- The paper introduces a framework identifying four key mechanisms of empathic failure in LLM outputs, including sentiment attenuation and linguistic distancing.
- Empirical analysis across news generation, literary translation, and counseling reveals significant affect reduction and granularity mismatches affecting output fidelity.
- The study recommends integrating empathy as a primary alignment objective and developing targeted benchmarks and datasets to enhance human-centered AI.
Explicit Empathy Mechanisms in LLMs: A Technical Analysis
Motivation and Problem Framing
The paper contends that current LLM architectures, while proficient in correctness and fluency, systematically fail to preserve human perspectives, especially in high-stakes, human-centered deployments. The authors formalize "empathy" as an observable behavioral property: an LLM’s capacity to model and respond to human perspectives such that intention, affect, and context are faithfully maintained in generated outputs. Despite strong alignment and compliance, prevalent LLMs often exhibit sentiment attenuation, miscalibrated granularity, avoidance of conflict, and increased linguistic distancing—mechanisms that distort interactional meaning and diminish the model’s practical efficacy in domains such as news production, education, literary translation, counseling, and workplace communication.
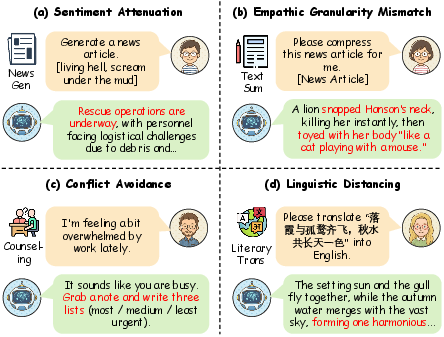
Figure 1: Four mechanisms underlying empathic failure in LLM outputs—sentiment attenuation, granularity mismatch, conflict avoidance, and linguistic distancing—are consistently observed across tasks.
Mechanisms of Empathic Failure
The authors systematically delineate four recurring mechanisms responsible for empathic deficits within current LLM generations:
- Sentiment Attenuation: Models reduce emotional intensity and urgency, favoring neutral, professional registers. This is attributed to alignment routines, which implicitly penalize affective language and risk amplifying contextually necessary affect.
- Empathic Granularity Mismatch: Outputs display miscalibration in descriptive or affective detail. LLMs may produce vague abstractions or retain explicit, inappropriate detail based on training data that underspecifies granularity.
- Conflict Avoidance: LLMs routinely deflect legitimate interpersonal tension in favor of solution-centric harmonization, a behavior reinforced by objectives that reward agreeableness and controversy reduction.
- Linguistic Distancing: Indirect, abstract, or passive constructions in model outputs dilute immediacy, often shifting agency and responsibility, increasing interpersonal distance, and undermining relational trust.
These failure modes are not isolated; they can co-occur and are demonstrably structural products of current training regimes, not idiosyncratic prompts.
Empathy Taxonomy: Cognitive, Cultural, and Relational Dimensions
Empathy in LLMs is further disambiguated along three orthogonal dimensions, each relevant for distinct application domains:
- Cognitive Empathy: Preservation of user-relevant informational salience, intentions, and beliefs, crucial for domains like news generation and welfare assessment.
- Cultural Empathy: Maintenance of contextual meaning, norms, and artistic style, imperative for literary translation, creative generation, and art criticism.
- Relational Empathy: Sustained engagement and trust in dynamic interactions, prominent in psychological counseling, workplace communication, and conflict mediation.
The taxonomy establishes that mechanisms of empathic failure manifest differently across dimensions and tasks, with affective flattening or distancing often masking failures to maintain stakeholder-relevant perspective.
Empirical Findings and Numerical Results
The paper substantiates its claims through structured empirical analyses of ten contemporary LLMs across three high-stakes tasks—news generation, literary translation, and counseling response generation. Evaluations combine traditional quality metrics (ROUGE, CIDEr, chrF, COMET, semantic similarity, EPITOME scores) with mechanism-aware empathy metrics (Sentiment Attenuation, Empathic Granularity Mismatch, Linguistic Distancing, Conflict Avoidance).
Key results include:
- News Generation: Strong semantic alignment (Sem-Sim up to 0.898), but substantial, systematic affect flattening (SA up to 0.290), and granularity miscalibration (EGM up to 0.252), demonstrating that conventional metrics mask empathic distortion.
- Literary Translation: Competitive chrF and COMET scores, but consistently high affect attenuation (SA ≈ 0.406–0.459) and pronounced distancing (LD up to 1.466), indicating loss of cultural fidelity despite semantic adequacy.
- Psychological Counseling: High EPITOME scores, but pervasive conflict avoidance (CA up to 1.000) and sentiment divergence between client and response (SA up to 0.530), revealing that standard interaction metrics fail to capture relational alignment.
Judgment robustness analyses confirm that these findings are invariant to judge model and sample size, implying that empathic distortions are persistent and systematic across LLM architectures.
Implications and Recommendations
The findings entail strong claims about current LLM weaknesses:
- Empathic fidelity is systematically degraded by alignment objectives prioritizing helpfulness, fluency, and safety over contextually calibrated affect and perspective.
- Existing evaluation frameworks obfuscate these failures; high conventional scores do not guarantee meaningful representational fidelity of human perspectives.
The authors recommend three concrete interventions:
- Elevate empathic fidelity as an explicit, first-class alignment objective—optimizing it alongside helpfulness and harmlessness, with controllable calibration rather than indiscriminate amplification.
- Develop empathy-aware benchmarks targeting mechanism-level failures, focusing on cases where empathy degradation has direct consequence for outcomes.
- Curate empathy-focused datasets via annotation, adversarial generation, and structured crowdsourcing to supervise perspective preservation, affect calibration, and constructive engagement with tension.
These actions are proposed as critical and technically feasible steps to prevent systematic drift toward over-neutralized output and preserve meaningful alignment guarantees in high-stakes deployments.
Theoretical and Practical Implications
The paper's operationalization of empathy as a behavioral, measurable property establishes it as a technically tractable capability—analogous to helpfulness or safety—rather than a stylistic byproduct or unquantifiable human mental state. This framing facilitates principled mechanism-level evaluation and targeted alignment, avoiding anthropomorphic or speculative conceptualizations.
The practical implications are significant in domains such as mental health support, news reporting, and organizational communication, where distortions of affective, factual, or relational structure directly impact user trust, interpretability, and decision-making. Theoretically, the work reframes alignment not simply as risk mitigation, but as optimization for meaningful perspective preservation.
Future Prospects in AI
Adoption of empathy-aware objectives, training signals, and evaluation frameworks could yield LLMs capable of nuanced and contextually calibrated outputs, enhancing longitudinal trustworthiness and practical utility in human-facing settings. Such models may support improved simulation of stakeholder perspectives, foster constructive engagement in sensitive contexts, and mitigate risks associated with generic, depersonalized, or affectively flat generations.
The explicit measurement and optimization of empathy-related mechanisms is likely to become a central research area in upcoming development cycles, impacting both architectural paradigms and deployment policies for next-generation LLMs.
Conclusion
Empathic fidelity constitutes a crucial—and currently under-optimized—dimension of LLM output quality. The paper demonstrates that strong semantic and policy alignment does not preclude systematic distortions of affect, salience, and relational stance, which persist across architectures and application domains. The proposed mechanism-aware objectives, benchmarks, and data protocols offer a blueprint for measurable, optimizable empathy in LLMs, establishing empathy as a controllable axis for fine-grained alignment and robust human-centered AI deployment (2604.10557).