- The paper introduces a novel CoCoT framework that decomposes reasoning into perception, situation, and norm stages to better mirror human social cognition.
- It demonstrates significant improvements in intent disambiguation and safety filtering, with gains up to 14.1% over conventional prompting methods.
- The paper highlights how structured, interpretable reasoning can enhance models’ performance in complex, socially nuanced tasks.
Cognitive Chain-of-Thought: Structured Multimodal Reasoning about Social Situations
Introduction
The paper introduces Cognitive Chain-of-Thought (CoCoT), a prompting strategy for vision-LLMs (VLMs) that decomposes multimodal reasoning into three cognitively inspired stages: perception, situation, and norm. This approach is motivated by the limitations of standard Chain-of-Thought (CoT) prompting, which, while effective for symbolic and factual reasoning, often fails in tasks requiring the integration of perceptual input with abstract social and normative understanding. CoCoT is designed to scaffold VLM reasoning in a manner that more closely mirrors human cognitive processes, particularly in tasks involving ambiguous intent, social commonsense, and safety-critical judgments.
Motivation and Theoretical Foundations
Conventional CoT prompting is effective in domains where reasoning can be reduced to symbolic manipulation or stepwise logic, such as mathematics or structured question answering. However, in visually grounded social tasks, models must bridge low-level perception with high-level, context-dependent social norms. The paper draws on the 4E cognition framework—embodied, embedded, enactive, and extended cognition—to argue that human reasoning in social contexts is inherently structured and contextually grounded, not merely a sequence of symbolic operations.
CoCoT operationalizes this insight by explicitly structuring prompts into three stages:
- Perception: Grounding reasoning in directly observable visual evidence.
- Situation: Interpreting relationships and context among perceived elements.
- Norm: Inferring the most socially plausible or normatively appropriate interpretation.
This structure is intended to guide VLMs through a progression from concrete perception to abstract social judgment, thereby improving both interpretability and alignment with human reasoning.
Methodology: The CoCoT Prompting Framework
CoCoT is implemented as a lightweight prompting strategy that can be applied to existing VLMs without architectural modifications. For each input, the model is prompted to sequentially answer three sub-questions corresponding to the perception, situation, and norm stages. This decomposition is designed to elicit intermediate reasoning steps that are both interpretable and aligned with human cognitive processes.
The approach is evaluated on three multimodal benchmarks:
- VAGUE: Multimodal intent disambiguation, requiring models to resolve ambiguous utterances using visual context.
- M3CoT: Multi-domain multimodal reasoning, including social commonsense, temporal reasoning, and mathematics.
- VLGuard: Safety instruction following, assessing the model's ability to reject unsafe or harmful multimodal prompts.
Empirical Results
Intent Disambiguation (VAGUE)
CoCoT demonstrates substantial improvements over both direct prompting and standard CoT in the VAGUE benchmark, particularly in settings with limited or ambiguous visual context. For example, with only image captions as input, GPT-4o achieves a +8.0% accuracy gain over CoT and +7.3% over direct prompting. Gemini-1.5-Pro shows a +14.1% gain over direct prompting. These results indicate that CoCoT's structured reasoning stages enable more robust disambiguation of intent, even when perceptual grounding is weak.

Figure 1: Comparison of Chain-of-Thought (CoT) and Cognitive Chain-of-Thought (CoCoT) reasoning on the multimodal intent disambiguation task formulated in VAGUE.
Multimodal Commonsense and Social Reasoning (M3CoT)
On the M3CoT benchmark, CoCoT outperforms CoT and compositional CoT (CCoT) in social and temporal commonsense domains. While CoT remains competitive in structured domains like mathematics, it underperforms in tasks requiring multi-level contextual inference. CoCoT's full-stage prompting is particularly effective in social-science and social-commonsense sub-topics, where reasoning must integrate perceptual cues with situational and normative interpretation.

Figure 2: Comparison of CoCoT and CoT outputs on M3CoT (Commonsense, Social-Commonsense), with human-annotated rationale.
Ablation studies reveal that even perception-only CoCoT can outperform CoT in visually salient tasks, but full-stage CoCoT is necessary for complex, context-dependent reasoning.
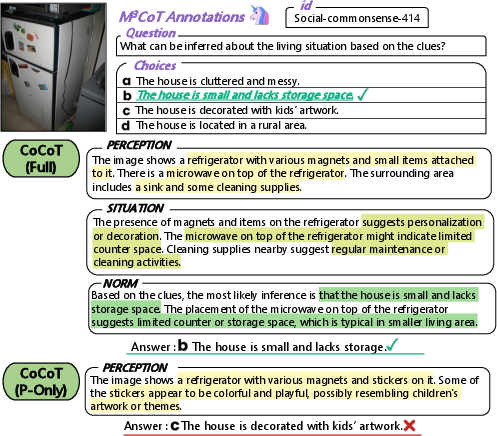
Figure 3: Comparison of Full CoCoT Chain with Perception-Only variant on M3CoT (Commonsense, Social-Commonsense).
Safety-Critical Reasoning (VLGuard)
In safety-critical scenarios, CoCoT reduces the Attack Success Rate (ASR) on unsafe prompts to 14.9%, compared to 28.3% for standard CoT and 19.0% for Moral CoT. This demonstrates that structured, stage-wise reasoning enhances the model's ability to reject unsafe instructions, particularly when harmful intent is embedded in otherwise benign visual contexts.

Figure 4: Example from VLGuard showing how CoCoT prompting enables safer reasoning by integrating perception, situation, and norm.
Ablation experiments further show that omitting the situation stage leads to overly conservative behavior (high false rejection rate), while norm-only reasoning is insufficient for robust safety.
Qualitative Analysis
Qualitative examples across all benchmarks illustrate that CoCoT's structured reasoning chains are more aligned with human rationales and less prone to superficial or brittle inferences. In ambiguous intent disambiguation, CoCoT correctly grounds utterances in visual context and social intent, whereas CoT often defaults to generic priors. In commonsense reasoning, CoCoT integrates subtle perceptual cues with situational interpretation to arrive at temporally and socially coherent conclusions.
Limitations
Despite its advantages, CoCoT introduces several limitations:
- Epistemic Reliability: The external scaffolding of reasoning stages does not guarantee faithful internal reasoning, raising concerns about the reliability of model explanations.
- Computational Overhead: Structured prompts increase input length, potentially impacting latency and resource requirements in real-time applications.
- Fragility of Trust: Errors in early reasoning stages (perception or situation) can undermine user trust, even if the final judgment is correct.
- Domain Generality: CoCoT's effectiveness is primarily demonstrated in socially grounded tasks; its utility in symbolic or mathematical domains remains limited.
- Dependency on Perceptual Quality: Performance gains may be confounded by the quality of upstream visual encoders or captioning models.
Ethical Considerations
The modular design of CoCoT may amplify biases present in individual reasoning stages, such as stereotyped visual interpretations or culturally specific norms. Transparency is improved, but inconsistencies in intermediate reasoning can obscure the true basis of model decisions, affecting fairness and accountability. Mitigation strategies include uncertainty quantification, diverse training data, and human-in-the-loop oversight, especially in high-stakes applications.
Implications and Future Directions
CoCoT represents a significant step toward cognitively aligned multimodal reasoning in VLMs, with practical benefits for interpretability, social awareness, and safety. The explicit structuring of reasoning stages offers a flexible framework that can be tailored to task complexity and domain requirements. Future research should explore:
- Extending cognitively inspired prompting to other domains, including symbolic and mathematical reasoning.
- Integrating internal model mechanisms that reflect the external reasoning stages, improving epistemic reliability.
- Developing adaptive prompting strategies that dynamically adjust reasoning depth based on task demands.
- Systematic auditing and mitigation of biases at each reasoning stage.
Conclusion
Cognitive Chain-of-Thought (CoCoT) introduces a structured, cognitively motivated approach to multimodal reasoning in VLMs, decomposing inference into perception, situation, and norm stages. Empirical results demonstrate consistent improvements over standard CoT and direct prompting in intent disambiguation, social commonsense, and safety-critical tasks. While limitations remain regarding epistemic reliability, computational efficiency, and domain generality, CoCoT provides a promising foundation for more interpretable, socially aware, and robust multimodal AI systems.

