Autonomous Knowledge Graph Exploration with Adaptive Breadth-Depth Retrieval
Abstract: Retrieving evidence for LLM queries from knowledge graphs requires balancing broad search across the graph with multi-hop traversal to follow relational links. Similarity-based retrievers provide coverage but remain shallow, whereas traversal-based methods rely on selecting seed nodes to start exploration, which can fail when queries span multiple entities and relations. We introduce ARK: Adaptive Retriever of Knowledge, an agentic KG retriever that gives a LLM control over this breadth-depth tradeoff using a two-operation toolset: global lexical search over node descriptors and one-hop neighborhood exploration that composes into multi-hop traversal. ARK alternates between breadth-oriented discovery and depth-oriented expansion without depending on a fragile seed selection, a pre-set hop depth, or requiring retrieval training. ARK adapts tool use to queries, using global search for language-heavy queries and neighborhood exploration for relation-heavy queries. On STaRK, ARK reaches 59.1% average Hit@1 and 67.4 average MRR, improving average Hit@1 by up to 31.4% and average MRR by up to 28.0% over retrieval-based and agentic training-free methods. Finally, we distill ARK's tool-use trajectories from a large teacher into an 8B model via label-free imitation, improving Hit@1 by +7.0, +26.6, and +13.5 absolute points over the base 8B model on AMAZON, MAG, and PRIME datasets, respectively, while retaining up to 98.5% of the teacher's Hit@1 rate.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Autonomous Knowledge Graph Exploration with Adaptive Breadth-Depth Retrieval”
1) What is this paper about?
This paper is about teaching an AI to look up facts in a huge map of knowledge, called a knowledge graph. A knowledge graph is like a big web of “things” (products, people, papers, diseases, drugs) connected by “relationships” (wrote, treats, is similar to, belongs to). The challenge is to find the right pieces of this web quickly and accurately when someone asks a question.
The authors introduce ARK (Adaptive Retriever of Knowledge), an AI helper that smartly switches between two ways of searching:
- Looking broadly across the whole graph for anything textually related to the question.
- Diving deeper along the links between related items when relationships matter.
2) What were they trying to find out?
The team wanted to answer simple questions in everyday terms:
- Can an AI decide when to search broadly (by text) and when to follow connections (relationships) to find the best evidence?
- Can it do this without special training for each new graph or topic?
- Can we keep it fast and affordable, and even teach a smaller, cheaper AI to do the same thing by showing it examples?
3) How did they do it?
Think of a knowledge graph as a city map:
- Places (nodes) are buildings (like “a product,” “a scientist,” or “a disease”).
- Roads (edges) are the relationships (like “wrote,” “is made by,” “treats”).
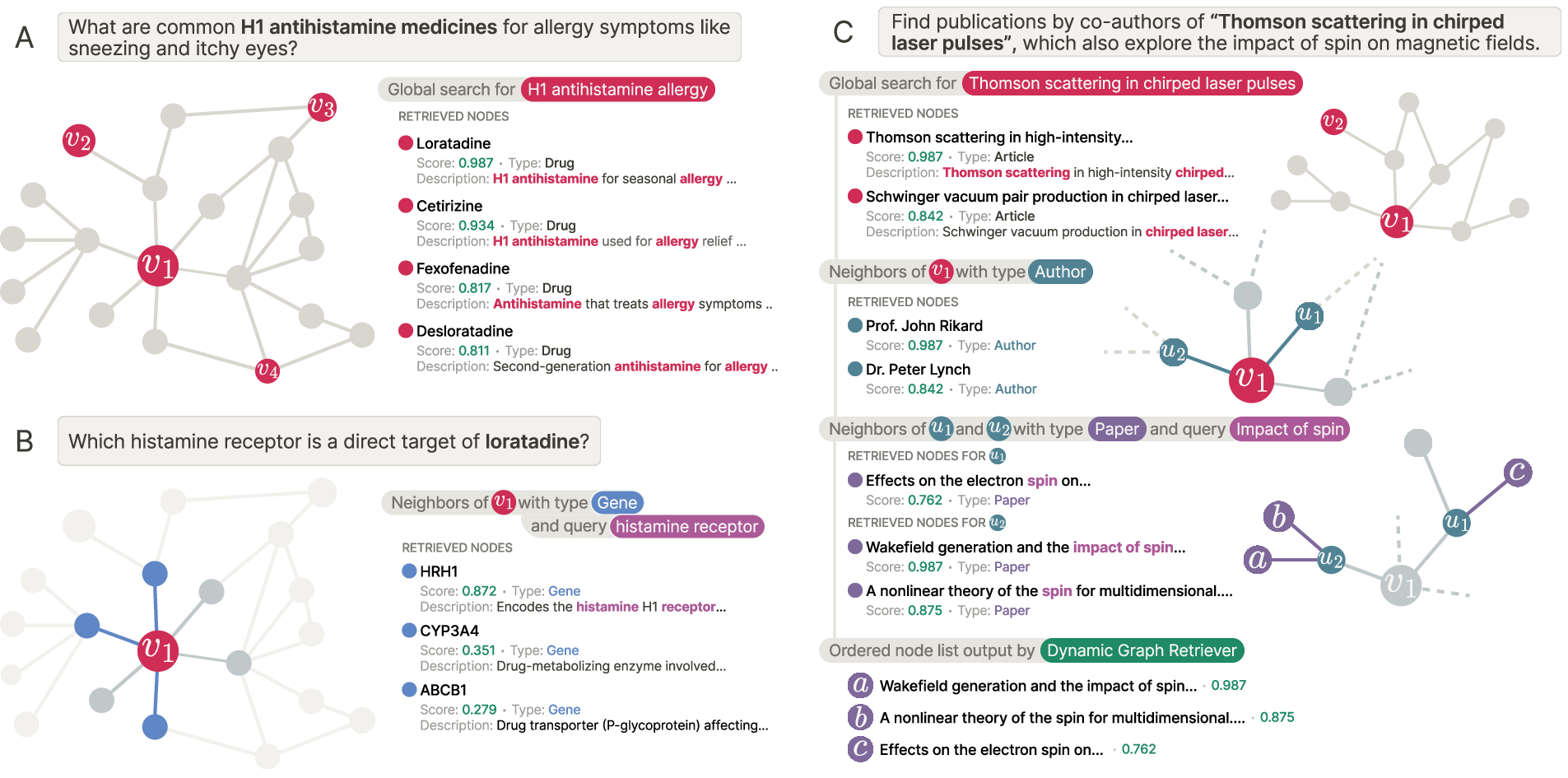
ARK gives a LLM just two simple “tools,” like two buttons on a remote:
- Global Search (breadth)
- Like using a city-wide search to find all buildings whose descriptions match your keywords.
- Useful when your question is mostly about matching text (for example, “Find a product with feature X” or “Which paper mentions Y?”).
- Neighborhood Exploration (depth)
- Like standing at one building and checking the buildings directly connected to it by specific roads.
- You can filter by the types of buildings and roads (for example, “from this author, show me their papers”), and you can rank nearby buildings by how well their text matches your sub-question.
- By taking one “hop” at a time and repeating, ARK can do multi-hop searches (like author → coauthor → coauthor’s papers) when needed.
A few extra touches:
- ARK can run several copies in parallel (like asking a few friends to search independently) and then combine their picks, which makes results more reliable.
- The scoring of text matches uses a standard keyword method (BM25), which is fast and stable.
- Distillation: The team had a larger “teacher” AI show its step-by-step tool use on many questions. Then a smaller “student” AI learned to copy those steps (no answer labels needed), making the system cheaper and faster to run.
4) What did they find, and why does it matter?
In tests across three big knowledge graphs:
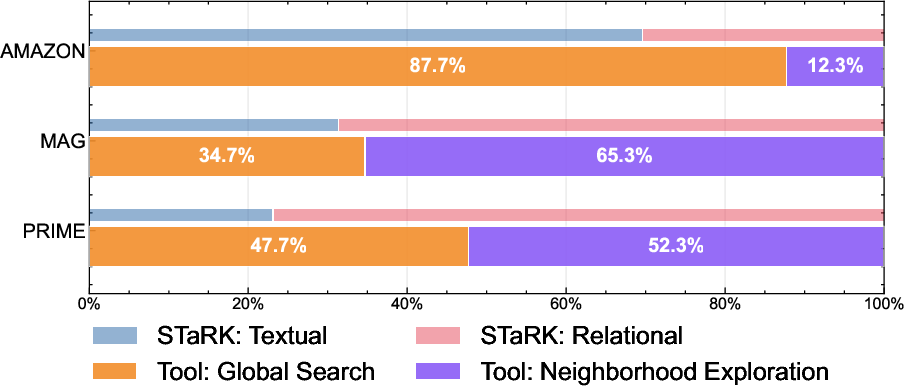
- AMAZON (shopping/products),
- MAG (scientific papers and authors),
- PRIME (biomedicine: diseases, drugs, genes),
ARK consistently found the right answers near the top better than other systems that don’t require special training.
Key takeaways:
- It adapts automatically. On text-heavy questions (like many in AMAZON), ARK mostly uses Global Search. On relationship-heavy questions (like many in MAG and PRIME), it switches to Neighborhood Exploration to follow connections. In short, it “uses the right tool for the job.”
- It beats strong baselines. ARK achieved top or near-top results without training on each graph, improving “right answer in first place” rates by large margins over many training-free methods.
- The two-tool design matters. Removing Neighborhood Exploration hurt performance on connection-heavy tasks; removing type filters or within-neighborhood ranking also made results worse. This shows that carefully exploring the local neighborhood is crucial.
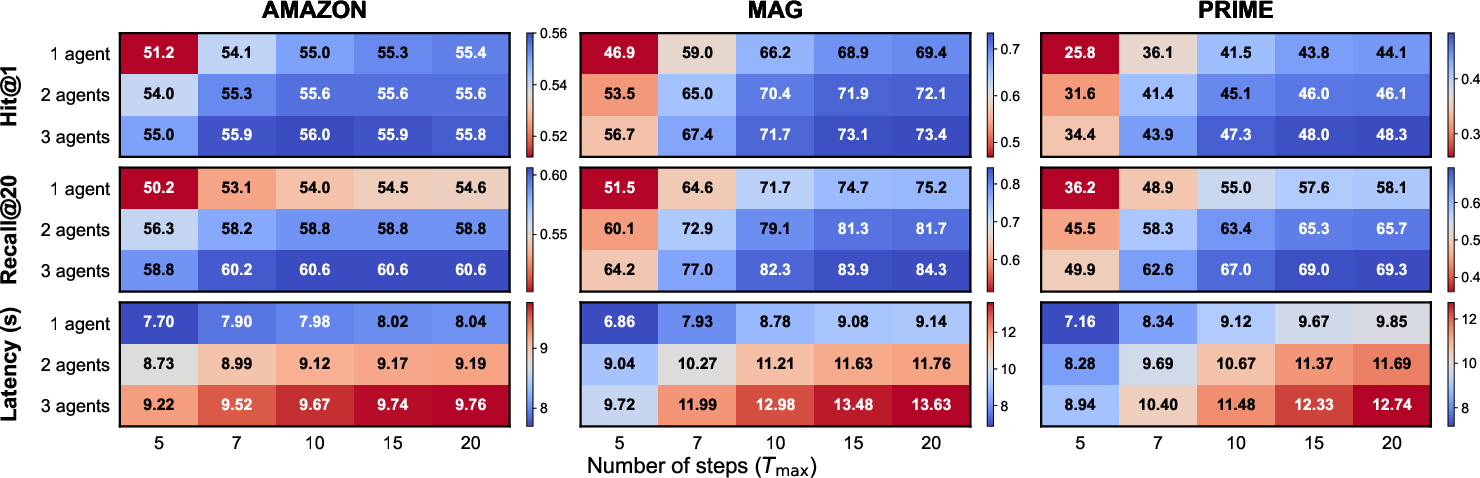
- More compute helps (with a trade-off). Letting ARK take more steps or run multiple agents improves accuracy but increases time. Even just going from one agent to two gave a nice boost with little extra delay.
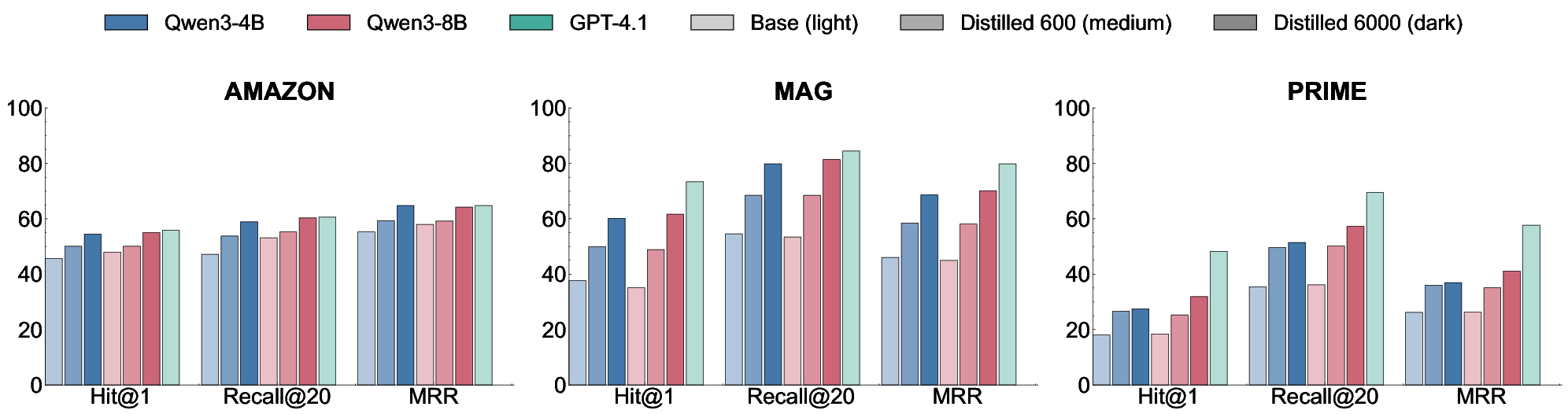
- Distillation works well. A smaller model, taught by watching the larger model’s search steps, kept up to about 98.5% of the big model’s top-1 accuracy and strongly improved over the small model’s original performance—without needing labeled answers.
Why this matters: It shows a simple, practical way to mix “broad keyword search” with “follow-the-links reasoning,” which is exactly what many real questions need.
5) What’s the impact?
This research suggests a clearer, more flexible path for AI systems that need to find trustworthy evidence:
- Practical: Two simple tools are enough to handle many kinds of questions across different domains without custom training.
- Controllable: You can decide how much speed vs. depth you want by adjusting how many steps or parallel agents to use.
- Affordable: You can train a smaller model to behave like the big one by copying its tool-using steps, cutting costs while keeping most of the quality.
Things to keep in mind:
- More steps and bigger models mean more time and cost; there’s a trade-off.
- If the graph’s text is sparse or uses unusual wording, keyword search may miss things.
- As with any system searching real-world data, we should watch for privacy and bias.
Overall, ARK shows that an AI can learn when to scan widely and when to dig deeper in a knowledge graph—much like a good researcher—using just a couple of well-chosen tools.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies concrete gaps and unanswered questions left by the paper that future work could address:
- Transfer to low-text or sparse-text KGs: Evaluate ARK on graphs with minimal or templated node descriptors (e.g., industrial knowledge bases), and quantify degradation relative to text-rich STaRK.
- Multilingual and alias robustness: Test ARK under paraphrases, domain-specific aliases, abbreviations, and non-English queries; compare BM25 global search with dense or hybrid lexical–semantic search for alias resolution.
- Edge directionality and path semantics: Neighborhood exploration treats adjacency regardless of direction; assess the impact of enforcing edge direction and relation sequences (e.g., “authored_by → published_in”) on multi-hop retrieval quality.
- Path-aware scoring: Incorporate and compare learned path scoring or symbolic constraints (relation-type sequences, path lengths) versus current BM25-only neighbor ranking.
- Adaptive budgets and termination: Replace fixed k and T_max with learned or query-adaptive controls for neighbor budget, hop depth, and stopping criteria; measure latency–quality trade-offs and failure recovery.
- Compute allocation policies: Develop cost-aware planning to decide per-query whether to deepen a single agent or run multiple agents; formalize compute–performance optimization beyond simple parallel ensembling.
- Parallel agent fusion: Compare rank fusion strategies (e.g., reciprocal rank fusion, learned aggregators) and study cross-agent communication or consensus to reduce conflicting selections and duplicates.
- Recovery from wrong anchors: Analyze whether and how ARK can detect and recover when initial global search anchors are off-target; add explicit re-anchoring or backtracking tools.
- Toolset minimality vs. extensibility: Test whether adding tools (e.g., relation-constrained global search, path-finder, SPARQL-like filters) improves performance without significantly increasing complexity.
- Type-filter selection robustness: Quantify errors from incorrect node/relation type constraints and explore automatic type inference or learning type-selection policies.
- Loop and redundancy control: Introduce visited-node tracking, cycle detection, and redundancy penalties; measure effects on efficiency and retrieval accuracy in high-degree regions.
- Context-length management: Investigate how large tool outputs are summarized or chunked for the LLM within the 16,384-token window; quantify context truncation effects and introduce adaptive summarization.
- Structured (non-text) attributes: Extend retrieval to numeric, categorical, and symbolic fields; compare hybrid scoring that respects non-text signals alongside text descriptors.
- Edge weighting and uncertainty: Evaluate using edge weights/confidence scores and uncertainty-aware exploration (e.g., probabilistic KGs) to prioritize reliable paths.
- Scalability to billion-scale KGs: Benchmark indexing time, memory footprint, latency, and throughput for global search and neighborhood expansion under distributed settings; explore caching and sharding strategies.
- Generalization beyond STaRK: Validate on real-world KGs (e.g., Wikidata, DBpedia, enterprise KGs), with noisy/incomplete edges, temporal dynamics, and streaming updates; measure robustness to KG drift.
- End-to-end downstream impact: Connect ARK retrieval to generation (RAG) and KG-grounded QA; quantify improvements in faithfulness, answer quality, and error propagation relative to retrieval-only metrics.
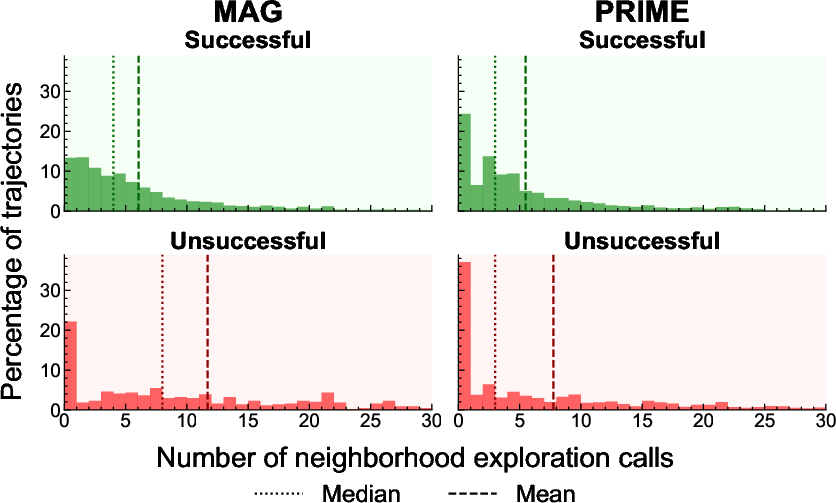
- Failure-mode taxonomy: Go beyond neighborhood-call distributions to systematically categorize failures (anchoring errors, drift, over-expansion, type misselection, alias mismatch) and design targeted mitigations.
- Hybrid global search: Compare BM25 vs. dense embedding retrievers (e.g., GTR, E5) or trainable hybrid scoring under the same ARK framework; analyze per-query regime switching.
- Distillation quality controls: Study trajectory filtering (e.g., removing low-quality or redundant steps), counterfactual negatives, and multi-teacher ensembles; measure sensitivity to teacher choice and student capacity.
- Cross-graph transfer: Train students on trajectories from one graph and test on another to assess schema transfer; develop schema-conditioned prompts or adapters to improve zero-shot transfer.
- OOD and adversarial queries: Stress-test ARK with unanswerable, adversarial, or highly compositional queries; add detection and graceful failure mechanisms.
- Fairness and coverage audits: Measure retrieval disparities across entity types, communities, and languages; develop debiasing for lexical/global search and neighbor ranking.
- Privacy-preserving retrieval: Prototype and evaluate redaction policies, differential privacy, and sensitive-field filters during tool execution; quantify utility–privacy trade-offs.
- Budget sensitivity analyses: Systematically vary k (neighbors), k (global search), T_max, and agent count; build guidelines for budget selection per dataset regime.
- Termination decision learning: Train or tune termination policies explicitly to avoid over-expansion and early stopping; compare to heuristic stopping and analyze effects on latency and accuracy.
- Duplicate and multi-target handling: Improve ranking when multiple relevant nodes exist; evaluate aggregation strategies for diverse evidence and resolve entity duplication across trajectories.
- Explainability of paths: Generate and evaluate user-facing explanations that trace KG paths for retrieved evidence; measure alignment between traces and actual graph semantics.
- Reproducibility with open models: Replace proprietary teachers (GPT-4.1) with strong open LLMs; document sensitivity to LLM choice and ensure replicable baselines.
- Impact of index construction choices: Analyze how tokenization, field weighting, stemming, and stopwords in BM25 affect ARK; provide best practices or auto-tuning for different KG schemas.
Practical Applications
Immediate Applications
Below are practical applications that can be deployed now using the paper’s ARK framework and its distilled variants.
- Enterprise knowledge search and Graph-RAG for internal knowledge bases (Software/Enterprise IT)
- Tools/Workflows: ARK-as-a-service API over existing enterprise knowledge graphs; inverted index of node descriptors; typed neighbor filters; multi-agent rank fusion; UI that shows “evidence paths” recovered via multi-hop exploration.
- Assumptions/Dependencies: Text-rich node metadata (titles, descriptions) and typed relations; access control and redaction for sensitive fields; BM25 vocabulary alignment with enterprise jargon; availability of a capable LLM or distilled model (e.g., Qwen3-8B).
- E-commerce product support and recommendation justification (Retail/E-commerce)
- Tools/Workflows: Customer support assistants that combine global search for product Q&A with neighborhood expansion to retrieve compatibility, accessory, and warranty relations; a “budget knob” to meet latency SLAs; evidence-path explanations for recommendations.
- Assumptions/Dependencies: Curated product KGs (catalog, Q&A, reviews) with descriptive text; consistent entity IDs and relation types; content moderation and privacy controls for user-generated text.
- Scholarly discovery and research navigation (Academia/Education)
- Tools/Workflows: Research search portals (MAG-like) that use ARK to answer multi-hop queries (e.g., “papers by co-authors of X on topic Y”); collaborator-finder; citation chasing with ranked evidence; path visualization for reproducible literature trails.
- Assumptions/Dependencies: Up-to-date scholarly KG with well-typed entities and relations; robust indexing of titles/abstracts; handling of synonyms and abbreviations via query expansion or lexicon mapping.
- Biomedical evidence retrieval and safety signal triage (Healthcare/Pharma)
- Tools/Workflows: Drug–gene–disease evidence lookup (PrimeKG-like) for pharmacovigilance triage; adverse event signal exploration using typed, query-ranked neighbors; on-prem deployment with distilled ARK for cost/privacy.
- Assumptions/Dependencies: High-quality biomedical KG with text attributes; domain terminology harmonization (ontologies, aliases); non-diagnostic usage with clinical disclaimers; governance for patient privacy.
- Regulatory and compliance research (Policy/Legal/Finance)
- Tools/Workflows: Regulatory knowledge portals that retrieve obligations and exceptions via multi-hop relations across statutes, guidance, and case law; relational filters by jurisdiction, sector, or obligation type.
- Assumptions/Dependencies: Structured regulation KGs with text-rich nodes (sections, clauses) and typed edges (amends, references, applies-to); updated indexes; careful interpretation of retrieved evidence (legal review).
- Data lineage and catalog search (Software/Data)
- Tools/Workflows: Multi-hop lineage retrieval across datasets, pipelines, and owners; query-ranked neighbor exploration to surface upstream/downstream dependencies; ranked lists for impact analysis.
- Assumptions/Dependencies: Accurate lineage KG with textual metadata; standardized entity naming; integration with data catalogs; access controls.
- Dependency and vulnerability triage (Software/Security)
- Tools/Workflows: Security assistants that traverse package and CVE graphs to find exploitable paths (component → version → CVE → fix); evidence path export for remediation tickets.
- Assumptions/Dependencies: Timely dependency/CVE KGs; consistent identifiers; adequate textual descriptors (advisories, release notes).
- Customer support triage and routing (Industry)
- Tools/Workflows: Ticket classification via global search and relation-aware expansion to map issues to products, known bugs, or KB articles; parallel agent voting to increase robustness.
- Assumptions/Dependencies: Support KG linking tickets, products, and resolutions; text normalization; privacy-compliant handling of customer data.
- Personal knowledge graph search and note retrieval (Daily life/Productivity)
- Tools/Workflows: Local note-taking app plugin that indexes notes as a KG and uses distilled ARK for on-device retrieval; evidence-path view to show “how concepts connect” across notes.
- Assumptions/Dependencies: Automatic note-to-KG extraction (entities, relations); sufficient text on nodes; user consent and local storage constraints.
- Asset management and incident analysis in utilities (Energy)
- Tools/Workflows: Asset KGs for equipment, incidents, and maintenance records; ARK to retrieve multi-hop causal chains (asset → incident → mitigation → outcome) and support incident investigations.
- Assumptions/Dependencies: Text-rich asset and incident metadata; normalized relation types (causes, mitigations); appropriate latency budgets for field use.
- Compute-aware retrieval operations (Cross-sector)
- Tools/Workflows: Use ARK’s budget-performance knobs (trajectory length, number of parallel agents) to meet service-level latency targets while maintaining retrieval quality; rank fusion for stability.
- Assumptions/Dependencies: Monitoring and autoscaling; alignment of budgets with query complexity (textual vs relational); selection of backbone LLM or distilled variant based on cost/latency.
Long-Term Applications
These applications are feasible with further research, scaling, validation, or productization beyond the current ARK capabilities.
- Clinical decision support integrated with EHR graphs (Healthcare)
- Tools/Workflows: Multi-hop retrieval across EHR KGs (labs → diagnoses → medications → guidelines); provenance-preserving evidence paths for clinician review; domain-specific distillation.
- Assumptions/Dependencies: Rigorous clinical validation, regulatory approval, bias audits, and privacy; harmonized clinical ontologies; extremely high precision/recall requirements; robust synonym/alias handling beyond BM25.
- AML and fraud detection on transaction networks (Finance)
- Tools/Workflows: Multi-hop exploration of entity-to-transaction graphs to surface suspicious patterns; hybrid lexical/relational ranking with sector-specific features; risk scoring pipelines.
- Assumptions/Dependencies: Access to large, evolving financial graph data; explainability, fairness, and compliance mandates; enhanced retrieval beyond lexical matching (dense embeddings, aliases).
- Dynamic supply chain intelligence and risk propagation (Manufacturing/Logistics)
- Tools/Workflows: Global search plus typed expansion over supplier–component–facility KGs to identify impacts from disruptions; ensemble retrieval under strict latency budgets; “what-if” exploration tools.
- Assumptions/Dependencies: Continuously updated, multi-lingual KGs; mapping across disparate identifiers; privacy and contractual constraints; robust alias resolution.
- Autonomous systematic review agents and evidence synthesis (Academia/Pharma)
- Tools/Workflows: Agentic workflows combining ARK retrieval with planning/summarization to assemble evidence; multi-hop path auditing; human-in-the-loop verification; trajectory distillation for domain students.
- Assumptions/Dependencies: High-quality domain KGs; standardized evaluation of coverage and bias; scalable trajectory generation; rigorous reproducibility controls.
- Adaptive tutoring and curriculum planning via concept graphs (Education)
- Tools/Workflows: Multi-hop retrieval over concept/prerequisite KGs to design personalized learning paths; evidence-path explanations; integration with assessment data.
- Assumptions/Dependencies: Accurate pedagogical KGs; alignment to curricula; student privacy; domain-specific query expansion (synonyms, misconceptions).
- Policy impact modeling across interlinked civic KGs (Government/Policy)
- Tools/Workflows: Cross-graph retrieval linking regulations to outcomes (health, environment, economics); typed traversal across datasets; evidence provenance for policy analysis.
- Assumptions/Dependencies: Standardized, interoperable civic KGs; bias and equity audits; data-sharing agreements; strong causal reasoning beyond retrieval.
- Robotics task planning over skill/tool KGs (Robotics)
- Tools/Workflows: Retrieval of multi-step procedures from skill graphs (goal → subtasks → tools → constraints); integration with planners and controllers; path verification.
- Assumptions/Dependencies: Rich procedural KGs with well-typed relations; bridging from retrieved plans to executable actions; safety certification.
- Privacy-preserving, on-device graph retrieval at scale (Cross-sector)
- Tools/Workflows: Trajectory distillation pipelines to produce small, domain-tuned students for edge devices; local indexing; federated update mechanisms.
- Assumptions/Dependencies: Sufficient device compute; secure local storage; privacy-by-design; efficient trajectory generation with strong teachers.
- KG curation and quality assurance guided by retrieval trajectories (Data/Knowledge Engineering)
- Tools/Workflows: “Retrieval path auditor” that flags missing relations, inconsistent types, or sparse descriptors discovered via ARK trajectories; semi-automated curation workflows.
- Assumptions/Dependencies: SME review loops; graph editing tools; versioning/provenance; feedback incorporation at scale.
- Standard ARK connectors for graph databases and platforms (Software/Data)
- Tools/Workflows: Native integrations with Neo4j, TigerGraph, AWS Neptune, and graph-aware search stacks; shared schema/type mapping; operationalized rank-fusion ensembles.
- Assumptions/Dependencies: Vendor collaboration; schema normalization; performance tuning across heterogeneous deployments; observability and governance.
- Hybrid retrieval (lexical + dense + learned policies) for sparse-text graphs (Cross-sector)
- Tools/Workflows: Augment ARK with dense embeddings, alias dictionaries, and learned traversal policies to handle limited text or high paraphrase variance.
- Assumptions/Dependencies: Additional training/data for embeddings/policies; domain lexicons; maintenance of hybrid indices; evaluation of trade-offs in latency and accuracy.
Glossary
- Adaptive Retriever of Knowledge (ARK): An adaptive agent-based framework for knowledge graph retrieval that alternates between global search and neighborhood exploration to balance breadth and depth. "We introduce ARK: Adaptive Retriever of Knowledge, an agentic KG retriever that gives a LLM control over this breadth-depth tradeoff using a two-operation toolset: global lexical search over node descriptors and one-hop neighborhood exploration that composes into multi-hop traversal."
- Agentic KG retriever: A retriever framed as an interactive agent that makes sequential tool-use decisions to gather evidence from a knowledge graph. "We introduce ARK: Adaptive Retriever of Knowledge, an agentic KG retriever that gives a LLM control over this breadth-depth tradeoff..."
- AvaTaR: A tool-using LLM agent that optimizes prompts using feedback from successful and unsuccessful trajectories. "AvaTaR \cite{wu_avatar_2024} is a tool-using agent that optimizes prompting from positive and negative trajectories."
- BM25: A probabilistic lexical ranking function widely used in information retrieval to score document relevance. "We implement $\rel$ with BM25 \cite{robertson_probabilistic_2009} over an inverted index of node textual attributes \cite{manning_introduction_2008}, yielding fast and stable scoring for the many short, evolving subqueries issued during exploration."
- Breadth-depth tradeoff: The balance between performing broad global search and deep relational traversal in retrieval. "an agentic KG retriever that gives a LLM control over this breadth-depth tradeoff using a two-operation toolset"
- CoRAG: A cooperative hybrid retrieval approach that preserves global semantic access beyond local neighborhoods. "CoRAG highlights cooperative hybrid retrieval that preserves global semantic access beyond local neighborhoods \cite{zheng_corag_2025}."
- GFlowNets: Generative Flow Networks used to learn policies that sample diverse high-reward trajectories in structured spaces. "GraphFlow \cite{yu_can_2025} learns a policy for generating multi-hop retrieval trajectories using GFlowNets \cite{bengio_flow_2021}."
- Global search: A tool that retrieves the top-k nodes across the entire graph by lexical relevance to a subquery. "Global search retrieves the highest-scoring nodes in the graph under $\rel$ for an agent-issued subquery "
- GraphFlow: An agent that learns multi-hop retrieval trajectories on knowledge graphs using GFlowNets. "GraphFlow \cite{yu_can_2025} learns a policy for generating multi-hop retrieval trajectories using GFlowNets \cite{bengio_flow_2021}."
- GraphRAG: A graph-based variant of retrieval-augmented generation that performs local-to-global retrieval over an entity-centric graph. "GraphRAG performs local-to-global retrieval over an entity-centric graph \cite{edge_local_2025},"
- Hit@1: A top-rank precision metric indicating whether the correct item appears at rank 1. "We follow the STaRK protocol and report Hit@1, Hit@5, Recall@20 (R@20), and Mean Reciprocal Rank (MRR)"
- Hit@5: A metric indicating whether the correct item appears within the top 5 results. "We follow the STaRK protocol and report Hit@1, Hit@5, Recall@20 (R@20), and Mean Reciprocal Rank (MRR)"
- HybGRAG: A hybrid graph–text retrieval method that mixes graph and text channels with iterative refinement. "GraphSearch and HybGRAG \cite{yang_graphsearch_2025,lee_hybgrag_2025};"
- Inverted index: A data structure mapping terms to the nodes/documents containing them for fast lexical retrieval. "over an inverted index of node textual attributes"
- KAR: A knowledge-aware retriever that augments queries and applies relation-type constraints during retrieval. "KAR grounds query expansion in KG structure \cite{xia_knowledge-aware_2025},"
- Knowledge graph (KG): A graph-based representation of entities and typed relations, often with text-rich node attributes. "Knowledge graphs (KGs) are a natural data representation for this setting because they organize evidence around entities and typed edges, support reuse across queries, and enforce relational constraints that a flat text index cannot express."
- Label-free imitation: Distillation that trains a student model from teacher interaction trajectories without ground-truth labels. "we distill ARK's tool-use policy into an 8B model via label-free imitation"
- LoRA adapters: Low-Rank Adaptation modules for parameter-efficient fine-tuning of LLMs. "We then distill a Qwen3-8B \cite{yang_qwen3_2025} student via supervised fine-tuning with LoRA adapters \cite{hu_lora_2021},"
- Mean Reciprocal Rank (MRR): A ranking metric that averages the inverse rank of the first correct answer across queries. "We follow the STaRK protocol and report Hit@1, Hit@5, Recall@20 (R@20), and Mean Reciprocal Rank (MRR)"
- mFAR: A multi-field adaptive retriever combining keyword matching and embedding similarity with learned query-dependent weights. "mFAR~\cite{li_multi-field_2025} is a multi-field adaptive retriever that combines keyword matching with embedding similarity to learn query-dependent weights over different node fields."
- MoR: A trained retriever that fuses multiple retrieval objectives to rank candidates. "MoR~\cite{lei_mixture_2025} is a trained retriever that combines multiple retrieval objectives."
- Multi-hop traversal: Following sequences of relations across a graph to locate evidence that is not accessible via single-hop expansion. "one-hop neighborhood exploration that composes into multi-hop traversal."
- Neighborhood exploration: A tool that filters one-hop neighbors by type constraints and optionally ranks them by a subquery for targeted expansion. "Neighborhood exploration returns adjacent nodes of a node filtered by optional node and edge type constraints selected by the agent as tool parameters, and optionally ranked using an agent-generated subquery "
- Parallel exploration: Running multiple agent instances concurrently and aggregating their retrieval lists to improve robustness. "We increase robustness by running independent instances of the same agent in parallel and aggregating their retrieved lists,"
- Rank fusion: A method for combining multiple ranked lists into a single consensus ranking, often based on vote counts or positions. "We then combine these lists using a simple rank-fusion rule inspired by classical rank aggregation and data fusion methods \cite{fagin_efficient_2003,cormack_reciprocal_2009}."
- ReAct: A tool-use prompting framework that interleaves reasoning and acting for LLM agents. "tool-use frameworks such as ReAct \cite{yao_react_2023}"
- Recall@20 (R@20): A coverage metric measuring the fraction of relevant items retrieved within the top 20 ranks. "We follow the STaRK protocol and report Hit@1, Hit@5, Recall@20 (R@20), and Mean Reciprocal Rank (MRR)"
- Retrieval-augmented generation (RAG): A paradigm that grounds LLM outputs in external evidence by retrieving relevant context. "Retrieval-augmented generation (RAG) grounds LLM outputs in external evidence by retrieving relevant context from a corpus or index \cite{lewis_retrieval-augmented_2020,guu_realm_2020}."
- Seed entities: Initial nodes selected to start traversal; poor seed choice can cause local anchoring and missed evidence. "depend on identifying a small set of seed entities from which exploration begins~\cite{markowitz_tree--traversals_2024,sun_think--graph_2024}."
- Self-consistency: An ensembling technique that aggregates multiple independent reasoning trajectories from LLMs. "akin to self-consistency and voting-based ensembling in LLM reasoning \cite{wang_self-consistency_2023,kaesberg_voting_2025}."
- Semi-structured knowledge base (SKB): A data store mixing text and explicit relations for retrieval and reasoning. "systems and memory modules that operate over semi-structured knowledge bases (SKB) that mix text with relational information"
- STaRK: A benchmark for entity-level retrieval over heterogeneous, text-rich knowledge graphs. "We measure retrieval performance on STaRK, a benchmark for entity-level retrieval over heterogeneous, text-rich KGs \cite{wu_stark_2024}."
- Teacher–student paradigm: A distillation setup where a student model imitates a stronger teacher’s tool-use trajectories via supervised fine-tuning. "We adopt a standard teacher--student paradigm in which a student model imitates the tool-usage trajectories of a stronger teacher LLM via supervised fine-tuning \cite{schick_toolformer_2023}."
- Type-based filtering: Restricting neighborhood expansions by node and relation types during exploration. "and w/o disables type-based filtering."
Collections
Sign up for free to add this paper to one or more collections.