- The paper introduces the D²VLM framework, which factorizes temporal grounding from text generation to capture event-level evidence more effectively.
- It proposes the innovative <evi> token that aggregates frame-wise semantics, leading to improved grounding accuracy and consistent text generation.
- Empirical results demonstrate that D²VLM outperforms SOTA methods by over 7% in key video-language tasks while using significantly fewer parameters.
Factorized Learning for Temporally Grounded Video-LLMs
Motivation and Problem Analysis
Recent developments in video-LLMs (VLMs) have yielded strong results in open-ended video understanding via unified text-in/text-out paradigms. However, prevailing frameworks conflate two central, logically dependent tasks: temporal evidence grounding (localizing relevant visual events) and coherent textual response generation. Existing methods typically intertwine these components, employing special tokens for timestamp outputs, yet rarely encode event-level visual semantics within temporally grounded representations. This coupling leads to suboptimal inductive biases and impedes faithful evidence-based answering, particularly for tasks requiring fine-grained event comprehension.
The D2VLM Framework
The D2VLM framework adopts a factorized learning approach that structurally decouples temporal grounding from text response generation, while explicitly maintaining their logical dependency. D2VLM enforces a two-stage autoregressive process: (1) a pure grounding phase localizes and captures essential event-level evidence, and (2) an interleaved text-evidence response phase generates answers with explicit referencing to grounded events.
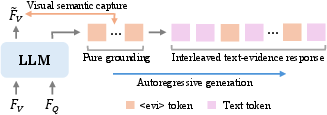
Figure 1: Conceptual demonstration of the D2VLM framework, including model architecture, decoupled grounding-then-answering paradigm, and introduction of evidence tokens enabling event-level semantic capture.
A central technical contribution is the introduction of the <evi> evidence token. Unlike classical grounding tokens that primarily encode timestamps, <evi> tokens are designed to aggregate event-level visual semantics directly from frame-wise encodings. Upon instantiation, token-feature similarity is computed between <evi> and all frame tokens; the evidence token pools salient frame semantics—determined by similarity thresholds—yielding enhanced representations aligned with the grounded event.

Figure 2: Visualization of the visual semantic capture process for the <evi> token, showing pooling from salient frame-level video tokens.
This mechanism allows D2VLM to model not just the temporal location, but also to encode the visual context underpinning downstream answers, which is crucial for robust next-token prediction and evidence-based reasoning.
A further architectural novelty is in the interleaved text-evidence response: after grounding, the model is trained to autoregressively generate both text and <evi> tokens, referencing earlier evidence to enforce answer-consistency with grounded intervals—a property regularized by an explicit stage-wise consistency loss. An auxiliary loss term is defined to align <evi> representations across grounding and answering phases, ensuring logical coherence and event consistency at both token and semantic levels.
Factorized Preference Optimization (FPO)
Recognizing that existing video preference optimization schemes inadequately separate textual relevance and temporal precision, the authors introduce Factorized Preference Optimization (FPO). FPO directly incorporates probabilistic temporal grounding into the preference learning objective, enabling joint alignment for both grounding and language components.
Distinct from conventional preference optimization, FPO requires preference-labeled pairs that differ in specific factors: errors in temporal grounding (e.g., interval shifts, missed/added events) and/or semantic text corruption. To circumvent the lack of suitable human-annotated data, the authors propose a fully automated, event-level synthetic data generation pipeline.
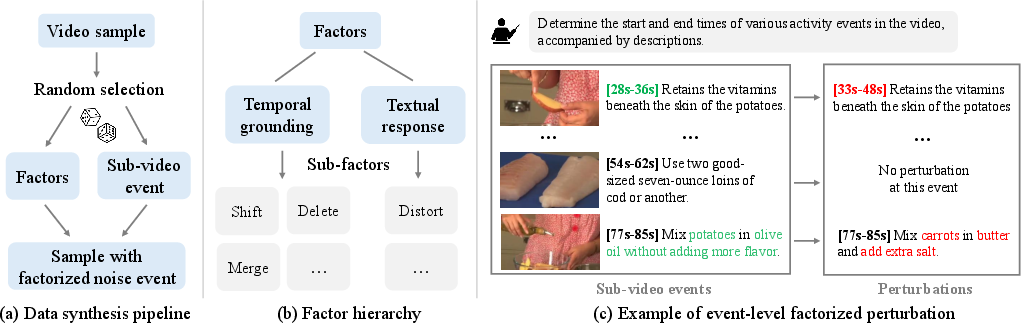
Figure 3: Data synthesis pipeline visualizing injection of factorized perturbations on either temporal grounding or textual factors to generate dispreferred samples.
Randomly selected events in reference responses are perturbed by precise mechanisms (interval shifts, deletions, semantic text distortions, or repeats) to generate well-controlled, multi-factor preference pairs.
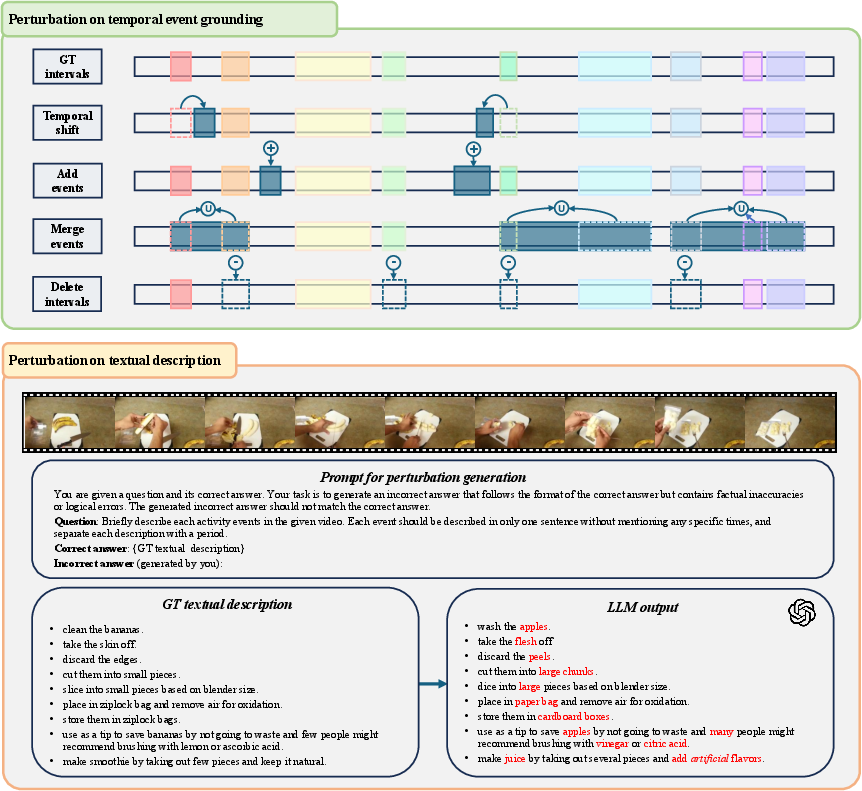
Figure 4: Example illustrating how the data synthesis framework produces positive and negative response pairs with controlled perturbations at the event level.
The probability computation for temporal grounding during FPO leverages the frame-evidence similarity: the log-probability of grounding is computed via the product of per-frame similarities within proposed intervals, integrated into the joint likelihood formulation for preference-based optimization.
Empirical Results
Extensive benchmarking is conducted on E.T. Bench Grounding (temporal localization), E.T. Bench Dense Captioning, Charades-STA (moment retrieval), and YouCook2 (dense captioning).
The D2VLM-3.8B model consistently outperforms recent state-of-the-art (SOTA) methods. For example, on E.T. Bench Grounding, D2VLM achieves a 42.3% avg F1 score, surpassing SOTA by at least 7% while maintaining a much smaller parameter count than rival solutions (3.8B vs. 7–13B). Similarly, on YouCook2, D2VLM attains 26.4% F1, 10.6 CIDEr, and 3.2 SODA_c, outperforming all baselines on both event localization and semantic caption quality.
Qualitative examples further demonstrate that D2VLM yields more precise grounding, generates more informative and less repetitive captions, and answers video questions in a manner that is highly consistent with grounded visual events.

Figure 5: Diverse qualitative examples on grounding-focused, dense captioning, and temporally grounded QA tasks, showcasing model outputs that align visual evidence and textual answers.
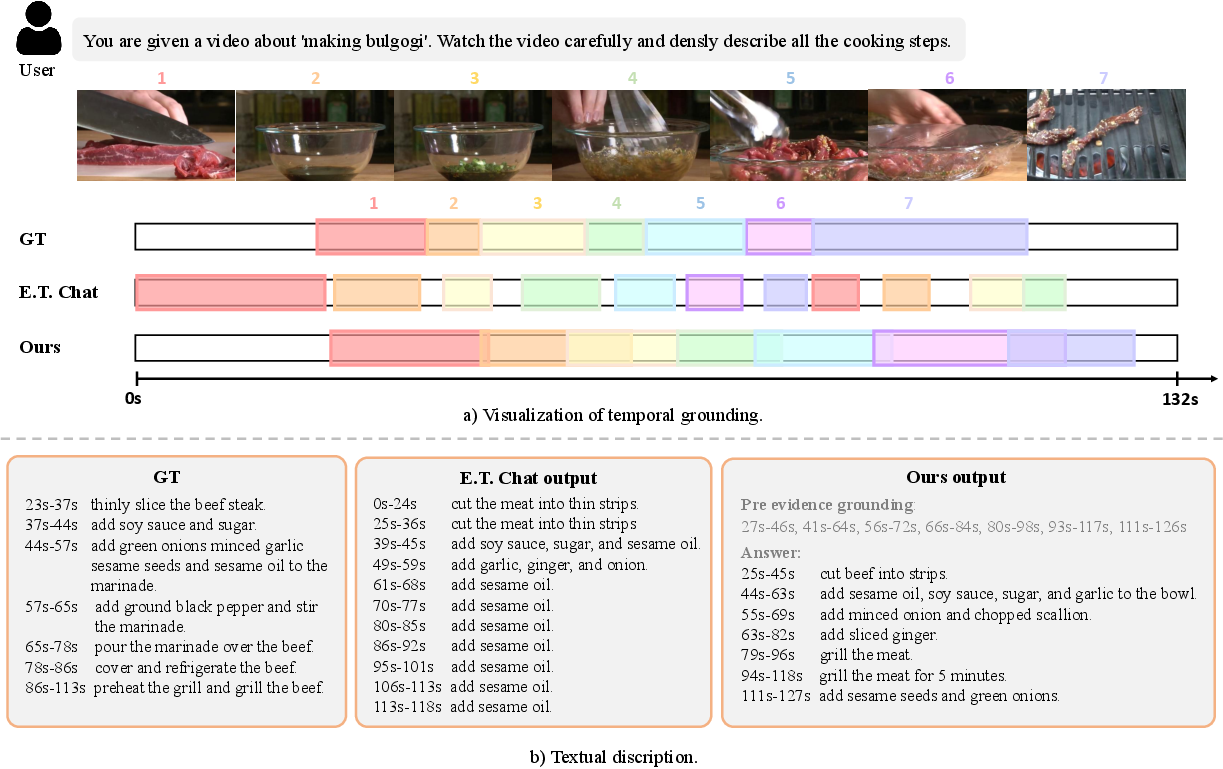
Figure 6: Detailed qualitative result for the dense captioning task, revealing event-level segmentation and semantic adequacy of generated captions.
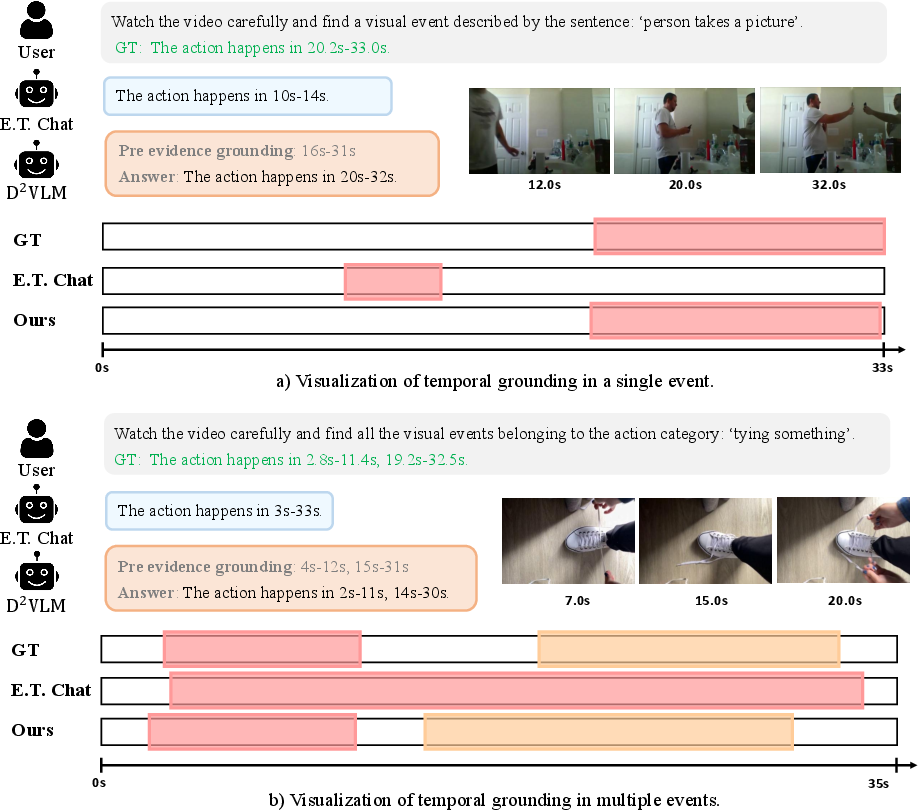
Figure 7: Qualitative grounding-focused results highlighting fine-grained event segmentation capabilities.

Figure 8: Temporally grounded video question answering, demonstrating the answer's explicit alignment with event-level evidence.
Ablation studies reveal that both the event-level modeling in <evi> tokens and explicit visual semantic capture are essential; disabling these components degrades both grounding and text generation. FPO yields further performance improvements, particularly in temporal grounding accuracy.
Theoretical and Practical Implications
This work generalizes the paradigm of factorized multi-task learning and preference optimization to the temporally grounded video-language domain. The explicit modeling of evidence as both temporally and visually semantic entities advances the fidelity of evidence-conditioned text generation. FPO introduces a modular learning signal that can be extended to other compositional tasks requiring disentangled reasoning (e.g., spatial grounding plus language, multimodal event parsing, or multi-step instructional videos).
On the practical front, the synthetic data pipeline enables controlled preference optimization at scale, avoiding annotation bottlenecks, and establishing a foundation for robust, scalable instruction tuning in complex video-language systems.
The findings suggest future research directions in multi-factor preference learning, better joint modeling of evidence and answer, and expansion to other modalities or domains where grounding and answer generation must be tightly yet transparently linked.
Conclusion
The D2VLM architecture and associated FPO algorithm introduce a technically rigorous framework for disentangling and jointly optimizing temporal grounding and textual response in video-LLMs. The explicit incorporation of event-level visual semantics, interleaved evidence-text generation, and multi-factor synthetic preference data yield consistent SOTA results across grounding, captioning, and question answering tasks. While the approach is currently limited to negative sample synthesis and modest F1 levels on some tasks, the architecture’s modularity and data efficiency set the stage for further advances in scalable, explainable, temporally grounded understanding in video-language intelligence systems (2512.24097).