- The paper presents a feed-forward network that predicts 3D Gaussian primitives and camera poses in a single pass for efficient novel view synthesis.
- It employs a geometry transformer and differentiable voxelization to cluster and reduce per-pixel Gaussians, enhancing multi-view consistency.
- Experiments on diverse datasets demonstrate state-of-the-art performance with reduced rendering latency compared to pose-aware baselines.
AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views
This paper introduces AnySplat, a novel feed-forward network designed for synthesizing novel views from collections of uncalibrated images, addressing limitations in traditional neural rendering pipelines and existing feed-forward methods. AnySplat predicts 3D Gaussian primitives, camera intrinsics, and extrinsics in a single forward pass, enabling efficient scaling to multi-view datasets without pose annotations. The approach demonstrates competitive performance against pose-aware baselines and outperforms existing pose-free methods, while also reducing rendering latency.
Methodological Overview
AnySplat employs a geometry transformer to encode input images into high-dimensional features, which are subsequently decoded into Gaussian parameters and camera poses. A differentiable voxelization module is introduced to merge pixel-wise Gaussian primitives into voxel-wise Gaussians, thereby improving efficiency. The model is trained using a self-supervised knowledge distillation pipeline, leveraging a pre-trained VGGT (Wang et al., 14 Mar 2025) backbone for camera and geometry priors. This enables training without 3D SfM or MVS supervision, relying solely on uncalibrated images. The architecture (Figure 1) consists of a geometry transformer, camera pose prediction, pixel-wise Gaussian parameter prediction, and a differentiable voxelization module.
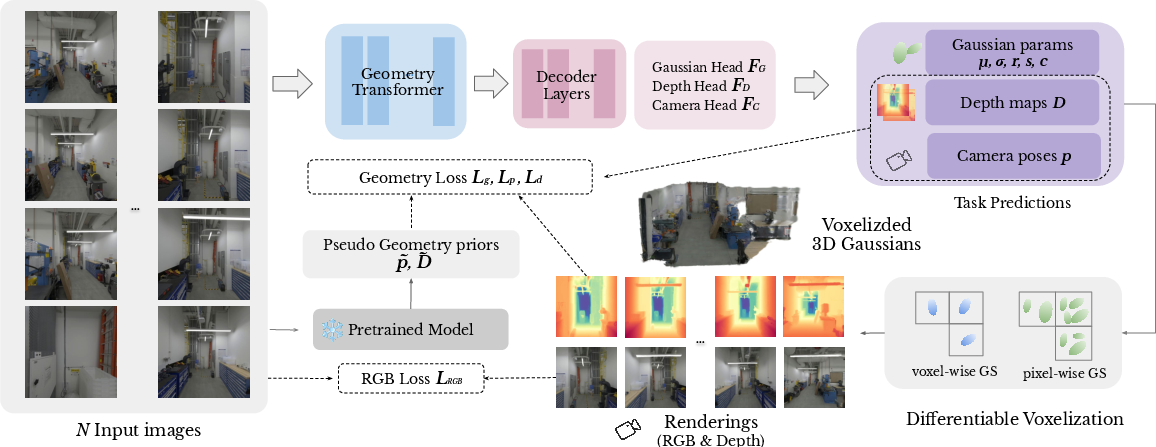
Figure 1: Overview of AnySplat.
The geometry transformer processes input images using a transformer-based architecture, incorporating frame and global attention mechanisms. Camera pose prediction is achieved through a camera decoder that refines camera tokens outputted by the geometry transformer. Pixel-wise Gaussian parameter prediction involves a dual-head design based on the DPT decoder (Alvarez, 2020), predicting per-pixel depth maps and Gaussian parameters. Differentiable voxelization clusters Gaussian centers into voxels, aggregating Gaussian attributes within each voxel to reduce computational cost. This module addresses the linear growth in per-pixel Gaussians under dense views, which can be seen in (Figure 2).
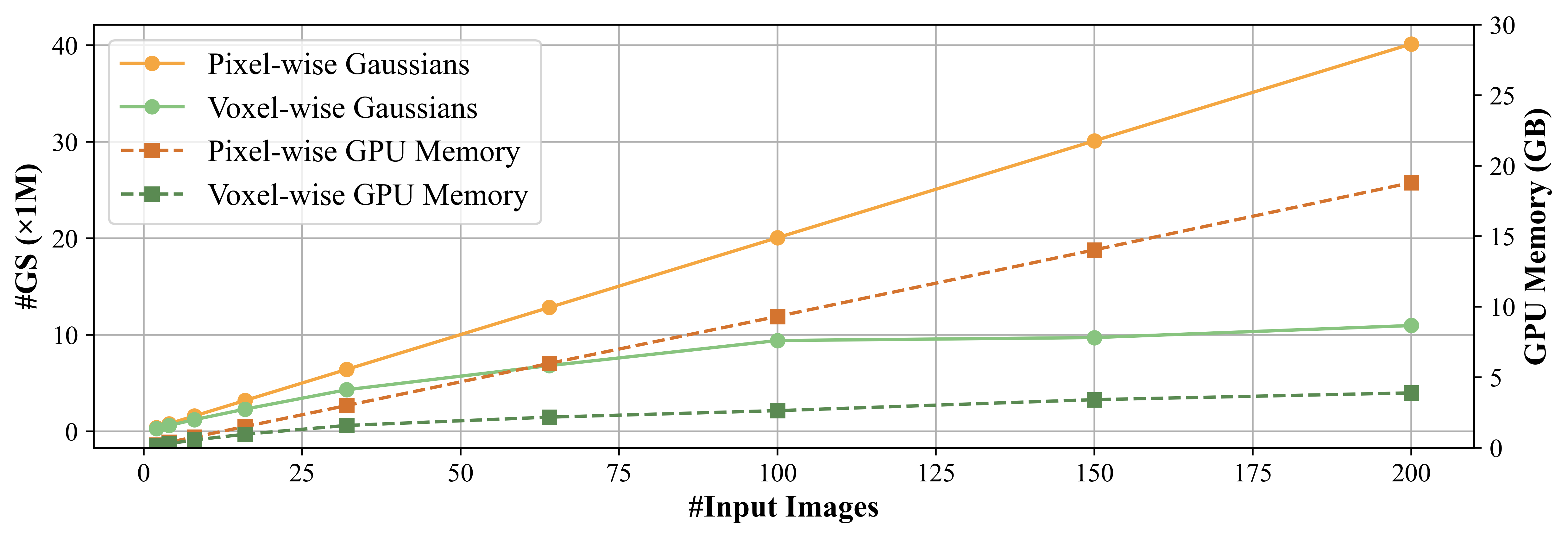
Figure 2: This figure shows the growth of Gaussian Primitives and GPU Memory Usage.
Training and Inference Strategies
A geometry consistency loss is employed to enforce agreement between rendered appearances and underlying depth predictions, mitigating inconsistencies arising from multiview alignment. The loss function, Lg, aligns depth maps obtained from the DPT head with rendered depth maps from 3D Gaussians, focusing on high-confidence pixels as determined by a confidence map. Camera parameters are regularized using a loss function, Lp, that leverages pseudo ground-truth pose encodings from a pre-trained model. Geometric information is distilled using a loss function, Ld, that compares predicted depth maps with pseudo depth maps from the pre-trained model. The overall training objective minimizes a combination of RGB loss, geometry consistency loss, and distillation losses.
During inference, a test-time camera pose alignment strategy is used to address scale inconsistencies between context and target views. An optional post-optimization stage can be applied to further refine reconstructions, particularly in dense-view scenarios.
Experimental Results
The model is trained on nine datasets, including Hypersim (Zouhar, 2021), ARKitScenes (Baruch et al., 2021), BlendedMVS (Johnston et al., 2020), ScanNet++ (McCann, 2023), CO3D-v2 (Langlois et al., 2021), Objaverse (Gupta et al., 2023), Unreal4K (Park et al., 2021), WildRGBD (Młotkowski et al., 2024), and DL3DV (Li et al., 2024), and achieves state-of-the-art rendering performance on sparse-view zero-shot datasets compared to recent feed-forward methods such as NoPoSplat (Ye et al., 2024) and Flare (Zhang et al., 17 Feb 2025) as seen in (Figure 3).

Figure 3: Qualitative comparisons against baseline methods.
In dense-view settings, AnySplat outperforms optimization-based methods such as 3D-GS (Qu et al., 2023) and Mip-Splatting (Nguyen et al., 2023). AnySplat also demonstrates competitive performance in relative pose estimation on the CO3Dv2 dataset, achieving accuracy comparable to VGGT (Wang et al., 14 Mar 2025). Multi-view geometric consistency is enhanced through 3D rendering supervision, as evidenced by improved alignment between rendered depth maps and depth maps predicted by the DPT head. Ablation studies validate the effectiveness of the distillation losses, geometry consistency loss, and differentiable voxelization module.
Conclusion
AnySplat presents a feed-forward 3D reconstruction model integrating a lightweight rendering head with geometry-consistency enhancement through self-supervised rendering and knowledge distillation. The approach demonstrates robust performance on sparse and dense multiview reconstruction and rendering benchmarks using unconstrained, uncalibrated inputs. The low-latency pipeline enables efficient 3D Gaussian Splatting reconstructions and high-fidelity renderings in seconds at inference time.
Future work should address artifacts in challenging regions, improve stability under dynamic scenes, and enhance the scaling to high-resolution inputs. Incorporating diverse real-world captures and high-quality synthetic datasets, enhancing patch-size flexibility, and improving robustness to repetitive texture patterns are promising directions for further research.
