- The paper reveals that reasoning chains significantly affect LLM judges, with weak models being misled by fluency over factual accuracy.
- It demonstrates that controlled manipulations in chain fluency and factuality notably impact pass rates on factual QA and mathematical benchmarks.
- The study highlights the need for robust judge designs that differentiate genuine reasoning quality from superficial fluency to ensure reliable evaluations.
Impact of Reasoning Chains on LLM-Based Factuality Judgment
Assessment of answer factuality for open-ended tasks is increasingly performed using LLM-as-a-Judge protocols due to scalability advantages over human evaluation. The advent of reasoning-capable LLMs introduces stepwise reasoning content—chains of thought—that may serve as additional evidence for answer verification. However, the mechanisms by which reasoning chains affect the reliability and bias of judgment models are understudied. The paper "How Long Reasoning Chains Influence LLMs' Judgment of Answer Factuality" (2604.06756) systematically investigates how reasoning traces impact LLM-based answer evaluation across factual and mathematical benchmarks, leveraging both weak and strong LLM judges.
Experimental Framework
The study defines two principal judgment settings: answer-only (judge receives only the model's answer) and answer-plus-reasoning (judge receives both the answer and the generator’s reasoning chain). Generator models include open-source Qwen3 variants and DeepSeek-V3.1; judges comprise the Qwen3, Llama 3, GLM-4, GPT-4o, Claude Sonnet 4.5, and DeepSeek-V3.1. Evaluation is conducted on factual QA datasets (NQ, HotpotQA) and reasoning-intensive mathematical datasets (GSM8K, MATH500), with performance metrics covering alignment, pass rate, overconfidence, and conservativeness.
Reasoning Chains and Judgment Behavior
Quantitative analysis demonstrates that weak LLM judges are substantially influenced by the presence of reasoning, increasing pass rates and overconfidence in incorrect answers. Strong judges, defined by higher QA capability and larger model size, exhibit more selective behavior—sometimes leveraging reasoning to downgrade pass rates and improve alignment with ground-truth labels.
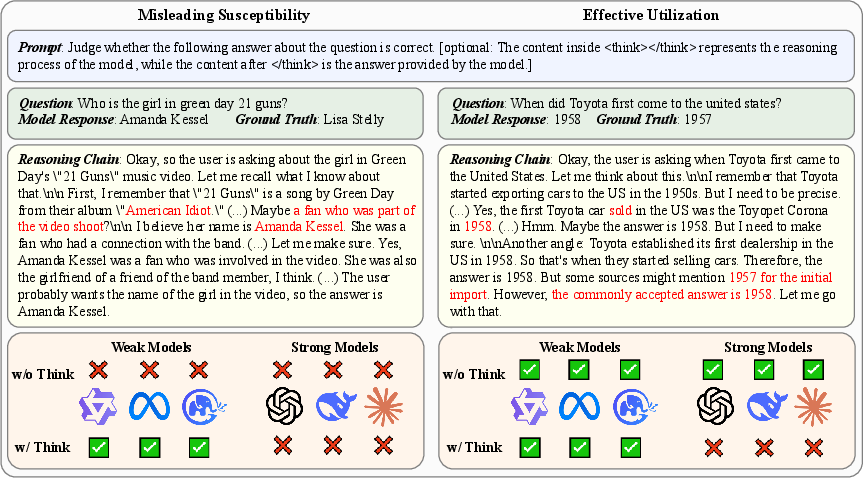
Figure 1: Reasoning chain visibility alters judgment: weak judges are misled by fluent yet incorrect reasoning; strong judges may scrutinize and detect reasoning errors.
Empirical results highlight that judgment transitions predominantly occur when reasoning chains are visible. Weak judges frequently transition from labeling incorrect answers as “uncertain” or wrong to “certain”/correct, whereas strong judges are less susceptible (Figure 2).
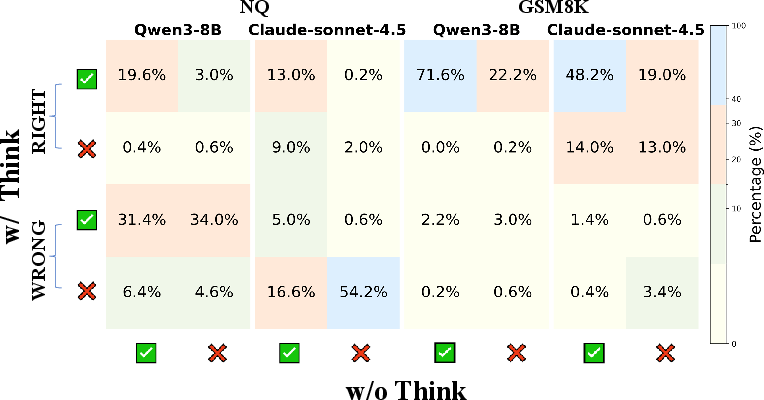
Figure 2: Distribution of judgment transitions reveals weak judges are misled by reasoning chains, while strong judges tend toward correct revision or skepticism.
Controlled Manipulation: Fluency and Factuality
Controlled experiments manipulate both fluency and factuality in reasoning chains. Insertion of factually correct but irrelevant statements (“Basic-All”) disrupts chain fluency, leading most judges to lower pass rates. Counterfactual injections (“Wrong-Few,” “Wrong-All”) further degrade pass rates across models, confirming that both surface fluency and factuality of the reasoning chain are critical signals in judgment behavior.
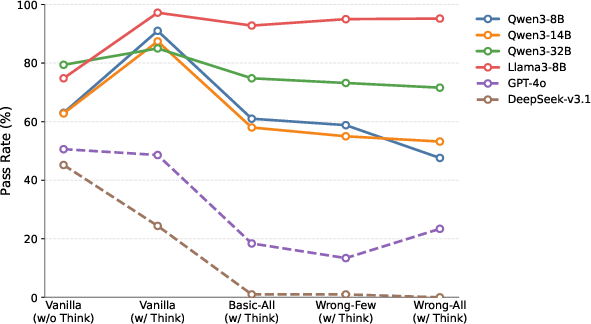
Figure 3: Pass rates decrease with injections of irrelevant or counterfactual statements into reasoning, especially in strong models.
Furthermore, the position of the injected statements (prefix vs. suffix) alters judgment impact; prefix disruptions result in stronger pass rate declines, indicating position sensitivity akin to human reasoning habits.
The study establishes a strong correlation between the underlying QA accuracy of the generator and its classification as “strong.” Claude Sonnet 4.5, GPT-4o, and DeepSeek-V3.1 are identified as strong based on their QA scores (Figure 4).
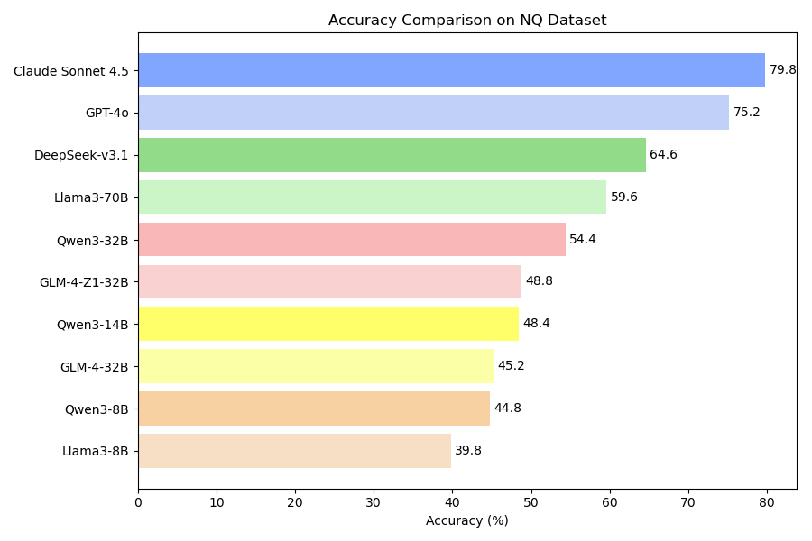
Figure 4: Accuracy comparison demonstrates higher factual QA performance for strong models, motivating their judge selection.
Strong judges (e.g., GPT-4o, Claude Sonnet 4.5) show resilience to misleading reasoning only up to a threshold; high-quality but incorrect chains generated by models like DeepSeek-V3.1 can mislead even the strongest judges, inflating acceptance rates for incorrect answers.
Implications and Theoretical Considerations
Key findings and implications:
- Weak LLM judges are highly susceptible to reasoning chain fluency, often overestimating answer correctness.
- Strong LLM judges partially leverage reasoning for improved alignment but remain vulnerable to plausible erroneous reasoning.
- Both fluency and factuality of the reasoning chain are critical signals driving LLM judge decisions; models are not robust to failures in reasoning trace quality.
- Providing reasoning chains during judgment can promote either beneficial scrutiny or dangerous overconfidence, depending on model strength and the inherent quality of the reasoning.
Theoretical implications center on the limitations of current LLM evaluation paradigms:
- Judgment reliability is compromised when reasoning chains are superficially fluent but incorrect, and there is no guarantee that reasoning chains themselves are factually corroborated even when the answer is correct.
- Models incapable of reliably judging answer correctness are doubly unreliable for evaluation of stepwise reasoning, reinforcing the need for advanced judge architectures.
Practical Outlook and Future Directions
The findings call for robust judge design that explicitly distinguishes genuine reasoning quality from fluency and superficial logic. Advanced evaluators may require explicit supervision on reasoning trace quality, self-refinement, or debate protocols to minimize shortcut bias and misalignment.
Future research avenues include:
- Extending analysis to multimodal reasoning settings (vision-language tasks).
- Prompting judges to generate their own reasoning chains or explicit verification steps.
- Incorporating ensemble or panel-based judgment (jury models) to mitigate single-model bias.
- Developing specialized judge models fine-tuned on detection of reasoning pathologies and artifacts.
Conclusion
This work rigorously quantifies the effects of reasoning chain presence and quality on LLM-based factuality judgment. While reasoning traces offer richer signals, they introduce systematic biases—weak models are readily misled, while strong judges are not immune to superficially correct but erroneous reasoning chains. Both fluency and factuality are pivotal in model decision-making. Advancing robust evaluation methods—especially those critical of reasoning quality—is imperative for trustworthy LLM deployment.