DeepMMSearch-R1: Empowering Multimodal LLMs in Multimodal Web Search
Abstract: Multimodal LLMs (MLLMs) in real-world applications require access to external knowledge sources and must remain responsive to the dynamic and ever-changing real-world information in order to address information-seeking and knowledge-intensive user queries. Existing approaches, such as retrieval augmented generation (RAG) methods, search agents, and search equipped MLLMs, often suffer from rigid pipelines, excessive search calls, and poorly constructed search queries, which result in inefficiencies and suboptimal outcomes. To address these limitations, we present DeepMMSearch-R1, the first multimodal LLM capable of performing on-demand, multi-turn web searches and dynamically crafting queries for both image and text search tools. Specifically, DeepMMSearch-R1 can initiate web searches based on relevant crops of the input image making the image search more effective, and can iteratively adapt text search queries based on retrieved information, thereby enabling self-reflection and self-correction. Our approach relies on a two-stage training pipeline: a cold start supervised finetuning phase followed by an online reinforcement learning optimization. For training, we introduce DeepMMSearchVQA, a novel multimodal VQA dataset created through an automated pipeline intermixed with real-world information from web search tools. This dataset contains diverse, multi-hop queries that integrate textual and visual information, teaching the model when to search, what to search for, which search tool to use and how to reason over the retrieved information. We conduct extensive experiments across a range of knowledge-intensive benchmarks to demonstrate the superiority of our approach. Finally, we analyze the results and provide insights that are valuable for advancing multimodal web-search.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
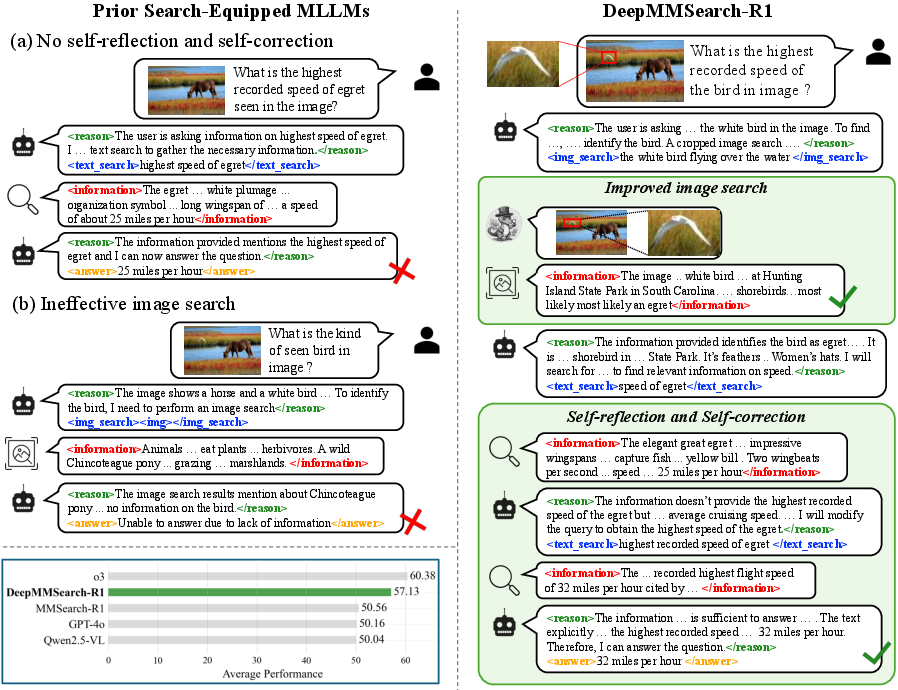
This paper introduces DeepMMSearch-R1, an AI system that can look at pictures, read text, and use the internet to find answers. It’s built to handle tricky, knowledge-heavy questions that normal “multimodal” AI models struggle with—especially questions where the image isn’t enough and the model needs fresh, up-to-date information from the web.
Think of it like a smart online detective: it can zoom into the important part of a picture, decide what to search, change its search words if the first try isn’t good, and combine what it sees with what it reads to produce a better answer.
What questions are the researchers trying to answer?
To make AI better at answering real-world questions, the researchers focused on simple but important goals:
- When should the AI search the web, and when should it rely on what it already knows?
- Which tool should it use: a text search (like a search engine) or an image search?
- How should it write good search queries—and improve them if the first try fails?
- How can it combine what it sees in the image with what it reads online to give the right final answer?
How did they build and train the system?
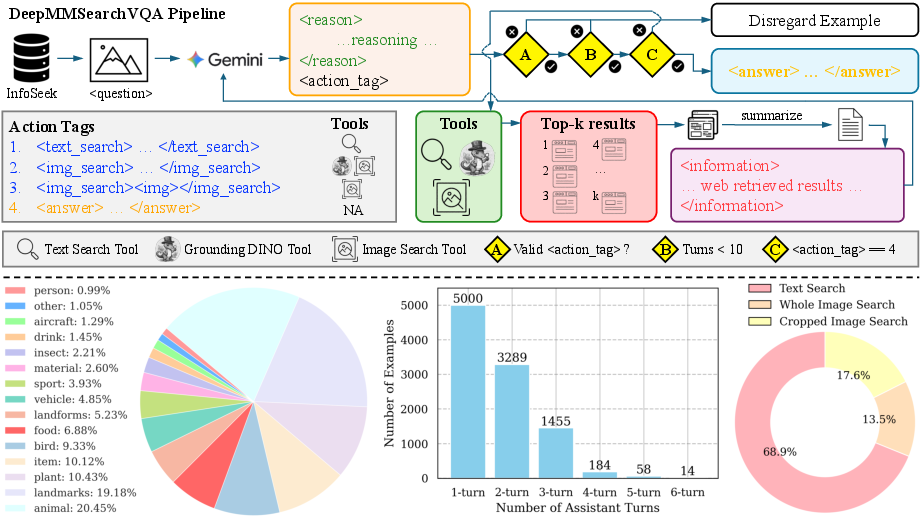
The tools it uses
DeepMMSearch-R1 works with three main tools:
- Text Search: It writes a focused search query (like “Pacu Jalur boat race location”) and reads summarized results from web pages.
- Image Search: It uploads an image (or part of it) to find similar images and descriptions from the web.
- Cropping (“Grounding”): If only part of the image matters (like a logo or a specific object), the model first writes a short description of that part (a “referring expression”), and a tool called Grounding DINO finds and crops that region. Searching with the crop makes results cleaner and more relevant.
This is like taking a photo of a crowd, drawing a box around one person’s shirt logo, and then searching the web only for that logo—so the results aren’t confused by the background.
Training in two stages
The model learns in two steps:
- Supervised Finetuning (SFT): The model is shown many examples of questions, images, tool calls, and reasons. It learns the “rules of the road”—how to decide whether to search, which tool to use, how to write queries, and how to follow a strict output format. This stage starts it off with good habits.
- Online Reinforcement Learning (RL): Here, the model practices by trying different answers for the same question, gets scored, and improves. The specific method, called GRPO, compares several responses in a “mini contest” and teaches the model to prefer the better ones. It also rewards answers that follow the correct format (so tools work smoothly).
A new training dataset
They built a new dataset called DeepMMSearchVQA. It contains:
- Multi-turn conversations (the model searches, reads, thinks, and tries again if needed).
- Structured tags like
<reason>,<text_search>,<img_search>,<answer>, and<information>so the model can clearly show its thinking, tool choices, and final answers. - A balanced mix of questions that need searching and ones that don’t, across many knowledge areas. This helps the model learn not to search when it’s unnecessary, but also to search well when it is.
What did they find?
Here are the main results:
- It beats other strong systems: DeepMMSearch-R1 performs better than several baselines, including models that only use text search or rely on fixed pipelines. It’s competitive with high-end closed systems.
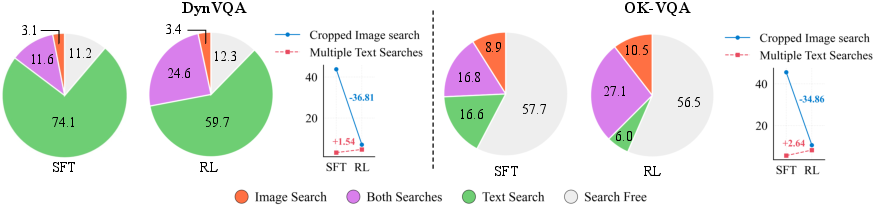
- Cropped image search helps: Searching with a focused crop rather than the whole image improves results, especially when the question is about a single object or detail.
- Self-reflection and self-correction matter: Letting the model try multiple searches and refine queries makes answers more accurate. It learns to adjust its wording based on what it finds.
- Balance is key: Training with a 50:50 mix of “search-required” and “search-free” examples leads to the best average performance. Too much search training makes the model search even when it doesn’t need to; too little makes it miss information when it does need to search.
- Smarter tool use after RL: Reinforcement learning reduces unnecessary tool calls. For example, it stops cropping when the whole image is already useful and increases the use of multiple, refined text searches when that’s helpful.
- General skills are preserved: Even after learning web-search skills, the model keeps its abilities on regular visual question answering tasks (like reading text in images or understanding diagrams).
Why does this matter?
This research makes AI assistants more practical and trustworthy for real life:
- Many questions need fresh, up-to-date information, not just what the model memorized during training.
- Real-world images are messy—zooming in on the right part of a picture improves accuracy.
- Iterative searching and self-correction help the model handle noisy web results and avoid getting stuck.
- The approach can power better educational tools, research helpers, and digital assistants that can “see and read” and then intelligently search the web.
The authors also note ethical care is needed: web content can be biased or wrong, and automatic summaries may amplify errors. Responsible use should include checking sources, filtering content, and human oversight for important cases.
In short, DeepMMSearch-R1 is a step toward AI that can look, read, search, and think—more like how people solve problems online—while being careful, efficient, and up-to-date.
Knowledge Gaps
Below is a single, concrete list of knowledge gaps, limitations, and open questions left unresolved by the paper. Each point highlights what is missing or uncertain and can inform actionable future research.
- Dependence on proprietary components: results rely on in-house text/image search APIs and a closed-source LLM summarizer and judge (gpt-5-chat-latest), limiting reproducibility and making it unclear how performance transfers to open-source retrieval stacks and judges.
- Dataset release and accessibility: DeepMMSearchVQA (10k SFT samples) is introduced but not clearly released; without public data, tool tags, and search traces, independent replication and analysis of tool-use behaviors are constrained.
- Distillation dependence on Gemini-2.5-Pro: training signals (reasoning, tool choices, query forms) inherit biases and potential errors from a single teacher model; no study of how teacher bias propagates to student behavior or how multiple teachers/ensembles would change outcomes.
- Limited SFT data scale and coverage: only 10k curated examples from InfoSeek; unclear how performance scales with more data, more diverse domains (e.g., medical, legal), or non-COCO imagery.
- Language and cultural coverage: model and data appear English-centric; multilingual, cross-cultural entities, and non-Latin scripts are not evaluated, leaving generalization to global settings open.
- Evaluation reliance on LLM-as-judge: correctness is judged by a single closed LLM with a binary score; no human evaluation, inter-annotator agreement, or sensitivity analysis across different judges to ensure robustness and fairness of reported gains.
- Lack of statistical rigor: no confidence intervals, statistical significance tests, or variability analyses across random seeds/rollouts; reported averages may not reflect stable improvements.
- No latency/cost analysis: the approach aims to reduce “excessive” search but does not report end-to-end latency, API call counts per sample, throughput, or monetary cost, preventing assessment of real-world efficiency.
- Efficiency reward shaping: GRPO uses final-answer and format rewards but no explicit cost/latency budget; open question whether adding cost-aware rewards (e.g., penalizing tool invocations or token usage) would optimize utility-cost trade-offs.
- Summarizer bottleneck: retrieval is summarized by a closed LLM; no ablation on summarizer quality, fidelity, compression ratio, or error propagation when key facts are dropped or hallucinated in summaries.
- Retrieval quality metrics: no measurement of retrieval effectiveness (e.g., NDCG, recall@k) for text/image search or how learned queries improve ranked results; retrieval remains a black box.
- Grounding/cropping robustness: cropping depends on Grounding DINO with no analysis of failure modes (occlusion, small objects, clutter) or comparison with alternative grounding/segmenting models (e.g., SAM variants, OWL-ViT).
- Error propagation analysis: no study of how grounding errors or incorrect region selection affect downstream search accuracy and final answers, nor strategies for uncertainty estimation or fallback when grounding is unreliable.
- Tool selection policy transparency: while tool-use rates are reported, there is no fine-grained analysis of decision sequences (e.g., image→text vs text→image), stopping criteria, or how the model decides to terminate search.
- Stopping and over-searching: although RL reduced some unnecessary cropping, the paper lacks a principled stopping policy or calibration study to ensure the model refrains from searching when confident.
- Safety and robustness to adversarial web content: no experiments on prompt injection, misleading pages, SEO spam, or adversarial images; unclear how the model filters, attributes, or cross-checks sources to avoid misinformation.
- Source attribution and citations: the system does not provide citations or provenance with answers; open question whether incorporating source attribution improves user trust and reduces hallucinations.
- Domain and temporal robustness: no evaluation on time-sensitive questions, rapidly changing facts, or explicit “freshness” tests; unclear how the system handles knowledge drift or stale indices.
- Generalization to other tool schemas: the tag schema and tool interfaces are fixed; it is unknown how easily the model adapts to different APIs/tools or expands to new tools (e.g., maps, tables, code executors).
- Model scale and backbone diversity: results are reported for Qwen2.5-VL-7B; no experiments on larger/smaller backbones or non-Qwen architectures to assess generality and scaling laws.
- RL algorithm choices: GRPO is used without comparison to PPO, DPO, RLAIF, or offline preference learning; the impact of different reward models, KL penalties, and rollout numbers remains unexplored.
- Mixed-objective training: the RL reward is binary correctness plus format; no exploration of richer rewards (calibration, uncertainty, citation quality, reasoning faithfulness, or partial credit) that might better guide multi-turn search.
- Faithfulness and reasoning verification: the method distills reasoning traces but provides no evaluation of reasoning faithfulness (e.g., does the cited web evidence actually support the answer?).
- Hallucination and over-reliance on internal knowledge: no direct measurement of hallucination rates, especially when search is skipped; calibration between internal knowledge and external retrieval remains unquantified.
- Benchmarks and selection bias: some evaluations use subsampled test sets (e.g., 2k from InfoSeek/Enc-VQA) without reporting sampling strategy effects or ensuring representativeness.
- Limited category-level error analysis: while a knowledge taxonomy is used for sampling, the paper does not report per-category failure modes or which categories benefit most from cropped image search/self-reflection.
- Long-context limitations: the system depends on summarization to fit within an 8k token limit; no experiments on longer contexts or memory mechanisms to accumulate evidence across many turns/sources.
- Continual learning and updates: no mechanism to adapt the model as the web changes (beyond using live search); open question how to incrementally finetune with new data without catastrophic forgetting.
- Privacy and compliance: web retrieval may surface sensitive content; the paper lacks a concrete filtering pipeline, PII handling, or compliance auditing for high-stakes domains.
- Human-in-the-loop workflows: no study of interactive correction, human feedback on tool use, or integration with preference data to improve reliability in real deployments.
- Transfer to non-VQA tasks: applicability to broader multimodal agent tasks (e.g., shopping, travel planning, scientific assistance) with heterogeneous tools is not demonstrated.
- Release and reproducibility gap: despite a reproducibility statement, reliance on closed APIs, proprietary judges/summarizers, and unspecified dataset availability impedes exact replication by the community.
Practical Applications
Immediate Applications
Below is a concise set of practical, deployable use cases that leverage the paper’s findings—on-demand, multi-turn multimodal search; cropped image search via referring expressions and Grounding DINO; iterative text query refinement (self-reflection/self-correction); and the two-stage SFT+RL training recipe (LoRA + GRPO)—along with sector links, potential tools/products, and key assumptions.
- Retail and e-commerce — visual product identification and enrichment
- Application: Identify products from user-uploaded photos (logos, packaging, variants), auto-fill catalog attributes (brand, model, specs), and source up-to-date pricing/availability with iterative text searches.
- Tools/products/workflows: “Image-to-Product” API with targeted cropped image search; catalog enrichment pipeline using an LLM summarizer of search results; a “tool budget” policy to minimize excess calls (benefiting from RL’s reduction of unnecessary searches).
- Assumptions/dependencies: Accurate grounding (Grounding DINO) for the relevant region; reliable text/image search APIs; mitigation for noisy or misleading web data; privacy controls for user images.
- Advertising and brand safety — logo and asset verification in user-generated content
- Application: Detect brand presence in images, confirm context via iterative search, and flag potential misuse or brand-safety risks.
- Sector: Marketing, social platforms.
- Tools/products/workflows: Brand monitoring dashboard with multimodal search agents and automated summaries of top-5 retrievals; alerting tuned via GRPO to cut redundant queries.
- Assumptions/dependencies: High-quality image search index; policies for rights/copyright and fair use; guardrails for misinformation amplification.
- Journalism and media — rapid image-context verification and fact-checking
- Application: Verify claims linked to images (events, locations, persons) by combining cropped image search with text queries; refine queries upon encountering conflicting sources.
- Sector: Media.
- Tools/products/workflows: Fact-checking toolkit with multi-turn query refinement and source attribution; “Evidence Cards” generated from LLM summarization.
- Assumptions/dependencies: Access to reliable, diverse search indices; source quality assessment; human oversight in high-stakes reporting.
- Education — visual encyclopedic tutors
- Application: Classroom tools that explain objects, landmarks, diagrams, or scientific apparatus in images, pulling recent, vetted information from the web.
- Sector: EdTech.
- Tools/products/workflows: “Visual Knowledge Cards” generator; curriculum-aligned multimodal assistant that uses cropped image search for question-specific focus.
- Assumptions/dependencies: Safe content filtering; constraints for age-appropriate sources; caching to manage latency and cost.
- Customer support — intelligent troubleshooting from photos
- Application: Identify devices/components from user photos, fetch manuals or fix guides via iterative text queries (self-correction when needed).
- Sector: Software/hardware support.
- Tools/products/workflows: Support agent SDK with tool-call schema; workflows enforcing tool-call limits and telemetry for RL-guided efficiency.
- Assumptions/dependencies: Reliable mapping of visual entities to correct manuals; privacy handling for user images; latency SLAs.
- Museums and tourism — landmark identification and contextualization
- Application: Identify exhibits or landmarks from photos and provide rich, current context (history, schedules, events).
- Sector: Cultural institutions, travel apps.
- Tools/products/workflows: Visitor-facing multimodal assistant; auto-generated exhibit “info tiles” updated via web search.
- Assumptions/dependencies: Up-to-date web indices; multilingual support (initially limited unless extended); safe summarization of potentially biased sources.
- Accessibility — object recognition with real-world context
- Application: For visually impaired users, identify objects and provide actionable, current context (usage, safety, alternatives).
- Sector: Accessibility tech.
- Tools/products/workflows: Mobile assistant using cropped image search to reduce noise and improve relevance; on-device prompt templates for concise summaries.
- Assumptions/dependencies: Low-latency inference; transparent safety controls; robust grounding on varied imagery.
- Enterprise knowledge assistants — multimodal RAG alternative with tool-use
- Application: Answer employee questions about visual artifacts (diagrams, dashboards, equipment photos) using web/intranet search without rigid retrieve-then-generate pipelines.
- Sector: Software/enterprise.
- Tools/products/workflows: Multimodal search SDK; governance policies for tool-use tags and logging; LoRA-based fine-tuning to preserve base VQA skills.
- Assumptions/dependencies: Access to internal search indices; data governance; performance monitoring for tool selection efficiency.
- Content moderation — context-aware adjudication of visual posts
- Application: When an image is borderline, perform cropped image search and corroborate context via text queries before automated actions.
- Sector: Trust & Safety.
- Tools/products/workflows: Moderation queue assistant with multi-turn search; confidence scoring integrated with RL rewards (format compliance + correctness).
- Assumptions/dependencies: Human review in critical cases; risk of biased/missing sources; clear policy definitions.
- Software platforms — agent tooling and developer workflows
- Application: Adopt the paper’s structured tool-call schema and prompts; instrument agents with query refinement loops and a cost-aware tool budget.
- Sector: Software/AI platforms.
- Tools/products/workflows: Agent SDK modules (grounding, image search, text search, summarization, GRPO training hooks); telemetry dashboards for tool call reduction.
- Assumptions/dependencies: Availability of summarization LLMs (paper uses gpt-5-chat-latest); reproducible prompts and reward settings; GPU resources (for RL).
- Data and evaluation — dataset generation pipelines and LLM-as-Judge scoring
- Application: Reuse DeepMMSearchVQA approach to build multi-turn, tool-augmented datasets in new domains; adopt LLM-as-Judge for nuanced correctness.
- Sector: Academia/industry research.
- Tools/products/workflows: Automated data curation scripts (balanced taxonomy, 50:50 search-required vs search-free); standardized evaluation prompts.
- Assumptions/dependencies: Dependence on closed-source judge/summarizer (swap with open alternatives if needed); taxonomy curation effort.
Long-Term Applications
These opportunities require further research, scaling, domain-specific validation, or additional tooling (e.g., multilingual expansion, domain-grade search indices, safety/regulatory compliance).
- Real-time AR assistants — “look-and-learn” overlays
- Application: AR glasses that identify objects/landmarks and surface verified, up-to-date information with multi-turn refinement.
- Sector: Consumer hardware, education, tourism.
- Tools/products/workflows: On-device grounding + hybrid edge/cloud search; live summarization streams; offline caches.
- Assumptions/dependencies: Edge inference for latency; battery constraints; robust safety guardrails.
- Robotics and field operations — visually grounded web-guided task execution
- Application: Robots identify tools/parts via cropped image search and fetch procedural knowledge from manuals or forums.
- Sector: Robotics, manufacturing, maintenance.
- Tools/products/workflows: Multimodal agent integrated with robotics stack; safety-aware query loops; tool budget optimized via RL for real-time.
- Assumptions/dependencies: Domain-grade retrieval sources; physical safety validation; closed-loop control integration.
- Healthcare — medication/device recognition with verified clinical context
- Application: Identify medical devices or pill packaging from images and retrieve authoritative guidance (contraindications, recalls).
- Sector: Healthcare.
- Tools/products/workflows: Clinical-grade multimodal assistant; verified medical search indices; audit trails and human-in-the-loop.
- Assumptions/dependencies: Strict regulatory compliance (HIPAA/GDPR); vetted medical knowledge bases (not general web); rigorous evaluation beyond LLM-as-Judge.
- Government and emergency management — rapid mis/disinformation triage from visual evidence
- Application: Validate viral images of disasters or public events with iterative search and source triangulation.
- Sector: Public sector, policy.
- Tools/products/workflows: Crisis-response verification console; provenance tracking; curated whitelists of trusted sources.
- Assumptions/dependencies: Access to reliable source networks; escalation workflows; bias and fairness audits.
- Finance and compliance — visual document verification
- Application: Verify IDs, certificates, or equipment labels via cropped image search and policy-aware text queries (standards, sanctions lists).
- Sector: Finance, compliance.
- Tools/products/workflows: Multimodal KYC/compliance assistant; domain-specific search indices; immutable logging.
- Assumptions/dependencies: PII handling; high-precision false-positive/negative controls; audited models and datasets.
- Energy and infrastructure — asset identification and standards mapping
- Application: Identify components in field images (meters, transformers) and map to standards, maintenance schedules, or recalls.
- Sector: Energy/utilities.
- Tools/products/workflows: Field inspection assistant; search index of standards; RL-tuned query policies.
- Assumptions/dependencies: Specialized knowledge sources; ruggedized devices; human oversight.
- Marketplace integrity — automated listing validation with multimodal search
- Application: Detect counterfeit items by comparing listing images to web evidence; refine text queries to identify anomalies.
- Sector: E-commerce platforms.
- Tools/products/workflows: Counterfeit detection pipeline; query refinement policies; dispute-resolution workflows.
- Assumptions/dependencies: Access to broad image indices; adjudication processes; appeal mechanisms.
- Multilingual, multimodal global assistants
- Application: Expand to multi-language queries and sources; cross-lingual image-text grounding.
- Sector: Global consumer and enterprise apps.
- Tools/products/workflows: Multilingual SFT datasets, taxonomy balancing; language-aware summarization prompts; RL reward adaptation.
- Assumptions/dependencies: High-quality multilingual search; language-specific safety filters; robust evaluation beyond English.
- Domain-curated knowledge graphs from image + text
- Application: Build knowledge graphs by linking visual entities (via cropping) to canonical web/enterprise facts.
- Sector: Enterprise knowledge management, research.
- Tools/products/workflows: Knowledge extraction agent; deduplication and provenance pipelines; graph QA interfaces.
- Assumptions/dependencies: Source reliability; disambiguation quality; maintenance costs.
- Cost-aware agent orchestration and observability
- Application: Platform features that auto-tune tool-call budgets, track group-relative rewards, and optimize for correctness vs latency/cost (production-grade GRPO-like policies).
- Sector: AI platforms, MLOps.
- Tools/products/workflows: Agent observability suite; policy optimizers; A/B testing frameworks for tool-use.
- Assumptions/dependencies: Access to reward models or proxy metrics; robust telemetry; guardrails for drift.
- Safer, audited summarization and evaluation stacks
- Application: Replace closed-source summarizers and judges with audited, open-weight alternatives; build explainability and provenance into summaries.
- Sector: Academia, standards bodies, AI governance.
- Tools/products/workflows: Open evaluation toolkits; explainable summarization prompts; datasets for judge calibration.
- Assumptions/dependencies: Community adoption; baseline agreement on scoring; reproducible pipelines.
- Next-generation assistants with richer tool diversity
- Application: Integrate additional tools (maps, shopping, booking, citations, scientific databases) with the structured tag schema and RL-tuned selection.
- Sector: Consumer and enterprise assistants.
- Tools/products/workflows: Unified tool registry; schema-compliance checkers; long-context strategies for multi-hop reasoning across tools.
- Assumptions/dependencies: Tool standardization; interoperability; scaling of context lengths.
Notes on feasibility across applications:
- The model’s performance and efficiency gains hinge on: (a) accurate grounding and effective cropped image search; (b) high-quality search indices and LLM summarization; (c) RL (GRPO) refinements that reduce unnecessary tool calls while preserving accuracy.
- Safety, governance, and reliability are critical: source attribution, content filtering, human oversight for high-stakes settings, and careful handling of PII/copyright.
- Operational constraints include latency, cost (API calls and inference), rate limits, and the need for balanced SFT datasets (including a 50:50 mix of search-required vs search-free) to avoid over-/under-search behaviors observed in the paper’s ablations.
Glossary
- Bounding box: A rectangular region that localizes a visual entity within an image for downstream processing and retrieval. "yielding a bounding box that is cropped and used as input for retrieval."
- bf16 mixed precision: A 16‑bit floating‑point format (bfloat16) used to accelerate training while maintaining numerical stability. "bf16 mixed precision"
- Causal Language Modeling (Causal LM): The next‑token prediction objective where the model predicts each token conditioned on previously generated tokens. "We adopt the standard Causal Language Modeling (Causal LM) objective."
- Clip ratio: A PPO/GRPO hyperparameter that limits how far the policy can change during updates to stabilize training. "clip ratio of 0.2"
- Cosine scheduler: A learning‑rate schedule that follows a cosine curve to smoothly anneal the learning rate. "cosine scheduler"
- Cropped image search: Retrieving web information using a cropped region of the image that focuses on the question‑relevant entity. "Cropped image search and distilled self-reflection and self-correction capabilities boost performance."
- DeepMMSearchVQA: A multimodal, multi‑turn VQA dataset with tool‑call annotations and web‑retrieved information for training search‑equipped MLLMs. "We introduce DeepMMSearchVQA, a novel dataset containing diverse, multi-hop VQA samples with multi-turn conversations."
- Grounding DINO: A referring‑expression grounding model used to identify and crop the region of interest in an image for targeted retrieval. "we introduce an intermediate image cropping tool, which in our case is Grounding DINO"
- GRPO (Group-Relative Policy Optimization): An RL algorithm that optimizes responses using advantages computed relative to the average reward of a group of rollouts. "The reinforcement learning stage relies on Group-Relative Policy Optimization (GRPO)"
- KL regularization: A penalty based on Kullback–Leibler divergence that constrains the learned policy to stay close to a reference model. "β scales the KL regularization with respect to a frozen reference model."
- LLM-as-Judge framework: An evaluation approach where a LLM assesses the correctness of model outputs against ground truth. "We evaluate model performance using the LLM-as-Judge framework"
- Long-tail distribution: A distribution where many queries are rare and fall outside the model’s core training knowledge, necessitating external retrieval. "many queries in the long-tail distribution"
- LoRA adapters: Low‑rank parameter matrices that enable efficient fine‑tuning of large models without updating all weights. "LoRA adapters with a rank of r=8 across all transformer blocks of the LLM"
- Multi-hop queries: Questions that require chaining multiple reasoning steps and sources to reach an answer. "This dataset contains diverse, multi-hop queries that integrate textual and visual information"
- Multimodal LLMs (MLLMs): Models that process and reason over multiple modalities (e.g., text and images) alongside language modeling. "Multimodal LLMs (MLLMs) in real-world applications require access to external knowledge sources"
- Proximal Policy Optimization (PPO): A reinforcement‑learning algorithm that uses a clipped surrogate objective to stabilize policy updates. "GRPO extends Proximal Policy Optimization (PPO)"
- Referring expression: A concise textual description used to identify a specific visual entity in an image for grounding/cropping. "first generates a referring expression of the visual entity most pertinent to the question"
- Reinforcement learning (RL): A learning paradigm where models optimize behavior through rewards and interaction, here used to refine tool use. "online reinforcement learning (RL) using GRPO algorithm"
- Retrieval-Augmented Generation (RAG): Methods that incorporate external knowledge retrieval into the generation process to improve factuality. "Retrieval-Augmented Generation (RAG) methods"
- Rollouts: Complete trajectories of model interactions and tool calls sampled from the current policy during RL training. "The rollouts are generated from the model checkpoint after SFT."
- Self-correction: The model’s ability to revise or refine its queries/answers based on retrieved feedback. "self-reflection and self-correction"
- Self-reflection: The model’s ability to analyze its own reasoning to decide next actions, including whether and how to search. "self-reflection and self-correction abilities"
- Supervised finetuning (SFT): Gradient‑based training on curated data to initialize and teach the model structured tool use and reasoning. "a cold start supervised finetuning phase"
- Tag schema: A structured output format that encodes reasoning, tool calls, and answers using specific tags for seamless tool integration. "annotated with the tag schema learned during SFT"
Collections
Sign up for free to add this paper to one or more collections.