- The paper demonstrates that using executable code as an intermediate chain-of-thought enables deterministic, interpretable image drafts.
- It introduces a three-stage pipeline—code generation, sandboxed draft rendering, and visual refinement—that outperforms text-only approaches.
- Experimental results on structured benchmarks reveal significant accuracy gains in complex scene composition and rare concept synthesis.
CoCo: Code as Chain-of-Thought for Structured Text-to-Image Generation
Motivation and Problem Setting
Recent advances in Unified Multimodal Models (UMMs) have led to significant progress in end-to-end text-to-image (T2I) synthesis, with Chain-of-Thought (CoT) paradigms demonstrating enhanced reasoning and controllability. However, prior CoT-based T2I systems predominantly rely on abstract textual intermediates, which are inherently limited in expressing complex spatial layouts, dense textual content, and structure-constrained visual scenes. This abstraction leaves existing UMMs ill-suited for tasks requiring precise compositionality, semantic alignment, and deterministic rendering.
The paper "CoCo: Code as CoT for Text-to-Image Preview and Rare Concept Generation" (2603.08652) addresses this critical gap by proposing a structured code-driven intermediate for explicit and verifiable multimodal reasoning. The core claim is that employing executable code as intermediate CoT not only enables faithful layout specification and interpretable drafts in T2I but also substantially outperforms text-only or visually drafted CoT approaches, especially on benchmarks emphasizing structured scenes, scientific figures, and rare concept synthesis.
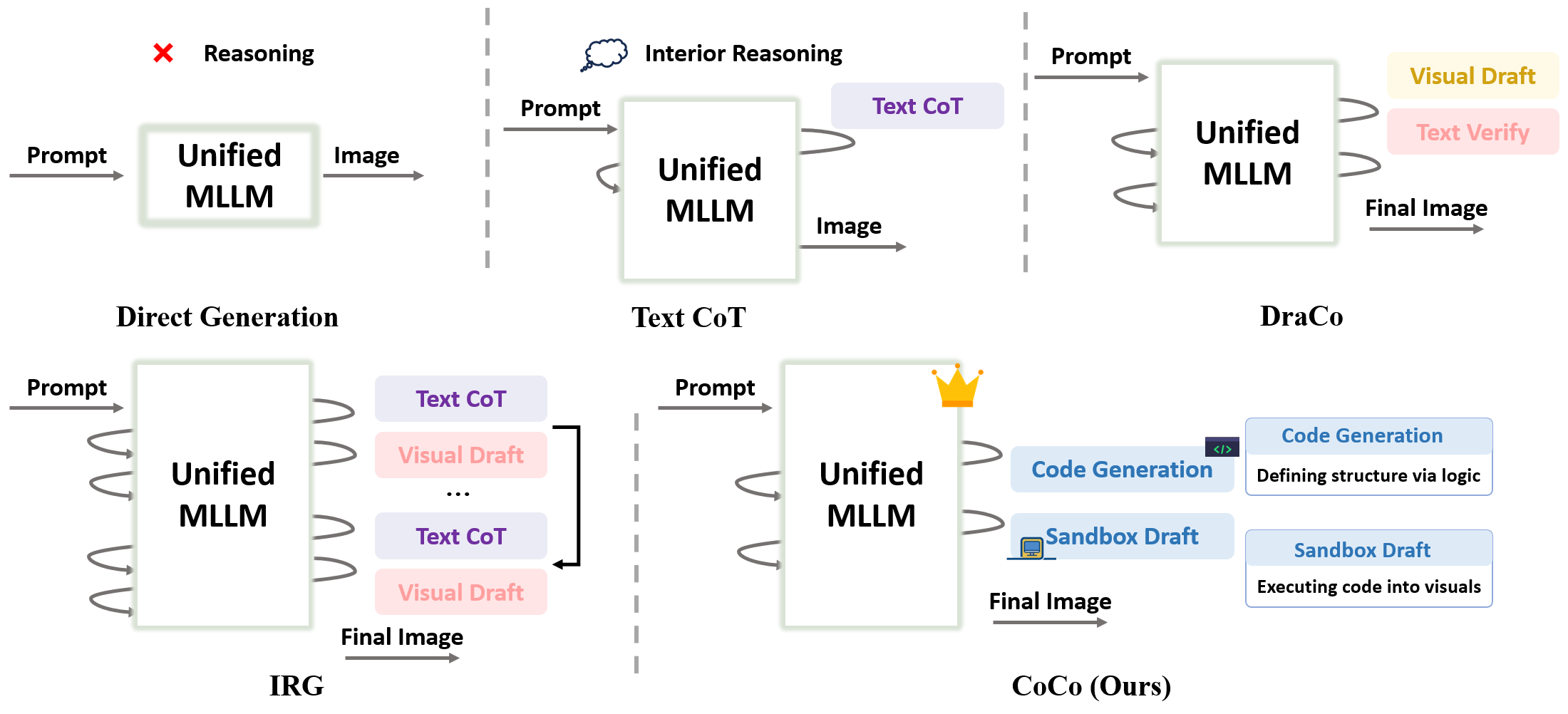
Figure 1: Comparison of reasoning paradigms for T2I, highlighting CoCo's approach of using executable code for explicit, controllable, and verifiable draft generation.
Methodology: Code-as-CoT Framework
The central framework, CoCo, builds on a unified MLLM (Bagel), and introduces a three-stage pipeline:
- Executable Code Generation: Given a textual prompt, CoCo generates structured domain-specific code (e.g., Python+matplotlib-like DSL) that declaratively specifies object layouts, spatial relationships, and textual annotations.
- Sandboxed Draft Rendering: The generated code is executed in a deterministic, sandboxed environment to yield an interpretable draft image capturing the compositional and spatial semantics prescribed by the code.
- Draft-Guided Visual Refinement: The preliminary draft and the original prompt are then input into Bagel for fine-grained visual editing, infilling, and stylization, producing the final high-fidelity image consistent with both the plan and the user intent.
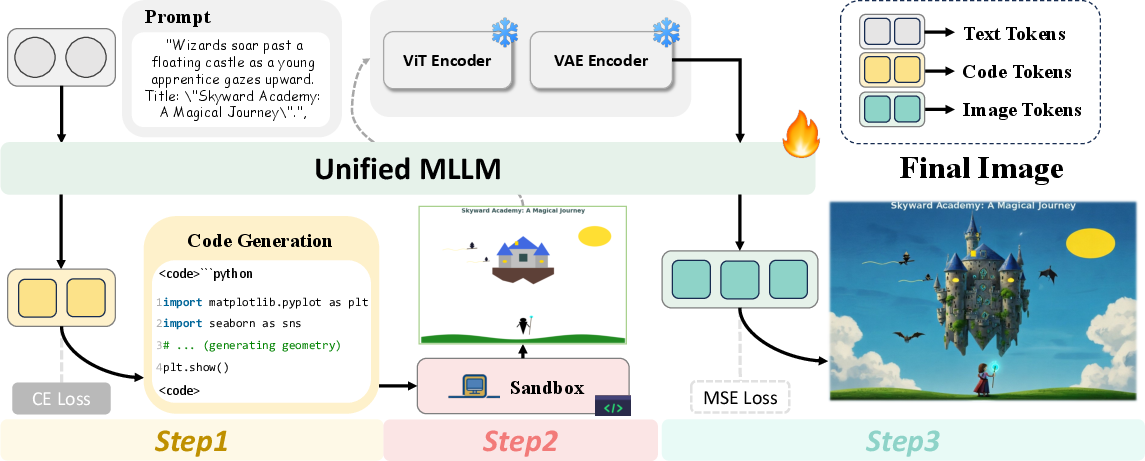
Figure 2: The CoCo pipeline, showing the code generation, draft rendering, and guided refinement stages.

Figure 3: Sample pipeline outputs—left shows code-executed drafts, right shows final images after draft-based refinement.
This paradigm fundamentally diverges from previous methods in its explicit and programmatic specification of visual reasoning, enabling deterministic, inspectable drafts and direct correction of layout or content errors before the expensive refinement stage.
Dataset: Construction of CoCo-10K
A key bottleneck is the absence of datasets coupling structured code, draft, and final images for supervision. To this end, the authors construct CoCo-10K, a synthetic dataset targeting three atomic correction capabilities:
- General structural editing (charts, graphs)
- Scientific diagrams
- Dense and complex text regions
Each instance consists of:
- A prompt
- Generated executable code
- A code-rendered draft image
- A high-fidelity, model-refined image
This design allows for explicit supervision of both code reasoning and visual refinement, facilitating both executable layout planning and semantically aligned correction.
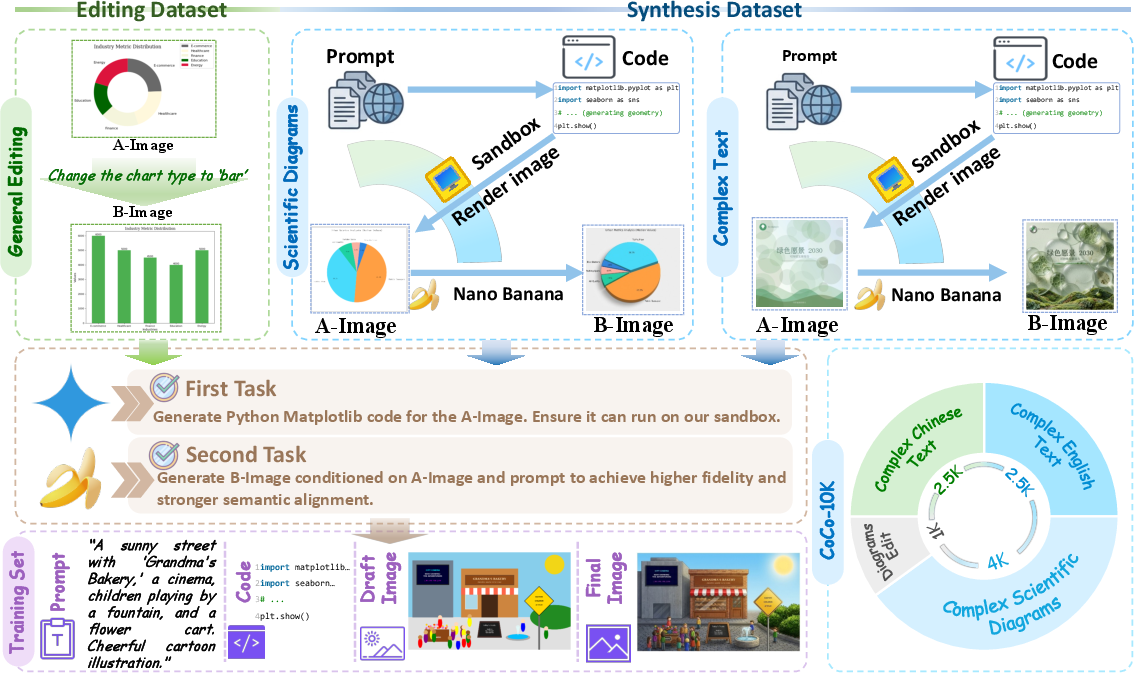
Figure 4: CoCo-10K construction pipeline targeting specialized structured image correction and generation capabilities.

Figure 5: Detailed CoCo-10K samples including prompt, generated code, draft, and final image—showing semantic consistency between all stages.
Experimental Results
Structured Visual Benchmarks
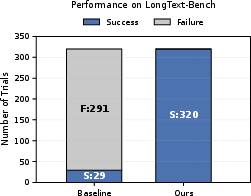
On three challenging benchmarks—StructT2IBench (Zhuo et al., 6 Oct 2025), OneIG-Bench (Chang et al., 9 Jun 2025), LongText-Bench (Geng et al., 29 Jul 2025)—CoCo establishes dominant performance, with the following key numerical highlights:
- StructT2IBench: CoCo obtains 73.52% overall accuracy, outperforming the best baseline (GPT-Image) by +23.94 points.
- OneIG-Bench text rendering (English/Chinese): Achieves 0.895/0.811, besting both generation-only and unified MLLM baselines.
- LongText-Bench: Achieves 0.755/0.753 (English/Chinese), a substantial improvement in long-form text rendering.
Notably, CoCo consistently yields higher accuracy on compositional, structured, and text-intensive tasks, with large margins in Charts, Graphs, Math, and Tables.

Figure 6: Visual comparisons on structured benchmarks; CoCo delivers semantically faithful layout and high-quality text compared to baselines.
Ablation and Diagnostic Analysis
Generalization and Flexibility
A notable emergent property is CoCo's adaptive selection of canvas aspect ratios in response to prompt semantics, despite all training data being at fixed resolution. This indicates deeper reasoning understanding and compositional flexibility, attributed to the parameterization of layouts in the code intermediate.
Implications and Future Directions
The empirical results strongly support the use of code-based CoT as a powerful, verifiable intermediate for high-precision, controllable T2I. Practical implications include:
- Higher fidelity and semantic alignment in tasks requiring rare concept rendering, scientific diagrams, document layouts, or typography.
- Deterministic editability: Changes are traceable and correctable at either code or draft stages without ambiguous text-only reasoning.
- Rare concept synthesis: By separating structure from rendering, the model can synthesize novel visual compositions beyond typical data-driven distributions.
Theoretically, the structured reasoning enabled by code intermediates draws parallels to program synthesis and interpretable planning. Bringing explicit, executable reasoning into the unified multimodal modeling framework opens avenues for auditability, verifiability, and zero-shot compositional extensions.
Likely future work includes extending code-based CoT to other modalities (e.g., video, 3D synthesis), integrating richer DSLs for more complex objects, and unifying programmatic and diffusion/transformer-based generation paradigms. There is also significant potential for closed-loop editing, human-in-the-loop correction at the code level, and robust rare-concept generalization.
Conclusion
CoCo introduces a decisive leap in structured text-to-image reasoning by formulating executable code as the intermediate Chain-of-Thought. By concretely encoding scene layouts, relationships, and textual content as code, CoCo enables deterministic, interpretable drafts and delivers state-of-the-art performance on benchmarks that stress structure and semantic alignment. The introduction of CoCo-10K and code-guided visual refinement establishes a foundation for future systems requiring high-precision, controllable, and verifiable structured image synthesis (2603.08652).