- The paper introduces FRS as a confidence-conditioned metric that evaluates LLM reasoning on axes such as faithfulness, coherence, utility, and factuality.
- It demonstrates that FRS stabilizes model ranking and exposes reasoning quality gaps that are masked by traditional accuracy metrics.
- FRS provides actionable insights for deployment by predicting when confidence-based selection will enhance or undermine output quality through rigorous benchmarking.
Filtered Reasoning Score: A Confidence-Conditioned Metric for Evaluating LLM Reasoning Quality
Introduction
The evaluation of LLMs on reasoning tasks remains predominantly outcome-oriented, focusing exclusively on whether the final answer is correct. However, answer accuracy does not necessarily track the underlying reasoning quality; models frequently produce correct answers through flawed, degenerate, or even self-contradictory chains of thought (CoT). As progress saturates standard benchmarks, distinguishing true advancements in reasoning from over-optimization and memorization becomes increasingly challenging. This work addresses the critical shortcoming of accuracy-based evaluation by introducing the Filtered Reasoning Score (FRS), a metric designed to assess the quality of a model’s most-confident reasoning traces, thus targeting the alignment between subjective model certainty and process-level soundness.
Reasoning Quality Beyond Accuracy
Accuracy as an evaluation paradigm obscures flaws in the quality of reasoning. The authors employ a rubric-based reasoning score along four key axes: faithfulness (internal consistency), coherence (logical flow), utility (each step contributes to the solution), and factuality (problem-grounded statements). Scoring is performed via a validated LLM-as-a-judge setup, using GPT-4o-mini and cross-checked with GPT-4o, Claude Sonnet 4.5, and human annotators (Spearman ρ=0.73 with human annotation). This systematic, multidimensional assessment reveals that models with similar end-task accuracy often produce traces with divergent reasoning qualities.
Critically, the reasoning score produces more stable and rapidly convergent model rankings than accuracy across a wide sample regime and multiple benchmarks. As demonstrated, accuracy-based rankings fluctuate significantly with evaluation set size, while reasoning scores stabilize quickly (Figure 1).
(Figure 1)
Figure 1: Median across-model standard deviation of score versus evaluation set size; reasoning score exhibits superior sample efficiency and lower variance.
However, even unfiltered reasoning score is insufficient: models with similar average reasoning can show opposite trends as a function of model confidence, which plain averaging masks.
Aggregation via Model Confidence: Motivation for FRS
Deployment practices generally operationalize LLMs through best-of-n selection, often ranking outputs by a confidence proxy such as token log-probability. The unfiltered mean reasoning score, which weights all samples equally, does not reflect deployed behavior. Many low-probability traces, which constitute a substantial fraction of generated rationales, are never surfaced in deployment. Consequently, the metric of primary practical interest is the quality of the reasoning that a model itself ranks highest.
FRS operationalizes this by evaluating the rubric-based reasoning score, not on the pool of all traces, but on the K% most-confident traces by a per-trace confidence estimator: for each problem, multiple traces are sampled, they are ranked by confidence (estimated from low-probability token statistics), and evaluation is restricted to the top K% subset. Reasoning-quality-by-confidence conditioning surfaces structure invisible to accuracy or mean process-based metrics.
This approach exposes critical pathologies: for some models, FRS increases as the confidence filter tightens—high-confidence traces are well-reasoned; for others, FRS drops as filtering tightens—confidence selects for degenerate or redundant solutions. Figure 2 visualizes this effect across representative models.
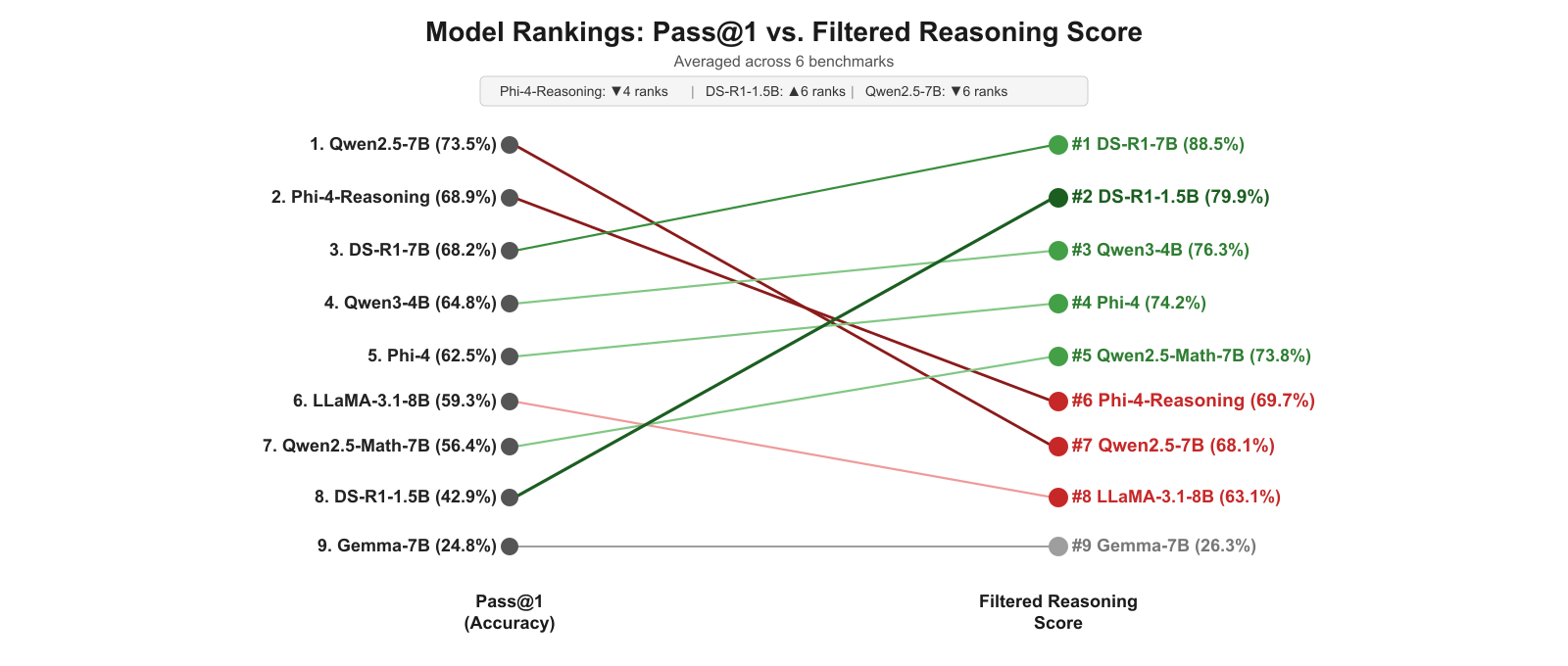
Figure 2: Reasoning quality on the top K% most-confident traces. For some models, restricting to higher-confidence outputs improves reasoning quality; for others, it degrades.
FRS as a Discriminative and Deployment-Relevant Metric
The central findings are that FRS both magnifies and exposes quality gaps masked by accuracy. Notably, among model pairs with <5pp accuracy difference, FRS creates significantly larger separations in over 80% of cases and is maximally discriminative where accuracy is saturated or uninformative.
Moreover, FRS systematically reshuffles the accuracy-based model rankings. For example, Qwen2.5-7B, ranked first by answer accuracy, drops to seventh by FRS, while DS-R1-1.5B jumps from eighth (by accuracy) to second via FRS (Figure 3). This underlines the inability of answer-first metrics to serve as a proxy for what deployed selection policies will actually deliver to users.
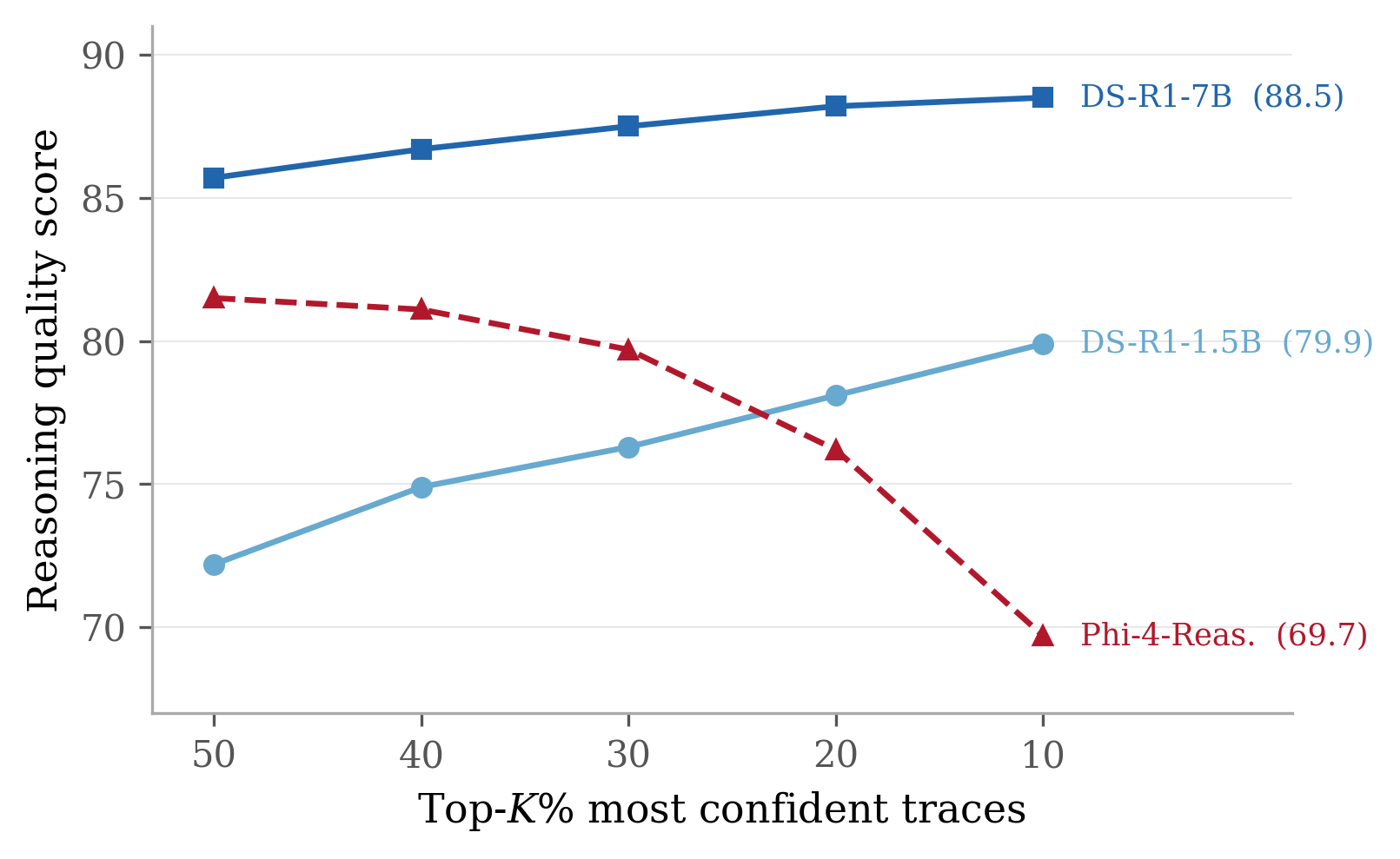
Figure 3: Model ranking reversals under greedy accuracy (left) versus FRS with K=10 (right). Green lines: models that rise by FRS; red: models that fall.
A striking example analyzes two models (DS-R1-7B and Qwen2.5-Math) that are tied on pass@1 accuracy (63.6% on MATH500) but diverge by 16.5 FRS points in the quality of their most-confident traces. Their confidence–reasoning alignment relationships are also reversed, as visualized in Figure 4.
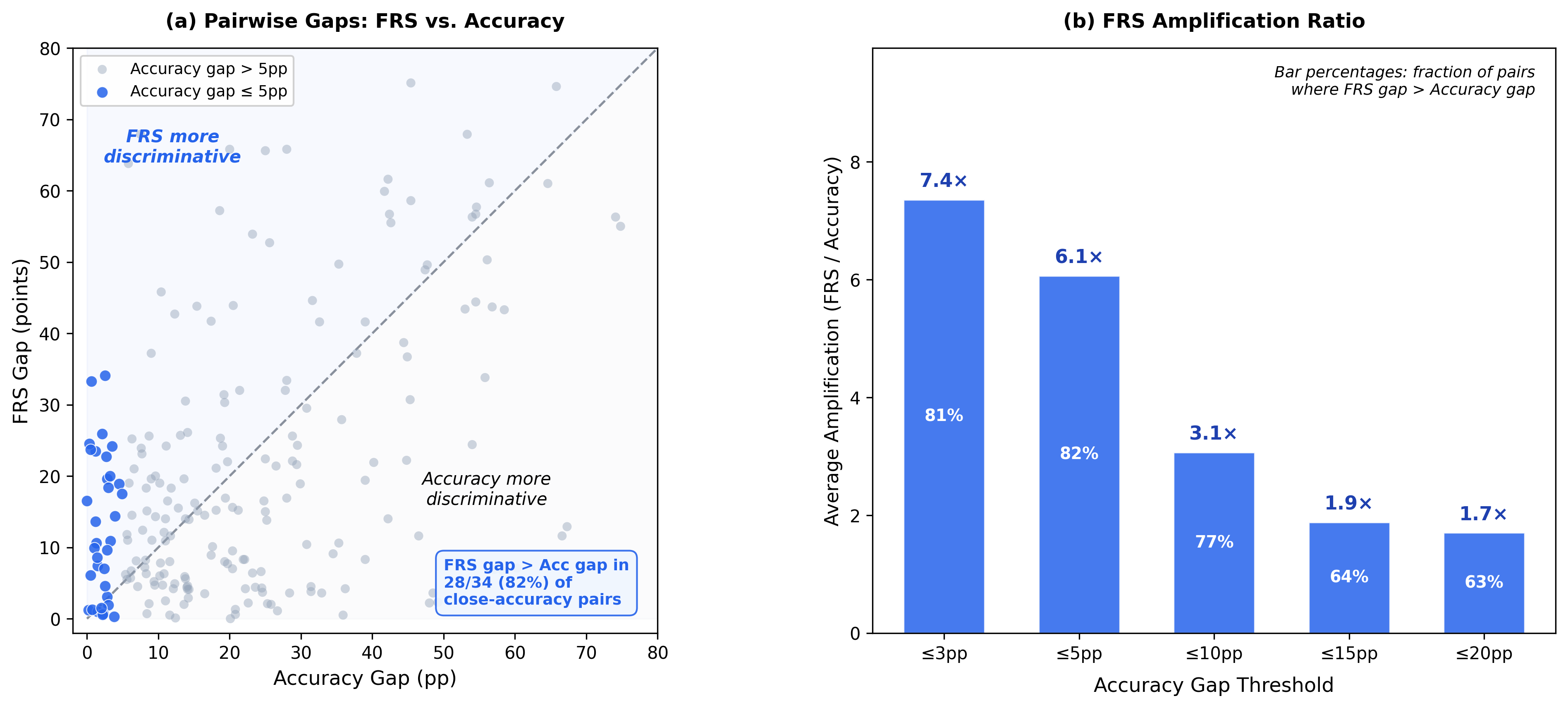
Figure 4: Reasoning quality by confidence bin for two models with matched accuracy; DS-R1-7B’s confidence selects for high-quality reasoning, Qwen2.5-Math’s selects for low-quality reasoning.
Attempting to substitute top-confidence accuracy for FRS is demonstrated to be unsatisfactory; pathological generation patterns (e.g., repetitive, degenerate content at high confidence) can produce superficially high-accuracy outputs that lack sound reasoning.
Methodological Details
- Reasoning Score: Graded on 1–5 along faithfulness, coherence, utility, factuality, averaged and normalized.
- Confidence Estimation: Token log-probabilities are aggregated, focusing on the low-probability tail (bottom 10th percentile), which is empirically validated as the strongest signal for confidence-quality separation.
- FRS Construction: For each benchmark and model, sample k traces per example (k=16), rank by confidence, evaluate the top K%, and average reasoning scores.
This is highly robust to choices of the confidence estimator and judge model. Model-level FRS rankings are stable across alternative token-aggregation schemes and even logit-free estimators such as self-consistency.
Empirical Results
Extensive experiments with 9 open-weight models (1.5B–14B), spanning arithmetic, mathematical, science, and commonsense benchmarks, reveal FRS’s capacity to surface distinctions invisible to accuracy, pass@1, or unfiltered process metrics. The key numerical results include:
- FRS amplifies accuracy gaps 6–7× for closely matched models.
- Model ranking reversals of up to +5/–6 positions compared to pass@1.
- Models with top-confidence traces containing degenerate repetitions (e.g., Phi-4-Reasoning) suffer significant FRS drops despite high top-confidence accuracy.
Furthermore, FRS is shown to be the only metric among six candidates that significantly predicts whether confidence-based selection will improve or degrade practical reasoning quality at deployment (Pearson K%0, K%1).
Cross-Benchmark Generalization
FRS generalizes: its cross-benchmark Spearman correlation is K%2 with accuracy and K%3 with unfiltered reasoning; more importantly, leave-one-benchmark-out analysis shows that FRS measured on five held-in benchmarks reliably predicts FRS on the sixth (K%4 mean), marking confidence–quality alignment as a transferable property rather than a byproduct of a specific benchmark or data domain.
Implications and Future Directions
FRS fills a critical gap in evaluation for confidence-mediated deployment. It enables pre-deployment auditing for the alignment between confidence and reasoning quality, flagging failure modes unseen by accuracy. Empirically, models whose FRS increases under filtering commonly underwent reinforcement learning during tuning, while those with failed alignment did not. This suggests a direction for future research: directly optimizing confidence–quality alignment as an objective, potentially through RL or novel calibration protocols.
Practical deployment can leverage FRS as a diagnostic—if FRS increases with tighter filtering, confidence-based selection improves output quality. If not, confidence may be anti-correlated with sound reasoning, presenting a deployment hazard.
Conclusion
FRS represents a substantive advance in the evaluation of LLMs, recasting the focus from outcome correctness to confidence-conditioned reasoning quality. It robustly identifies model deficiencies unobservable under standard accuracy metrics and provides the only currently available process-based metric that predicts whether confidence-based selection strategies will enhance or undermine practical reasoning quality at inference time. FRS thereby enables both nuanced research evaluation and informed deployment decisions, while exposing underexplored axes of model alignment. Future work should focus on training interventions that directly improve confidence–quality alignment, using FRS not only for evaluation but as a training signal.

