- The paper demonstrates that LLMs reuse discourse tactics nearly twice as often as humans, leading to formulaic and less engaging support.
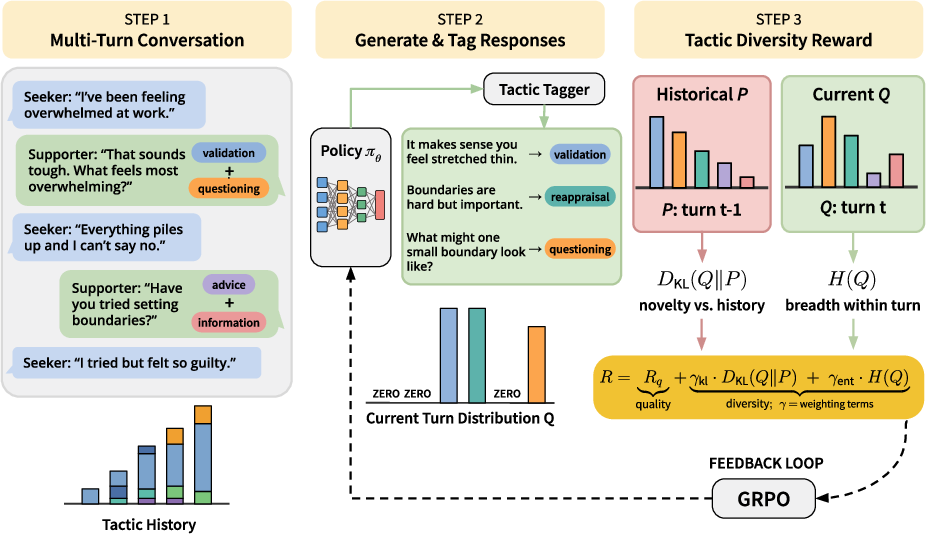
- The paper introduces MINT, a reinforcement learning framework that optimizes cross-turn tactic diversity using KL divergence and entropy measures.
- Experimental results reveal a 26.3% drop in tactic stickiness and a 25.3% empathy quality boost, closely aligning LLM behavior with human conversational dynamics.
Discourse Diversity in Multi-Turn Empathic Dialogue: Technical Summary
Problem Framing and Motivation
LLMs have achieved state-of-the-art human-perceived empathy in single-turn empathic dialogue settings. Despite fine-tuning for support tasks, empirical analyses demonstrate that LLMs’ outputs become increasingly formulaic, reusing not only lexical and syntactic constructions but also repetitive discourse moves (categories such as advice, validation, questioning) at substantially higher rates than human supporters. Empathic support in multi-turn dialogue, however, demands more than isolated warmth; it requires strategic variation and responsive adaptation to the seeker’s evolving needs over the course of the conversational arc. Previous work analyzed repetitiveness only in single-turn or short horizon setups; this study extends the scope to full multi-turn human–LLM dialogues using a rigorous, psychology-grounded taxonomy of empathy tactics.
Quantitative analysis reveals that, in actual emotional support conversations, LLMs repeat their previous turn’s tactics with a probability of 0.50–0.56—nearly double that of humans (0.27)—a disparity invisible to standard surface-form and semantic similarity metrics. This rigidity undermines quality of interaction and impacts user re-engagement, as confirmed by negative correlations between tactic stickiness and user satisfaction in held-out SENSE-7 data. These findings highlight a critical deficiency: procedural empathy in LLMs lacks cross-turn strategic diversity, which is integral for credible, sustained emotional support.
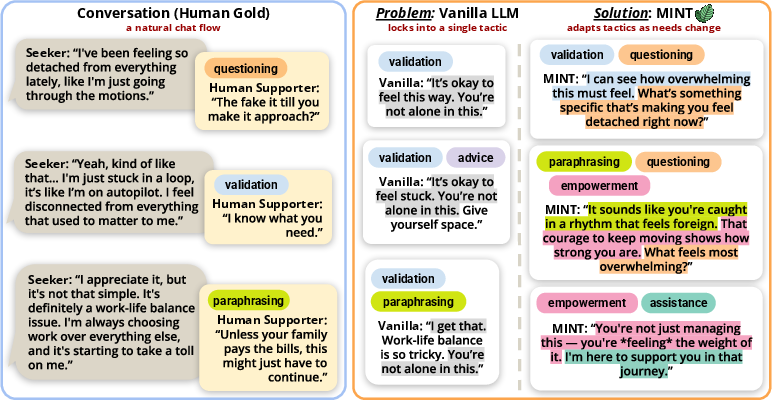
Figure 1: As the seeker’s needs evolve, vanilla LLMs recycle a narrow tactic set, whereas MINT adapts its discourse moves across turns.
Empathy Tactic Taxonomy and Analysis
The foundation for empirical investigation is a granular, codified taxonomy of ten empathy tactics derived from psychological literature (validation, advice, questioning, information, paraphrasing, reappraisal, empowerment, self-disclosure, emotional expression, assistance). Tactics are annotated at the sentence level by human experts, with inter-annotator F1 averaging 0.80, and then used to fine-tune Llama3.1-8B adapters for large-scale automatic tactic detection.
Applying these taggers to two large public multi-turn support corpora (WildChat, SENSE-7) and a human–human evaluation benchmark (Lend-an-Ear), the study examines both tactic prevalence (use within a turn) and stickiness (reuse from turn to turn). LLMs show marked over-reliance on advice and information (up to 89% and 80% of turns, respectively), underuse questioning (as low as 25% vs. 42% for humans), and display the highest stickiness for the most overused tactics, creating a self-reinforcing loop of repetitive support moves.
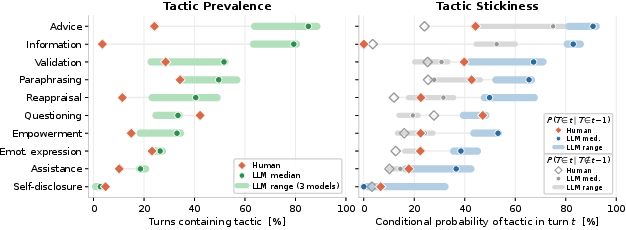
Figure 2: Left: Tactic prevalence per turn—the overuse of advice/information and underuse of questioning by LLMs. Right: Tactic stickiness—LLMs are much more likely than humans to repeat a tactic used in the previous turn.
Lexical overlap (bigram, BLEU-2) and semantic similarity (BERTScore) between consecutive turns do not distinguish LLMs from humans in this dimension, underscoring that tactic-level analysis is required for diagnosing and mitigating formulaicity at the discourse function level.
MINT: Multi-turn Inter-tactic Novelty Training
To address excessive cross-turn tactic repetition, the authors propose MINT (Multi-turn Inter-tactic Novelty Training), a reinforcement learning (RL) framework explicitly optimizing for diversity of discourse move trajectories over dialogue history. The MINT reward augments traditional empathy quality signals with a quantitatively defined cross-turn tactic diversity objective. Specifically, for policy πθ:
Experimental Results: Efficacy of Cross-Turn Diversity
Rigorous ablation experiments using Qwen3-1.7B and Qwen3-4B LLMs compare MINT against:
- Standard prompt enhancements (system prompting with tactic definitions and usage history).
- Inference-time diversity methods (Verbalized Sampling).
- Quality-only RL (PsychoCounsel reward).
- Token-level entropy-based diversity RL (R1-Zero-Div).
Evaluations use two orthogonal axes: (1) multi-dimensional empathy quality assessed turn-wise via Lend-an-Ear (with gpt-oss-120b judge, κw=0.58 to expert median), and (2) tactic stickiness (measuring minority class performance against human reference).
Empathic quality improves substantially with MINT: average aggregate empathy up by 25.3% over Vanilla, and up to 4.67 on a 5-point scale for 4B models. Critical, however, is a 26.3% reduction in tactic stickiness—a generalization unattainable by quality-only or token-level diversity RL, confirming that diversity must be promoted at the level of discourse function, not just token sequence. MINT yields fewer tactics per turn than token-entropy baselines but much greater cross-turn adaptation, closely matching human tactical dynamics. An illustrative outcome is the dramatic (up to 44.8%) decrease in unsolicited advice and near doubling of elicitation tactics such as encouraging elaboration compared to prompt baselines.
Qualitative analysis further demonstrates that MINT-generated supporter turns natively eschew templated reassurance and hollow advice in favor of contextually novel, targeted moves—guiding conversational flow more adaptively as in human expert support.
Implications and Future Directions
This work establishes that LLMs’ current deficits in multi-turn emotional support stem from repetitive discourse maneuvering, not from a lack of surface empathy. The MINT framework opens the door to integrating measurable, learnable cross-turn discourse diversity objectives in RL-based model tuning.
Theoretically, attention to discourse function diversity moves evaluation and optimization beyond surface-level similarity measures, calling for function-level benchmarking in all dialogue-based LLM assessment protocols. Practically, strategic diversification of discourse tactics enables LLMs to sustain human engagement and credibility in support scenarios, likely generalizing to non-empathic open-domain conversation and other sequential decision-making tasks with long-horizon interactional structure.
Extensions may include joint optimization of diversity with personalized user-adaptive policies, live deployment with real user feedback, and refinement or expansion of tactic taxonomies for richer human–AI conversational interplay. The technical stack (publicly released data, code, and high-fidelity taggers) forms a replicable pipeline for cross-lab benchmarking.
Conclusion
Discourse move diversity is both measurable and optimizable at the level of RL training objectives. The MINT framework demonstrates that anchoring diversity at the tactic function level, and not merely surface form, enables LLMs to more convincingly emulate the adaptive, responsive strategies of skilled human supporters across the arc of a dialogue. These findings demand future conversational AI research to foreground discourse function diversity as a core metric for effective, sustained interaction.