- The paper demonstrates that LLMs reliably produce templated empathic responses using formal regular expression patterns with coverage up to 90%.
- Methodologies include a taxonomy of ten empathic tactics applied to thousands of responses, highlighting stark differences between AI and human diversity.
- Findings suggest that while AI-generated empathy is well-liked, its formulaic nature may shift human communication norms and impact emotional support practices.
Authoritative Summary of "AI generates well-liked but templatic empathic responses" (2604.08479)
Overview
This paper examines the linguistic structure and discourse-level patterns of empathic responses generated by LLMs, contrasting them with those written by humans. It introduces a taxonomy of ten empathic language tactics, systematically applies this taxonomy to thousands of responses across multiple studies, and demonstrates that LLMs overwhelmingly produce well-liked but highly templatic empathic language. By formalizing regular expression templates for tactic usage, the authors expose both the high coverage (up to 90%) and within-response homogeneity of LLM responses, with significant divergence from the diversity and flexibility of human-written empathy.
Taxonomy and Methods
The authors derive a taxonomy of ten empathic response tactics—validation, paraphrasing, emotional expression, empowerment, information provision, reappraisal, self-disclosure, advice, assistance, and questioning—grounded in psychological and linguistics literatures. Responses to support-seeking Reddit posts were collected from both human writers (psychology-trained Upworkers and Redditors) and six LLMs spanning GPT-4 family, Llama3, and Qwen. Annotation of tactic usage was performed manually in Study 1 and at scale via LLM-judged few-shot prompts in Study 2, achieving high inter-rater reliability.
Empathic Tactic Prevalence and Diversity
LLMs use a concentrated subset of tactics, principally paraphrasing, validation, advice, and information, in nearly every response. Human writers exhibit broader tactic diversity, including frequent self-disclosure and contextually adaptive questioning and assistance.
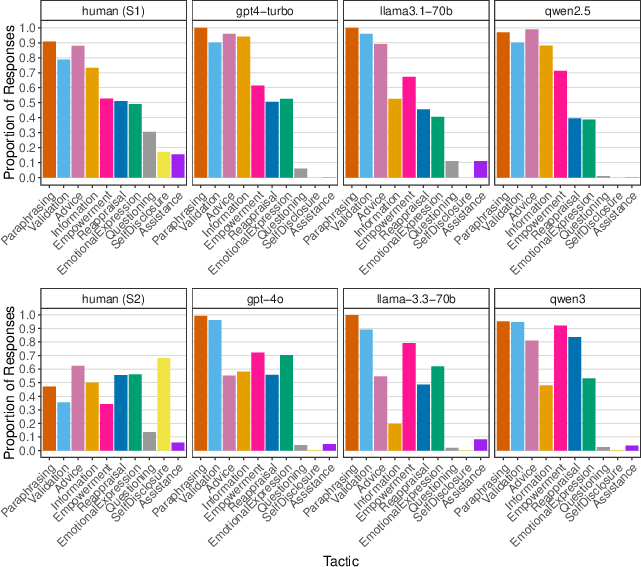
Figure 1: Distribution of unique empathic tactic usage across writers in Study 1 (top) and Study 2 (bottom), highlighting LLM concentration versus human diversity.
LLMs' tactic distributions are highly consistent both within and across model families (rhuman−gpt = .98, rhuman−llama = .94, rhuman−qwen = .97), and model versions, while humans vary markedly across cohorts and contexts (Upworkers vs. Redditors, rhuman:s1,s2 = .37). Notably, self-disclosure is nearly absent from LLMs by design, contrasting with substantial human prevalence, especially in more informal online settings.
Templatic Discourse Patterns in LLM Responses
The discourse structuring of LLM responses is highly regularized. Through formal regular expression templates, the authors demonstrate that the overwhelming majority of LLM responses conform to a reiterative sequence: initial paraphrasing and validation, interspersed with emotional expressions and empowerment, followed by cycles of advice and information, further cycles of validation, emotional expression, empowerment, and reappraisal, then advice and information again. Successive refinement of these templates leads to coverage upwards of 90% across LLM responses and 81–92% within those matched responses, greatly exceeding human template conformity, which ranges from 6–40%.
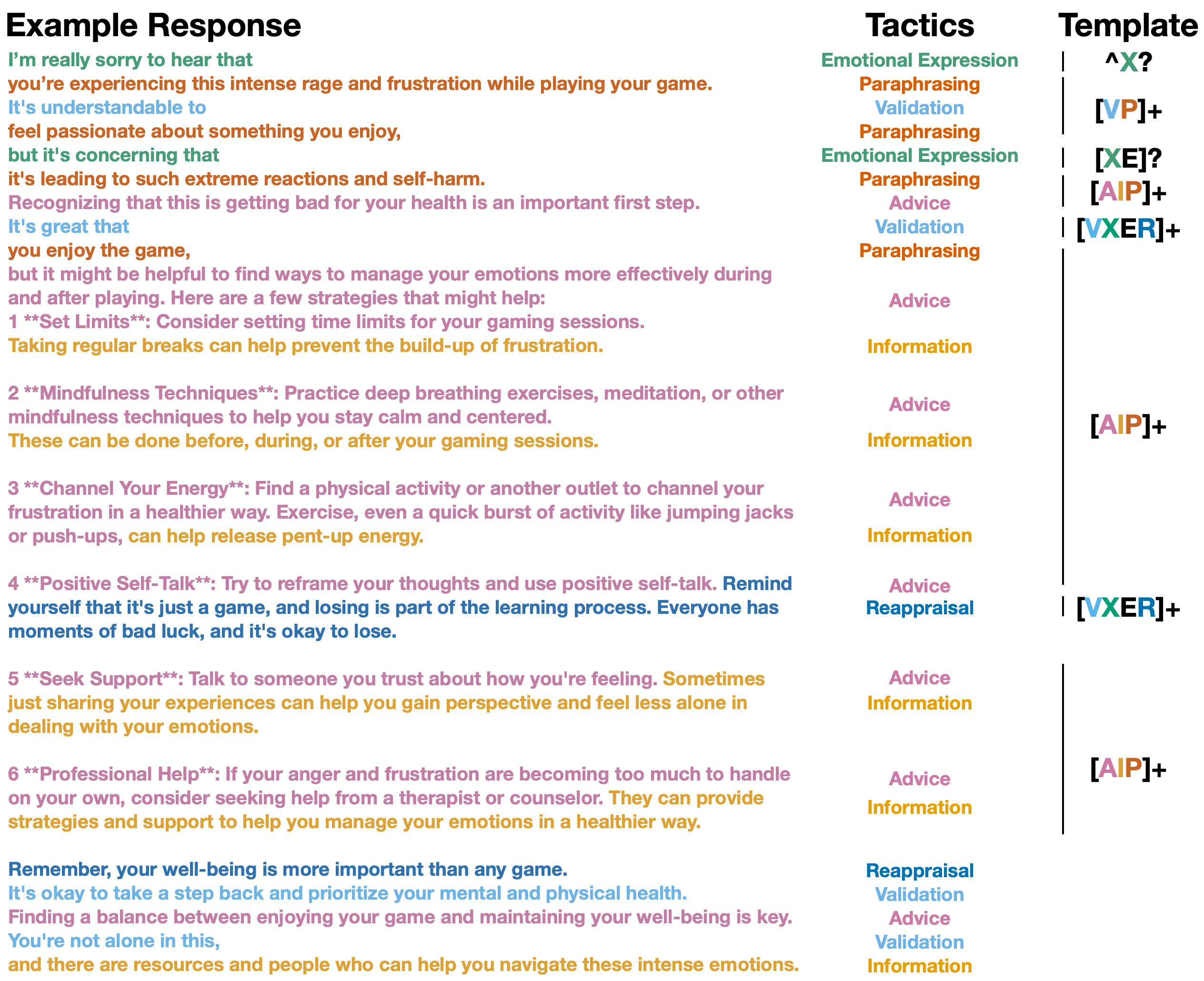
Figure 2: An example GPT-4 Turbo response with annotated tactic sequence, mapping to Template Pattern 5 (matches 80.8% of response).
These templates generalize robustly across datasets and LLM generations, with negligible sensitivity to training data variations. Conversely, human responses show significant idiosyncrasy and context-driven adaptation, further emphasizing the LLMs' tendency toward standardization.
Implications for AI-Driven Empathic Communication
Numerical Highlights
- LLM responses: up to 90% matched by a single template; coverage within matched responses up to 92%.
- Humans: template matched in only 6–40%; coverage within matched responses similar, reflecting occasional imitation or training.
Claims
- LLMs reliably produce formulaic empathic responses aligning with a well-liked, effective template.
- Human-written empathic responses are structurally more diverse and contextually nuanced.
- AI exposure may precipitate homogenization of empathic language, potentially influencing human expectations and communication norms.
Practical and Theoretical Consequences
LLMs have captured a "modal" empathic template, perceived as highly empathic by recipients. This consistency facilitates rapid, scalable emotional support, and suggests opportunities for AI-driven empathy coaching and communication training (cf. [sharma2023human], [kumar2026practicing]). However, the lack of context sensitivity and diversity raises concerns regarding AI sycophancy, attitude extremity, risk of maladaptive outcomes, and reduction in human creative ideation ([rathje2025sycophantic], [anderson2024homogenization], [doshi2024generative]). Further, repeated exposure to templatic AI-generated empathy may shift social expectations, pressuring conformity and diminishing interpersonal nuance.
The findings also intersect with broader theoretical debates about the nature and credibility of AI empathy. Despite psychological theories positing AI's inability to authentically empathize (cf. [perry2023ai]), empirical results consistently show recipients rating LLM responses as more empathic than human ones ([ong2026ai], [howcroft2025ai], [lee2024large]).
Future Directions
The authors underline several avenues:
- Cross-cultural and demographic adaptation: Future work should assess how empathic templates perform across varied recipient backgrounds ([malik2025llms]).
- Prescriptive recommendations: Investigating effective empathic discourse strategies and their impact on well-being.
- AI as empathy intervention: Leveraging AI tools for human empathy training, and studying downstream effects on language diversity, creativity, and mental health.
Conclusion
The paper establishes that LLMs generate empathic responses which are highly consistent, well-liked, and structurally templatic, as formalized through regular expression patterns. This regularity sharply contrasts with human diversity and context-responsiveness. The results have important implications for the role of AI in emotional support, empathy coaching, and broader sociolinguistic trends. While template-driven responses offer advantages in standardization and perceived empathic quality, they pose risks of context insensitivity, sycophantic behavior, and cultural homogenization, motivating ongoing research and thoughtful deployment in AI-mediated communication.

