- The paper demonstrates a novel post-training method that leverages synthetic reasoning traces to improve LLMs' reasoning efficiency and accuracy.
- It shows that GPT-OSS traces reduce inference tokens by approximately 4× compared to DeepSeek-R1, offering significant operational benefits.
- Experiments on 242,000 math problems across multiple benchmarks validate the approach and highlight potential cost reductions in real-world applications.
Learning to Reason: Training LLMs with GPT-OSS or DeepSeek R1 Reasoning Traces
Introduction
The paper "Learning to Reason: Training LLMs with GPT-OSS or DeepSeek R1 Reasoning Traces" investigates strategies for enhancing reasoning capabilities in LLMs through the use of synthetic reasoning traces generated by frontier models such as DeepSeek-R1 and GPT-OSS. The authors focus on post-training medium-sized LLMs to learn from these traces, aiming to optimize reasoning efficiency and accuracy without relying on costly human-annotated data.
Background and Methodology
The approach outlined in this study leverages test-time scaling, a method that increases computational resources during inference to improve model accuracy. This enables models to generate intermediate reasoning traces as they work through complex problems. These traces, produced by DeepSeek-R1 and GPT-OSS, serve as high-quality training data for smaller models, helping them develop sophisticated reasoning skills.
In the experiments, the authors sampled 300,000 math problems from the Nemotron-Post-Training-Dataset-v1, analyzing and comparing reasoning traces from DeepSeek-R1 and the GPT-OSS model. Rigorous filtering methods ensured only samples with correct answers from both models were used, resulting in a final dataset of 242,000 samples.
Experimental Setup
Two 12B parameter models were selected as the base for this study: NVIDIA-Nemotron-Nano-12B-v2-Base and Mistral-Nemo-Base-2407. These models underwent post-training using reasoning traces from the aforementioned datasets. The training infrastructure comprised NVIDIA's DGX Cloud Lepton and NeMo Framework to ensure efficiency and scalability during the experiments.
Training was conducted with specific hyperparameters, such as a learning rate of $5e-6$ and a global batch size encompassing approximately $11.5B$ tokens overall. The models were evaluated across benchmarks, including GSM8k, AIME 2025, and MATH-500, using standardized conditions for consistency.
Results
The results demonstrate comparable accuracy across math benchmarks for models trained on both reasoning styles. However, gpt-oss generated approximately 4× fewer tokens during inference compared to DeepSeek-R1, highlighting a significant efficiency advantage.
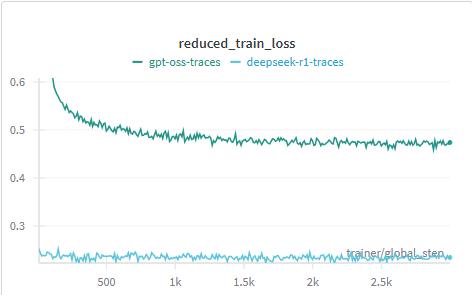
Figure 1: Graph comparing the training loss when fine-tuning Nemotron-Nano-12B-V2 on the two datasets.
The figure illustrates that fine-tuning on DeepSeek-R1 traces resulted in low, stable training loss, whereas gpt-oss traces showed a gradually decreasing loss. This suggests the influence of initial training datasets containing DeepSeek-R1 traces.
Discussion
Although verbose reasoning traces from models like DeepSeek-R1 might intuitively seem beneficial, the study reveals that efficiency gains are achievable without compromising accuracy. Models trained using gpt-oss traces evidenced both fewer tokens and comparable performance, offering a tangible reduction in latency and operational costs in real-world applications.
These findings open avenues for further inquiry into reasoning efficiency across different tasks and prompts exploration of hybrid approaches that blend multiple reasoning styles to achieve optimal balance between verbosity and performance.
Conclusion
The paper effectively contrasts the reasoning styles of DeepSeek-R1 and gpt-oss in training medium-sized LLMs. Both styles demonstrate similar accuracy on challenging math tasks, though impact inference efficiency differently. Understanding these dynamics enhances deployment cost-efficiency and responsiveness in applied settings. This work invites further exploration into integrating diverse reasoning traces in training regimens, contributing to broader advancements in AI reasoning capabilities.