Scaling Spatial Intelligence with Multimodal Foundation Models
Abstract: Despite remarkable progress, multimodal foundation models still exhibit surprising deficiencies in spatial intelligence. In this work, we explore scaling up multimodal foundation models to cultivate spatial intelligence within the SenseNova-SI family, built upon established multimodal foundations including visual understanding models (i.e., Qwen3-VL and InternVL3) and unified understanding and generation models (i.e., Bagel). We take a principled approach to constructing high-performing and robust spatial intelligence by systematically curating SenseNova-SI-8M: eight million diverse data samples under a rigorous taxonomy of spatial capabilities. SenseNova-SI demonstrates unprecedented performance across a broad range of spatial intelligence benchmarks: 68.7% on VSI-Bench, 43.3% on MMSI, 85.6% on MindCube, 54.6% on ViewSpatial, and 50.1% on SITE, while maintaining strong general multimodal understanding (e.g., 84.9% on MMBench-En). More importantly, we analyze the impact of data scaling, discuss early signs of emergent generalization capabilities enabled by diverse data training, analyze the risk of overfitting and language shortcuts, present a preliminary study on spatial chain-of-thought reasoning, and validate the potential downstream application. SenseNova-SI is an ongoing project, and this report will be updated continuously. All newly trained multimodal foundation models are publicly released to facilitate further research in this direction.
First 10 authors:



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI systems to understand space better — not just flat pictures, but the real 3D world. The authors build and train a family of AI models called SenseNova-SI to improve “spatial intelligence,” which means knowing where things are, how big they are, how they relate to each other, and how they look from different viewpoints. They do this mostly by giving the models a huge amount of well-designed practice data focused on spatial skills.
What is the paper trying to find out?
The researchers explore five simple questions:
- Can we make AI much better at spatial thinking by training on a large, carefully chosen set of spatial problems?
- Which parts of spatial intelligence improve most as we scale up the data?
- Does training on diverse spatial tasks help the model “transfer” skills to new tasks it hasn’t seen?
- Are the improvements real, or is the model just guessing from text patterns or taking shortcuts?
- Do these spatial skills help with real-world tasks, like controlling a robot to move objects in the right places?
How did they do it?
The starting point: multimodal foundation models
They start from powerful, general models that can understand both images and text:
- Qwen3-VL
- InternVL3
- Bagel
Think of these as smart “base brains” that already read and see reasonably well.
A data-first strategy
Instead of changing how the models are built, they change what the models learn from. They assemble about eight million question–answer examples focused on spatial skills. This collection is called SenseNova-SI-8M. The data covers five core abilities:
- Metric Measurement (MM): Estimating sizes and distances (e.g., “How far is the chair from the camera?”).
- Spatial Relations (SR): Understanding left–right, front–back, up–down, near–far, big–small.
- Mental Reconstruction (MR): Figuring out 3D shapes from limited 2D views (e.g., “Which side of the box is visible?”).
- Perspective-taking (PT): Reasoning across different camera views (e.g., recognizing the same object from different angles).
- Comprehensive Reasoning (CR): Combining multiple skills to solve multi-step problems.
To build this data, they mix:
- Existing public datasets that already test spatial reasoning.
- New, large-scale Q&A made from real 3D scene datasets (like ScanNet and Matterport3D), which provide accurate labels for where objects are and how they move.
Training and testing
- They train each model on the same spatial dataset for one pass (called one “epoch”).
- They keep the model architectures the same to make fair comparisons.
- They test on new, tough benchmarks that measure spatial intelligence, like VSI-Bench, MMSI, MindCube, ViewSpatial, and SITE, and also on a general test called MMBench-En to ensure the models didn’t forget their general skills.
Guarding against shortcuts
To make sure the models aren’t just gaming the tests:
- They use “debiased” versions of benchmarks that remove text-only hints.
- They run “circular tests” that shuffle answer choices to prevent memorizing patterns.
- They test performance without images to check if the model can still guess correctly from text alone (which would be bad).
Trying chain-of-thought (CoT)
They also test whether step-by-step written reasoning (CoT) helps with spatial problems. They try several CoT styles, including detailed “cognitive maps” that track objects across frames.
What did they find?
Big improvements in spatial intelligence
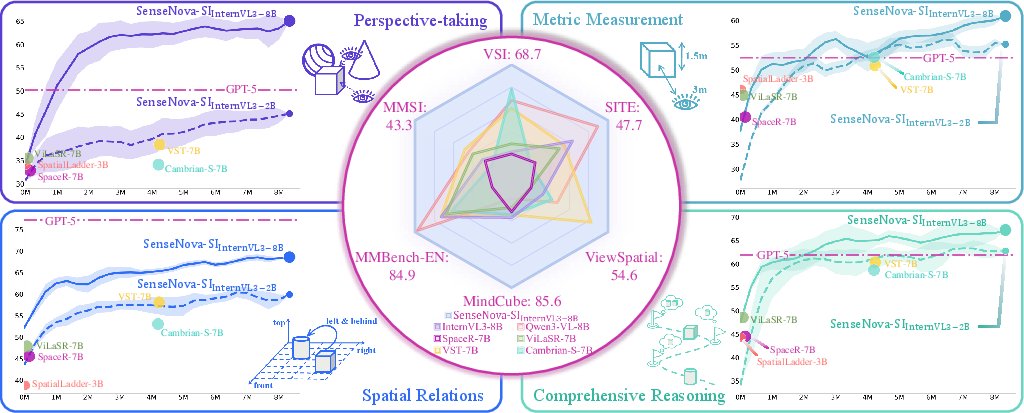
Across many benchmarks, SenseNova-SI models set new records for open-source models (and sometimes rival closed, proprietary systems):
- VSI-Bench: up to 68.7%
- MMSI: up to 43.3%
- MindCube: up to 85.6%
- ViewSpatial: up to 54.6%
- SITE: up to 50.1%
They also keep strong general skills:
- MMBench-En: around 84.9%
Perspective-taking is the game-changer
Training with lots of viewpoint-change problems (PT) is especially powerful. It teaches the model to “mentally rotate” and match objects across different camera angles — a core human-like skill that many AI models lacked.
Scaling laws and saturation
- More spatial data generally makes the models better, but gains slow down after a while.
- Bigger models learn more complex spatial skills (like perspective-taking) better than smaller ones.
Emergent generalization
- When trained on one spatial task (like matching the same object across two views), the model gets better at different, related tasks it wasn’t trained on (like figuring out camera motion or navigating a maze).
- The model trained on short video clips can still handle longer clips during testing, showing it learned underlying spatial structure, not just memorized frame patterns.
Less cheating, more real vision
- SenseNova-SI relies much less on text-only cues than other models.
- On tests without images, SenseNova-SI’s performance drops a lot — which is good, because it means the model actually needed the visuals to answer correctly.
- In “circular” tests, SenseNova-SI stays stable, showing it doesn’t depend on answer ordering tricks.
Chain-of-thought is not a silver bullet
- Even carefully designed CoT provides only small improvements on spatial tasks.
- The extra training and inference cost for CoT doesn’t pay off much compared to simply giving the model more, better spatial data.
Real-world impact: robot manipulation
- Without any extra fine-tuning, SenseNova-SI improves success rates on robot manipulation tasks in EmbodiedBench’s spatial subset.
- It better understands commands like “place the block to the left of the cup” and executes motions more reliably.
Why does this matter?
- Stronger spatial intelligence is key for embodied AI: robots, AR glasses, home assistants, and any system that needs to understand and interact with the physical world.
- The paper shows a practical path: data-centric scaling focused on core spatial skills builds robust, general improvements.
- Perspective-taking — seeing the world from changing viewpoints — is central. Training it well unlocks broader spatial abilities.
- Simply adding more data will eventually hit limits; future advances may need new ideas beyond text-based step-by-step reasoning.
- The authors release their models and keep updating their work, helping the community build better spatially aware AI faster and more fairly.
In short: by carefully scaling the right kind of spatial training data and validating results against shortcuts, the SenseNova-SI models take a big step toward AI that “thinks in space” more like we do.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored based on the paper; each item is phrased to be directly actionable for future research.
- Architectural priors vs. data scaling: The study intentionally avoids modifying base architectures; it remains open whether explicit 3D inductive biases (e.g., camera-aware tokens, differentiable geometry, SLAM-like memory, neural fields) would surpass pure data scaling for spatial intelligence (SI).
- Camera metadata integration: The models do not ingest camera intrinsics/extrinsics; evaluate whether providing real camera parameters improves metric measurement, perspective-taking, and cross-view consistency.
- Depth/3D sensor inputs: Only 2D images/video are used at inference; test whether adding depth/point clouds (or learned 3D features) materially improves SI without compromising general multimodal ability.
- Long-horizon spatiotemporal reasoning: Training was limited to 16 frames and extrapolation plateaus beyond 64; investigate architectures and memory mechanisms for stable SI over minutes-long videos and sparse temporal sampling.
- Saturation characterization: Gains diminish with scale but no formal scaling-law fits are reported; quantify exponents, inflection points, and capability-specific scaling regimes to guide data/model scaling decisions.
- Data–model size interaction: Only 2B and 8B models are examined; systematically map how SI scales across wider model sizes (sub-1B to >30B) and vision backbone capacities/resolutions.
- Perspective-taking (PT) “meta-tasks”: Spill-over is observed but not causally pinned down; identify minimal PT tasks that induce broad generalization via controlled ablations with matched data sizes, negative controls, and domain randomization.
- Comprehensive reasoning (CR) scarcity: CR data are reused and limited; curate and release diverse, multi-step CR tasks requiring composition of PT, SR, MM, and MR under longer contexts.
- Mental reconstruction (MR) and object reconstruction gaps: The paper notes object reconstruction remains unaddressed; design MR tasks that require reconstructing occluded geometry, topology, and fine-grained part relations with evaluable 3D metrics.
- Open-ended vs. multiple-choice evaluation: Most benchmarks lean on multiple-choice; evaluate SI with open-ended, graded, and programmatic targets (e.g., numeric distances with tolerances, structured spatial graphs) to reduce guessing and option-order biases.
- Debiasing and decontamination breadth: Debiasing is shown for VSI and MindCube only; extend text-only, circular, and counterfactual tests across all benchmarks and provide dataset-level decontamination audits (near-duplicate and source overlap detection).
- Cross-domain generalization: Training and evaluation skew indoor; test SI on outdoor, aerial, driving, egocentric mobile AR, and surgical/industrial scenes to probe domain shift and scale ambiguity.
- Robustness to real-world perturbations: Systematically stress-test occlusions, lighting/weather, camera FOV/distortion, motion blur, sensor noise, and object clutter; report failure modes and robustifying interventions.
- Spatial Chain-of-Thought (CoT) design: CoT yields limited gains on one subset; explore alternative intermediate representations (diagrammatic/scene graphs, sketch-based steps, executable geometry programs, 3D latent rollouts) and measure their cost–benefit across SI capabilities.
- Tool-augmented reasoning: Evaluate hybrid approaches that call geometry engines, differentiable renderers, physics simulators, or mapping modules at inference, and measure utility vs. latency in SI tasks.
- Uncertainty estimation and calibration: No uncertainty is reported; develop calibrated confidence and abstention for SI decisions (especially metric estimates and PT), and test selective prediction strategies.
- Interpretability of spatial representations: The model’s internal coordinate frames and metric understanding are opaque; probe emergent world frames, object trajectories, and scale priors via probing tasks and mechanistic analyses.
- Multilingual spatial language: Benchmarks are primarily English; assess cross-lingual SI (different frames of reference, prepositions, and cultural conventions) and multilingual training strategies.
- Embodied deployment gap: Downstream results are in simulation and prompt-only; conduct closed-loop real-robot trials, study latency, safety constraints, sim-to-real transfer, and task-level sample efficiency without fine-tuning.
- Efficiency and cost: Training uses uniform hyperparameters (1 epoch, 128 GPUs) across bases; quantify sample efficiency, data-mixing/balancing strategies, curriculum schedules, and the return on compute vs. data scale.
- Temporal modeling choices: The impact of specialized motion encoders (optical flow, 3D CNNs, video transformers with long context) is not assessed; ablate temporal encoders for SI gains per FLOP.
- Evaluation metrics for metric measurement: Accuracy-only metrics obscure near-miss performance; adopt continuous error metrics (e.g., absolute/relative distance error) and calibration curves for MM tasks.
- Data quality and heterogeneity: Merged datasets likely differ in label schemas, biases, and annotation quality; publish auditing analyses, harmonization procedures, and per-source contribution to SI improvements.
- Data leakage risks: The paper aggregates many SI datasets (e.g., VSI-590K) while evaluating on related benchmarks; provide thorough leakage checks and source-level deduplication reports for each benchmark.
- Release completeness: Models and code are released, but it is unclear if the full 4.5M generation pipeline and prompts for QA synthesis are public; release generation scripts, templates, and licensing notes for reproducibility.
- Numeric inconsistency: The paper alternately cites SenseNova-SI-8M and a total of 8.5M QA pairs; clarify the final corpus size, splits, and exact composition used for each reported result.
- Trade-offs across capabilities: Heavy emphasis on PT might overshadow other skills; provide ablations on data allocation (PT vs. SR vs. MM vs. MR vs. CR) and their cross-capability trade-offs.
- Beyond accuracy improvements: Investigate whether SI gains affect harmful biases, privacy risks (e.g., Ego-Exo4D content), and security vulnerabilities (e.g., adversarial patches) in spatial settings.
- Open-ended planning and programs: For CR and embodied tasks, examine program-of-thought or planning-language interfaces that output structured action plans grounded in spatial representations.
Practical Applications
Immediate Applications
The paper releases open-source multimodal models (SenseNova-SI), an 8.5M-sample spatial dataset, and training/evaluation code that together enable drop-in improvements to spatial reasoning in existing vision-language systems. The following applications can be deployed now, with noted assumptions and dependencies.
- Robotics manipulation with natural spatial language (warehousing, manufacturing, labs)
- Sector(s): Robotics, Manufacturing, Logistics
- What it enables: More reliable pick-and-place in clutter; following instructions like “grasp the rear-left red box,” improved pose-aware action planning without task-specific finetuning (validated on EmbodiedBench); better egocentric-to-allocentric grounding for robot control.
- Potential tools/products/workflows: “Spatial Planner” plugin for VLA stacks (e.g., OpenVLA, RT-X) using SenseNova-SI as the perception-and-reasoning layer; prompt templates like SIP (spatial-intelligence-oriented prompts); QA-based regression tests for spatial skills.
- Dependencies/assumptions: Camera extrinsics/robot calibration and safety interlocks; deterministic low-latency inference; domain shift management (indoor-biased training data); integration with motion planners and controllers; adherence to safety/standards.
- Multi-camera retail shelf auditing and planogram compliance
- Sector(s): Retail, Robotics, Computer Vision
- What it enables: Cross-view correspondence for product/location checks; metric and relative-position validation (“is the small toothpaste above and left of the large shampoo?”); fewer manual audits.
- Potential tools/products/workflows: “Shelf Auditor” microservice that consumes multiple aisle images and returns compliance deltas; store ops dashboard with spatial alerts.
- Dependencies/assumptions: Camera placement metadata or light calibration; SKU detection pipeline; privacy compliance.
- AR-assisted measuring, layout, and assembly guidance
- Sector(s): AR/VR, Interior Design, Consumer Apps, DIY
- What it enables: Room/furniture measurements from photos/video (Metric Measurement); viewpoint-consistent placement guidance; assembly instructions that disambiguate “front/back/left/right” steps.
- Potential tools/products/workflows: Mobile SDK for SpatialQA; “Measure & Place” app leveraging PT+SR; instruction generators that auto-check spatial steps.
- Dependencies/assumptions: Adequate camera calibration or scale priors; edge compute or streaming; user safety disclaimers for measurement tolerances.
- Construction progress monitoring and BIM comparison
- Sector(s): AEC (Architecture, Engineering, Construction), Real Estate
- What it enables: Multi-view progress checks vs. BIM; hazard spot checks (e.g., clearances, occlusion zones); perspective-consistent photo documentation.
- Potential tools/products/workflows: “BIM Comparator” service to align site photos to allocentric plans; periodic site QA with alerting.
- Dependencies/assumptions: Access to site imagery; coarse camera pose or reference points; alignment to BIM coordinate frames; human-in-the-loop validation.
- Manufacturing quality control (spatial checks)
- Sector(s): Manufacturing, QA/QC
- What it enables: Automated checks for assembly relations (above/below, near/far, correct orientation), fast triage of misalignments from multi-view stations.
- Potential tools/products/workflows: “Spatial QC” operator that reads station images and returns pass/fail with explanations; integration with MES.
- Dependencies/assumptions: Stable imaging geometry; tolerance thresholds; explainability logs for auditors.
- Surveillance and multi-camera identity/path reasoning
- Sector(s): Security, Smart Cities, Transportation
- What it enables: Cross-view re-identification aided by geometric PT; route/path inference through camera networks; egocentric/exocentric reasoning for incident reconstruction.
- Potential tools/products/workflows: “Camera Network PT Engine” that computes consistent identities and trajectories across feeds.
- Dependencies/assumptions: Camera topology knowledge; privacy and regulatory compliance; robust object detectors.
- Geospatial cross-view alignment (street-level ↔ aerial/satellite)
- Sector(s): Geospatial, Mapping
- What it enables: Viewpoint transfer between ground images and overhead maps; establishing correspondences for change detection and mapping updates.
- Potential tools/products/workflows: “CrossView Mapper” API; photogrammetry preprocessor for better tie-points from casual imagery.
- Dependencies/assumptions: Coordinate reference system metadata; enough overlap across views; domain adaptation for outdoor scenes.
- Healthcare imaging workflow assistance (non-diagnostic)
- Sector(s): Healthcare, Medical Imaging
- What it enables: Viewpoint alignment hints for endoscopy/ultrasound videos; distance/relative-location cues; instruction-following for probe navigation (“rotate clockwise until vessel appears at lower-right”).
- Potential tools/products/workflows: “View Coach” sidebar in imaging consoles; training simulators with spatial feedback.
- Dependencies/assumptions: Strict non-diagnostic use; IRB/compliance; model validation on medical data; clinician-in-the-loop.
- Education and assessment of spatial reasoning
- Sector(s): Education, EdTech
- What it enables: Tutors that teach PT/SR/MM via interactive tasks; automatic grading for geometry and visuospatial items; personalized remediation.
- Potential tools/products/workflows: “Spatial Skills Tutor” with EASI-aligned curricula; item generators; analytics dashboards.
- Dependencies/assumptions: Age-appropriate content; bias checks; alignment to standards; classroom device constraints.
- Developer and research tooling for spatial AI
- Sector(s): Software, AI/ML
- What it enables: Rapid evaluation with VSI/MMSI/MindCube/SITE; debiasing tests (VSI-Debiased, circular-choice protocols); scalable data curation from 3D datasets (ScanNet, Matterport3D).
- Potential tools/products/workflows: “SpatialQA API” with taxonomic tags (MM, SR, MR, PT, CR); CogMap JSON schema for intermediate reasoning; unit/regression harnesses for spatial capabilities.
- Dependencies/assumptions: GPU availability; adherence to dataset licenses; reproducible pipelines.
- Insurance claims and property assessment from photos
- Sector(s): Insurance, Real Estate Finance
- What it enables: Size/position estimates for damages; multi-view alignment to validate claims; triage for field inspections.
- Potential tools/products/workflows: “ClaimSpatial” intake assistant; adjuster review UI with viewpoint overlays.
- Dependencies/assumptions: Calibrated or reference objects for scale; fraud detection checks; human approval workflows.
- E-commerce product sizing and AR try-on realism
- Sector(s): E-commerce, Advertising
- What it enables: Size-consistency checks across seller photos; better AR placement that respects relative scale/pose; returns reduction via clear fit expectations.
- Potential tools/products/workflows: “SizeGuard” listing validator; AR scene fitter using PT+MM.
- Dependencies/assumptions: Marketplace policy integration; customer camera variations; lighting/occlusion robustness.
- Cinematography/camera-planning assistants
- Sector(s): Media, Entertainment, Game Dev
- What it enables: Storyboarding with camera motion reasoning; matching shots across viewpoints; automatic spatial continuity checks.
- Potential tools/products/workflows: “ShotMatch” for cross-view continuity; previz plugins for DCC tools and game engines.
- Dependencies/assumptions: Scene proxy models or annotated keyframes; artist oversight.
- Accessibility: spatially aware assistance for blind/low-vision users
- Sector(s): Assistive Tech, Consumer
- What it enables: Interpreting instructions like “the exit is behind the table, to your left”; object-finding via multi-angle captures; step-by-step spatial guidance.
- Potential tools/products/workflows: Mobile assistant that fuses user-captured views; earbud/voice feedback powered by SR/PT.
- Dependencies/assumptions: On-device or private compute; careful UX to avoid unsafe guidance; liability considerations.
- Public-sector triage from multiview disaster imagery
- Sector(s): Emergency Response, Policy
- What it enables: Rapid alignment of crowd-sourced photos to maps; distance/clearance estimates; prioritization of search areas.
- Potential tools/products/workflows: “CrisisSpatial” intake and mapping pipeline; volunteer photo QA with PT checks.
- Dependencies/assumptions: Data rights and privacy; uncertain geometry and GPS; human verification loops.
Long-Term Applications
Several higher-impact uses will require additional research (e.g., new reasoning mechanisms beyond text CoT), broader data coverage, scaling, and/or regulatory clearance.
- General-purpose embodied agents with robust spatial planning
- Sector(s): Robotics, Consumer, Service
- What it targets: Home/service robots that follow complex spatial instructions, build allocentric maps, and generalize across homes/factories.
- Dependencies/assumptions: Robust long-horizon memory; reliable PT under heavy occlusion; safety certification; affordable hardware.
- Autonomous vehicles and drones with improved cross-view reasoning
- Sector(s): Mobility, Logistics, Agriculture
- What it targets: Integrating PT/MR into perception stacks for better occlusion handling, map alignment, and camera pose inference from sparse views.
- Dependencies/assumptions: Tight integration with SLAM/HD-maps; real-time guarantees; extreme reliability; outdoor domain scaling.
- Surgical navigation and robotic assistance (regulated use)
- Sector(s): Healthcare, MedTech
- What it targets: Precise viewpoint reasoning across endoscopic views; spatially-aware tool guidance; occlusion-aware planning.
- Dependencies/assumptions: Clinical-grade validation; regulatory approvals; domain-specific training; human override.
- City-scale digital twins from heterogeneous viewpoints
- Sector(s): Smart Cities, Utilities, Urban Planning
- What it targets: Consistent, continuously updated 3D twins using cross-view fusion (street, drone, satellite) for maintenance, traffic, and planning.
- Dependencies/assumptions: Massive data ingestion; standardized coordinate frames; governance and privacy frameworks.
- Neuro-symbolic spatial reasoning and non-text CoT paradigms
- Sector(s): AI/ML Research, Software
- What it targets: New reasoning mechanisms that go beyond text-based Chain-of-Thought—e.g., explicit 3D scene graphs, executable planners, or differentiable simulators tied to SenseNova-SI embeddings.
- Dependencies/assumptions: Algorithmic innovations; efficient intermediate representations; training supervision and compute budget.
- Persistent AR glasses with scene-consistent spatial understanding
- Sector(s): AR/VR, Consumer, Enterprise
- What it targets: Always-on viewpoint-consistent overlays, multi-user shared spatial frames, accurate metric cues in dynamic scenes.
- Dependencies/assumptions: Low-power on-device models; privacy-by-design; continual calibration; robust multi-sensor fusion.
- Fully automated industrial inspection and certification
- Sector(s): Manufacturing, Energy, Aerospace
- What it targets: End-to-end spatial QA without human review for critical tolerances and clearances across multi-view stations and robots.
- Dependencies/assumptions: Zero/low-defect operation; explainability; compliance with standards and audits.
- Multi-agent spatial coordination via shared allocentric maps
- Sector(s): Warehousing, Defense, Construction
- What it targets: Teams of robots/humans coordinating through consistent world models (PT/CR), adapting to viewpoint changes and occlusions.
- Dependencies/assumptions: Communication latency guarantees; resilient shared maps; safety and liability frameworks.
- Large-scale SI education and workforce upskilling
- Sector(s): Education, Workforce Development
- What it targets: Standardized, objective measurement and training of spatial intelligence for STEM careers, pilot/operator training, and robotics literacy.
- Dependencies/assumptions: Validity/reliability studies; fairness/bias audits; alignment with credentialing bodies.
- Cross-modal geospatial reasoning (vision ↔ language ↔ LiDAR/radar)
- Sector(s): Geospatial, Transportation, Infrastructure
- What it targets: Fusing language instructions, 2D views, and 3D sensors for richer, more reliable spatial understanding and decision-making.
- Dependencies/assumptions: Sensor-time synchronization; scalable multimodal training; standard data schemas.
Notes on Assumptions and Dependencies That Cut Across Applications
- Model and data access: Availability and licensing of SenseNova-SI weights/datasets; sufficient GPU/edge compute.
- Domain shift: Current data skews toward indoor scenes; outdoor/medical/industrial domains need adaptation and validation.
- Calibration and geometry: Many high-accuracy uses require camera intrinsics/extrinsics or reference objects for metric scale.
- Safety, regulation, and liability: Especially for robotics, medical, and transportation applications.
- Privacy and governance: Multi-camera and surveillance-like deployments need strict compliance and data minimization.
- Robustness limits: Saturation trends and limited gains from text CoT suggest the need for new reasoning paradigms for the most demanding tasks.
- Latency and scale: Video and multi-view inference costs must be managed (e.g., frame subsampling; the paper shows some extrapolation to longer sequences, but real-time guarantees still require engineering).
Glossary
- 2D grounding: Associating textual references with 2D image regions for localization or understanding. "It covers general visual understanding (Non-SI), 2D grounding, and five core spatial abilities: Metric Measurement (MM), Spatial Relationship (SR), Perspective-Taking (PT), Mental Reconstruction (MR), and Comprehensive Reasoning (CR)."
- 3D coordinate system: A reference frame with three axes used to represent positions and relations in space. "We define SR as the ability to impose and reason within a 3D coordinate system."
- 3D expert encoders: Specialized vision models that infer 3D properties from images and provide geometric features to multimodal systems. "an intuition is to employ 3D expert encoders that infer key 3D attributes from images"
- AdamW: An optimizer variant that decouples weight decay from gradient updates, improving training stability. "We employ AdamW~\cite{loshchilov2017decoupled} with a learning rate of 510 for all model-training runs."
- Allocentric Transformation: Reasoning about changes in viewpoint using world- or object-centered coordinates rather than the observer’s perspective. "Allocentric Transformation. Simulate viewpoint shifts and express spatial relations across coordinate systems, including camera, object-target, and self-oriented views."
- Camera Motion Reasoning: Inferring how the camera moved between views based on changes in visual appearance and geometry. "Camera Motion Reasoning. Infer relative camera motion between views, linking appearance changes to 3D transformations."
- Capability synergy: The phenomenon where improvements in fundamental skills transfer and enhance more complex abilities. "This suggests the presence of capability synergy, where advances in fundamental spatial tasks (e.g., PT and SR) transfer to more complex reasoning skills."
- Catastrophic forgetting: Loss of previously learned capabilities when training on new data without safeguards. "Empirically, we find that data diversity is crucial: incorporating a wide coverage of multimodal data and varied general knowledge sources effectively mitigates catastrophic forgetting and preserves overall multimodal competence."
- Chain-of-Thought (CoT): A prompting/training technique that elicits step-by-step reasoning in model outputs. "Chain-of-Thought (CoT)~\cite{wei2022chain} has become the de facto approach for complex reasoning tasks."
- Circular tests: Robustness checks that reorder answer options to detect reliance on superficial text patterns. "we conduct circular tests~\cite{liu2024mmbench,li2024core,cai2025has}, which reorders the choices in the questions to eliminate dependency on certain text patterns."
- Cognition map (CogMap): A structured, often JSON-style representation of entities and relations used to scaffold spatial reasoning. "constructs a JSON-style cognition map (CogMap) within the CoT;"
- Confidence bands: Shaded regions around a performance curve indicating variability (e.g., standard deviation) in results. "the shaded regions (confidence bands) represent standard deviation."
- Cross-modal alignment: The learned correspondence between modalities (e.g., vision and language) enabling integrated reasoning. "thus enables stronger cross-modal alignment, more efficient scaling, and improved visual–language reasoning."
- Cross-view visual correspondence: Matching the same points/objects across images taken from different viewpoints. "The lower example demonstrates how a camera rotation task, based on cross-view visual correspondence, generalizes to tasks with distinct questions and visual appearances."
- Data scaling laws: Empirical relationships describing how performance changes as training data size increases. "Our study investigates the data scaling laws of spatial intelligence through extensive experiments on the widely adopted InternVL3 multimodal foundation model family~\cite{zhu2025internvl3}, and further extends the analysis to Qwen3-VL~\cite{Qwen3-VL} as well as Bagel~\cite{deng2025bagel}, a unified understanding and generation model."
- Debiased benchmark (VSI-Debiased): An evaluation designed to remove text-only shortcuts so that visual reasoning is required. "The recently proposed VSI-Debiased~\cite{brown2025benchmark(vsidebiased)} is a specifically designed variant of VSI to eliminate text-only shortcuts by removing questions that can be answered correctly without visual understanding."
- Downstream (tasks/applications): Practical tasks where a trained model is applied to measure real-world utility. "we conduct downstream robot manipulation experiments on EmbodiedBench~\cite{yang2025embodiedbench}, focusing specifically on its spatial subset."
- Egocentric: A perspective centered on the observer/camera’s viewpoint. "In egocentric, local level of view, it unfolds into frontâback, leftâright, and upâdown relations between subjects."
- Embodied AGI: An AI paradigm where agents perceive and act in the physical world, integrating cognition with embodiment. "which is fundamental to embodied AGI that can perceive, adapt to, and interact with the physical world."
- Embodied agent: An AI system that controls a physical or virtual body to perform tasks based on perception and reasoning. "SenseNova-SI is instantiated as an embodied agent that controls a virtual Franka Panda robot to execute user instructions containing rich spatial language such as "left", "on top of", "rear", and "horizontal"."
- Emergent generalization: Unexpected transfer and performance on new tasks arising from diverse training without explicit instruction. "discuss early signs of emergent generalization capabilities enabled by diverse data training,"
- Exocentric: A perspective external to the observer, often world- or third-person-centered. "translate between egocentric and exocentric viewpoints"
- Extrapolation: Successfully handling inputs or contexts longer or more complex than those seen during training. "and demonstrate extrapolation to longer spatial contexts beyond the training distribution."
- Finetuning: Further training a pretrained model on a specific task or dataset to specialize its capabilities. "without any finetuning"
- Language priors: Answering tendencies driven by textual patterns or biases rather than actual visual reasoning. "revealing a heavy dependence on language priors rather than visual reasoning."
- Language shortcuts: Spurious cues in text that allow correct answers without genuine multimodal reasoning. "overfitting and language shortcuts"
- Mental Reconstruction (MR): Inferring 3D object or scene structure from limited 2D observations. "MR focuses on inferring 3D object structure from limited 2D observations."
- Metric Measurement (MM): Estimating distances, scales, and sizes within scenes and objects. "MM involves a basic understanding of the physical scale and typical object sizes."
- Multi-perspective localization: Determining positions across multiple viewpoints, often integrating egocentric and allocentric frames. "isolates multi-perspective localization, evaluating a modelâs perspective-taking ability to reason across egocentric (camera) and allocentric (human or object) viewpoints."
- Multimodal foundation model: A large model trained to process and reason across multiple modalities like vision and language. "multimodal foundation models~\cite{Qwen3-VL, zhu2025internvl3, deng2025bagel} have achieved groundbreaking progress across a wide spectrum of tasks."
- Object-centric frame: A coordinate frame centered on an object, used to reason about its geometry and views. "align views in a canonical object-centric frame."
- Perspective-taking (PT): Reasoning about how a scene appears from different viewpoints and transforming between them. "PT addresses reasoning with changing camera viewpoints."
- Pretraining paradigms: Strategies and setups used to train models on large corpora before downstream adaptation. "across diverse architecture designs and pretraining paradigms."
- Spatial Relations (SR): Reasoning about relative positions and orientations (e.g., left/right, near/far) within a scene. "We define SR as the ability to impose and reason within a 3D coordinate system."
- Spatially grounded data: Datasets where annotations and tasks require true spatial understanding rather than textual cues. "scarcity and imbalance of spatially grounded data."
- State-of-the-art (SoTA): The best reported performance at the time on a task or benchmark. "achieves state-of-the-art (SoTA) results on five recent spatial intelligence benchmarks"
- Taxonomy (of spatial capabilities): A principled categorization of the different skills that comprise spatial intelligence. "under a rigorous taxonomy of spatial capabilities."
- Unified understanding and generation model: An architecture designed to both comprehend inputs and generate outputs across modalities. "a unified understanding and generation model."
- View correspondence: Matching entities across different views, often under scale or occlusion changes. "View Correspondence. Establish correspondences of points or objects across views, recognizing entities under changes in viewpoint, scale, and occlusion."
- Viewpoint transformations: Mappings that convert representations between different camera or coordinate viewpoints. "We hypothesize that the 2B model lacks sufficient capacity to robustly learn viewpoint transformations"
Collections
Sign up for free to add this paper to one or more collections.

