Practicing with Language Models Cultivates Human Empathic Communication
Abstract: Empathy is central to human connection, yet people often struggle to express it effectively. In blinded evaluations, LLMs generate responses that are often judged more empathic than human-written ones. Yet when a response is attributed to AI, recipients feel less heard and validated than when comparable responses are attributed to a human. To probe and address this gap in empathic communication skill, we built Lend an Ear, an experimental conversation platform in which participants are asked to offer empathic support to an LLM role-playing personal and workplace troubles. From 33,938 messages spanning 2,904 text-based conversations between 968 participants and their LLM conversational partners, we derive a data-driven taxonomy of idiomatic empathic expressions in naturalistic dialogue. Based on a pre-registered randomized experiment, we present evidence that a brief LLM coaching intervention offering personalized feedback on how to effectively communicate empathy significantly boosts alignment of participants' communication patterns with normative empathic communication patterns relative to both a control group and a group that received video-based but non-personalized feedback. Moreover, we find evidence for a silent empathy effect that people feel empathy but systematically fail to express it. Nonetheless, participants reliably identify responses aligned with normative empathic communication criteria as more expressive of empathy. Together, these results advance the scientific understanding of how empathy is expressed and valued and demonstrate a scalable, AI-based intervention for scaffolding and cultivating it.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question with a big impact: Can practicing with an AI “chat partner” help people learn to sound more caring and understanding when someone shares a problem? The authors built a practice platform called “Lend an Ear,” where people chatted with an AI that pretended to be going through tough situations. They tested whether quick, personalized coaching from the AI could teach people to communicate empathy better.
What questions did the researchers ask?
The study focused on a few clear questions:
- Can short, personalized feedback from an AI coach help people express empathy more effectively than no coaching at all?
- Is AI coaching better than watching short, general advice videos?
- Do people who feel empathic on the inside actually show it in their words?
- Do outside observers agree that the “better” conversations (according to expert rules) really feel more empathic?
How did they study it?
The practice platform
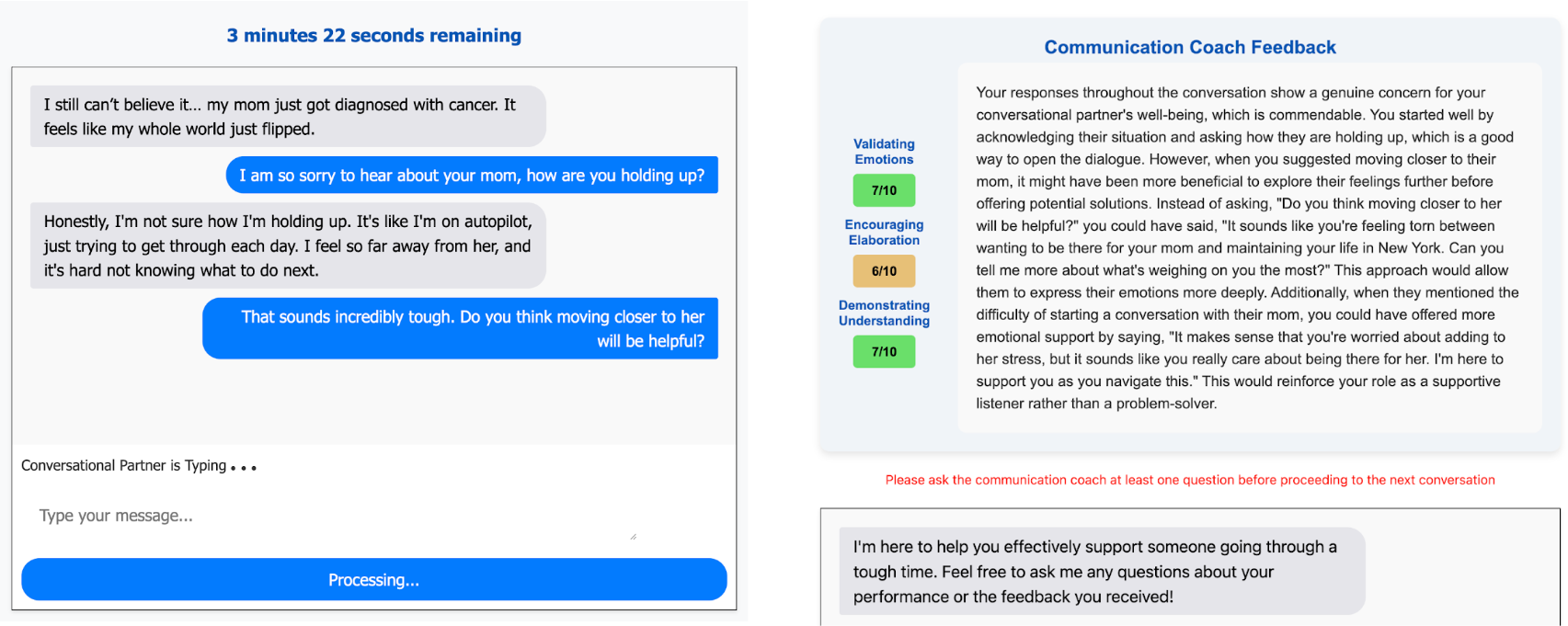
The team built “Lend an Ear,” a website where volunteers practiced comforting an AI character going through real-life troubles, like:
- Personal: a family member’s cancer diagnosis or death
- Work: losing a job, being passed over for promotion, or feeling undervalued
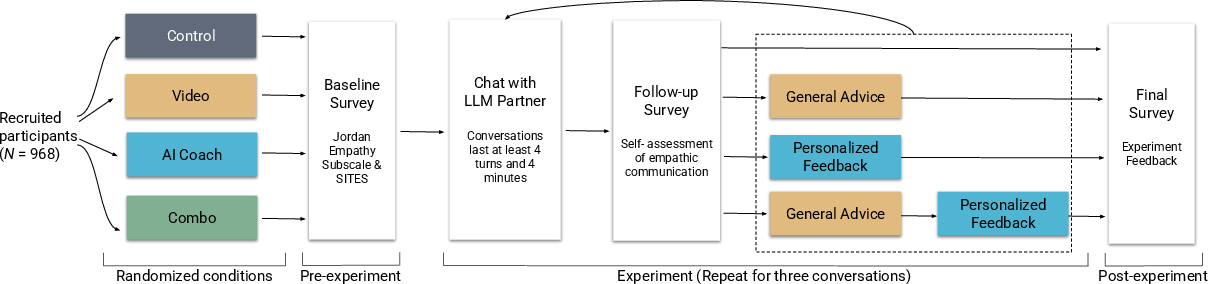
Each person had three short, text-only conversations with different AI characters. After each chat, some participants got feedback before the next one.
About 1,000 people took part, creating almost 3,000 conversations and over 33,000 total messages. Most said the scenarios felt realistic.
The four groups (randomized like a coin flip)
- Control: no feedback
- Video: two very short advice videos (general tips)
- AI Coach: personalized feedback based on what you actually wrote, plus a chance to ask follow-up questions
- Combined: both the videos and the AI coaching
Random assignment helps make the groups fair to compare.
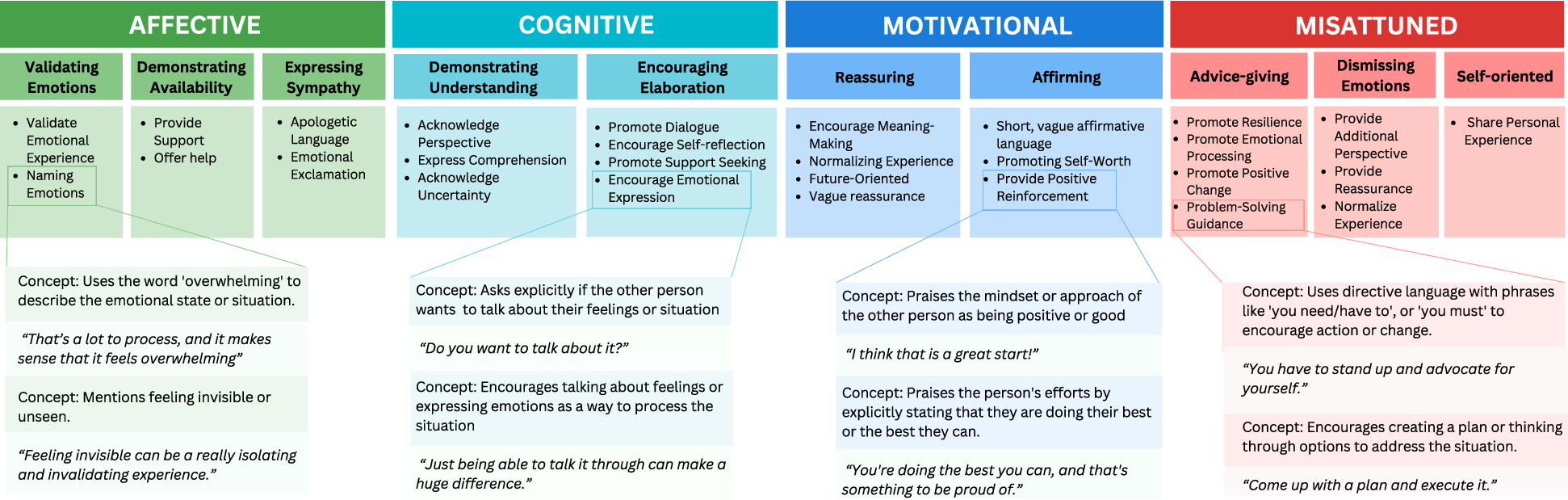
How they measured “good empathy”
They scored messages based on six communication habits that research links to making someone feel heard. Three to do:
- Encourage elaboration (ask helpful questions so the person can share more)
- Validate emotions (let them know their feelings make sense)
- Show understanding (paraphrase their experience to show you got it)
And three to avoid:
- Unsolicited advice (jumping into “you should…” too soon)
- Self-focused replies (turning the talk back to yourself)
- Dismissing feelings (downplaying or ignoring emotions)
They used a LLM—a powerful text AI—to rate messages on these behaviors. Prior work shows LLM ratings can match expert judgments in this area.
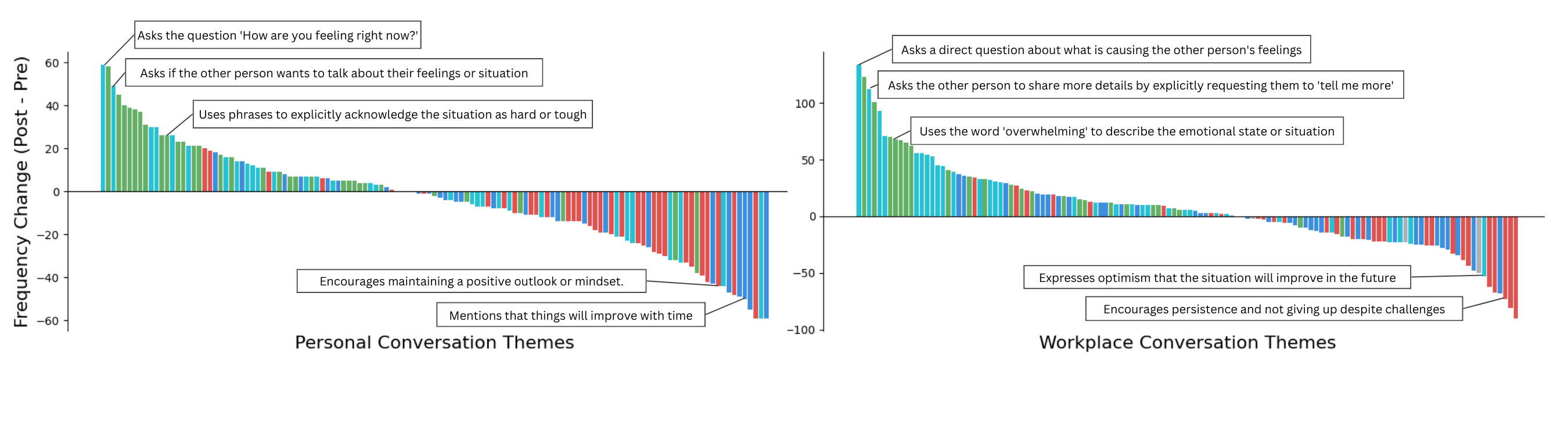
Finding patterns in empathy language
The team used a computer “pattern-finder” (a k-sparse autoencoder—think of it like a super sorter) to group 29,000+ sentences into 128 themes. It’s like organizing thousands of puzzle pieces into piles that share the same picture (for example, “naming emotions,” “asking gentle follow-up questions,” or “offering quick fixes”). This helped map the common ways people try to be empathic—and where they go wrong.
A double-check with human observers
In a second test, new people compared pairs of conversations and chose which one felt more empathic. This showed whether ordinary readers agreed with the AI-based scores.
What did they find?
- AI coaching worked—and worked best:
- People who got personalized AI feedback improved much more than those with no coaching or only videos.
- They did more of the helpful behaviors (asking, validating, showing understanding) and less of the unhelpful ones (unwanted advice, dismissing feelings, shifting focus to themselves).
- The combined condition (videos + AI coach) was strong too, but personalization was the key.
- Quality changed, not quantity:
- People didn’t type more or write longer messages after coaching. They just chose better words and phrasing.
- The “silent empathy” effect:
- Many people felt empathy but didn’t express it clearly. Personality-style empathy scores (how empathic you say you are in general) didn’t predict how empathically people actually wrote.
- People also consistently rated their own messages as more empathic than the graders did. In other words, feeling caring isn’t the same as sounding caring.
- Human readers agreed with the scores:
- When two conversations differed by a lot in quality (based on the six behaviors), human raters picked the better one most of the time. Bigger gaps led to stronger agreement. This supports the idea that the measured “skills” match what people like to hear when they’re upset.
- A map of empathy language:
- The 128 themes showed common “moves” people use. About three-quarters of messages were forms of affective empathy (sharing/validating feelings), cognitive empathy (showing understanding), or motivational empathy (showing care and willingness to help). The rest were “misattuned” (like rushing to advice or minimizing feelings).
Why does it matter?
- Empathy is a learnable skill:
- This study shows that expressing empathy isn’t magic or only for “naturally caring” people. It’s a set of communication habits you can practice, like learning the right moves in a sport or the right chords on a guitar.
- AI can be a helpful coach:
- Short, personalized feedback from an AI can help many people improve quickly, at low cost, and at large scale. That could help in schools, workplaces, and healthcare—anywhere people need to support each other.
- Better everyday conversations:
- Small changes—asking one extra question, naming a feeling, or reflecting back what someone said—can make a real difference in whether someone feels heard.
- Not a replacement for humans:
- AI isn’t a substitute for human connection. But it can help people practice and get better at the parts of empathy that matter most to the person who’s hurting.
- Future directions:
- The study focused on U.S. participants and lower-intimacy settings (like coworkers or acquaintances). Next steps include adapting training for close relationships and different cultures, where the “empathy idiom” (the style and wording) may differ while the core skills stay the same.
In short: Practicing with an AI coach helped people learn to communicate care more clearly. Feeling empathy is important—but learning how to show it in words is what makes others feel truly heard.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- External validity beyond low-familiarity, US, English, text-only settings: Does the intervention generalize to high-relational contexts (e.g., partners, family, close friends), different cultures and languages, and other modalities (voice, video, face-to-face) where tone, prosody, and nonverbal cues matter?
- Real-world deployment outcomes: Do skills learned with an LLM partner transfer to authentic interactions with humans in the wild (e.g., workplaces, healthcare, education), and do recipients actually feel more heard, supported, and trusting when interacting with trained participants?
- Durability and transfer: What is the long-term retention of gains (weeks/months), and do improvements transfer across scenarios not seen in training (e.g., discrimination, financial stress, conflict, mental health crises)?
- Dose–response and training design: How do frequency, spacing, and duration of coaching affect outcomes? Which coaching components (personalized examples, corrective prompts, reflection, practice rounds) drive gains (ablation studies)?
- Comparison to human-delivered training: How does LLM coaching stack up against best-practice human coaching programs (personalized human feedback, role-play with human confederates) on both effectiveness and cost-effectiveness?
- Heterogeneity and fairness: Which participant characteristics (baseline skill, writing proficiency, demographics, culture, English fluency, neurodiversity) moderate effects? Do LLM evaluators/coaches systematically advantage certain dialects, sociolects, or communication styles?
- Context-conditional norms (especially advice-giving): How should coaching adapt when advice is explicitly solicited or normatively expected (e.g., mentorship)? Can the system detect and tailor to advice-request contexts to avoid penalizing appropriate advice?
- Measurement validity and Goodhart risks: To what extent do improvements reflect optimization to LLM-judged stylistic markers rather than better recipient experiences? Can outcome measures include recipient-reported feeling heard, alliance, trust, and well-being—not only LLM ratings?
- Independence and robustness of evaluators: Were the coach and judge models independent? How robust are results to using different LLMs as judges (cross-model and version robustness), and to expert human judgments? What is inter-rater reliability and calibration to human experts?
- Taxonomy stability and reproducibility: How sensitive are k-sparse autoencoder concepts to choices of embedding model, k, random seed, and sample? Do the 128 themes replicate on new datasets and across cultures/modalities?
- AI role-player realism and constraints: Does practicing with LLM partners (2–3 sentence turns, goal to feel heard) produce effects that hold with human partners who vary in verbosity, emotion, and responsiveness? What happens when partners react negatively or unpredictably?
- Downstream conversational dynamics: Beyond prescriptive/proscriptive labels, do trained participants elicit more partner disclosure, longer turns, richer emotion talk, or improved conversational outcomes over time?
- Authenticity and perception risks: Do recipients perceive coached responses as formulaic or inauthentic, and does disclosure of AI-based training affect trust or perceived sincerity?
- Spillovers and overgeneralization: Does emphasis on avoiding advice-giving reduce problem-solving when warranted, or lead to overuse of empathic markers in contexts needing directness or efficiency?
- Safety and high-stakes contexts: How should the system adapt for crisis scenarios (e.g., suicidal ideation) where empathic communication norms, risks, and escalation protocols differ?
- Meta-cognitive calibration: Can coaching also reduce the disconnect between felt and expressed empathy by improving self-assessment accuracy (metacognitive feedback), not just behavior?
- Additive effects and content framing: Why did videos alone increase advice-giving? Can alternative non-personalized content avoid this; what framing reduces misinterpretation while preserving gains?
- Organizational and societal uptake: What are barriers to adoption (privacy, cost, incentive alignment) in workplaces/healthcare? Do trained skills change willingness to engage in supportive conversations at scale?
- Data transparency and reproducibility: Are datasets, prompts, and models (role-player, coach, judge) publicly available for replication? How does LLM version drift affect reproducibility over time?
- Ethical and privacy considerations: How will user data be safeguarded in at-scale deployments; how to prevent misuse (e.g., manipulative “empathy hacking”) and ensure informed consent?
- Cross-cultural norm mapping: How do empathic idioms vary across cultures, and can the coach dynamically learn and teach culturally appropriate expressions while preserving core outcomes (feeling heard)?
- Turn-level mechanisms: Which micro-moves (e.g., specific question types, paraphrase structures, emotion labeling) most strongly predict recipient-perceived empathy, and how can the coach prioritize these?
- Real-world recipient knowledge of AI involvement: Do outcomes differ when recipients know the supporter was AI-trained or used AI assistance, and how should disclosure be managed?
Practical Applications
Immediate Applications
Below are concrete ways the paper’s findings and methods can be deployed now across sectors. Each item notes potential tools/workflows and key assumptions or dependencies.
- Empathy coach inside workplace chat and email
- Sector: Software, Enterprise HR/People Ops
- What: A Slack/Teams/Gmail add-on that privately scores drafts against the six empathic dimensions and suggests “rewrites” (validate emotions, encourage elaboration, demonstrate understanding; avoid unsolicited advice, self-focus, dismissal).
- Workflow: Inline nudge when composing; post-message debrief with examples from the taxonomy; periodic RCI-style progress tracking.
- Assumptions/Dependencies: Privacy-by-design; on-device or secure inference; opt-in “backstage” coaching (avoid AI frontstaging to mitigate the attribution penalty).
- Customer-care training and QA
- Sector: Contact centers (telecom, finance, utilities, ecommerce, healthcare payers)
- What: Role-play labs that mirror common complaint scenarios; LLM-as-judge scoring and Elo-style comparative reviews; targeted micro-lessons when advice-giving spikes.
- Workflow: After-call coaching and weekly cohorts; dashboards by team using the taxonomy’s categories; sampling review with human audit.
- Assumptions/Dependencies: Union and compliance alignment; bias audits across customer demographics; latency and cost control for scale.
- Healthcare communication skills labs
- Sector: Healthcare (medical/nursing schools, telehealth groups, hospital onboarding)
- What: Lend-an-Ear–style modules covering breaking bad news, grief, chronic illness check-ins, and team handoffs; immediate personalized feedback.
- Workflow: Pre- and post-scenario evaluations with RCI; integration into OSCE prep; de-identified transcripts for portfolio evidence.
- Assumptions/Dependencies: Non-clinical, low-risk scope at first; HIPAA-safe environments; not a substitute for clinical supervision.
- Leadership and manager development
- Sector: Corporate L&D
- What: Short simulations for performance reviews, underperformance conversations, and RIF/layoff comms; AI coach converts “urge to fix” into validating and exploratory moves.
- Workflow: Monthly micro-simulations; team-level heatmaps of misattuned behaviors; human-led reflections using exemplar transcripts.
- Assumptions/Dependencies: Guard against surveillance culture; use scores for learning (not punitive evaluation); informed consent.
- Teacher, counselor, and RA training
- Sector: Education (K-12 SEL staff, higher-ed RAs, school counselors)
- What: Scenario banks for student anxiety, grade conflict, roommate disputes; feedback emphasizing elaboration and understanding over advice.
- Workflow: Semester-long micro-practice; tracked improvement on the six dimensions; supervisor review of flagged patterns.
- Assumptions/Dependencies: Age-appropriate content; parental consent for minors; safeguarding protocols.
- Peer-support and employee assistance programs
- Sector: Mental health peer support, HR EAP, community organizations
- What: Practice drills for non-clinical volunteers; taxonomy-based prompts to reduce dismissing emotions and self-referencing.
- Workflow: Onboarding bootcamps; quarterly refreshers; opt-in transcripts for skills coaching.
- Assumptions/Dependencies: Not for crisis triage; clear escalation pathways; scope boundaries.
- Drafting assistants for sensitive messages
- Sector: Daily life, Enterprise communications
- What: “Empathy rewrite” for condolence notes, difficult feedback, or exit communications; suggestions grounded in the taxonomy.
- Workflow: Browser extension or mobile keyboard; example-based prompts (“try naming the emotion you’re hearing”).
- Assumptions/Dependencies: Human authorship preserved; disclose assistance if organizational policy requires.
- Program evaluation for public services
- Sector: Government, Policy (benefits hotlines, unemployment offices, social services)
- What: LLM-as-judge to monitor empathic quality across call/chat transcripts; before/after training comparisons; human preference spot-checks.
- Workflow: Quarterly audits; targeted coaching for high-friction services; publish aggregate improvements.
- Assumptions/Dependencies: Procurement and privacy compliance; fairness reviews; avoid automated discipline.
- Research instrumentation and coding-at-scale
- Sector: Academia (communication, HCI, psychology, management)
- What: Use the six-dimension rubric and k-sparse-autoencoder taxonomy to annotate large corpora (forums, workplace comms) to study empathy in the wild.
- Workflow: LLM-assisted coding with human auditing; cross-dataset comparisons; release of labeled benchmarks.
- Assumptions/Dependencies: Model drift controls; IRB approvals; domain adaptation to different communities.
- Hiring/interview practice (candidate-side coaching)
- Sector: Talent, Career services
- What: Simulations to practice empathetic responses in behavioral interviews and mock stakeholder conversations.
- Workflow: Career center offerings; scorecards with strengths and growth areas; RCI-tracked progress.
- Assumptions/Dependencies: Avoid use for automated candidate screening; equity considerations.
Long-Term Applications
These uses require further validation, domain adaptation, multi-modal capabilities, or policy frameworks before wide deployment.
- Clinical-grade communication certification
- Sector: Healthcare
- What: CE-accredited empathy training for clinicians tied to patient outcomes (adherence, satisfaction); specialty-specific “idiom packs.”
- Dependencies: Multi-site RCTs; durable learning studies; regulator and accreditation approval.
- Real-time “whisper” coaching in calls and meetings
- Sector: Enterprise, Sales/Success, Healthcare, Public services
- What: Live suggestions on voice/video (prosody, pacing, turn-taking) to encourage elaboration or avoid dismissals.
- Dependencies: Low-latency on-device ASR/LLM; consent from all parties; distraction and safety mitigations.
- Cross-cultural and multilingual empathy models
- Sector: Global companies, International NGOs, Education
- What: Localization of empathic idioms; culturally appropriate validation vs. solutioning; multilingual taxonomy expansions.
- Dependencies: Cultural co-design, diverse datasets, human-in-the-loop evaluation; avoid imposing Western norms.
- Organizational empathy analytics linked to outcomes
- Sector: Enterprise, Customer operations
- What: Aggregate (privacy-preserving) dashboards connecting empathy metrics to KPIs (retention, NPS, churn, safety).
- Dependencies: Strong governance; de-identification; causal evaluation to avoid metric gaming.
- K–12 SEL curriculum infusion
- Sector: Education
- What: Age-graded practice modules embedded in SEL standards; parent portals for guided at-home practice.
- Dependencies: Longitudinal safety/efficacy research; district approvals; digital equity.
- Law enforcement, emergency response, and de-escalation training
- Sector: Public safety
- What: High-fidelity simulations with multi-modal (voice, video) cues for emotion recognition and empathic responding.
- Dependencies: VR/AR integration; rigorous oversight; independent evaluations of harm reduction.
- Standard-setting and evaluation frameworks
- Sector: Policy, Standards bodies
- What: Benchmark suites (human/LLM) and auditing protocols for empathy coaching tools; ISO-like guidelines for measurement and reporting.
- Dependencies: Multi-stakeholder consensus; bias and fairness safeguards; transparency requirements.
- Safeguards against manipulative “weaponized empathy”
- Sector: Policy, Cybersecurity, Platforms
- What: Detection and throttle of AI-optimized persuasion in scams or disinformation; provenance indicators for AI-shaped messaging.
- Dependencies: Platform cooperation; legal frameworks; red-team datasets.
- Social robotics and simulation labs
- Sector: Robotics, Healthcare training
- What: Physical or embodied agents as practice partners in simulation centers (e.g., bedside manner, eldercare).
- Dependencies: Multi-modal alignment; ethical design that keeps humans frontstage in real care.
- Multimodal empathy assessment and coaching
- Sector: Healthcare, Enterprise, Education
- What: Combine text with prosody, facial expression, and turn-taking to coach timing, tone, and presence.
- Dependencies: Consent and privacy for video/audio; robust cross-device performance; bias controls for vision models.
- Longitudinal personal “empathy portfolio”
- Sector: Consumer, Professional development
- What: Cross-app record of progress with RCI-like metrics, idiom mastery, and personalized practice plans.
- Dependencies: Data portability standards, user control, and strong privacy defaults.
- Community moderation and platform health
- Sector: Social media, Online communities
- What: Moderator training using the taxonomy to reduce dismissals and dogpiling; A/B tests on community “felt heard” metrics.
- Dependencies: Platform data access; careful measurement to avoid over-policing speech; transparency with users.
Cross-cutting assumptions and risks to monitor
- Generalization: Effects shown in low-relational, text-only, U.S.-based scenarios; high-stakes and high-intimacy contexts need dedicated validation.
- Durability: Single-session gains are promising; long-term retention and transfer to real interactions require longitudinal evidence.
- Attribution penalty: Keep AI as a backstage coach; avoid substituting AI as the speaker in sensitive contexts.
- Fairness and bias: Regular audits across identities, languages, and cultures; human oversight of consequential uses.
- Privacy and security: Sensitive conversations demand on-device or tightly controlled inference; rigorous de-identification for analytics.
- Model drift and reproducibility: Version pinning, continuous evaluation against human judgments, and transparent reporting.
Glossary
- Affective empathy: Sharing another’s emotions while maintaining a self–other distinction; one of the three core components of empathy. "Affective empathy accounted for 25\%, cognitive empathy for 27\%, and motivational empathy for 26\% of messages."
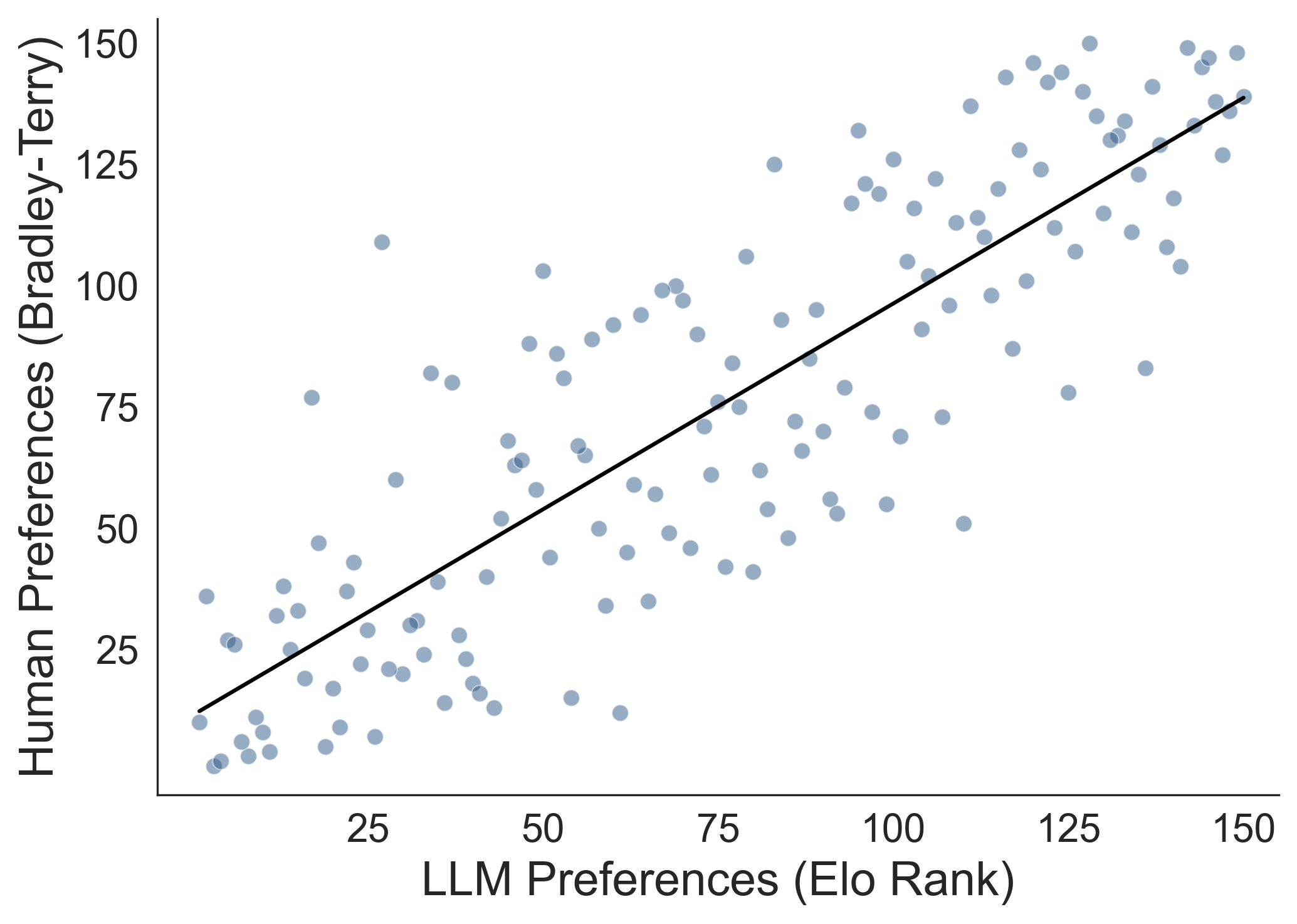
- Bradley-Terry (BT) model: A statistical model for deriving rankings from pairwise comparisons by estimating the probability one item beats another. "We also estimated human-preference rankings from participantsâ pairwise choices using a Bradley-Terry (BT) model for each scenario, and compared these to LLM-derived rankings."
- Cognitive empathy: Recognizing and understanding another person’s emotional state; one of the three core components of empathy. "Affective empathy accounted for 25\%, cognitive empathy for 27\%, and motivational empathy for 26\% of messages."
- Elo ratings: A rating system originally developed for chess that updates player (or item) strengths based on pairwise outcomes. "This sample was constructed by selecting 3 conversations from each decile of Elo ratings derived from pairwise LLM judgments (resulting in 30 conversations per scenario across five scenarios; see Figure \ref{fig:preference_elo}A for Elo rankings per decile and Methods for details)."
- Jordan empathy subscale: A validated psychology instrument for measuring trait empathy. "They first reviewed instructions outlining the procedure and their role in the conversations, and then completed a baseline survey, including the Jordan empathy subscale~\cite{jordan2016empathy} and the SITES measure~\cite{konrath2018development} to capture self-reported trait empathy."
- k-sparse autoencoder (kSAE): An autoencoder that enforces a fixed number of active units (top-k) to produce sparse, interpretable representations. "We map communicative diversity by empirically identifying the phrasal lexicon~\cite{becker1975phrasal, o1995managing, lambert2001semi} (the communicative moves participants used) using a k-sparse autoencoder (kSAE) on text embeddings of 29,520 sentence-level units extracted from 16,975 messages in 2,904 conversations."
- Latent concepts: Hidden, data-driven factors or themes inferred from models (e.g., autoencoders) that capture underlying structure. "We identified 128 latent concepts as optimal through a grid search over the number of latent features ranging from (16) to (256), balancing clustering quality (silhouette score of 0.42 for 128, compared to 0.35 for 64 features and 0.38 for 256) with interpretability and thematic distinctiveness (see Methods)."
- Likert scale: A psychometric scale (e.g., 5-point) for measuring attitudes or perceptions via ordered response options. "All conversations had been previously assessed by LLM judges across six sub-components on a 5-point Likert scale and ranked using Elo ratings from pairwise judgments elicited from an LLM evaluator."
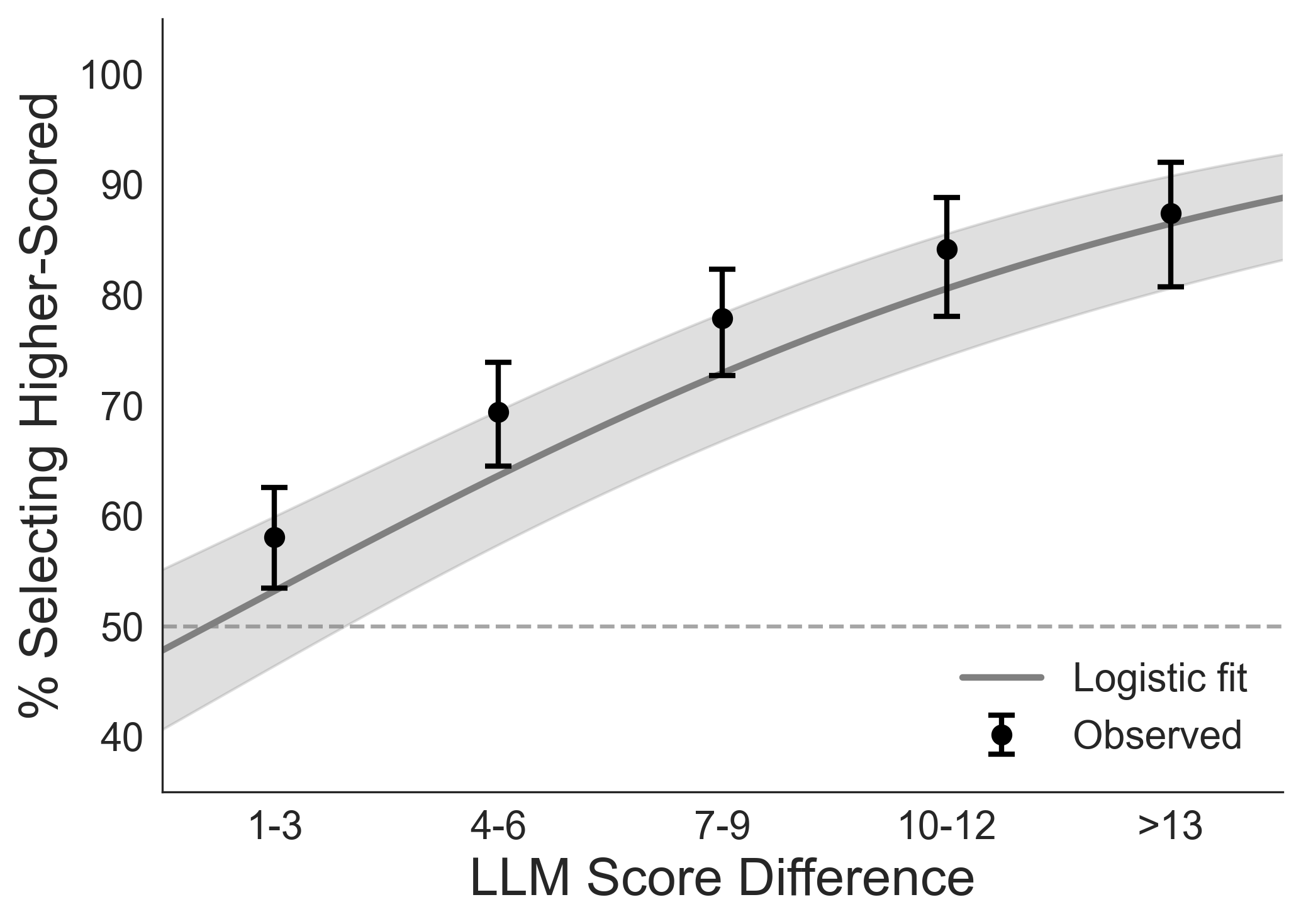
- Logistic regression: A statistical model for predicting probabilities of binary outcomes from predictors. "A logistic regression predicting selection of the higher-scored conversation from LLM score differences (higher minus lower) showed a positive association (, ; , 95\% CI [1.12, 1.19]; See Figure~\ref{fig:preference_elo}B)."
- LLM-as-judge paradigm: Using a LLM to evaluate or score human-generated content against specified criteria. "We use an LLM-as-judge paradigm to score participants' responses on six preregistered dimensions of empathic communication including encouraging elaboration (asking questions to prompt the partner to share more about their experiences and emotions) \cite{bodie2011active}, validating emotions (acknowledging and affirming the partner's feelings) \cite{kim2018social}, demonstrating understanding (paraphrasing the partner's experiences to show comprehension) \cite{gerdes2011teaching}, providing unsolicited advice (offering guidance without first asking if it is wanted) \cite{fitzsimons2004reactance}, self-oriented responding (shifting focus away from the partner's experience) \cite{burleson2008counts}, and dismissing emotions (minimizing or invalidating the partner's feelings) \cite{yao2023person}."
- Misattuned behaviors: Responses that deviate from empathic norms (e.g., dismissing emotions, unsolicited advice) and tend to make recipients feel unheard. "The other 22\% of messages were categorized as misattuned behaviors that normative models of empathy recommend avoiding such giving unsolicited advice (e.g., ``You just need to move on''), dismissing emotions, and redirecting focus to oneself~\cite{goldsmith1997normative, weger2014relative, jones2004personcentered}."
- Motivational empathy: Empathic concern that motivates caring actions or effort to support another; one of the three core components of empathy. "Affective empathy accounted for 25\%, cognitive empathy for 27\%, and motivational empathy for 26\% of messages."
- Odds ratio (OR): A measure of association in logistic models comparing the odds of an outcome across conditions or levels of a predictor. "A logistic regression predicting selection of the higher-scored conversation from LLM score differences (higher minus lower) showed a positive association (, ; , 95\% CI [1.12, 1.19]; See Figure~\ref{fig:preference_elo}B)."
- Phrasal lexicon: A set of recurring idiomatic phrases or communicative moves characteristic of a domain or style. "We map communicative diversity by empirically identifying the phrasal lexicon~\cite{becker1975phrasal, o1995managing, lambert2001semi} (the communicative moves participants used) using a k-sparse autoencoder (kSAE) on text embeddings of 29,520 sentence-level units extracted from 16,975 messages in 2,904 conversations."
- Polysemous sentences: Sentences that can express multiple meanings or align with multiple thematic concepts. "In our analysis, each sentence was assigned to its top two activating features to account for polysemous sentences that could align with multiple thematic concepts."
- Preregistered randomized experiment: A study whose analysis plan is specified in advance (preregistered) and that randomly assigns participants to conditions. "In a preregistered randomized experiment with 968 participants, producing 2904 conversations with an average of 11 turns per conversation, and a total of 16,975 human messages and 16,963 LLM-generated messages, we evaluate the impact of personalized feedback from an LLM coach on participants' empathic communication performance."
- Prescriptive behaviors: Recommended actions to do (e.g., validating, encouraging elaboration) according to a normative framework. "Personalized feedback from the AI coach improved all three prescriptive behaviors relative to control (Encouraging Elaboration , Validating Emotions , Demonstrating Understanding ; all )."
- Proscriptive behaviors: Actions to avoid (e.g., unsolicited advice, dismissing emotions) according to a normative framework. "Personalized feedback from the AI coach significantly reduced all three proscriptive behaviors including Advice Giving (, ), Dismissing Emotions (, ), and Self-Oriented responses (, )."
- Reliable Change Index (RCI): A statistic indicating whether an individual’s change exceeds what is expected from measurement error, signaling reliable improvement/decline. "We computed the Reliable Change Index (RCI) for each participant, allowing us to classify individual change as reliable improvement, reliable decline, or measurement noise."
- Silent empathy effect: The phenomenon where people feel empathy but fail to express it in ways that others perceive. "Moreover, we find evidence for a silent empathy effect that people feel empathy but systematically fail to express it."
- Silhouette score: A clustering quality metric that assesses how well points fit within their cluster versus other clusters. "We identified 128 latent concepts as optimal through a grid search over the number of latent features ranging from (16) to (256), balancing clustering quality (silhouette score of 0.42 for 128, compared to 0.35 for 64 features and 0.38 for 256) with interpretability and thematic distinctiveness (see Methods)."
- SITES measure: The Single-Item Trait Empathy Scale, a brief instrument to assess self-reported trait empathy. "They first reviewed instructions outlining the procedure and their role in the conversations, and then completed a baseline survey, including the Jordan empathy subscale~\cite{jordan2016empathy} and the SITES measure~\cite{konrath2018development} to capture self-reported trait empathy."
- Sparsity constraint: A model constraint encouraging only a few features to activate, yielding parsimonious and interpretable representations. "This sparsity constraint helps distill recurring linguistic patterns in a data-driven way, surfacing latent concepts that capture thematically coherent expressions across our data."
- Spearman correlation (rho): A nonparametric rank correlation coefficient measuring monotonic association between two variables. "BT rankings closely matched LLM assessments (Spearman with LLM empathy scores; with Elo ratings; for both; Figure~\ref{fig:preference_elo}C)"
- Text embeddings: Vector representations of text that capture semantic relationships for use in machine learning models. "We map communicative diversity by empirically identifying the phrasal lexicon... using a k-sparse autoencoder (kSAE) on text embeddings of 29,520 sentence-level units..."
- Two-alternative forced-choice (2AFC): An experimental design where participants choose the better item from a pair on each trial. "We recruited 150 participants via Prolific to perform two-alternative forced-choice comparisons for 150 conversations sampled from the Lend an Ear dataset."
- Wilson confidence intervals: A method for calculating binomial proportion confidence intervals with better coverage than the normal approximation. "Points show observed selection rates (with 95\% Wilson confidence intervals) binned by LLM score difference; gray line shows logistic regression fit (OR = 1.15 per point, 95\% CI [1.12, 1.19])."
Collections
Sign up for free to add this paper to one or more collections.