- The paper introduces ABMamba, a multimodal LLM that replaces transformer backbones with a Deep SSM for linear-time video sequence modeling.
- The AHBS module enables hierarchical, bidirectional, multi-resolution temporal abstraction, resulting in up to 3x faster decoding and improved captioning performance.
- Experimental results on VATEX and MSR-VTT benchmarks show significant BLEU4, CIDEr, and ROUGE gains alongside enhanced memory efficiency.
ABMamba: A Fully Open Multimodal LLM with Aligned Hierarchical Bidirectional Scan for Video Captioning
Introduction and Motivation
ABMamba introduces a fully open multimodal LLM (MLLM) tailored for efficient and scalable video captioning (2604.08050). Traditional transformer-based approaches exhibit prohibitive computational complexity when applied to long video sequences due to the quadratic scaling of self-attention. This impedes real-time and large-scale video understanding applications. Existing solutions commonly rely on aggressive input compression which systematically eliminates fine-grained temporal information, negatively impacting captioning accuracy.
ABMamba addresses these shortcomings through two primary architectural advances: (1) replacing the transformer backbone with a Deep State Space Model (Mamba) enabling linear-time sequence modeling and (2) introducing the Aligned Hierarchical Bidirectional Scan (AHBS) module, which performs explicit, multi-resolution, bidirectional modeling of the complex temporal dynamics specific to video data.
Model Architecture
ABMamba comprises three main components: a dual-encoder vision backbone, the AHBS module for hierarchical temporal abstraction, and a Mamba-based LLM for multimodal fusion and caption generation.
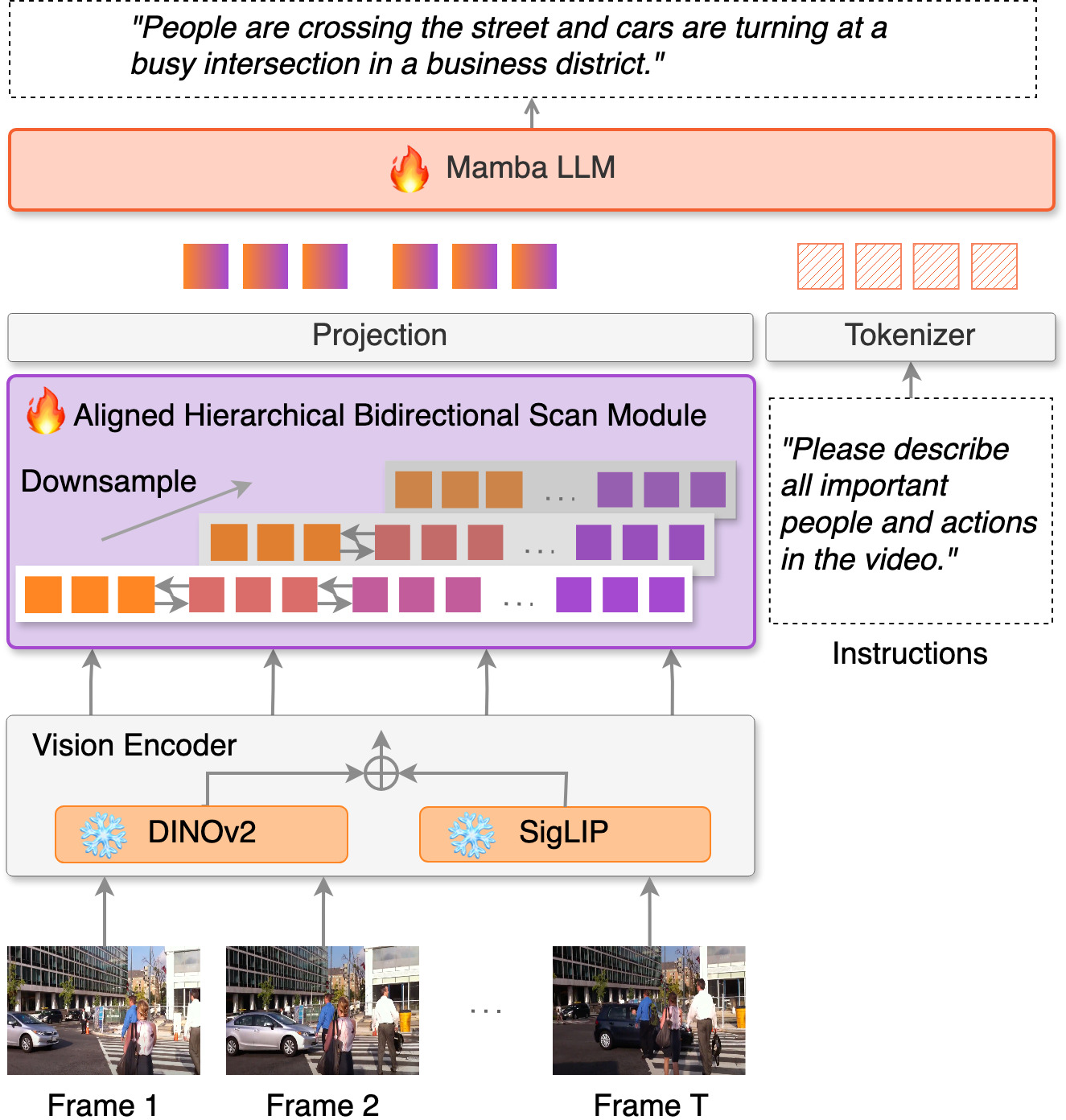
Figure 2: Overall architecture of ABMamba: dual vision encoder, AHBS module for hierarchical temporal modeling, and Mamba-based LLM for sequence processing.
Vision Encoder
The model employs SigLIP and DINOv2 as vision encoders, motivated by their complementary strengths—SigLIP provides robust image-text semantic alignment while DINOv2 yields fine-grained self-supervised visual features. Each video frame is patchified and encoded through both models, with features concatenated to form a detailed multimodal representation.
Aligned Hierarchical Bidirectional Scan (AHBS)
The AHBS module is the crux of ABMamba’s temporal modeling strategy. It applies spatial downsampling to encode frames into token sequences, then operates over multiple parallel temporal pathways—each with different resolutions—allowing modeling of both fine and coarse temporal granularity. In each path, bidirectional scan modules propagate information in both forward and backward directions across the sequence. Aggregating multiple such paths ensures robust coverage of hierarchical and non-causal temporal dependencies absent in prior approaches.
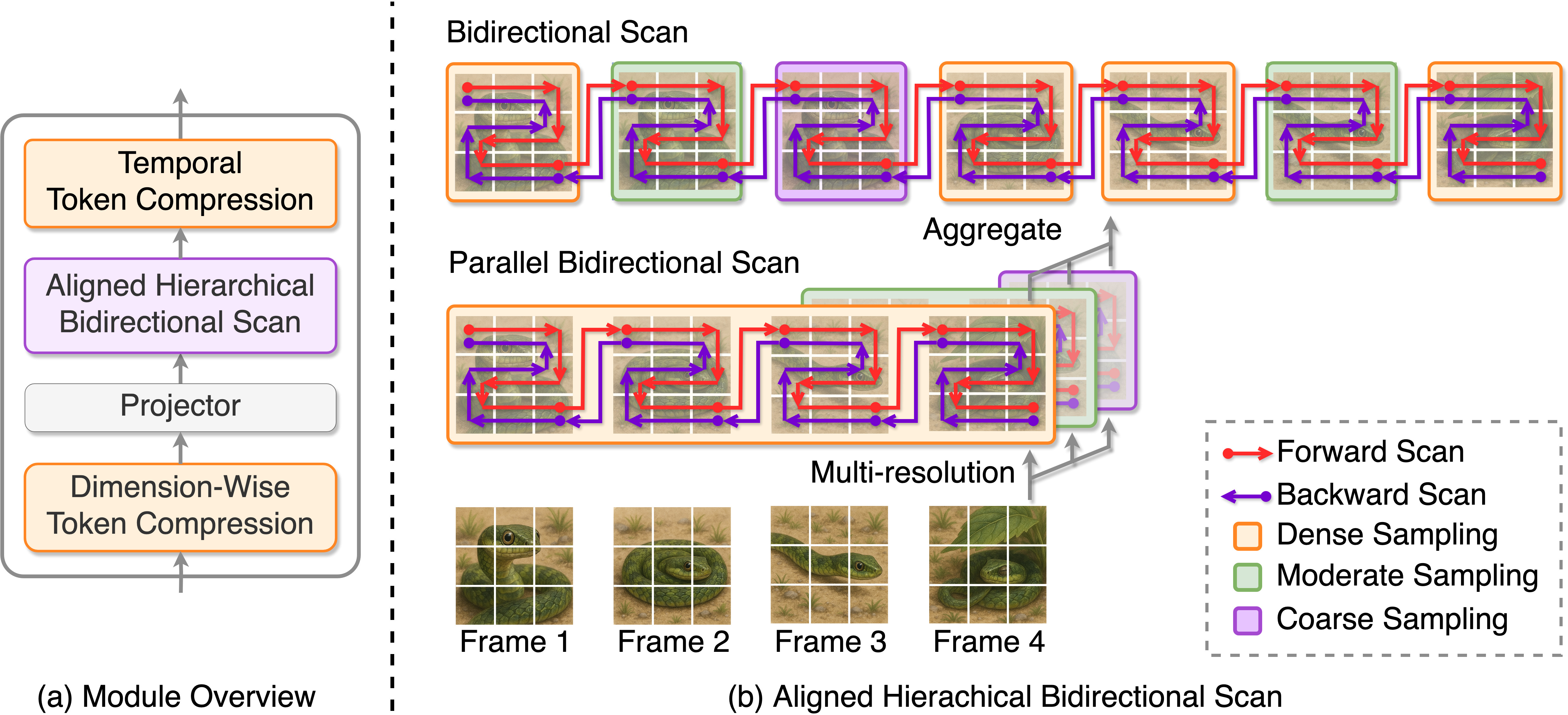
Figure 1: Schematic of the AHBS module, highlighting hierarchical, multi-resolution bidirectional scanning and sequential aggregation.
This architectural choice surpasses simple downsampling or unidirectional scan by maintaining sub-quadratic complexity while preserving sequential cues necessary for causal and associative temporal understanding.
Mamba-Based LLM Backbone
The language encoder is an instantiation of the Mamba Deep SSM. It takes as input the concatenation of the AHBS-projected vision tokens and text prompt embeddings. The selective scan mechanism in Mamba allows dynamic control of its state transitions, endowing the model with adaptivity crucial for handling long, heterogeneous multimodal contexts. This is directly aligned with recent evidence favoring Deep SSMs over transformers for large-scale sequence tasks.
Experimental Results
Datasets and Baselines
ABMamba is evaluated on VATEX and MSR-VTT—two established open-domain benchmarks for video captioning. Competing baselines include both fully open and small proprietary MLLMs (e.g., Video-LLaVA, LLaVA-OneVision, InternVL2.5) and the proprietary Gemini-1.5-Pro.

Figure 3: Use-case demonstration—ABMamba generates descriptive video captions contextualized by a user-supplied prompt.
Quantitative Results
ABMamba achieves the highest BLEU4 scores of 28.6 (VATEX) and 23.6 (MSR-VTT), surpassing the strongest non-proprietary competitor by 4.1 and 0.3 points, respectively. CIDEr and ROUGE scores also consistently favor ABMamba or are competitive among sub-7B parameter models.
The most significant finding is the throughput improvement: ABMamba achieves an average decoding speed of 95.4 tokens/s (MSR-VTT), which is ~3x faster than the best open baseline, attributed to the linear complexity of the Mamba-based SSM in contrast to transformer attention’s quadratic scaling.
Qualitative Results
ABMamba’s captions exhibit higher fidelity with respect to object/action composition, scene structure, and dynamic context alignment compared to InternVL2.5 and LLaVA-OneVision. On challenging video queries—especially those requiring multi-actor or composite temporal event modeling—ABMamba’s generated captions closely approximate reference texts, while baselines either hallucinate or under-describe scenario details.
Ablation and Analysis
Ablation experiments demonstrate that omitting bidirectionality or hierarchical temporal structure in AHBS degrades BLEU4 by up to 10 points and CIDEr by up to 17 points. Increasing the number of temporal branches in AHBS provides measurable gains, with performance maximizing at three branches and a stride of two—confirming the necessity of multi-resolution modeling of video dynamics.
Error analysis reveals the primary failure modes as object and action hallucination or local context bias, stemming from insufficient fusion. Lexical mismatch with references—prevalent across benchmarks—also affects automatic metrics but less so qualitative assessment.
Practical and Theoretical Implications
The main practical implication is that sub-quadratic sequence modeling with Deep SSMs enables real-time video-language understanding at scale. Memory efficiency is increased approximately 4x over transformer baselines, suggesting immediate deployability in resource-constrained or latency-limited environments.
ABMamba’s fully open recipe (code, weights, and data) lowers the barrier for foundational research and downstream applications—robotics, assistive vision, and video analytics—where transparent, reproducible benchmarks are essential. The modularity of AHBS suggests possible transfer to other sequence processing and multimodal XL tasks, beyond video captioning—for instance, video-QA and action recognition.
On the theoretical front, the results reinforce that transformer attention is not a strict requirement for effective temporal abstraction in multimodal domains. The selective, hierarchical, bidirectional SSM construction matches or exceeds transformer representations when carefully architected, opening avenues for new model classes in long-context vision-language reasoning.
Future Directions
Several directions are promising: (1) Integrating fine-grained vision-language fusion earlier in the pipeline, e.g., utilizing cross-modal AHBS blocks, (2) extending AHBS for dialogue-level or multi-turn video reasoning, (3) adaptation to instructional, long-form, or real-time video annotation contexts, and (4) rigorous analysis and mitigation of hallucination via diagnostic datasets and loss variants.
Conclusion
ABMamba establishes a new framework for efficient video captioning using a fully open multimodal LLM powered by Deep State Space Models and hierarchical, bidirectional, multi-resolution temporal abstraction. The model outperforms contemporaneous open models in both accuracy and speed, with favorable implications for real-world scalable video-language understanding. The introduction of AHBS and confirmation of SSMs’ utility in the video-language domain provide a robust foundation for further advances in multimodal LLM architectures.