- The paper introduces an anchor-aligned 3D Gaussian splatting method that leverages multi-view stereo priors to decouple scene representation from image resolution.
- It employs a transformer-based Gaussian decoder and a differentiable refiner to boost rendering fidelity and geometric consistency.
- The approach achieves up to 20× fewer Gaussians and faster reconstruction times while outperforming previous pixel- and voxel-aligned methods in benchmark tests.
AnchorSplat: Feed-Forward 3D Gaussian Splatting with 3D Geometric Priors
Overview
AnchorSplat introduces a feed-forward, anchor-aligned 3D Gaussian Splatting (3DGS) architecture that leverages geometric priors for efficient and consistent scene-level 3D reconstruction. In contrast to previous pixel-aligned or voxel-aligned feed-forward methods, the proposed anchor-aligned framework decouples scene representation from image resolution and input-view density, drastically reducing computational redundancy and improving geometric fidelity. The method integrates geometric cues extracted from pretrained multi-view stereo (MVS) estimators, utilizes a transformer-based Gaussian decoder, and employs a differentiable Gaussian refiner to further boost rendering quality and consistency.
Motivation and Background
Conventional optimization-based 3DGS methods, such as 3DGS and NeRF, deliver high-fidelity results but are hindered by significant per-scene optimization overhead and scalability limitations. Recent feed-forward methods improve computational efficiency but either bind the 3D Gaussians directly to pixels—resulting in over-complete and inconsistent 3D reconstructions, especially across views—or rely on voxel-aligned approaches that remain sensitive to resolution and viewpoint coverage. Typical artifacts include floaters, ghost geometry, and inconsistencies under occlusions and low-texture regions.
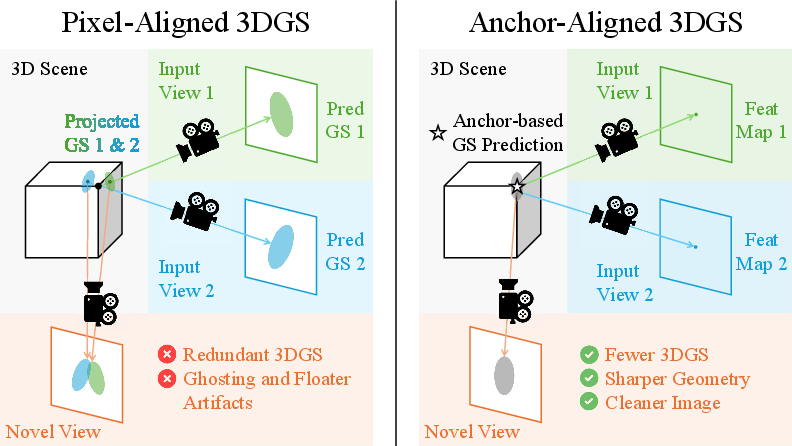
Figure 1: Comparison between pixel-aligned and anchor-aligned Gaussian representations; anchor alignment delivers more stable and consistent 3D geometry.
AnchorSplat directly addresses these challenges by introducing an anchor-based alignment. Rather than generating one Gaussian per pixel, which couples the number and distribution of Gaussians to 2D image structure, AnchorSplat uses sparse, geometry-aware 3D anchors obtained via MVS priors. These form the support for all subsequent Gaussian parameter prediction, compressing the representation and regularizing the predicted scene geometry.
Methodology
Pipeline
AnchorSplat is composed of three principal modules: an anchor predictor, a Gaussian decoder, and a Gaussian refiner.
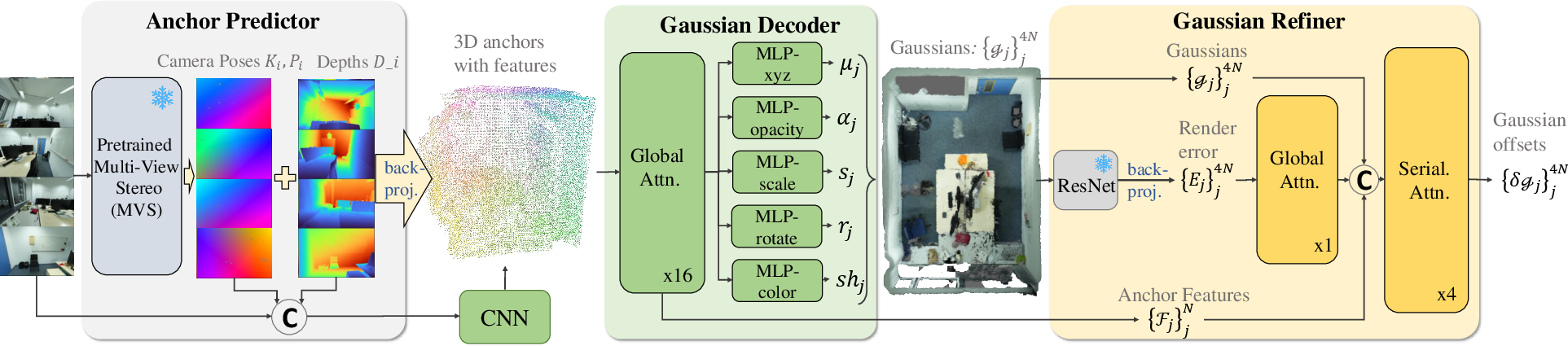
Figure 2: AnchorSplat pipeline integrating geometric priors, a transformer Gaussian decoder, and a plug-and-play Gaussian refiner.
- Anchor Prediction: Employs a pretrained MVS network (e.g., MapAnything or MVSAnywhere) to extract camera pose, depth maps, and back-projected 3D geometry from posed or unposed images. The system downsamples the resulting dense point cloud to a sparse set of representative 3D anchors via farthest point sampling (FPS) informed by spatial voxelization.
- Gaussian Decoding: Each anchor is associated with an aggregated set of multi-view image features (including RGB, depth, and camera embeddings), projected and fused in 3D using average pooling. These features are processed by a transformer-based network that predicts Gaussian attributes (mean, scale, rotation, opacity, and SH coefficients). Each anchor predicts multiple nearby Gaussians, enhancing expressivity and completeness of the scene representation.
- Gaussian Refinement: A differentiable module evaluates the rendered outputs against ground-truth RGB and depth, backpropagates the rendering error to each Gaussian’s parameters, and updates attributes using transformer layers. This module is lightweight and plug-and-play, enabling post-hoc refinement without retraining the entire network.
Anchor Alignment and Efficiency
Anchor alignment provides two central advantages:
The plug-and-play Gaussian refiner further sharpens geometric structure and corrects color/opacity inconsistencies that remain after initial anchor-based decoding.
Training Paradigm
The system trains in two stages:
- Stage 1: Trains the anchor-aligned Gaussian decoder with rendering, depth, opacity, and scale regularization losses.
- Stage 2: Freezes the decoder and trains only the Gaussian refiner, using rendering loss for fine-tuning.
Experimental Results
Benchmarking and Comparisons
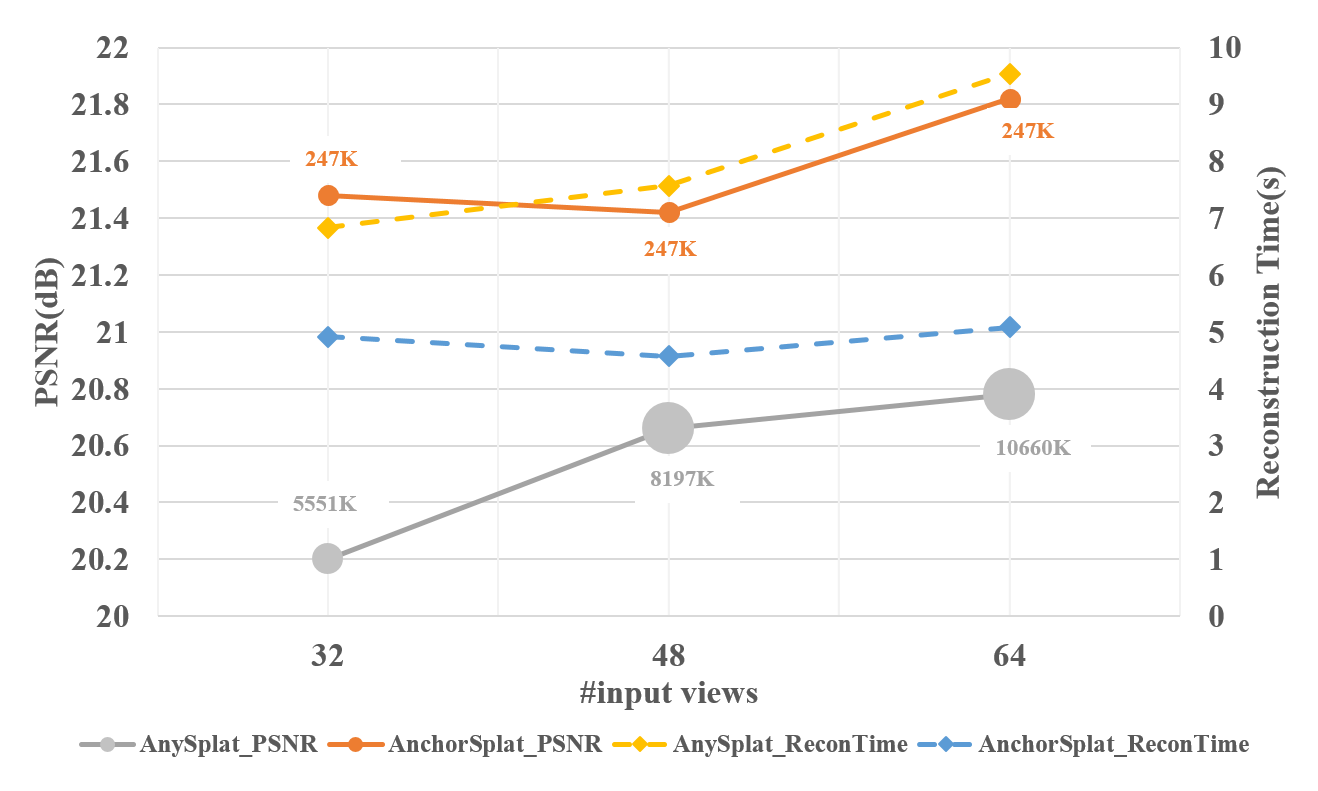
Experiments on the ScanNet++ V2 benchmark and additional datasets (Replica, ARKitScenes, and Tanks and Temples) demonstrate strong improvements in both rendering fidelity and efficiency. Key quantitative results:
Under extremely sparse-view and dense-view settings, the anchor-aligned representation remains compact and stable, whereas AnySplat becomes either under-detailed (sparse) or runs out of memory (dense).
Qualitative Analysis
AnchorSplat delivers sharper, artifact-free geometry with substantially reduced floaters and ghosting artifacts. Across a range of queries—including indoor/outdoor scenes, dense/sparse input, and challenging view extrapolation tasks—the method exhibits consistently superior visual performance and robust depth estimation.

Figure 5: AnchorSplat yields sharper, cleaner renderings with significantly fewer Gaussians and less computation vs. AnySplat.
Application of the Gaussian refiner further improves boundary sharpness and color consistency, especially in occluded or ambiguous areas.

Figure 6: The Gaussian Refiner module fills in missing regions, sharpens object boundaries, and corrects color mismatch.

Figure 7: Across multiple scenes and viewpoints, AnchorSplat outperforms AnySplat and avoids multi-view misalignment artifacts.
Ablation Studies
Several ablations further highlight method robustness:
Implications and Future Directions
AnchorSplat’s anchor-aligned representation regularizes 3D scene encoding across arbitrary numbers of views and scene complexities, suggesting a scalable path for real-world and online multi-view 3D reconstruction. The method’s decoupling of primitive count from image and viewset size directly improves computational efficiency for robotics, augmented reality, and scene-level 3D reasoning. Robustness to view sparsity and scene scale supports practical deployment on resource-constrained settings and dynamic multi-agent systems.
Theoretically, the introduction of strong geometric priors and explicit 3D aggregation mechanisms mitigates view-selection bias, a persistent issue in pixel- and voxel-aligned splatting systems. Unlike prior generalizable 3DGS networks, AnchorSplat supports auxiliary geometric supervision or global priors, opening avenues for joint semantic/geometry learning, dynamic scene modeling, and multi-modal (language, audio) anchor integration.
Future work should address coverage limitations in regions of poor geometric prior, pursue adaptive anchor density control, and explore lifelong/dynamic scene extension with temporally evolving anchors.
Conclusion
AnchorSplat establishes a new anchor-aligned framework for scene-level feed-forward 3D Gaussian Splatting. By leveraging compact and geometry-aware anchors informed by 3D priors—combined with a transformer-based decoder and differentiable refinement module—the method achieves state-of-the-art 3D reconstruction quality, efficiency, and view generalization. Results on established benchmarks solidify its superiority over pixel- and voxel-aligned feed-forward methods, particularly in computation, memory, and geometric reliability. The anchor-aligned paradigm poses significant implications for the scalability of learned 3D scene reconstruction in practical, multi-modal, and dynamic settings.