- The paper introduces OmniScript, a framework that utilizes hierarchical scene-event parsing and chain-of-thought reasoning for structured audio-visual script generation.
- It leverages a memory-augmented annotation pipeline with a Character Profile Manager to maintain consistent narrative and character identities across extended videos.
- Empirical evaluations show competitive event and scene-level metrics, demonstrating efficient long-context processing and superior dialogue extraction compared to baseline models.
Introduction and Motivation
The task of video-to-script generation for long-form cinematic content presents multifaceted technical requirements: temporally grounded understanding of audio-visual streams, cross-scene character tracking, and the production of fully structured, interpretable scripts incorporating dialogue, actions, expressions, and environmental cues. The "OmniScript" framework (2604.11102) defines and operationalizes this Video-to-Script (V2S) task, emphasizing hierarchical scene-event parsing and precise multimodal field annotation in real narrative settings. This work both establishes a stringent benchmark for the field and introduces an advanced omni-modal model with competitive parameter efficiency.
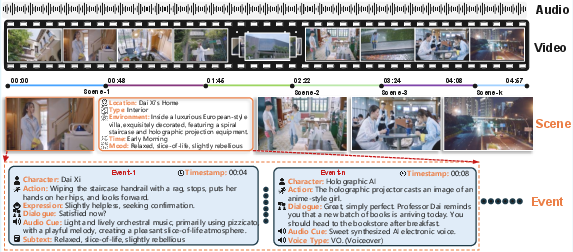
Figure 1: Overview of the Video-to-Script (V2S) framework, which decomposes cinematic videos into hierarchically structured, multimodal scripts.
The paper identifies significant gaps in previous literature: existing datasets are limited by low annotation density and short-clip bias, and current evaluation metrics—based primarily on n-gram or tIoU—fail to reflect open-vocabulary narrative quality or temporal alignment. OmniScript addresses these through a novel dataset and an explicit, temporally aware hierarchical evaluation protocol, integrating LLM-based alignment, name-resolution, and similarity judgment modules.
Data Generation and Memory-Augmented Annotation Pipeline
To circumvent the annotated data bottleneck in long-form, multimodal settings, OmniScript introduces a memory-augmented, CoT-driven annotation engine. A central component is the Character Profile Manager (CPM), which accumulates, reconciles, and updates character profiles across scenes, ensuring intra- and inter-segment identity consistency—a critical requirement for coherent narrative extraction in full-length video.
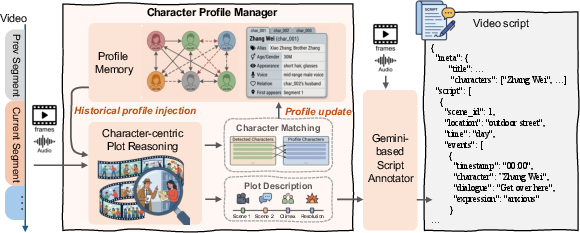
Figure 2: Memory-augmented annotation pipeline applying historical character profiles and reasoning chains to drive Gemini-based fine-grained script annotation.
By leveraging expert models (e.g., Gemini-2.5-Pro, DeepSeek), the pipeline first segments raw video into manageable chunks with preserved narrative structure, performs character-centric plot reasoning, and creates detailed CoT annotations. This hierarchical reasoning forms the backbone of high-quality supervised data, enabling the model to learn explicit narrative logic, scene and event boundaries, and robust character identification despite costume or context shifts.
The OmniScript schema is strictly hierarchical, supporting meta, scene, and event levels, with each event containing timestamped attributes—character, action, dialogue, expression, and audio cue.
A central theoretical contribution is the evaluation pipeline: text-based event alignment using composite semantic similarity and temporal proximity, LLM-assisted identity resolution (bipartite graph construction and fallback mapping), fine-grained field evaluation with context-insensitive similarity scoring, and isolated group-level tIoU analysis. This four-stage metric objectively evaluates precision, recall, and F1 at each schema level.
Dataset curation was performed across 10 genres, yielding 19.9 hours of dense, expert-verified annotation with average event densities exceeding 14 per minute—far above previous benchmarks. The resulting testbed supports variable clip durations (5–30 min), stress-testing models for long-context retention, narrative coherence, and open-world entity disambiguation.
Model Architecture and Training
OmniScript is instantiated as an 8B parameter Qwen3-VL-based model with a customized AV-DeepStack fusion block for deep hierarchical audio-visual integration.
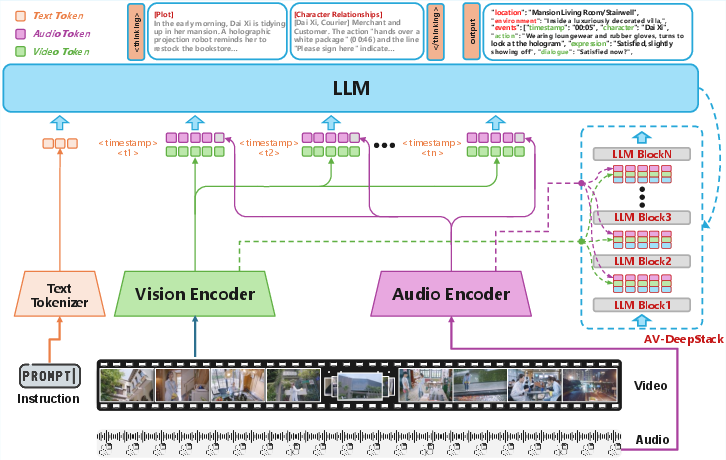
Figure 3: Multimodal LLM architecture. Video and audio are temporally tokenized and fused via AV-DeepStack. Scene/event fields are predicted after an explicit reasoning/tracing stage.
Visual frames and Whisper-extracted audio are aligned into timestamp-indexed token pairs, injected via residual multimodal adapters across the transformer stack. The decoder enforces a chain-of-thought regime—first generating a common-sense plot trace and character-relationship state, then decoding highly structured scene-event outputs. This captures semantic dependencies across long horizon dependencies and supports cross-modal attribute fusion (e.g., speaker detection, implicit expression reasoning).
Training employs a progressive four-stage pipeline: audio-visual alignment (modality projector tuning using ASR targets), large-scale multimodal pretraining (temporal grounding, action/dialogue fusion), supervised fine-tuning with high-density CoT supervision, and reinforcement learning with event-level, temporally segmented rewards optimizing F1.
Long Video Decoding Strategies
Standard models suffer catastrophic degradation on hour-scale videos. OmniScript systematically compares two architectural strategies for scaling context:
- Long Context Extension (LCE): Expands the context window, trains with both native and pseudo-long synthetic data (cross-video composition with annotation merging). This strategy directly tests long-horizon memory and global reasoning.
- Two-Stage Script Generation (TSG): A planning-decoding cascade: (1) LLM-based segmentation into plot-anchored units, (2) segmentwise script generation with injected context, followed by global merging and consistency enforcement.
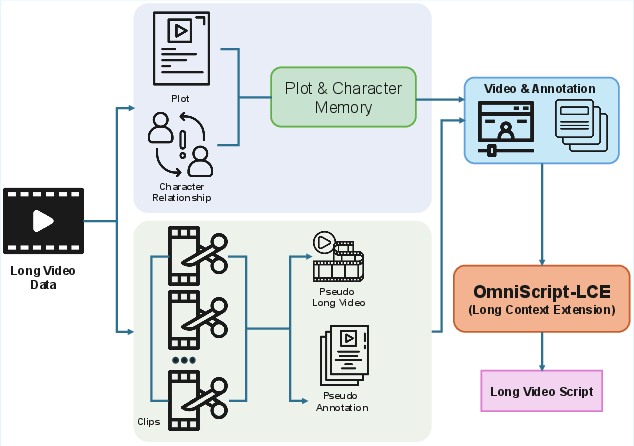
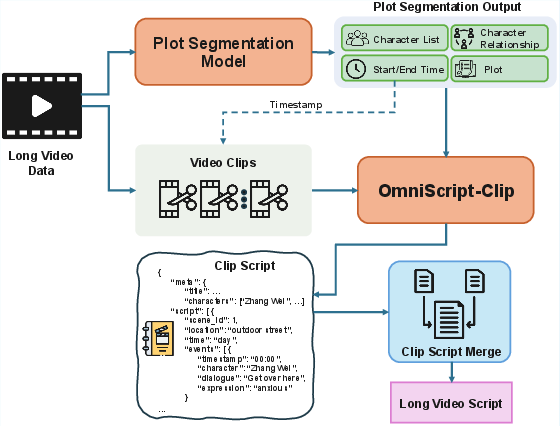
Figure 4: Long context extension paradigm for end-to-end decoding of extended video inputs.
Empirical results establish that TSG exhibits near length-invariance in output quality, fundamentally outperforming all baselines—including parameter-multiplied proprietary systems—for video durations exceeding 30 minutes. LCE retains moderate-length advantage (~20 minutes) and demonstrates superior resilience compared to open-source and even closed-source vision-LLMs.
Quantitative and Qualitative Results
Comprehensive experiments reveal several key findings:
- With only 8B parameters, OmniScript achieves Overall Event F1 (37.7) and [email protected] (69.3), distinctly outperforming much larger open models (e.g., Qwen3VL-235B), and closely matching Gemini 3-Pro for both semantic and temporal precision.
- On scene-level metrics, OmniScript delivers competitive performance (Overall 52.4, [email protected] 74.6), with robustness under subtitle-masked regimes—showing dramatically less performance drop compared to vision-only systems.
- OmniScript's AV-DeepStack outperforms vision-only ablations by >16 points F1 on dialogue, confirming the necessity of multimodal alignment for narrative transcription.
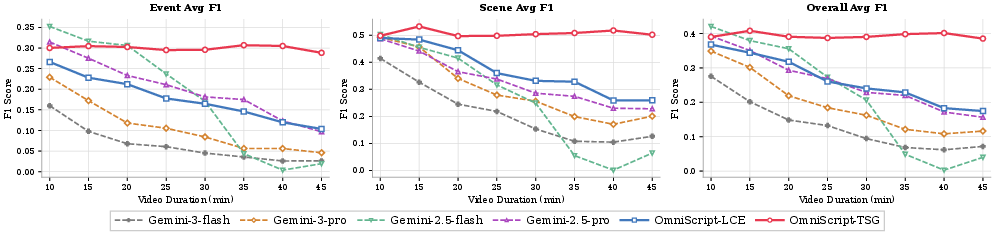
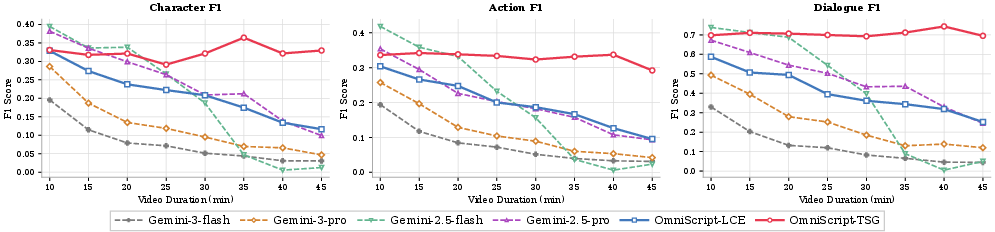
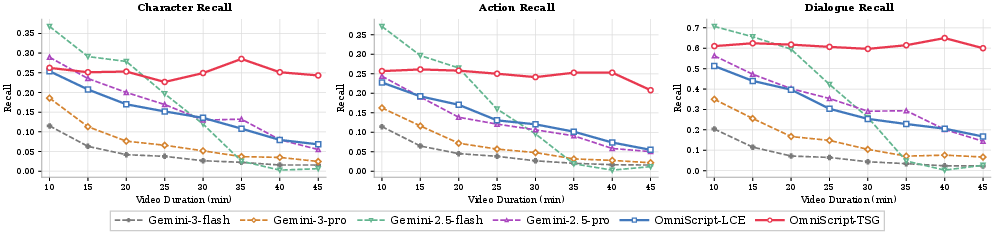
Figure 5: Event-level, scene-level, and overall F1 score curves as a function of increasing video duration.
Ablation studies confirm the additive gains of chain-of-thought decoding (+1.7 to Overall F1), RL alignment (+0.7), and temporally segmented event rewards (critically, outperforming global reward structuring by emphasizing distributed recall and boundary precision).
Qualitative analysis of outputs demonstrates high-fidelity scene segmentation, massively improved dialogue and implicit relationship tracking, and explicit logical consistency in the generated script entities. The CPM-track stabilized memory is robust under repeated costume, setting, or name changes (Figure 6).
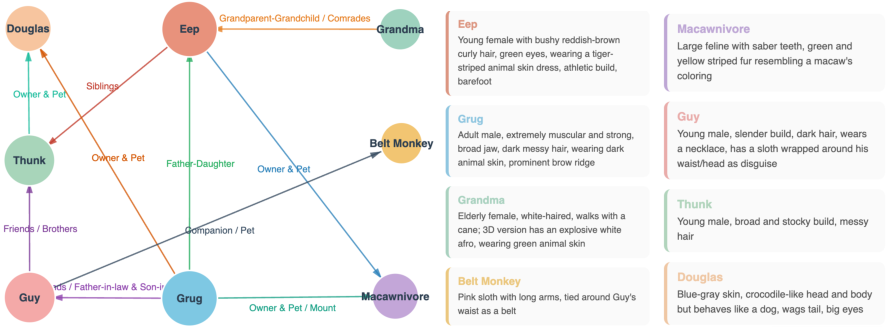
Figure 6: Visualization of Character Profile Manager output for sustained identity tracking across a cinematic narrative.

Figure 7: Example OmniScript output showing interpretable, temporally-synchronized, multi-field event and scene annotation for a full video.
Practical and Theoretical Implications
OmniScript substantiates that compact, chain-of-thought-enabled, audio-visual LLMs, judiciously trained on highly structured, temporally aligned data, are now competitive for complex, high-resolution narrative tasks traditionally reserved for much larger models. It sets a baseline for the automation of cinematic script logging, retrieval, and cross-modal content mining at scale, relevant for industrial pipelines and long-form media analysis.
The research demonstrates that fixed-context architectures have a sharply bounded context-length ceiling due to cumulative dependency and identity drift; in contrast, two-stage planning architectures decouple error propagation and offer scalable narrative retention. This insight extends to other sequence-to-structure tasks across multimodal time series domains.
Open theoretical questions persist regarding generalized evaluation for narrative generation, the construction of globally coherent reward signals for RL post-training, and the upper bounds of efficiency vis-a-vis scene granularity, event-field density, and open-world vocabulary.
Conclusion
OmniScript (2604.11102) formalizes and solves the problem of long-form, hierarchical, multi-field script generation from audio-visual streams, introducing both a new benchmark and a strongly parameter-efficient reference model. By integrating memory-augmented reasoning, temporally aware evaluation, and robust cross-modal fusion, OmniScript advances the state of the art for holistic cinematic video understanding. Future work will likely build on its hierarchical, event-driven alignment protocols and two-stage narrative segmentation methods for extending model capability and efficiency in even broader applications.