Deep GraphRAG: A Balanced Approach to Hierarchical Retrieval and Adaptive Integration
Abstract: Graph-based Retrieval-Augmented Generation (GraphRAG) frameworks face a trade-off between the comprehensiveness of global search and the efficiency of local search. Existing methods are often challenged by navigating large-scale hierarchical graphs, optimizing retrieval paths, and balancing exploration-exploitation dynamics, frequently lacking robust multi-stage re-ranking. To overcome these deficits, we propose Deep GraphRAG, a framework designed for a balanced approach to hierarchical retrieval and adaptive integration. It introduces a hierarchical global-to-local retrieval strategy that integrates macroscopic inter-community and microscopic intra-community contextual relations. This strategy employs a three-stage process: (1) inter-community filtering, which prunes the search space using local context; (2) community-level refinement, which prioritizes relevant subgraphs via entity-interaction analysis; and (3) entity-level fine-grained search within target communities. A beam search-optimized dynamic re-ranking module guides this process, continuously filtering candidates to balance efficiency and global comprehensiveness. Deep GraphRAG also features a Knowledge Integration Module leveraging a compact LLM, trained with Dynamic Weighting Reward GRPO (DW-GRPO). This novel reinforcement learning approach dynamically adjusts reward weights to balance three key objectives: relevance, faithfulness, and conciseness. This training enables compact models (1.5B) to approach the performance of large models (70B) in the integration task. Evaluations on Natural Questions and HotpotQA demonstrate that Deep GraphRAG significantly outperforms baseline graph retrieval methods in both accuracy and efficiency.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Deep GraphRAG: What this paper is about
This paper introduces a smarter way for AI systems to find and use information called Deep GraphRAG. It helps LLMs answer questions more accurately and faster by searching through a “map” of knowledge (a graph) from big picture to small details, and then carefully combining the right pieces into a clear, truthful answer. It also shows how to train a smaller AI model to do this well by balancing three goals: being relevant, being faithful to the facts, and being concise.
The main goals of the research
The authors wanted to solve three practical problems:
- How to search a huge web of information without getting lost (look wide enough to find the right area, but deep enough to get details).
- How to avoid picking the wrong path when searching, by re-checking and re-sorting options at every step.
- How to train a smaller, cheaper AI to combine information in a way that’s correct, useful, and not too long.
How their system works (in simple terms)
Think of knowledge as a city:
- The “graph” is a map of the city, where locations (entities) are dots and roads (relationships) connect them.
- “Communities” are neighborhoods—groups of related dots.
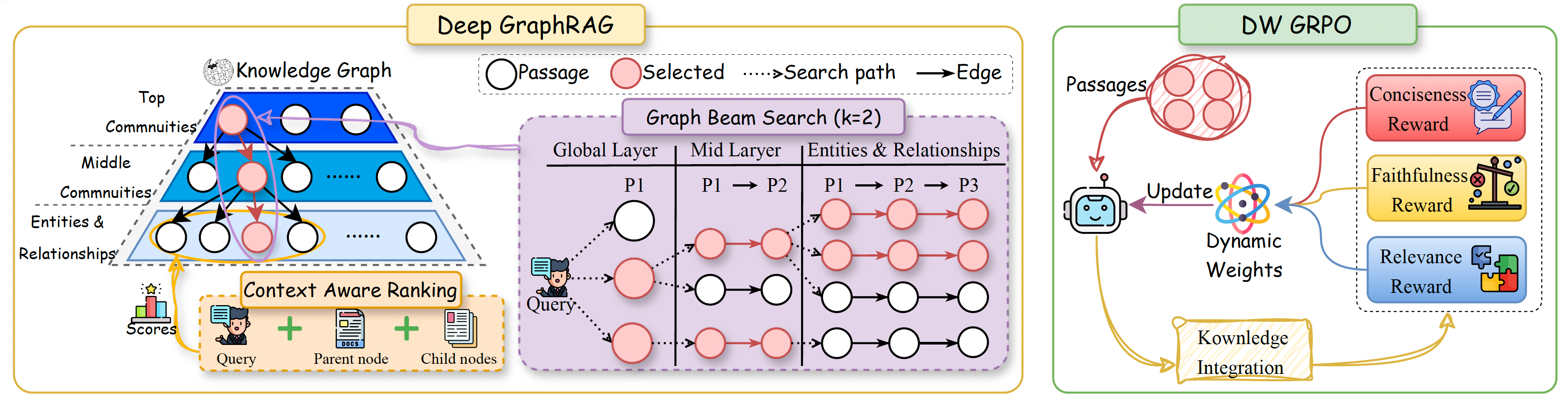
- Deep GraphRAG searches like using a zoomable map: from city-level, to neighborhood-level, to specific buildings.
Here’s the three-stage search strategy:
- Inter-community filtering (city view): Quickly pick the most promising neighborhoods based on the question.
- Community-level refinement (neighborhood view): Look inside those neighborhoods to find the most relevant clusters of facts.
- Entity-level search (street view): Zoom into the best neighborhoods to pick the exact facts (entities) that answer the question.
To avoid going down the wrong road, the system uses beam search with dynamic re-ranking:
- Beam search = keep the top few best options at each step (like following the 3 most promising routes at once).
- Dynamic re-ranking = repeatedly re-check and re-sort which options look best as new info appears.
How the knowledge map is built:
- Split long documents into chunks and extract entities (people, places, things) and their relationships using a LLM.
- Merge duplicate entities (e.g., “U.S.” and “United States”) so the map stays clean and consistent.
- Group related entities into a three-level hierarchy (like buildings → neighborhoods → districts) using a community detection method.
How answers are combined (knowledge integration):
- After retrieving the best pieces, an AI model writes a short, accurate response.
- The authors train a compact model (1.5B) using a new technique called DW-GRPO (Dynamic Weighting Reward GRPO) that balances three goals:
- Relevance: Does the answer address the question?
- Faithfulness: Is it true to the source text?
- Conciseness: Is it short and not repetitive?
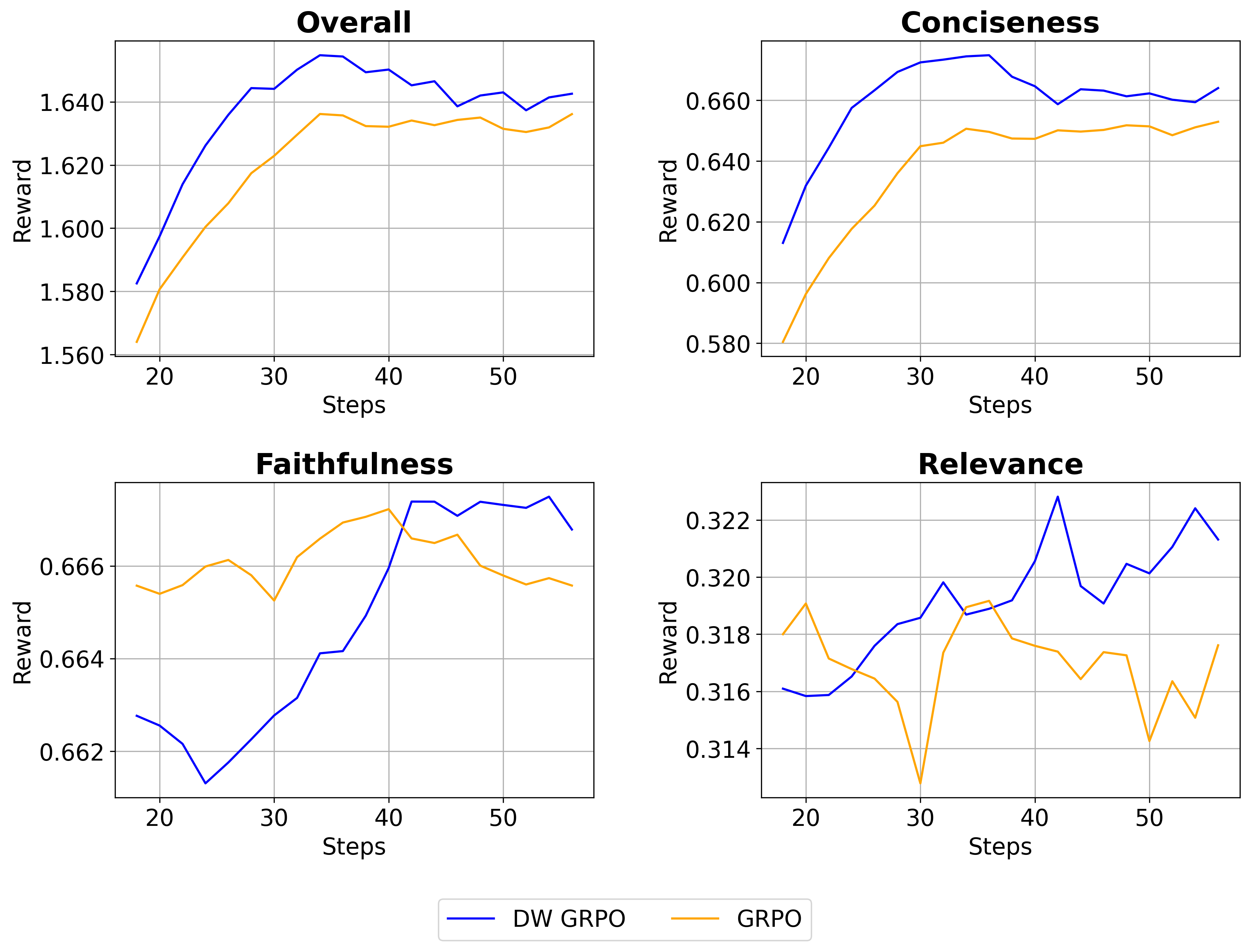
- DW-GRPO adjusts how much it cares about each goal on the fly—if one goal lags (say, faithfulness), it boosts that goal’s importance until the model improves.
What they found and why it matters
- Better accuracy on hard questions: On two popular datasets (Natural Questions and HotpotQA), Deep GraphRAG got higher overall exact-match scores than other methods, especially on “global” questions that require connecting information across different sources or topics.
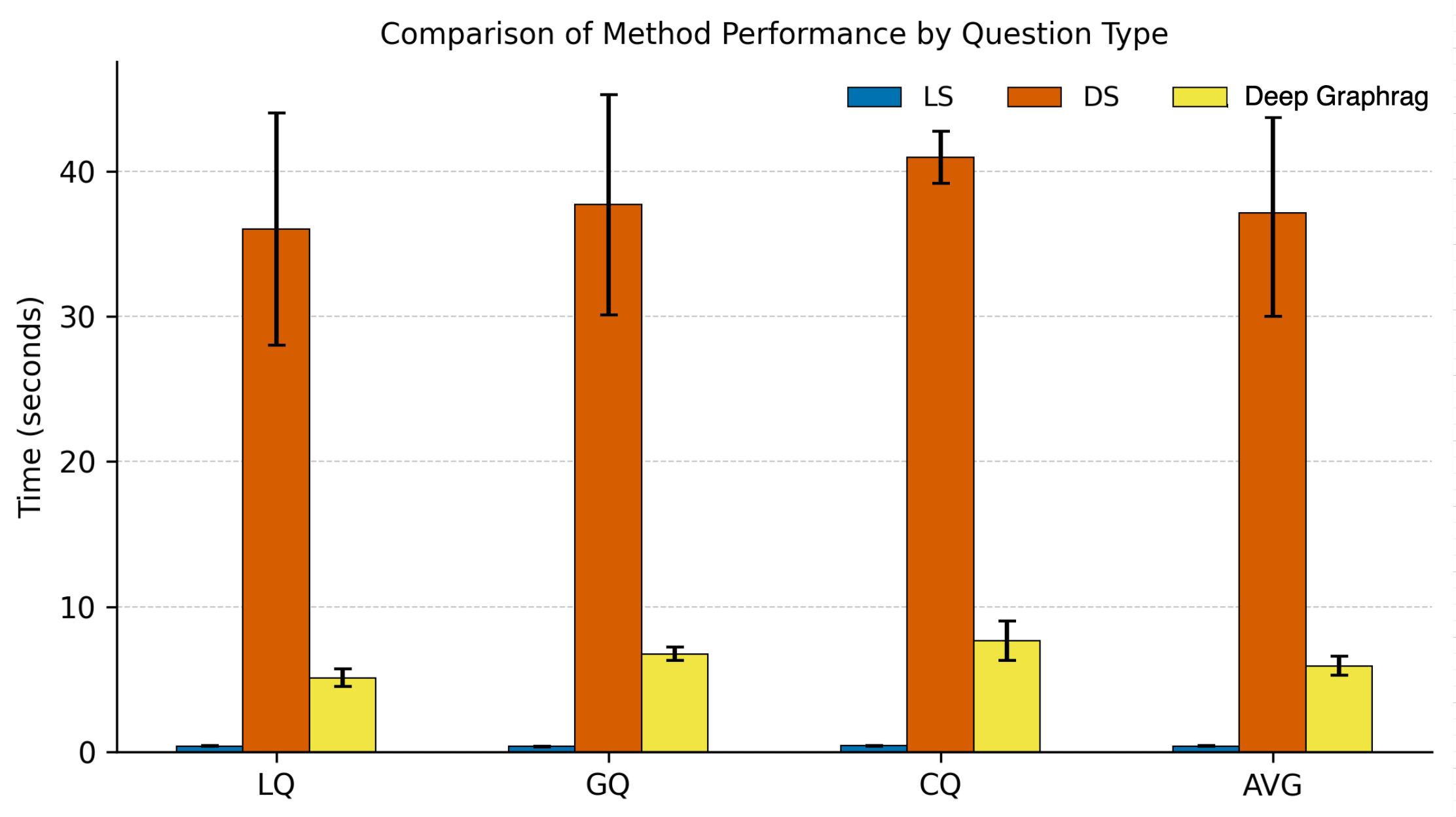
- Faster answers: Compared to a strong baseline (Drift Search), Deep GraphRAG cut the time to get results by about 80%+ in tests—meaning it’s not just smarter, but also quicker.
- Small model, big performance: Using DW-GRPO, their small 1.5B model got close to the performance of much larger models (like 72B) for the integration step. That’s a big deal because smaller models are cheaper and easier to run.
- Honest trade-offs: On some “comprehensive” questions (which need both big-picture reasoning and small details), the method didn’t always win. This shows a known challenge: summarizing broadly can sometimes hide tiny but important facts.
Why this research is useful
- More reliable AI answers: The system is designed to reduce hallucinations (made-up facts) by searching structured knowledge and rewarding faithfulness.
- Works on smaller computers: Because the smaller model performs well, this approach could be used in places where big models are too costly.
- Good for complex tasks: It’s especially strong at questions that need multi-step reasoning across different topics—useful for research assistants, enterprise search, or customer support.
- A better way to train: DW-GRPO offers a general idea—don’t keep fixed priorities during training. Instead, watch which skill is lagging and boost it. That can be applied beyond this paper.
In short
Deep GraphRAG is like a careful city-wide search that starts from a map, zooms into the right neighborhoods, picks the exact buildings you need, and then writes a clear, truthful summary. It beats other methods on accuracy and speed for tough questions—and shows how smaller models can punch above their weight by training with smart, adaptive goals.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or left unexplored in the paper. Each point is framed to be concrete and actionable for future research.
- Coverage and generalization beyond NQ/HotpotQA: Assess Deep GraphRAG on diverse domains (e.g., scientific literature, finance, law), multilingual corpora, and non-English queries to validate domain and language robustness.
- Graph construction quality and error analysis: Quantify precision/recall of entity and relation extraction by Qwen2.5-72B and measure how extraction errors propagate through retrieval and integration; provide systematic error analyses and human audits.
- Sensitivity to chunking strategy: Evaluate the impact of fixed chunk size T=600 and overlap O=100 on entity boundary integrity, relation extraction, and downstream EM; search for optimal chunking under varied corpora and query types.
- Entity resolution thresholds and verification: Analyze the false-merge/false-split trade-offs of the high similarity threshold (τ>0.95) and LLM discriminator; report metrics and ablations for alternative thresholds, embeddings, and resolution strategies.
- Hierarchy design choices: Justify and ablate the 3-level Louvain hierarchy (γ=1.0), including depth selection, resolution parameter sensitivity, overlapping communities, and non-tree hierarchical structures; explore adaptive depth conditioned on query complexity.
- Representation learning limitations: Compare mean-pooling and concatenation-based representations to stronger graph-aware encoders (e.g., GNNs, graph transformers, attention pooling); test alternative sentence embeddings and cross-encoders for node/community scoring.
- Retrieval scoring simplicity: Investigate replacing cosine similarity with trained learning-to-rank models or cross-encoder scoring at each stage; quantify gains and cost trade-offs.
- Beam search hyperparameters: Conduct sensitivity studies on beam width (k), top-m entity selection, and stopping criteria; develop adaptive beam width policies tied to question type (LQ/GQ/CQ) or uncertainty.
- Multi-stage re-ranking details: Specify and evaluate the “dynamic re-ranking” algorithm components (features, update rules, heuristics); compare against bandit-based or supervised re-ranking baselines.
- Evidence tracking and faithfulness: Add explicit evidence selection, citation grounding, and faithfulness measurement beyond BERTScore (e.g., entailment checks, attribution metrics, human factuality ratings) to ensure verifiable answers.
- CQ performance trade-offs: Diagnose failure cases where hierarchical summarization obscures local facts; develop hybrid strategies (e.g., dual-path retrieval, evidence-preserving summarization) and evaluate their impact on CQ.
- Efficiency and scalability characterization: Provide end-to-end complexity analysis and benchmarks vs. graph size (nodes/edges), hierarchy depth, and beam widths; report memory, throughput, and scalability to millions of nodes.
- Latency measurement transparency: Detail hardware, batching, caching, parallelism, and pipeline components included in latency; break down retrieval vs. integration costs and include construction time overheads.
- Baseline comparability and significance: Ensure baselines are tuned comparably and report statistical significance (confidence intervals, variance across seeds); standardize integrator/generator across methods to isolate retrieval effects.
- DW-GRPO algorithm specification: Fully specify hyperparameters (temperature T, window τ, total weight W), normalization, and update schedules; provide pseudocode for weight updates and advantage estimation to improve reproducibility.
- Theoretical guarantees for DW-GRPO: Study convergence, stability, and regret properties of slope-based dynamic weighting; compare with multi-objective RL (Pareto optimization, constrained RL, gradient norm weighting) and analyze potential oscillations or reward hacking.
- Reward design robustness: Examine sensitivity to proxy metrics (cross-encoder relevance, BERTScore faithfulness, length-based conciseness), and test alternative or complementary signals (e.g., calibrated QA accuracy, entailment, compression ratios with semantic constraints).
- Human evaluation of integration quality: Include expert human judgments on relevance, factuality, and conciseness to validate proxy reward alignment and detect nuanced hallucinations or omissions.
- Training pipeline details: Report SFT data quantities, teacher-student distillation methodology, RL steps, batch sizes, optimizers, learning rates, and random seeds to support replication.
- Impact of teacher bias in distillation: Quantify how the 72B teacher’s biases influence the 1.5B student via SFT and RL; explore teacher diversity or ensemble teachers to mitigate bias transfer.
- End-to-end compact model evaluation: Test whether the 1.5B-DW-GRPO model can serve as both integrator and generator end-to-end without reliance on 72B/DeepSeek-R1, and measure performance, latency, and cost implications.
- Incremental and streaming graph updates: Develop methods for maintaining and updating the knowledge graph in dynamic corpora (concept drift, new entities/relations) with efficient re-indexing and minimal downtime.
- Robustness to adversarial or ambiguous queries: Evaluate behavior under prompt injection, ambiguous/multi-interpretation queries, and noisy input; add defenses and uncertainty-aware retrieval/integration.
- Provenance-preserving integration: Design integration outputs that retain source-level provenance (node/edge IDs, citations), enabling auditability and downstream verification.
- Cross-community linkage handling: Address how inter-community edges are preserved or prioritized when Louvain yields a tree-like hierarchy; evaluate retrieval across overlapping or densely interconnected communities.
- Multimodal and structured data extension: Explore extension to tables, images, code repositories, and structured KBs, and evaluate retrieval/integration across modalities.
- Resource and cost analysis: Quantify compute and monetary costs of LLM-based graph construction at scale; compare against lighter extraction pipelines and investigate cost-performance trade-offs.
Practical Applications
Overview
Below are practical, real-world applications derived from the paper’s hierarchical GraphRAG retrieval framework and the DW-GRPO training strategy for compact LLMs. Each item is categorized as deployable now or requiring further development, and linked to relevant sectors with potential tools/workflows and key assumptions or dependencies.
Immediate Applications
These can be piloted or deployed with existing tooling, data pipelines, and compact or large LLMs.
- Enterprise knowledge assistant for large document repositories (intranets, SharePoint, Confluence, email archives)
- Sector: software, enterprise IT
- Tools/Workflow: hierarchical knowledge graph indexer (entity extraction + resolution + Louvain clustering), Graph Beam Search with dynamic re-ranking, compact 1.5B integrator trained via DW-GRPO for cost-effective summarization, retrieval APIs
- Assumptions/Dependencies: access to document corpora; high-quality entity extraction; privacy/PII controls; embedding/cross-encoder availability (e.g., bge-m3, cross-encoder scorer)
- Customer support and contact center QA (multi-step troubleshooting and policy retrieval)
- Sector: software, consumer services
- Tools/Workflow: integrate GraphRAG into CRM/helpdesk; tri-stage global-to-local retrieval to avoid missing fine-grained steps; DW-GRPO to balance relevance, faithfulness, and concise answers for agents/customers
- Assumptions/Dependencies: clean, up-to-date support knowledge base; alignment with call scripts; human-in-the-loop escalation
- Legal e-discovery and compliance review (contracts, clauses, precedents)
- Sector: legal, compliance
- Tools/Workflow: contract/entity graph construction (parties, clauses, obligations), community-level refinement to surface related subgraphs, beam search re-ranking for multi-hop connections across documents
- Assumptions/Dependencies: accurate entity resolution across heterogeneous legal text; rigorous auditability; confidentiality safeguards; lawyer oversight
- Financial research assistant (cross-document analysis of 10-K/10-Q, earnings calls, news)
- Sector: finance
- Tools/Workflow: build issuer/metric/event graphs; global-to-local retrieval for multi-hop comparisons (e.g., segment changes vs. guidance); DW-GRPO-driven concise synthesis for analyst notes
- Assumptions/Dependencies: timely ingestion from data vendors; compliance with research restrictions; robust grounding to avoid hallucinations
- Cyber threat intelligence and threat hunting
- Sector: cybersecurity
- Tools/Workflow: IOC/TTP/actor knowledge graphs; community-level refinement to highlight related campaigns; entity-level fine-grained retrieval for case triage; latency improvements aid interactive hunts
- Assumptions/Dependencies: high-quality CTI feeds; continuous updates; false-positive mitigation; secure deployments
- Clinical literature and guideline QA for care teams
- Sector: healthcare
- Tools/Workflow: graph-based aggregation of guidelines, systematic reviews, drug labels; DW-GRPO to enforce faithfulness and conciseness; hierarchical retrieval for multi-hop clinical queries (e.g., comorbidity interactions)
- Assumptions/Dependencies: domain adaptation with medical ontologies; regulatory compliance (HIPAA); clinician supervision; careful validation of outputs
- Course and textbook assistants for multi-hop reasoning
- Sector: education
- Tools/Workflow: course content graph (concepts, prerequisites, examples); Graph Beam Search to traverse concepts; DW-GRPO-trained integrator generates crisp, grounded explanations
- Assumptions/Dependencies: rights to ingest content; mapping of curriculum to graph nodes; classroom integration plans
- Software engineering assistants (monorepo QA, design doc linking, bug triage)
- Sector: software
- Tools/Workflow: entity graph over code modules, dependencies, tickets; hierarchical search across services; small integrator for on-prem deployments to reduce cost/latency
- Assumptions/Dependencies: robust code/entity extraction; CI/CD integration; developer trust and review
- Business intelligence semantic lineage and metric QA
- Sector: software, data analytics
- Tools/Workflow: build semantic graph of metrics/dashboards/data lineage; global-to-local retrieval to explain discrepancies and trace metric derivations; concise DW-GRPO summaries
- Assumptions/Dependencies: accurate metadata/lineage; governance; BI tool integration
- SRE and incident response knowledge management
- Sector: software, DevOps
- Tools/Workflow: incident/runbook/log entity graphs; fast hierarchical retrieval for root-cause exploration; DW-GRPO ensures succinct, relevant mitigation steps
- Assumptions/Dependencies: secure ingestion from APM/log platforms; postmortem curation; on-call workflows
- Personal knowledge management (PKM) assistants
- Sector: daily life, productivity software
- Tools/Workflow: local notes/bookmarks/mail graph; compact integrator for on-device summarization; community-level refinement for topic hubs
- Assumptions/Dependencies: user consent and privacy; efficient local embeddings; lightweight indexing
- Government policy and regulation QA (statutes, regulatory guidance)
- Sector: public sector, policy
- Tools/Workflow: statute/regulation/agency guidance graphs; multi-hop queries across jurisdictions; DW-GRPO-trained integrator for clear, faithful summaries
- Assumptions/Dependencies: current corpora; jurisdictional mapping; legal review and accountability
Long-Term Applications
These require further R&D, scaling, domain adaptation, productization, or validation.
- Vertical GraphRAG foundation models (industry-specific)
- Sector: healthcare, finance, legal, cybersecurity, manufacturing
- Tools/Workflow: pre-training large graph encoders and integrators on domain corpora; standardized schemas/ontologies; continual learning on updates
- Assumptions/Dependencies: large-scale labeled/unlabeled graph corpora; domain evaluation suites; compute for training
- Real-time, multi-modal GraphRAG (text + tables + diagrams + logs + images)
- Sector: healthcare (EHR + imaging), energy (SCADA + telemetry), robotics (plans + sensor data)
- Tools/Workflow: cross-modal embedding alignment; streaming hierarchical retrieval; multi-modal DW-GRPO rewards (accuracy, safety)
- Assumptions/Dependencies: robust multi-modal encoders; latency constraints; safety/regulatory approvals
- Autonomous agents with hierarchical long-term memory
- Sector: robotics, process automation
- Tools/Workflow: agents that read/write into hierarchical knowledge graphs for planning and recall; dynamic re-ranking to avoid local optima
- Assumptions/Dependencies: reliable memory persistence; safe planning frameworks; alignment with human goals and constraints
- Privacy-preserving federated GraphRAG across organizations
- Sector: finance, healthcare, supply chain
- Tools/Workflow: federated retrieval and secure multi-party computation; policy-aware ranking across distributed graphs
- Assumptions/Dependencies: data-sharing agreements; privacy-preserving embeddings; performance trade-offs under privacy constraints
- DW-GRPO as a general multi-objective RL framework beyond RAG
- Sector: recommendation systems, planning, dialog systems
- Tools/Workflow: plug-in library to dynamically balance competing objectives (e.g., utility vs. fairness vs. diversity)
- Assumptions/Dependencies: reliable reward estimation; domain-specific metrics; stability under different temperatures/window sizes
- Regulatory-grade evidence synthesis (audit-ready outputs)
- Sector: healthcare, public policy, legal
- Tools/Workflow: provenance tracking in the retrieval chain; faithfulness auditing; standardized reporting for regulators
- Assumptions/Dependencies: agreed-upon standards for evidence grading; external validation; human oversight
- High-throughput legal drafting assistant (multi-source grounding)
- Sector: legal
- Tools/Workflow: hierarchical retrieval across precedents/statutes; DW-GRPO to balance brevity and legal fidelity; drafting workflows with review gates
- Assumptions/Dependencies: liability frameworks; court acceptability; continuous updates to corpora
- Energy grid incident prediction and mitigation
- Sector: energy
- Tools/Workflow: streaming GraphRAG over telemetry and maintenance logs; multi-hop causal path discovery; operator-facing concise briefs
- Assumptions/Dependencies: high-velocity data ingestion; integration with existing SCADA; safety-critical validation
- Automated investment research pipelines
- Sector: finance
- Tools/Workflow: end-to-end multi-hop retrieval + synthesis across filings, macro data, alt data; portfolio-level reasoning; compliance-aware outputs
- Assumptions/Dependencies: regulatory compliance (e.g., research independence); risk management; rigorous backtesting
- Personalized curriculum mapping and learning analytics
- Sector: education
- Tools/Workflow: learner knowledge graphs; multi-hop mapping from learning outcomes to materials; adaptive tutoring using DW-GRPO
- Assumptions/Dependencies: content alignment to standards; student data privacy; long-term efficacy studies
Notes on Assumptions and Dependencies
- Data quality and structure: The framework depends on accurate entity extraction, resolution, and hierarchical clustering; noisy corpora degrade retrieval quality.
- Reward models: DW-GRPO requires reliable relevance and faithfulness signals (e.g., cross-encoders, BERTScore); domain-specific calibration may be needed.
- Compute and latency: While latency reductions are shown versus specific baselines, real-world performance depends on embedding generation, graph size, and deployment architecture.
- Safety, compliance, and auditability: High-stakes domains (healthcare, legal, finance, public policy) require human oversight, provenance tracking, and regulatory adherence.
- Domain adaptation: Ontologies and schemas improve performance; custom prompts and extraction templates may be necessary per domain.
- Model choice: Compact integrators (≈1.5B) trained with DW-GRPO can approach large model performance for integration tasks, but generation may still benefit from larger models or careful distillation.
Glossary
- Beam search: A heuristic search strategy that explores the top k candidates at each level to efficiently traverse large search spaces. "beam search ()"
- BERTScore: A text evaluation metric that uses contextual embeddings to compute similarity between generated and reference texts. "BERTScore"
- Community hierarchy: A multi-level organization of graph nodes into nested communities to capture structure at different granularities. "multi-granular 3-level community hierarchy"
- Community-level refinement: A retrieval stage that prioritizes relevant subgraphs within selected communities based on entity interactions. "community-level refinement"
- Cosine similarity: A vector-based similarity measure that evaluates the cosine of the angle between two embeddings. "cosine similarity"
- Cross-encoder: A model that jointly encodes a query and a candidate to produce a direct relevance score. "cross-encoder model"
- DPO (Direct Preference Optimization): An approach to train models from preference data via a direct optimization objective. "DPO"
- Dynamic re-ranking: Reordering candidates on the fly using updated signals to better balance efficiency and coverage. "dynamic re-ranking module"
- Dynamic Weighting Reward GRPO (DW-GRPO): An RL method that adaptively adjusts reward weights during policy optimization to balance multiple objectives. "Dynamic Weighting Reward GRPO (DW-GRPO)"
- EM: Exact Match; a QA metric that counts predictions matching the ground-truth answer string exactly. "Best total EM in bold."
- Entity Resolution: The process of identifying and merging nodes that refer to the same real-world entity. "Entity Resolution"
- Entity-interaction analysis: Analysis of relationships among entities to assess and prioritize relevant subgraphs. "entity-interaction analysis"
- Entity-level search: Fine-grained retrieval over individual entity nodes within selected communities. "Entity-level Search"
- Exploration–exploitation tradeoff: The balance between exploring new parts of the graph and exploiting known promising areas. "exploration-exploitation tradeoff"
- Faithfulness: The degree to which generated or distilled content remains semantically consistent with the source knowledge. "Faithfulness"
- Global-to-local retrieval: A strategy that retrieves information from coarse global structures down to fine local details. "hierarchical global-to-local retrieval"
- GraphRAG: Retrieval-Augmented Generation that leverages knowledge graphs to support structured reasoning and retrieval. "GraphRAG"
- GRPO (Group Relative Policy Optimization): A policy optimization algorithm that uses group-relative baselines for reward shaping in RL. "GRPO"
- Hallucination: The generation of plausible-sounding but unsupported or false content by LLMs. "hallucination"
- Inter-community filtering: A top-level filtering step that prunes the search space by selecting relevant communities. "Inter-community filtering"
- Knowledge cutoff: The temporal limit after which a model has not been trained on new data. "knowledge cutoff"
- Knowledge graph: A structured representation of entities and relations extracted from text. "Knowledge Graph"
- Knowledge Integration Module: The component that synthesizes retrieved knowledge into a coherent context for downstream generation. "Knowledge Integration Module"
- Map-Reduce: A distributed summarization/aggregation paradigm consisting of mapping and reducing phases. "Map-Reduce"
- Mean pooling: An aggregation method that averages embeddings to form a composite representation. "mean pooling"
- Multi-hop reasoning: Reasoning that requires chaining multiple facts across entities or documents. "multi-hop reasoning"
- Multi-stage re-ranking: Applying re-ranking at several stages of retrieval to progressively refine candidate sets. "multi-stage re-ranking"
- PPO (Proximal Policy Optimization): An RL algorithm that stabilizes training by limiting the size of policy updates. "PPO"
- Reinforcement Learning (RL): A learning paradigm where agents optimize behavior via reward feedback. "Reinforcement Learning (RL)"
- Seesaw effect: A phenomenon in multi-objective training where improving one objective degrades others. "the seesaw effect"
- Softmax temperature: A scaling factor that controls the sharpness of probabilities produced by softmax. "softmax function with temperature T"
- Topological consistency: Preservation of structural integrity and connectivity properties of the graph. "topological consistency"
- TRPO (Trust Region Policy Optimization): An RL algorithm that uses trust regions to ensure stable policy improvement. "TRPO"
- Weighted Louvain algorithm: A community detection algorithm that optimizes modularity on weighted graphs. "weighted Louvain algorithm"
Collections
Sign up for free to add this paper to one or more collections.