- The paper introduces a novel dynamic refinement mechanism using view-adaptive MLPs to update Gaussian attributes per view.
- The method decouples view-invariant geometry from view-dependent residual updates, enhancing fine structure and reducing rendering artifacts.
- Experiments show a +0.8 dB PSNR improvement, robust cross-dataset generalization, and real-time feed-forward inference at 17 FPS.
ViewSplat: View-Adaptive Dynamic Gaussian Splatting for Feed-Forward Synthesis
Introduction
"ViewSplat: View-Adaptive Dynamic Gaussian Splatting for Feed-Forward Synthesis" (2603.25265) addresses fundamental fidelity limitations in feed-forward 3D Gaussian Splatting (3DGS) frameworks for novel view synthesis from unposed images. Previous advances in feed-forward 3DGS have accelerated pose-free 3D scene reconstruction, but a notable performance gap persists compared with per-scene optimization-based pipelines. This discrepancy is attributed to the limitations of single-step static Gaussian primitive regression, especially regarding view-dependent effects and high-frequency details.
ViewSplat proposes a paradigm shift by introducing view-adaptive, dynamically-updated 3D Gaussian representations. The method leverages dynamic multilayer perceptrons (MLPs) that predict per-view residuals for all Gaussian attributes, enabling each primitive to adapt its geometry and appearance in response to the target viewpoint. This dynamic refinement strategy is incorporated into a fully pose-free, feed-forward pipeline built on large-scale vision transformers.
Methodology
The foundational insight behind ViewSplat is that static regression of 3D Gaussian attributes from limited unposed multi-view images is ill-posed for capturing universal scene properties. Instead, the approach decouples view-invariant geometry inference from view-dependent attribute refinement by introducing two latent components: (1) a base primitive representation, and (2) the parameters of a context-conditioned, per-pixel view-dependent MLP. During rendering, these MLPs consume a reduced, 4D target pose encoding and generate residual updates for each Gaussian primitive's position, scale, rotation, opacity, and spherical harmonics (SH) coefficients.
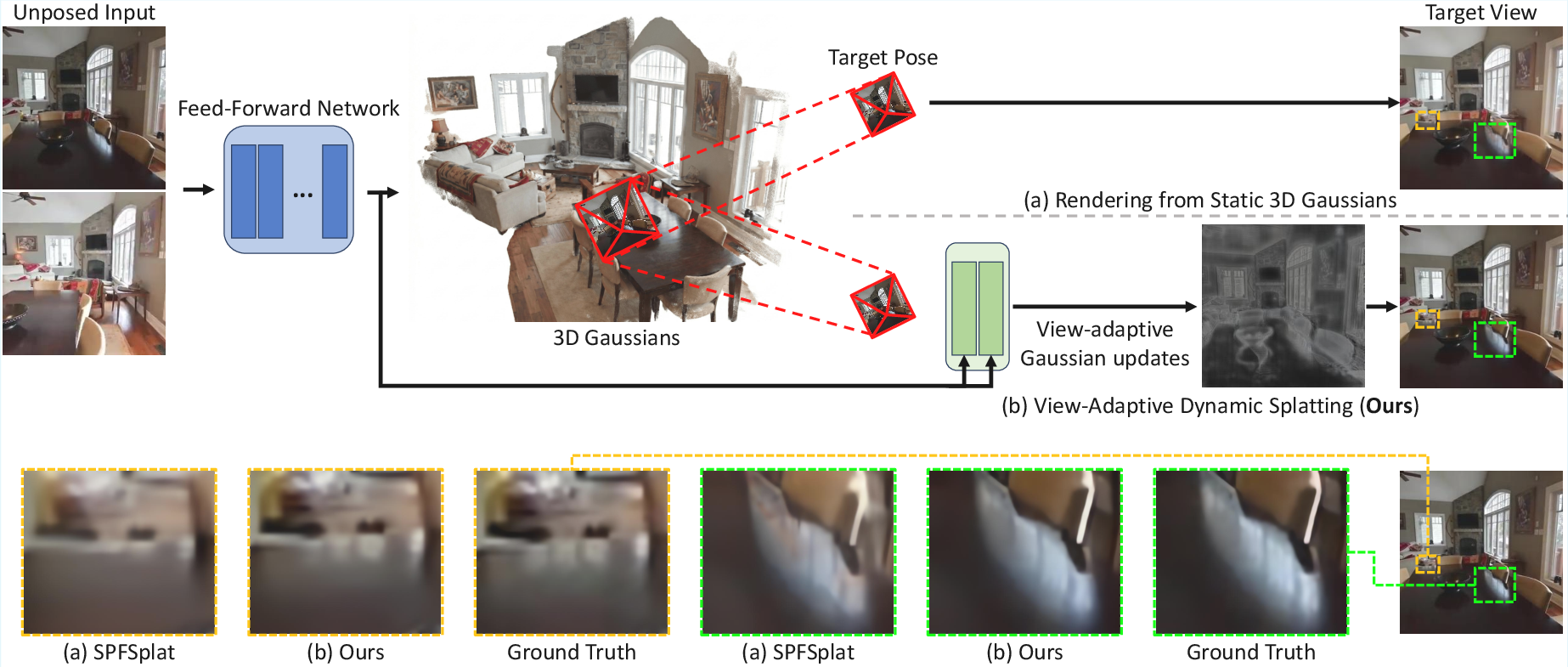
Figure 1: View-adaptive refinement corrects blurred details produced by static 3D Gaussians, improving fine structure and view-dependent effects.
The network backbone comprises a geometry transformer (MASt3R/VGGT), dense-prediction transformer (DPT) heads for Gaussian parameters, and a pose estimation head. The residual prediction component—termed the view-dependent head—utilizes a hypernetwork meta-architecture to synthesize compact view-MPLs conditioned on both scene and viewpoint, allowing local response adaptation.
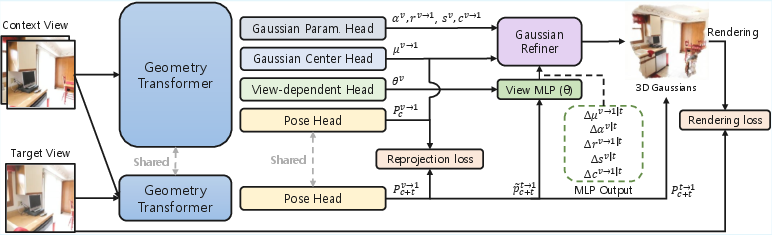
Figure 2: The ViewSplat architecture: a geometry transformer encodes scene context, which informs the canonical Gaussian, pose, and view-dependent residual heads. Residuals are predicted per-pixel, conditioned on target pose.
For computational efficiency, the target pose is reparameterized as a 3D unit direction vector and a log-distance scalar, minimizing MLP input complexity compared to a full extrinsic matrix while retaining spatially-relevant cues for residual synthesis.
The training objective is a combination of an image rendering loss (MSE + LPIPS) and a geometric reprojection loss, with gradients supported through target pose estimation and the 3DGS rasterizer.
Results
Quantitative Analysis
ViewSplat achieves new state-of-the-art PSNR, SSIM, and LPIPS metrics across RE10K and ACID datasets, outperforming all relevant baselines. Notably, the method records an average PSNR improvement of approximately +0.8 dB over SPFSplat, while maintaining fast feed-forward inference (17 FPS) and real-time rendering (154 FPS).
Ablation studies reveal that joint refinement of both geometric and opacity parameters is necessary; decoupling leads to severe perceptual artifacts and collapse, underscoring the requirement for coordinated view-dependent updates.
View-dependent Effects
Critically, increasing the SH degree in static baselines fails to bridge the expressivity gap observed with ViewSplat's dynamic residual modeling, emphasizing the structural limitations of static SH-based splatting for real-world, view-dependent rendering tasks.

Figure 3: Comparison on RE10K demonstrates ViewSplat’s improved reflectance/sharpness versus baselines.
Generalization
The architecture demonstrates robust zero-shot transfer to out-of-domain datasets (e.g., DTU, ACID), reflecting high generalizability of the learned dynamic refinement mechanism—a substantial practical advantage for real-world photogrammetry or photorealistic content creation.
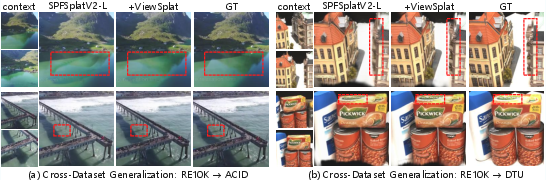
Figure 4: Cross-dataset qualitative results reveal ViewSplat’s stable generalization to unfamiliar scene classes.
Component Analysis
Systematic ablations on the refinement process reveal:
- Decoupling mean and opacity offsets leads to catastrophic failure, confirming that Gaussian positional updates must be tightly coupled with density to preserve spatial coherence and suppress ghosting or collapse.
- Dynamic update of rotation, scale, SH without mean/opacity refinement yields strong improvements, but holistic, joint refinement across all parameters produces the highest fidelity metrics.
- Component-wise analysis justifies the adoption of residual addition for parameter refinement and the selection of 4D pose input encoding.
Efficiency and Practical Considerations
Despite the increased per-pixel computation induced by the view-dependent MLPs, ViewSplat remains practically real-time for most applications, with only moderate increases in inference time and VRAM occupancy relative to the baseline. The architecture remains modular, allowing frozen backbone usage or end-to-end fine-tuning depending on resource constraints, with minimal loss of performance when freezing the transformer's weights.
Limitations
The principal limitation inherited from reconstruction-based, pose-free 3DGS methods is the inability to synthesize plausible content in unobserved or severely occluded regions. Both ViewSplat and its predecessors lack generative priors for hallucinating unseen geometry, resulting in minor blurring or emptiness in highly sparse camera configurations.

Figure 5: Artifacts in unobserved regions illustrate ViewSplat’s limitation—reconstruction without generative priors cannot hallucinate missing content.
Future Directions
The methodological shift suggested by ViewSplat indicates several avenues for future research: (1) increasing MLP/hypernetwork expressivity, (2) integrating lightweight generative priors or compositional inpainting to handle unobserved regions, and (3) exploiting temporal or multi-sequence datasets for dynamic scene understanding via view-temporally adaptive mechanisms.
Conclusion
ViewSplat delivers a rigorous, computationally-efficient solution that overcomes the core limitations of feed-forward, pose-free 3D Gaussian Splatting via dynamic, view-adaptive refinement. This architecture models high-fidelity, view-dependent phenomena and generalizes reliably across domains and scene taxonomies while maintaining real-time rendering. The approach is theoretically significant in bridging the gap between inflexible static representations and expensive iterative optimization, providing a strong basis for advancing high-fidelity neural scene representations in practical settings.