- The paper introduces the Multi-Stream Scene Script (MTSS) that factorizes video content into Reference, Shot, Event, and Global streams for improved captioning.
- It demonstrates significant improvements, including a 25% reduction in error rates and a 110% boost in reasoning performance on advanced video captioning tasks.
- The framework enhances identity consistency, temporal alignment, and multi-shot controllability, paving the way for more precise audio-visual understanding and generative video modeling.
Deep Structured Audio-Visual Captioning with Multi-Stream Scene Script (MTSS)
Introduction and Motivation
Script-a-Video introduces the Multi-Stream Scene Script (MTSS), a deeply structured paradigm for representing video semantics that supersedes conventional monolithic captions. Standard approaches encode the entire temporal, visual, auditory, and identity content of a video into a single narrative, entangling cross-modal dependencies and impeding local editability, reference consistency, and model learnability. The MTSS framework strategically factorizes a video into four specialized and relationally grounded streams: Reference, Shot, Event, and Global. This stream-centric approach addresses three structural bottlenecks in previous work: persistent entity referencing, explicit temporal cross-modal alignment, and modular, non-redundant scripting for fine-grained downstream control.
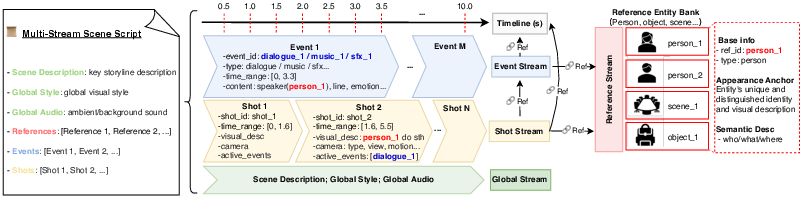
Figure 1: Overview of the Multi-Stream Scene Script (MTSS) representational design, depicting factorization into four complementary and interconnected streams for improved traceability and update efficiency.
MTSS Design: Factorization and Relational Grounding
MTSS is built on two essential principles: stream factorization and relational grounding.
Stream Factorization splits video content into:
- Reference Stream: A persistent entity bank containing unique identifiers, semantic descriptions, and appearance anchors for principal actors, objects, and scenes. This stream eliminates redundancy by allowing identity mentions across the script to cite an explicit reference (e.g.,
PERSON_1) rather than regenerate semantic and perceptual details.
- Shot Stream: A chronologically ordered set of visual segments, each precisely timestamped and described with both a narrative and explicit camera/action metadata. Each shot binds to the relevant reference entities and links temporally to concurrent auditory events.
- Event Stream: A track of temporally grounded, relationally anchored audio events (e.g., dialogues, sound effects, or music) with explicit speaker binding and micro-timestamps for precise lip-sync and action-event correspondence.
- Global Stream: Ambient, scene-setting information capturing the overarching context, style, and any persistent or non-localized audio cues.
Relational Grounding then reinstates semantic cohesion by explicitly mapping each stream’s elements to global entity IDs and precise temporal anchors, thus ensuring that persistent subjects, cross-modal events, and their interactions remain unambiguous and logically coherent across multi-shot content.

Figure 2: Example of a Multi-Stream Scene Script (MTSS) showing relationally grounded streams with explicit references, timestamps, and contextual linkage.
Improvements on Video Understanding and Captioning
On multiple open and proprietary Audio-Visual MLLMs, MTSS consistently delivers reduced error rates and enhanced detail granularity in captioning and a notable boost in downstream reasoning:
- On Video-SALMONN-2, MTSS reduces the total error rate by 25% over monolithic captions. On UGC-VideoCap, there is a gain from 62.80 to 71.54 in detail scores for Qwen3-Omni, and 110% improvement on the Daily-Omni reasoning test (2604.11244).
- MTSS narrows the performance gap between small and large MLLMs, evidencing improved learnability and compositional generalization.
- Fine-tuning with MTSS pushes open-source models into parity with commercial state-of-the-art, halving the omission rates compared to monolithic baselines.
Contradictory Claims
Ablation studies and baseline comparisons strongly suggest that the improvements are a function of the structured representation (not just extra annotation), as even prompt-only replacement (sans architecture changes) yields significant quantitative and qualitative benefits.
MTSS for Advanced Generative Video Modeling
The authors systematically evaluate MTSS as a control interface for multi-shot, identity-consistent, and jointly audio-visual video generation using an adapted LTX-2 generative framework. Two architectural augmentations leverage the MTSS structure:
- Shot-Aware Structured Attention partitions the diffusion model’s attention by explicit shot boundaries, with cross-attention between visual tokens and shot-specific embeddings, achieving sharp inter-shot context isolation and enhancing multi-shot controllability.
- Identity Customization injects character and object identities via reference VAE features and learnable tokens, directly grounded by the Reference Stream.
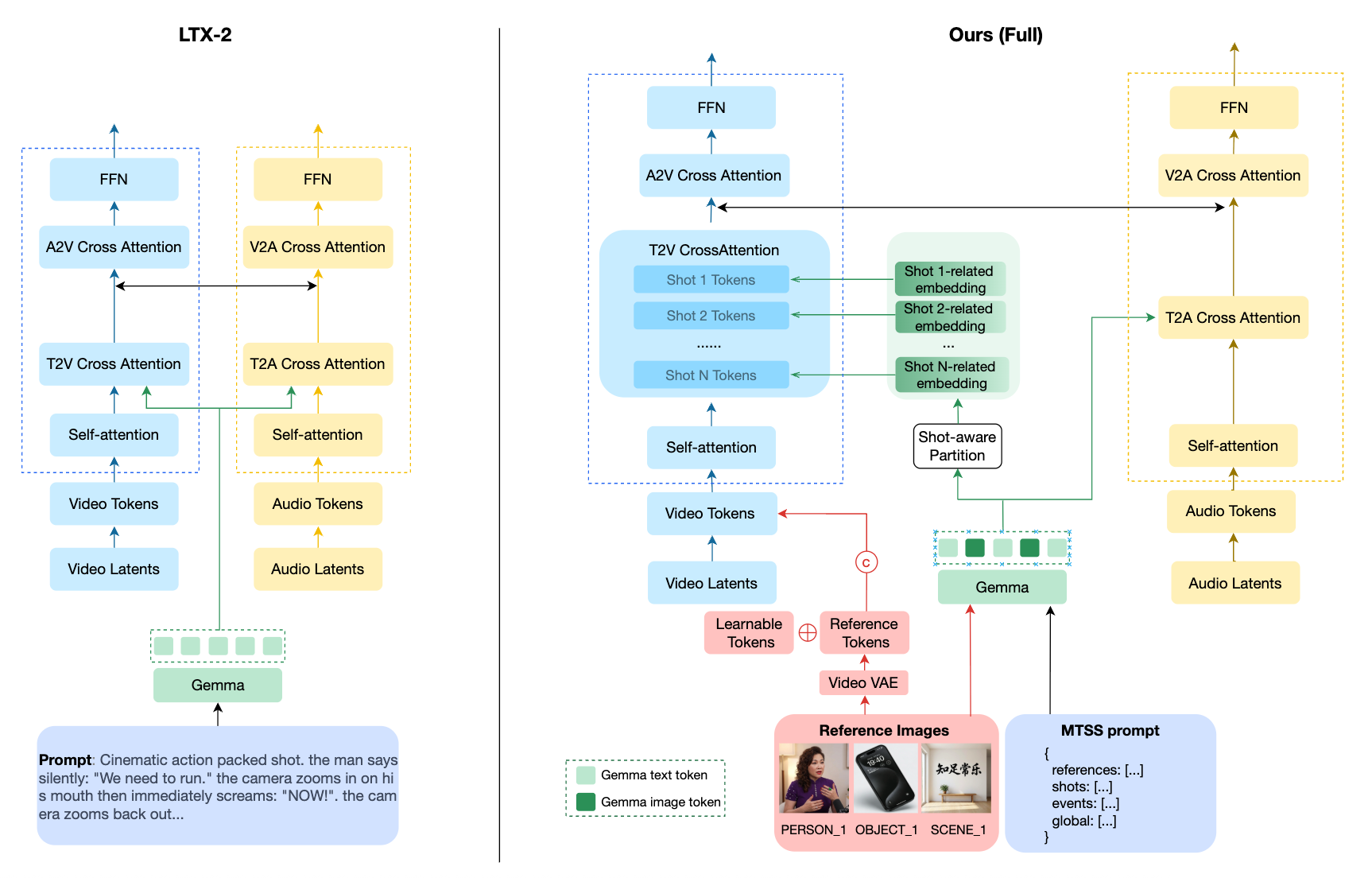
Figure 3: The pipeline overview with dual-branch DiT architecture, highlighting MTSS-driven shot-awareness and identity customization.
Empirical Results
Quantitative benchmarks and human ratings confirm substantial gains:
| Task |
Monolithic |
MTSS Prompt |
MTSS + Model Adap. |
| Multi-shot Consistency |
1.22 |
1.77 |
2.41 |
| Audio-Visual Alignment |
1.18 |
1.85 |
2.26 |
| Controllability |
1.00 |
1.71 |
2.59 |
Pure representational replacement (with MTSS prompts) already accounts for the majority of improvement, with model-level changes further amplifying the benefit. Automated metrics (e.g., shot boundary deviation, Ref. ID similarity, WER, A-V sync) consistently favor the full MTSS pipeline.
Qualitative comparisons (Figures 4–7) illustrate:
- Monolithic prompts lead to identity drift, weak shot boundaries, and flat/irrelevant audio.
- MTSS-structured control, even without further adaptation, yields persistent identity, accurate shot transitions, and precise audio-visual correspondence.
- The full MTSS pipeline achieves near-human-level alignment and narrative coherence in both single- and multi-shot scenarios.

Figure 4: Single-shot comparison: Only MTSS-structured specification maintains identity and continuous audio coverage, outperforming monolithic and weak baselines.

Figure 5: Single-shot comparison: Only MTSS-structured pipelines generate speech-like, temporally precise AV patterns.

Figure 6: Multi-shot comparison: MTSS and pipeline variants achieve accurate identity and event grounding across dynamic, cross-shot transitions.

Figure 7: Multi-shot comparison: Periodic audio-visual events and boundaries (e.g., footsteps) are only synchronized via MTSS streams and grounding.
Theoretical Implications and Future Prospects
The MTSS paradigm establishes a data-centric foundation for both discriminative and generative tasks:
- It exposes video as a relational database, making cross-modal temporal inference and reference retrieval tractable within MLLMs, and substantially reducing the search/decoding space in generative models.
- For generation, MTSS offers a universal and composable scripting interface well-suited to advanced, controller-rich Diffusion Transformer architectures.
- Future directions include scaling structured annotation quality for open-source MLLMs, optimizing cross-stream attention and alignment, and comprehensive evaluation on long-form and out-of-domain multimodal content.
Conclusion
Script-a-Video’s MTSS paradigm (2604.11244) delivers a principled, scalable, and highly effective framework for structured audio-visual captioning and tightly controlled multi-shot video generation. By decomposing the representational load into relationally grounded streams, MTSS addresses the key limitations of monolithic captioning: ambiguity, redundancy, and intractable edit/update logic. Empirical analysis confirms robust gains in descriptive fidelity, logical reasoning, identity consistency, multi-shot controllability, and audio-visual synchronization. MTSS can be anticipated to provide the backbone for next-generation semantic interfaces in both video understanding and generative modeling.