- The paper demonstrates that chain-of-thought prompts degrade spatial reasoning, with a 3% average accuracy drop across evaluated multimodal models.
- It shows that even specialized MRMs rely on text-based priors, often resulting in visual hallucinations and incorrect spatial inferences.
- The findings advocate for vision-centric retraining and evaluation frameworks to ensure robust, embodied spatial reasoning in future models.
Chain-of-Thought Decreases Visual Spatial Reasoning in Multimodal LLMs
Introduction
Recent developments in Multimodal Reasoning Models (MRMs) and Chain-of-Thought (CoT) prompting have markedly advanced the state of open-ended mathematical and logical reasoning. However, the translation of these text-centric, step-wise reasoning strategies to vision-grounded spatial intelligence remains underexplored. "Chain-of-Thought Degrades Visual Spatial Reasoning Capabilities of Multimodal LLMs" (2604.16060) undertakes an extensive evaluation of contemporary MRMs and Multimodal LLMs (MLMs) across a suite of rigorous visual spatial benchmarks. The paper demonstrates that, contrary to the prevailing consensus in math and logic, CoT prompting consistently impairs spatial reasoning performance in both open-source and proprietary MRMs.
Experimental Setup
The analysis spans seventeen models—nine open-source MRMs built on Qwen2.5-VL-7B, and additional MLMs (Qwen, LLaVA, InternVL) plus proprietary models (GPT-4o, GPT-5), evaluated across thirteen spatial benchmarks. The selected datasets probe spatial relation, geometric generalization, and temporal and egocentric understanding, including CV-Bench (2D/3D), BLINK, MMVP, 3DSRBench, MindCube, OmniSpatial, and others. The evaluation protocol employs both CoT and non-CoT prompting, with results measured using pass@1 accuracy on MCQ-formatted queries, with prompts and scoring strictly standardized for direct comparability.
Main Findings
Across the model and dataset spectrum, CoT prompting introduces a consistent reduction in accuracy on spatial reasoning benchmarks. On average, CoT prompts result in a 3% absolute drop across backbone MLMs. For specialized open-source MRMs, six of eight architectures perform better when CoT reasoning is omitted in favor of direct answer formats (Table: main results). This result is robust to model size, architecture, and even for models with explicit spatial perception tuning (e.g., Qwen3-VL-8B-Thinking).
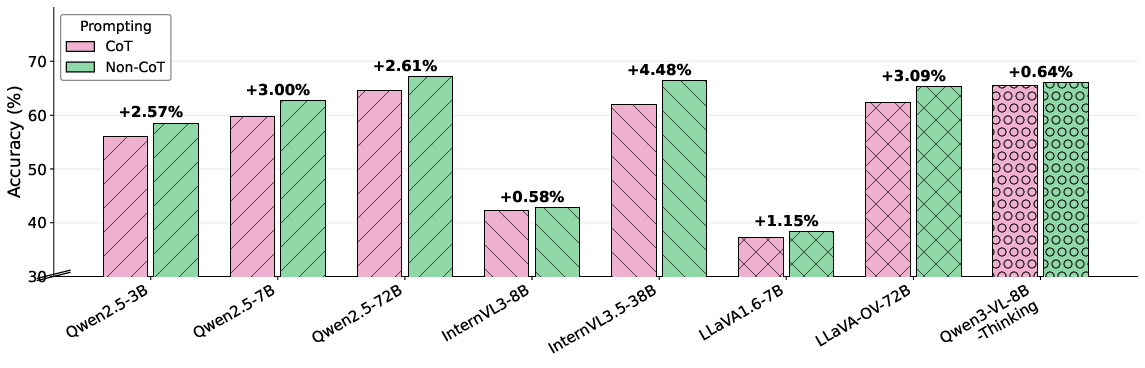
Figure 1: Comparison of CoT vs non-CoT prompting—CoT consistently underperforms on a wide spectrum of open-source MRMs and model scales across 13 spatial benchmarks.
Despite extensive post-training using SFT and RL on general-purpose reasoning datasets, most MRMs underperform their underlying Qwen2.5-VL-7B backbone on aggregate spatial scores. Notably, ViGoRL (-2.0%) and TreeVGR (-1.6%), both directly optimized for spatial reasoning, fail to outperform the base MLM. Among outliers, Vision-G1 marginally exceeds its backbone, but subsequent ablation reveals it does so largely due to leveraging dataset-specific textual priors rather than authentic visual grounding.
Severe Shortcut Learning and Visual Hallucination
A novel No-Image++ ablation reveals that MRMs, especially under CoT prompts, show a marked tendency to hallucinate visual details or spatial relations even when provided with a blank image and a "Cannot determine" answer option. Accuracies in this regime plummet, with detailed CoT traces confidently postulating absent visual facts strictly from world-knowledge priors embedded in the text, underscoring a critical limitation of text-oriented reasoning chains for vision tasks.
Proprietary Model Behavior
Benchmarks of proprietary models (GPT-4o, GPT-5 series) indicate that CoT reasoning does not confer consistent benefits on spatial benchmarks. For GPT-5 and GPT-5-nano, non-CoT prompting surpasses CoT by up to 1.23%. Interestingly, proprietary CoT traces are much more concise and less repetitive than their open-source counterparts, hinting at differing training strategies and reflecting that trace quality/moderation, not just presence, mediates success on spatial tasks.
Qualitative Analysis
Extensive qualitative analyses expose degenerate behavioral modes: GThinker, when deprived of its habitual CoT prompt, produces malformed outputs, while models like ViGoRL invent spatial coordinates and relationships for completely blank images rather than abstaining or selecting the appropriate "Cannot determine" option. These phenomena starkly illustrate the dominance of text-based priors and the absence of robust perception-grounded reasoning even in advanced MRMs.
Implications
The results constitute a strong negative finding for the vision-language reasoning community: prevailing pipelines for step-wise, reflection-centric reasoning, effective in math and logic, are insufficient—and often deleterious—for spatial intelligence. The widespread tendency for models to exploit dataset priors or hallucinate absent evidence signals that vision grounding and perceptual verification are not emergent from current CoT-based training. MRMs trained with extensive RL and SFT data only rarely surpass strong, non-reasoning backbones.
Practically, this calls for retraining paradigms and evaluation standards: process supervision must emphasize the verification of each reasoning step against actual visual input, not only textual self-consistency. Theoretically, these outcomes challenge the transferability of text-induced reasoning faculties to domains fundamentally requiring embodied or perceptually grounded inferences.
Future Directions
The paper proposes actionable research targets. Promising avenues include:
- Test-time Visual Verifiers: Integrating auxiliary models to cross-examine each reasoning step for visual plausibility, with mechanisms for backtracking upon visual inconsistency.
- Visually-Grounded Reward Modeling: Training with reward signals that explicitly privilege perception-anchored rationales over text-only traces.
- Data Curation and Prompting Schemes: Reducing shortcut opportunities and hallucination biases by curating datasets and prompts that decouple visual evidence from world-prior sufficiency.
Conclusion
This study provides unambiguous evidence that current CoT prompting and RL-based reasoning strategies systematically degrade spatial reasoning capability in MRMs. These findings stress the necessity for vision-centric training objectives and evaluation benchmarks that genuinely measure perceptual reasoning, not just linguistic pattern-matching. The implications extend to both practical deployment and future architecture design for spatial intelligence in multimodal systems.

