- The paper reveals that multilingual LLMs can produce correct answers through unsound reasoning, with elevated Trace Inconsistency Rates in low-resource languages.
- It introduces a reasoning-awareness framework that decouples answer accuracy from the validity of reasoning traces across six languages, validated by both human and automated methods.
- Findings imply that conventional accuracy metrics may overstate model reliability, urging the adoption of trace-aware evaluations for safety-critical applications.
Reasoning-Answer Misalignment in Multilingual LLMs
Introduction
"Beg to Differ: Understanding Reasoning-Answer Misalignment Across Languages" (2512.22712) presents a systematic investigation into the fidelity of reasoning processes in LLMs across multiple languages and scripts. The core contention of the paper is that standard multilingual evaluation practices, which center on answer accuracy, are insufficient for diagnosing LLM reasoning quality. Through a large-scale, human-validated framework, the work elucidates how LLMs often achieve correct answers via logically unsound reasoning paths, particularly in non-Latin-script and low-resource languages. This misalignment, unaccounted for by mere accuracy scores, poses significant challenges for the reliability and transparency of multilingual LLM deployment.
Experimental Framework
The paper introduces a reasoning-awareness framework that evaluates cross-lingual reasoning-answer alignment, explicitly disentangling accuracy from reasoning trace support. The methodology centers on the following protocol:
- For each multiple-choice question in GlobalMMLU, a model generates both a stepwise reasoning trace and a final answer in a target language.
- The reasoning trace is truncated, withholding the final answer.
- Human annotators and automated evaluators, seeing only the truncated trace, must infer which option is most supported by the reasoning.
- Trace Inconsistency Rate (TIR) is defined as the proportion where the inferred conclusion differs from the model's selected answer.
The framework is applied over 65,000 traces spanning six models and six languages (English, Spanish, Hindi, Arabic, Ukrainian, Korean), stratified by both resource level and script type. All non-English reasoning traces are back-translated into English using a rigorous, high-performance translator pipeline to ensure cross-language comparability.
Empirical Findings
Systematic Reasoning-Answer Misalignment
The key finding is that reasoning-answer misalignment is pervasive and systematically amplified in non-Latin-script and low-resource languages. While accuracy for high-resource languages like English and Spanish approximates 87–89%, with corresponding TIRs of 0.91–3.99%, non-Latin-script languages such as Korean and Hindi display sharply elevated TIRs (up to 13.3% in Korean for Qwen2.5-32B-Instruct) in spite of only moderate drops in accuracy.
This effect is graphically demonstrated by the error taxonomy distributions across languages:
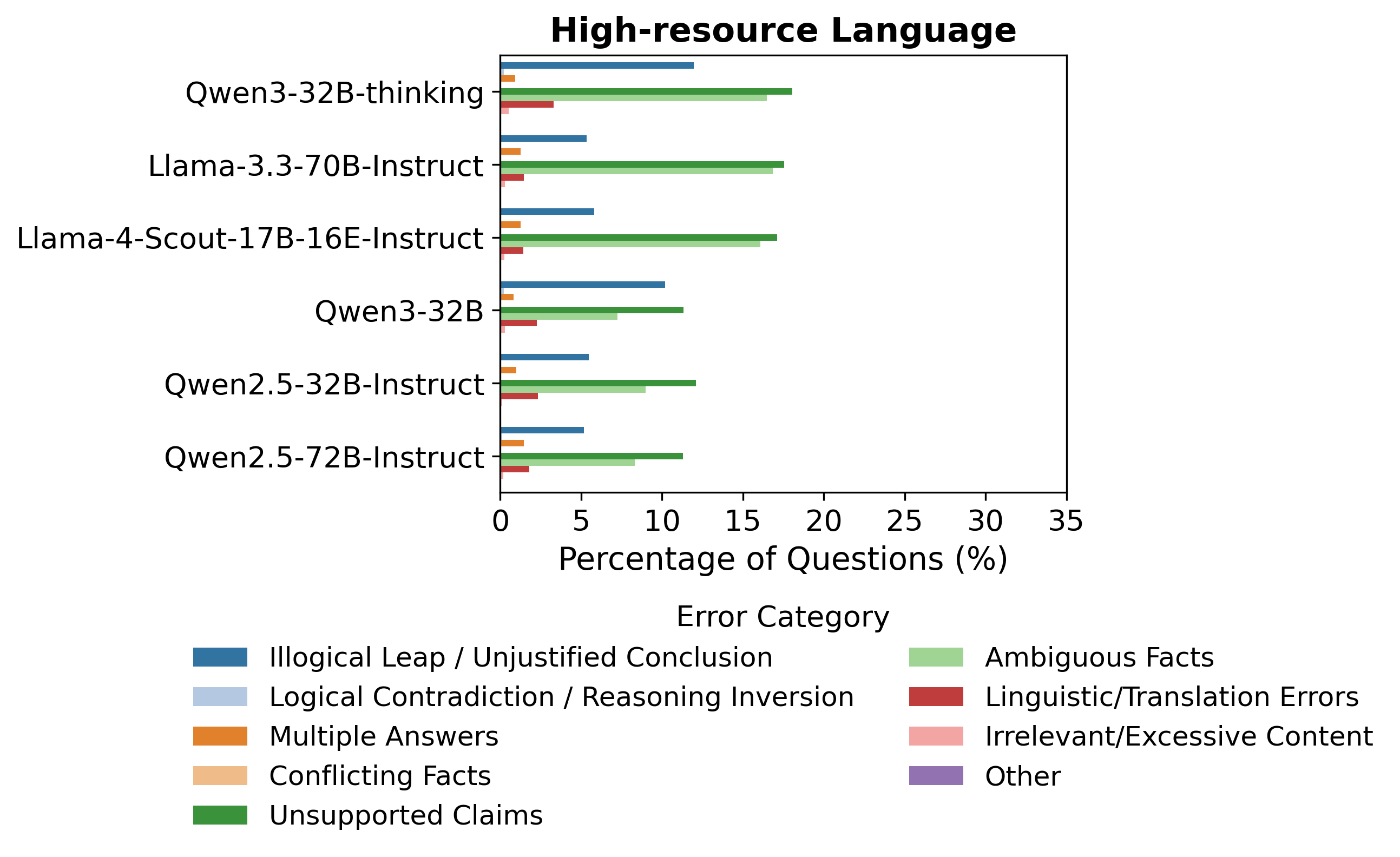
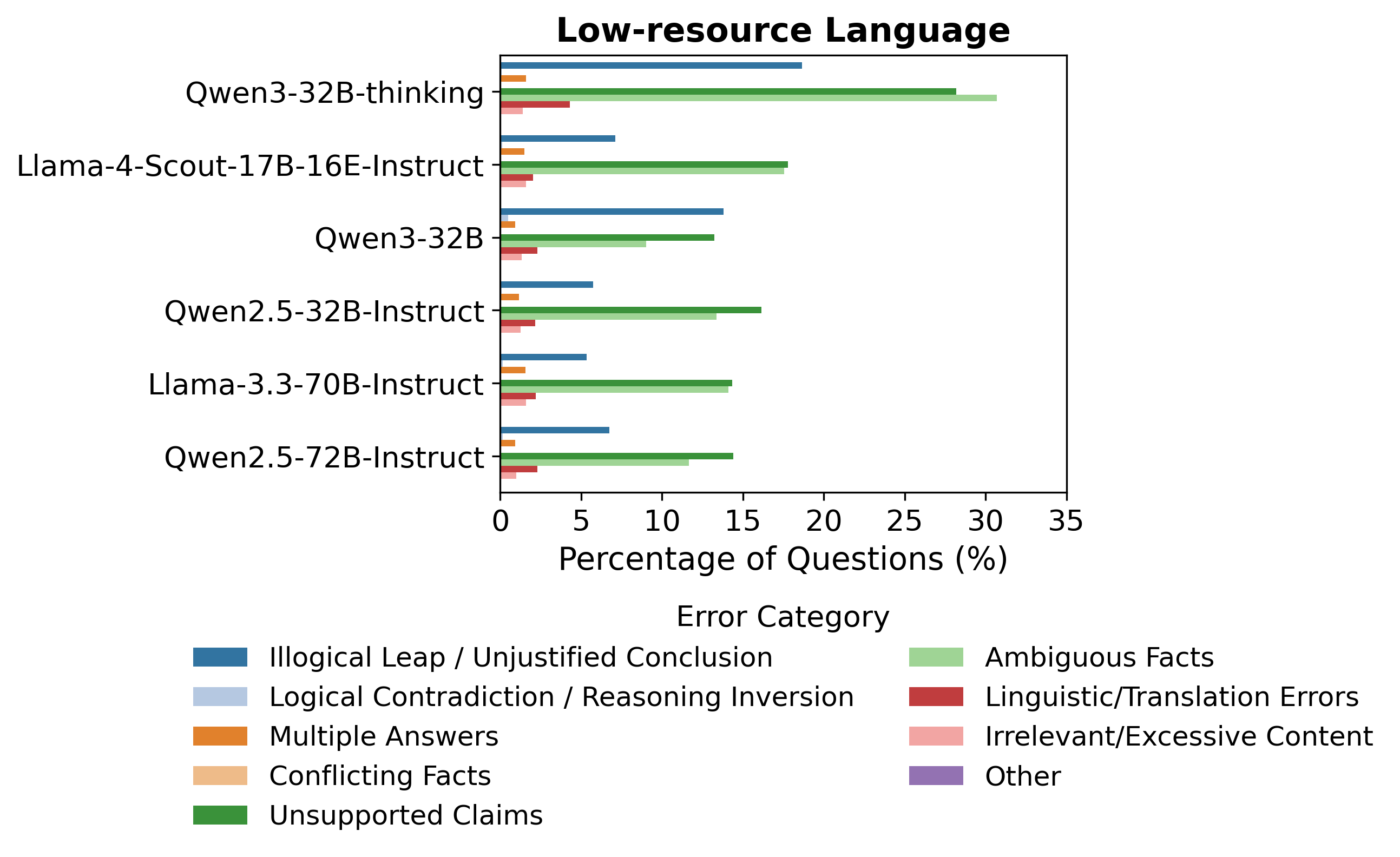
Figure 1: Distribution of detected reasoning trace error types, with unsupported claims and ambiguous facts prevalent and more pronounced in lower-resource languages.
The prevalence of unsupported claims, ambiguous facts, and illogical leaps is significantly higher for models operating on non-Latin or low-resource languages.
Case Analysis: “Right for the Wrong Reasons”
An illustrative example involves models producing correct answers in multiple scripts, but with reasoning traces that fail to justify those answers outside of English input contexts.

Figure 2: Example of reasoning misalignment—correct answers provided in both English and a non-English language, but the reasoning in the non-English example is unsupported.
Detailed trace error analysis reveals that a model might select the empirically correct answer in non-English, but the pathway is marred by evidence-free assertions or logical gaps, a phenomenon unseen when the input is in English.
Human vs. Automated Evaluation
Inter-annotator Cohen’s κ for answer selection reached 0.7, with 80% agreement, validating the reliability of the proposed framework. Automated model-based evaluation via Llama-4-Scout-Instruct agreed with human consensus at moderate-to-strong levels for answer selection and logical trace sufficiency. This automation enables comprehensive large-scale error taxonomy profiling without resorting to costly human annotation for every instance.
Failure Taxonomy
A finely-grained error taxonomy was derived through inductive thematic analysis of annotated traces. The dominant reasoning trace errors identified are:
- Unsupported Claims: Assertions unbacked by explicit evidence.
- Ambiguous Facts: Vague or underspecified statements lacking grounding.
- Illogical Leaps: Reasoning transitions without justified deduction.
- Logical Contradictions: Internal inconsistencies within the trace.
Unsupported claims and ambiguous facts collectively account for nearly 50% of all detected failures, overtaking both illogical leaps and logical contradictions, especially in low-resource scenarios. Model size and instruction tuning (e.g., “thinking” variants) reduce but do not eliminate these error types.
Implications and Theoretical Consequences
These findings challenge the assumption that high accuracy in multilingual settings implies a consistent, transferable underlying reasoning process. The evidence suggests that models develop divergent, language-dependent problem-solving strategies that may not generalize or faithfully reflect valid reasoning across scripts.
Several practical implications follow:
- Evaluation: Standard accuracy-based benchmarks are insufficient for model validation in safety-critical or fairness-sensitive applications.
- Diagnostics/Calibration: High TIR on incorrect answers in certain languages may serve as an early warning for model unreliability.
- Training: Alignment during instruction-tuning and intervention via factuality-promoting objectives must account for language- and script-specific disparities.
From a theoretical standpoint, reasoning trace failures signal that multitask or multitoken alignment objectives do not guarantee cross-lingual faithfulness of internal logical structure; LLMs exhibit distinct latent reasoning pathologies across linguistic axes even when output correctness is preserved.
Future Directions
The study motivates several research frontiers:
- Scaling Human Validation: Extending reasoning-aware human evaluations to a broader set of languages, particularly those with more severe script and data resource limitations.
- Better Reasoning Traces: Developing objectives or prompts that directly supervise trace factual consistency, not merely final output correctness.
- Diagnostic Tools: Automated, fine-grained tools for real-time trace error taxonomy assignment across languages as part of LLM deployment pipelines.
- Faithfulness Adjudication: Exploring how cross-lingual interpretability techniques might bridge misalignment and provide more robust explanations for multilingual users.
Conclusion
This work articulates and quantifies the phenomenon of reasoning-answer misalignment in state-of-the-art LLMs for multilingual tasks, showing that answer accuracy systematically overstates model reasoning integrity, especially outside high-resource, Latin-script contexts. These insights reset expectations on LLM cross-lingual robustness and call for explicit, trace-aware evaluation protocols as a necessary step toward dependable multilingual AI.