- The paper introduces a role-oriented taxonomy of MLLMs with key roles including Semantic Reasoner, Expressive Performer, and Visual Synthesizer to achieve end-to-end video translation.
- The paper details methodologies for joint audiovisual-textual learning, emphasizing precise multimodal alignment, temporal coherence, and expressive TTS generation.
- The paper demonstrates enhanced zero-shot performance and robust cross-modal consistency compared to traditional cascaded translation models.
A Role-Oriented Survey of MLLMs in Unified Video Translation
Introduction
The manuscript "Empowering Video Translation using Multimodal LLMs" (2604.11283) delineates the state-of-the-art transformation of video translation systems through Multimodal LLMs (MLLMs). The work presents a focused survey, departing from general video-language understanding reviews, by structuring the field around three foundational roles of MLLMs—Semantic Reasoner, Expressive Performer, and Visual Synthesizer. This role-oriented analysis highlights both the integration of audiovisual-textual modalities and the pathway toward end-to-end, contextually accurate video translation workflows. The implications for translation accuracy, robustness, multimodal alignment, and temporal coherence are dissected across the MLLM-based taxonomy proposed herein.
Challenges and Evolution of Video Translation Pipelines
Traditional video translation pipelines typically chain ASR, MT, TTS, and rule- or model-based lip synchronization submodules in a cascaded fashion. These pipelines suffer from error compounding and limited audiovisual-textual alignment, often resulting in low cross-modal consistency and expressivity. The integration of MLLMs allows end-to-end modeling of semantic fidelity, timing, speaker identity, and emotional nuance, reframing video translation as a unified multimodal reasoning and generation problem. This paradigm shift is motivated by recent advances in large-scale vision-language pretraining, diffusion-based video generation, and LLM-centered multimodal architectures.
MLLMs-Based Video Translation: Architecture and Taxonomy
The work proposes an architecture where the MLLM acts as a global controller, orchestrating the understanding and generation process across modalities.
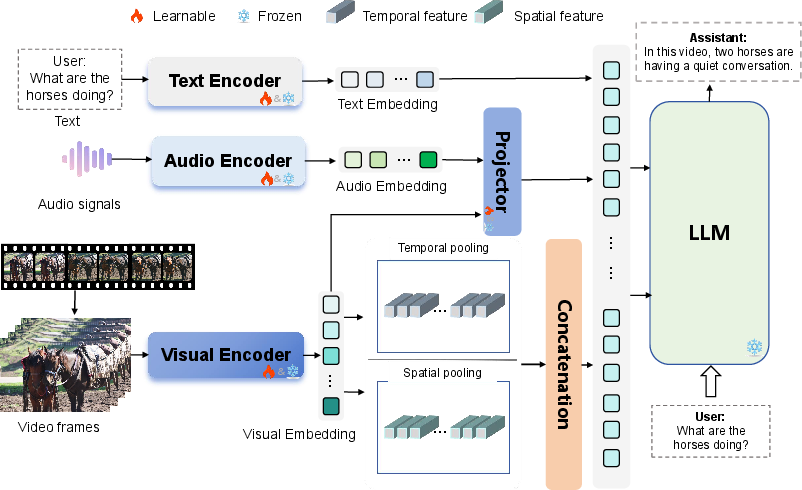
Figure 2: Typical architecture of an MLLMs-based video understanding model; encoders for text, audio, and video may be learnable or frozen.
This architecture facilitates joint representation learning and multimodal context fusion, which are critical for maintaining fine-grained semantic and temporal alignment across modalities throughout the translation process.
The authors introduce a taxonomy across three functional roles:
The Semantic Reasoner
The Semantic Reasoner encompasses modules responsible for the conversion of multimodal evidences (visual, acoustical, lexical) into reasoning-ready representations. This role is instantiated by the adoption of parameter-efficient temporal modules, cross-modal alignment mechanisms (e.g., Q-Former, LLaMA-Adapter, BT-Adapter), and progressive training paradigms (e.g., RED-VILLM, Otter, InternVideo2). These approaches enable scaling to long-form video understanding, hierarchical temporal reasoning, and robust multimodal fusion. The design trade-offs involve balancing temporal granularity, contextual window size, and the required transfer from image-text to audiovisual-text settings.
As the generation core for speech, the Expressive Performer is tasked with producing temporally aligned, context-sensitive, and emotionally consistent TTS output. The taxonomy bifurcates this role into LLM-driven and LLM-augmented models. LLM-driven methods (CosyVoice, MegaTTS 2, Spark-TTS, HALL-E) focus on zero-shot transfer, prompt-based prosody, and multi-speaker synthesis. LLM-augmented systems (XTTS, VALL-E R, NaturalSpeech3, F5-TTS, ControlSpeech) prioritize conditional controllability, speaker/linguistic adaptation, and high-fidelity output. The survey emphasizes the shift toward instruction-aware, zero-shot, and robust expressive generation aligning with real-world dubbing scenarios.
The Visual Synthesizer
This component is focused on high-fidelity visual rendering, mainly lip synching and facial motion generation regulated by the translated speech’s timing and expressivity. The taxonomy recognizes two dominant architectures: UNet-based (MagicVideo, Tune-A-Video, ControlNet-lineage) and DiT-based (Vidu, Phantom, OmniHuman-1). UNet-based designs are noted for their spatial detail and explicit controllability, making them advantageous for accurate lip synchronization. DiT-based models exhibit superior scalability and temporal coherence, critical for long-form and subject-consistent avatar generation. Here, the key challenge arises in synthesizing fine lip/facial dynamics synchronized to generated TTS with sustained coherence.
Key Trends and Empirical Outcomes
The survey compiles competitive results across major VideoQA, TTS, and video generation benchmarks, highlighting strong performance and robustness of MLLM-based systems in zero-shot and multi-speaker scenarios. Systems such as VideoLLaMA 3, Slot-VLM, IG-VLM, and F5-TTS provide numerical evidence of multi-modal semantic parsing accuracy, synthesis naturalness, and translation quality surpassing cascaded and unimodal models. Notably, the reviewed models demonstrate:
- Resilient performance in zero-shot and fine-grained expressive tasks: LLM-driven and LLM-augmented approaches attain high-fidelity outputs under minimal supervision, with prosody, speaker identity, and style preserved across translation boundaries.
- Improved temporal and cross-modal alignment: DiT-based visual synthesizers and hierarchical video-language adapters enable scalable, efficient modeling of minute-level temporal dependencies, closing the gap with human-judged narrative coherence.
- Computational and data efficiency via parameter-efficient and memory-augmented training protocols: Adapter-based and progressive multimodal curricula leverage pretraining from large unimodal corpora, mitigating the scarcity of large-scale multimodal translation datasets.
Limitations and Research Prospects
Despite progress, several outstanding limitations are identified:
- Fine-Grained Understanding: Current MLLMs have limited ability to capture micro-expressions, subtle object interactions, and emotion nuances, especially in long-form and highly dynamic video settings.
- Temporal Modeling: Hierarchical event-level representation and long-range narrative tracking remain challenging; existing positional encoding and retrieval-augmented modules are insufficient for holistic temporal consistency.
- Multimodal Alignment: Realistic, high-frequency audio-visual-text alignment remains an open issue due to underutilization of raw audio cues and synchronization complexity across cascaded/parallel subsystems.
- Scalability and Efficiency: Large-scale deployment is bottlenecked by the need for large multimodal datasets, significant computational overhead, and insufficient streaming/online inference support.
The trajectory for subsequent research includes the development of memory-augmented and hierarchical understanding frameworks, improved temporal attention mechanisms, tightly-coupled multimodal alignment strategies, self-supervised and Whisper-style audio pretraining, and techniques for structured computation sparsity and on-device deployment.
Conclusion
This work systematically structures the field of video translation within a role-based MLLM-centric taxonomy, providing clarity on the interaction between semantic understanding, expressive generation, and visual synthesis. The survey offers not only a technical foundation for benchmarking and model selection but also a roadmap for advancing MLLM-integrated architectures capable of delivering semantically faithful, temporally coherent, and expressively rich video translation at scale. As MLLMs continue to evolve, their centrality in unified, robust video translation workflows will drive practical and theoretical advances in both multimodal generation and cross-lingual communication research.