re-implemented in a training-free setup, potentially underrepresenting their trained variants; how SEAL compares to properly trained baselines is not evaluated.
- Generalization across k: While k∈{1,3,5} is tested, the behavior for larger k (e.g., 10–50) and tasks requiring aggregating many documents simultaneously (lists, exhaustive queries) is unclear; no fallback or batching strategy is proposed.
- Repair ceiling and missed bridges: The rate at which micro-queries recover bridges absent from the initial pool is not reported; failure analysis does not quantify when Active Repair still cannot surface missing facts.
- Blocklist policy effects: The blocklist B_t is introduced without ablation; its impact on avoiding loops vs. prematurely suppressing productive queries is not measured.
- Controller’s reliance on LLM judgments: Sufficiency, coverage, corroboration, and answerability are zero-shot LLM scores; their calibration, reliability across models, and susceptibility to prompt or model drift are untested.
- Evaluation bias and human validation: LLM-as-judge (Judge-EM) is used exclusively; no human evaluation, inter-annotator agreement, or error typology audits are provided to validate correctness and evidence use.
- Evidence quality metrics in open settings: Gold-title Precision/Recall use alias normalization tied to Wikipedia; how to measure evidence quality in open-domain corpora without gold titles (e.g., via entailment/attribution) is left open.
- Adversarial and noisy settings: Robustness to distractor injection, adversarially-crafted passages, conflicting sources, or noise-heavy corpora is not evaluated; the controller’s contradiction mitigation in such settings remains unknown.
- Safety and reliability: The controller’s behavior under unsafe or sensitive queries, its tendency to hallucinate despite the Verbatim Constraint, and guardrails for misinformation are not studied.
- Failure-mode remediation: Proposed fixes (e.g., verification steps to reduce extraction noise) are not implemented or quantified; the trade-offs in latency and accuracy for adding verification are not examined.
- Integration with adaptive selection: The interaction of replacement with dynamic selection methods (e.g., Adaptive-k + repair) is not explored; hybrid controllers may outperform either alone.
- Retrieval-time vs. read-time reasoning boundaries: The shift from read-time to retrieval-time reasoning is argued conceptually, but a formal characterization of which question types benefit (bridge vs. comparison vs. compositional) and per-type breakdowns are missing.
- Reproducibility concerns: Deterministic claims rely on temperature=0, but API/model updates can change behavior; the paper does not provide seeds, full prompts, and model snapshots sufficient for strict reproducibility with proprietary services.
- Scalability under load: There is no analysis of throughput, parallelism, and caching strategies needed to deploy SEAL-RAG at production scale; micro-query rates and vector-store contention under concurrency remain uncharacterized.
Practical Applications
Overview
Below are practical applications derived from the paper’s “replace, don’t expand” paradigm for multi-hop Retrieval-Augmented Generation (RAG), the SEAL-RAG controller, and its fixed-budget, gap-aware evidence assembly. Applications are grouped by deployment horizon and, where relevant, are linked to sectors and note potential tools/workflows and key assumptions or dependencies.
Immediate Applications
- Precision-first enterprise knowledge assistants
- Sectors: software, enterprise IT, operations
- What: Integrate SEAL-RAG as a controller in existing RAG stacks (e.g., LangGraph/LangChain + Pinecone + OpenAI embeddings) to answer complex internal queries (policies, procedures, cross-team dependencies) without expanding context.
- Workflow: Fixed-k retrieval → entity ledger extraction → sufficiency gate → targeted micro-queries → replacement of distractors → single final generation.
- Assumptions/Dependencies: Clean internal index; reliable entity extraction with aliases; stable LLM performance; access control and logging for provenance.
- Customer support copilots for multi-hop troubleshooting
- Sectors: customer service, telecommunications, SaaS
- What: Use SEAL-RAG to assemble only the most relevant docs across product manuals, tickets, and changelogs (e.g., “feature X fails after patch Y if Z is enabled”).
- Tools/Products: SEAL-RAG controller wrapped as a microservice; ticket desk plugin (e.g., Zendesk plugin).
- Assumptions/Dependencies: High-quality document segmentation; domain-specific synonym/alias maps; latency budgets compatible with loop L.
- Legal and compliance Q&A with auditable provenance
- Sectors: legal, compliance, finance
- What: Retrieve statutes and regulatory clauses, then target missing qualifiers (date, jurisdiction, clause number) via micro-queries; replace irrelevant summaries with primary sources.
- Workflow: Entity ledger + qualifiers (dates/sections) → micro-queries for missing legal details → entity-first ranking to evict distractors → emit answer with citations.
- Assumptions/Dependencies: Up-to-date, authoritative corpora; careful prompt/judge calibration; human-in-the-loop for high-stakes decisions.
- Scientific literature triage and evidence assembly
- Sectors: academia, pharma R&D
- What: Assemble minimal, high-precision sets of papers to answer multi-hop questions (e.g., “Which clinical trial established efficacy of compound A for indication B under dosage C?”).
- Tools/Products: Research assistant plugin integrated with PubMed/semantic scholar indices; provenance logs from the entity ledger.
- Assumptions/Dependencies: Access to bibliographic databases; domain-specific ontologies; alias normalization for author names, compounds, and trials.
- Educational study assistants that reduce context dilution
- Sectors: education, edtech
- What: Tutors that fetch concise, gap-closing excerpts from textbooks/notes for multistep questions (e.g., compare two historical events with specific dates and outcomes).
- Workflow: Explicit gap specification (missing dates/relations) → micro-queries → replacement to maintain k and precision.
- Assumptions/Dependencies: Indexed course materials; correct entity linking; content licensing.
- FinOps and cost governance for LLM deployments
- Sectors: finance (IT cost management), software platform ops
- What: Adopt fixed-k evidencing and single final generation to keep token/latency within predictable envelopes; dashboards that track loop L and swap decisions.
- Tools/Products: “RAG budget” policies; controller logs integrated into observability stacks (Datadog, Grafana).
- Assumptions/Dependencies: Instrumentation of controller states; policy thresholds for k and L; consistent retriever performance.
- E-discovery and document review optimizers
- Sectors: legal, enterprise search
- What: Targeted micro-queries for missing links (e.g., “which email references contract revision X?”), replacing topical but non-probative documents to keep precision high.
- Tools/Products: E-discovery pipeline augmentation with SEAL-RAG; audit-ready ledger export.
- Assumptions/Dependencies: Comprehensive index; robust access controls; alias/redirect maps.
- News/claims fact-checking with high evidence precision
- Sectors: media, civic tech
- What: Gap-driven micro-queries for dates, locations, and named entities; replacement of opinion pieces with primary reporting or official sources.
- Workflow: Verbatim constraint to ensure extracted facts are text-supported; sufficiency gate before emitting verdict.
- Assumptions/Dependencies: Source credibility scoring; fast web retrieval; careful blocking of low-signal sources.
- Cybersecurity alert triage
- Sectors: cybersecurity, IT operations
- What: Retrieve CVEs and patch notes, then fill missing qualifiers (affected versions, release dates); replace forum chatter with vendor advisories.
- Tools/Products: SOC integrations; controller-driven playbooks that output minimal high-signal artifacts for analysts.
- Assumptions/Dependencies: Up-to-date vulnerability feeds; correct entity normalization for product/version naming.
- RPA (Robotic Process Automation) for form completion
- Sectors: operations, HR, procurement
- What: Multi-source field filling (e.g., vendor IDs, contract dates) using micro-queries; keep fixed-k evidence and expose provenance for audit.
- Tools/Products: RPA bots augmented with SEAL-RAG; “explain-why” panels using the entity ledger.
- Assumptions/Dependencies: Access to structured/unstructured repositories; clear data governance.
- Developer tools: controller plug-ins
- Sectors: software, tooling
- What: Package SEAL-RAG as a controller SDK for LangGraph/LangChain with configurable utility function weights (gap coverage, corroboration, novelty, redundancy).
- Tools/Products: Open-source repo (paper’s GitHub); templates for fixed-k RAG graphs; Pinecone/Weaviate adapters.
- Assumptions/Dependencies: Maintained open-source components; compatibility with chosen LLM/backends; observability hooks.
- Search engine query rewriting modules
- Sectors: search, ad-tech
- What: Replace broad rewrites with atomic micro-queries derived from explicit gaps; boost clickthrough on high-intent queries.
- Workflow: Question parsing → gap typing (entity/relation/qualifier) → atomic query generation → ranking by gap coverage.
- Assumptions/Dependencies: Accurate gap parsing at scale; evaluation instrumentation; alignment with relevance ranking pipelines.
Long-Term Applications
- Regulated clinical decision support with verifiable evidence trails
- Sectors: healthcare
- What: SEAL-RAG-like controllers that retrieve guideline-level evidence and fill missing qualifiers (dosage, contraindications), emitting answers only under sufficiency gates and with strict provenance.
- Potential Products: “Evidence-first CDS” with clinical ontologies and verification modules.
- Assumptions/Dependencies: Medical-grade extraction and verification; rigorous validation and regulatory approvals (e.g., FDA/CE); domain-specific aliasing.
- Organizational knowledge graphs via continuous gap repair
- Sectors: enterprise knowledge ops
- What: Use the entity ledger to incrementally construct canonical entity-relationship graphs; run continuous gap-detection and micro-query repair to keep knowledge fresh.
- Potential Tools: Knowledge ops platforms with SEAL-RAG controllers; ledger-to-graph ETL.
- Assumptions/Dependencies: Stable identity resolution; governance over graph updates; change management.
- Policy synthesis and impact analysis assistants
- Sectors: government, public policy, NGOs
- What: Multi-document policy assistants that target missing qualifiers (effective dates, jurisdictions, exceptions), replacing narrative commentary with statutes and impact studies.
- Potential Products: Policy drafting copilots with sufficiency gates and audit logs.
- Assumptions/Dependencies: Access to authoritative legal/policy data; transparent decision criteria; human review loops.
- Multi-modal fixed-budget retrieval (text + code + logs + images)
- Sectors: software reliability, manufacturing, robotics
- What: Extend entity-ledger extraction and gap typing across modalities (stack traces, telemetry, diagrams), replacing noisy artifacts with gap-closing evidence.
- Potential Products: “Precision incident copilots” for SRE/DevOps; factory diagnostic assistants.
- Assumptions/Dependencies: Multi-modal embeddings; modality-specific extractors; unified utility functions.
- Privacy-preserving, on-prem RAG with predictable cost envelopes
- Sectors: finance, healthcare, government
- What: Deploy SEAL-RAG within air-gapped environments; fixed-k windows for predictable latency/token budgets; strict provenance logging.
- Potential Products: Compliance-ready RAG appliances; controller-as-a-service on-prem.
- Assumptions/Dependencies: Private vector stores; local LLMs; robust identity/alias mapping built in-house.
- Edge/IoT assistants for constrained environments
- Sectors: energy, logistics, automotive
- What: On-device retrieval-time reasoning with strict k and L, enabling micro-queries to local indices and replacement policies under tight compute and bandwidth.
- Potential Products: Maintenance assistants; driver/copilot systems; field repair tools.
- Assumptions/Dependencies: Lightweight models; local caching; intermittent connectivity strategies.
- Standardization of evidence precision/provenance in LLM QA
- Sectors: standards bodies, certification
- What: Benchmarks and compliance rubrics for controller-level precision, sufficiency gating, and provenance logging; audits focused on context composition.
- Potential Products: Certification kits; controller evaluation harnesses.
- Assumptions/Dependencies: Community consensus; robust, reproducible metrics; cross-model comparability.
- Autonomous research agents with retrieval-time reasoning
- Sectors: academia, industrial R&D
- What: Agents that iteratively close gaps via micro-queries, maintain entity ledgers, and emit answers only when sufficiency predicates hold; expanded to hypothesis generation.
- Potential Products: Lab copilots; literature-to-experiment planners.
- Assumptions/Dependencies: Strong verification and de-biasing; domain ontologies; oversight mechanisms.
- Financial due diligence copilots
- Sectors: finance, consulting
- What: Multi-hop linking of management biographies, filings, and news with dates/locations qualifiers; high-precision evidence assembly under token budgets.
- Potential Products: M&A diligence assistants; risk assessment dashboards.
- Assumptions/Dependencies: Premium data sources; up-to-date indices; compliance workflows.
- Advanced evaluation frameworks for controller-centric RAG
- Sectors: ML tooling, research
- What: Open testbeds that isolate controller logic from retrievers/LLMs, with statistical significance routines and blind judging; adoption of fixed-k and loop-budget ablations.
- Potential Products: Controller benchmarking suites; research platforms.
- Assumptions/Dependencies: Shared environments; standardized datasets; judge stability.
Notes on cross-cutting assumptions and dependencies
- Index quality and coverage: Success depends on high-quality, well-segmented indices and access to authoritative sources.
- Entity extraction and aliasing: Robust alias normalization and entity linking are critical, especially in specialized domains.
- LLM reliability: Controller signals (coverage, corroboration, contradiction, answerability) depend on LLM scoring being stable; temperature and prompt discipline matter.
- Governance and auditability: Provenance logs (entity ledger + citations) should be integrated into compliance and review workflows for high-stakes use.
- Cost/latency constraints: Fixed-k and loop budget L must be tuned to meet SLAs; micro-queries should be instrumented for efficiency.
- Human-in-the-loop: For regulated or high-risk domains, human review remains necessary until verification modules are mature.
Glossary
- 2WikiMultiHopQA: A multi-hop question answering dataset requiring compositional reasoning across Wikipedia entities. "On 2WikiMultiHopQA (), it outperforms Adaptive- by +8.0 pp in accuracy"
- Adaptive-: A dynamic pruning method that selects an optimal number of retrieved documents by analyzing relevance score gaps. "Adaptive- by +8.0 pp in accuracy"
- Adaptive-RAG: A routing approach that classifies query complexity to choose between retrieval-free and retrieval-augmented processing. "Adaptive-RAG \cite{jeong2024adaptive} functions as a router"
- Active Repair: A controller strategy that diagnoses missing information and fetches new evidence to replace distractors. "In contrast, SEAL-RAG performs Active Repair"
- Active Retrieval: An inference-time process where the system interacts with search tools to iteratively improve retrieved evidence. "Active Retrieval \cite{jiang2023active}"
- Alias Normalization: A matching procedure that maps aliases and redirects to canonical titles for evaluating evidence retrieval. "Alias Normalization: retrieved titles are matched against gold titles using a redirect map"
- Breadth-First Addition: A corrective strategy that appends new passages to the context without evicting existing ones. "they typically operate via Breadth-First Addition: they append new passages to the existing context"
- Budgeted Maximization: An optimization setup that selects evidence under a strict size constraint to maximize answer correctness. "We treat evidence assembly as a Budgeted Maximization problem"
- ColBERT: A late-interaction dense retrieval model that enables efficient passage search via token-level matching. "late-interaction models like ColBERT"
- Context Dilution: Degradation of reasoning due to irrelevant or redundant context crowding out key information. "a phenomenon known as context dilution"
- CRAG: Corrective Retrieval Augmented Generation; a method that evaluates retrieval quality and augments context via additional searches. "CRAG (Corrective RAG)"
- Dense Passage Retrieval (DPR): A dense vector-based retrieval method for open-domain question answering. "dense retrievers like DPR"
- Dwell-Time Guard: A controller mechanism that temporarily protects newly inserted evidence from immediate eviction. "Dwell-Time Guard"
- Entity Ledger: A structured record of entities, relations, and provenance extracted from the evidence set. "Entity Ledger"
- Entity-First Replacement: A policy that ranks and swaps passages based on their ability to close entity-centric gaps. "Entity-First Replacement policy"
- Explicit Gap Specification: A precise, structured description of missing entities, relations, or qualifiers needed to answer the query. "Explicit Gap Specification"
- Fixed-Budget Evidence Assembly: A paradigm that optimizes a fixed-size context by replacing low-utility items rather than expanding. "Fixed-Budget Evidence Assembly"
- Fixed- Gap Repair: An approach that repairs missing information while strictly maintaining a fixed number of retrieved passages. "Fixed- Gap Repair"
- Gold-title Precision@: The proportion of top- retrieved titles that match the gold evidence titles. "Gold-title Precision@"
- Holm-Bonferroni correction: A multiple-comparisons procedure for controlling the family-wise error rate in statistical tests. "Holm-Bonferroni correction"
- HotpotQA: A multi-hop question answering benchmark emphasizing bridge and comparison reasoning. "On HotpotQA ()"
- Hysteresis Threshold: A margin in replacement decisions to prevent thrashing between near-equivalent passages. "a small hysteresis threshold"
- Judge-EM: An accuracy metric where an external judge assesses factual consistency of answers against ground truth. "Judge-EM"
- LangGraph: A framework for building agentic workflows with explicit state management and graph-based execution. "workflows using LangGraph"
- Largest Gap Strategy: A pruning heuristic that chooses the cut-off point in a ranked list based on the biggest score drop. "the ``Largest Gap'' strategy"
- Late Interaction: A retrieval design where interaction between query and document representations occurs at a token level post-encoding. "late-interaction models"
- Maximal Marginal Relevance (MMR): A ranking criterion balancing relevance and novelty to reduce redundancy. "Maximal Marginal Relevance (MMR)"
- McNemar’s test: A statistical test for paired nominal data to compare two classifiers on the same instances. "McNemarâs test"
- Micro-Query: A targeted, atomic query generated to fetch evidence specifically addressing a diagnosed gap. "micro-queries"
- Multi-hop Reasoning: Answering that requires composing information across multiple documents or facts. "multi-hop reasoning"
- Natural Document Segmentation: An indexing approach that preserves semantic integrity by using entire pages or coherent units as retrieval items. "Natural Document Segmentation"
- Open Information Extraction: A method for extracting structured relations and facts from unstructured text without a fixed schema. "Open Information Extraction"
- Parametric Leakage: Using model-internal knowledge rather than retrieved evidence, potentially biasing evaluation. "to prevent parametric leakage"
- Pinecone: A managed vector database used to store and query dense embeddings for retrieval. "a Pinecone vector store"
- Read-Time Reasoning: Dependence on the generator to integrate multiple evidence pieces simultaneously during answer generation. "Read-Time Reasoning"
- Redirect Map: A mapping of aliases and alternative titles to canonical pages used for evidence matching. "a redirect map (e.g., mapping
JFK'' toJohn F. Kennedy'')" - Retrieval-Augmented Generation (RAG): A paradigm where a generator uses retrieved documents to produce answers. "Retrieval-Augmented Generation (RAG) systems"
- Retrieval-Time Reasoning: Offloading bridging and linking steps to the retrieval/controller phase before final generation. "Retrieval-Time Reasoning"
- Self-RAG: A reflective RAG method where the model critiques its own retrieval and generation to trigger corrective steps. "Self-RAG"
- Sufficiency Gate: A decision module that assesses whether the current evidence is adequate to answer the query. "The Sufficiency Gate"
- Tavily: An external web search service used to augment retrieval in corrective pipelines. "via Tavily"
- Verbatim Constraint: A rule requiring extracted facts to be explicitly supported by text spans to prevent hallucination. "Verbatim Constraint"
- Zero-shot estimator: Using an LLM without task-specific training to score components like coverage or answerability. "zero-shot estimator"
Collections
Sign up for free to add this paper to one or more collections.