mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs
Abstract: Prevailing Vision-Language-Action Models (VLAs) for robotic manipulation are built upon vision-language backbones pretrained on large-scale, but disconnected static web data. As a result, despite improved semantic generalization, the policy must implicitly infer complex physical dynamics and temporal dependencies solely from robot trajectories. This reliance creates an unsustainable data burden, necessitating continuous, large-scale expert data collection to compensate for the lack of innate physical understanding. We contend that while vision-language pretraining effectively captures semantic priors, it remains blind to physical causality. A more effective paradigm leverages video to jointly capture semantics and visual dynamics during pretraining, thereby isolating the remaining task of low-level control. To this end, we introduce mimic-video, a novel Video-Action Model (VAM) that pairs a pretrained Internet-scale video model with a flow matching-based action decoder conditioned on its latent representations. The decoder serves as an Inverse Dynamics Model (IDM), generating low-level robot actions from the latent representation of video-space action plans. Our extensive evaluation shows that our approach achieves state-of-the-art performance on simulated and real-world robotic manipulation tasks, improving sample efficiency by 10x and convergence speed by 2x compared to traditional VLA architectures.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Robots learn from data. Many recent robot models learn from pictures and text (like captions) found online. That helps them understand “what” things are and “what” people want. But pictures and words don’t show “how things move” over time. This paper says: to teach robots how to act better, we should learn from videos, because videos show the step-by-step motion and physics of the world.
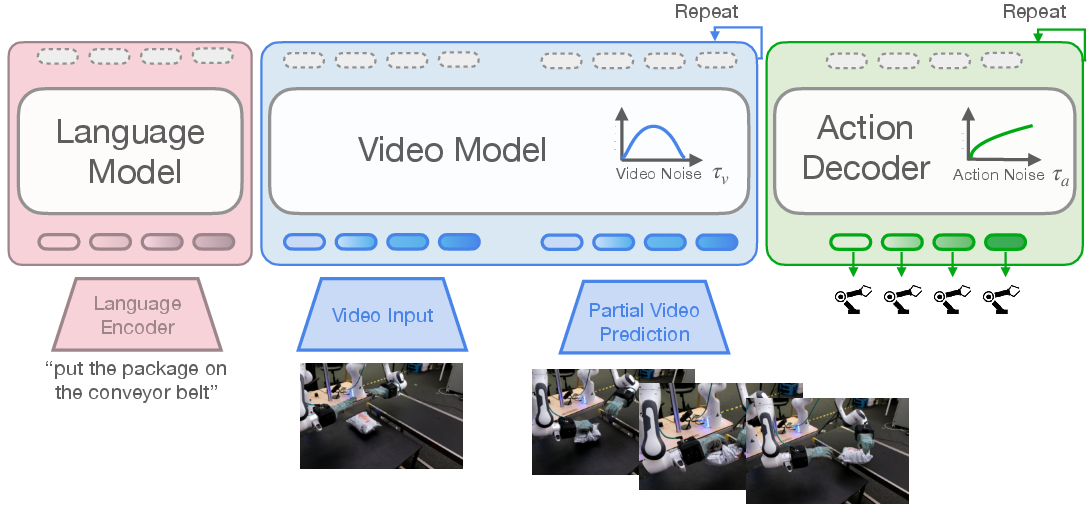
The authors introduce “mimic-video,” a new kind of model they call a Video-Action Model (VAM). It uses a powerful video model (trained on tons of internet videos) to imagine a rough future “visual plan” of what should happen, and then a small “action decoder” turns that plan into the robot’s actual motor commands.
Main idea in one sentence
Instead of learning the laws of motion from scratch, mimic-video borrows them from a big video model and focuses the robot’s learning on the simpler job: turning a visual plan into precise actions.
What were the goals?
- Make robots learn with much less expert robot data.
- Help robots handle tasks that need understanding of physical cause-and-effect (like stacking, picking, or handing objects).
- Compare using video knowledge (how things move) versus image-and-text knowledge (what things are) for controlling robots.
How does it work? (Everyday explanation)
Think of it like this:
- The video model is a “how-to” expert that has watched millions of clips. It knows typical motion patterns (like how a hand reaches, how objects slide, how doors open).
- The robot first asks this video expert to imagine a short future—like a rough sketch of how the next few moments should look to complete the task.
- Then a small “translator” (the action decoder) converts that sketch into the robot’s “muscle movements” (its low-level motor commands).
A few key pieces:
- Video backbone: A large pre-trained video model (Cosmos-Predict2) that has learned visual dynamics from internet-scale video. It doesn’t need to produce a perfect, full video; it just provides useful internal features that capture “what should happen next.”
- Action decoder (Inverse Dynamics Model): A smaller model that reads those video features and the robot’s current state and outputs the next chunk of actions. It’s like turning the imagined scene into exact joint movements.
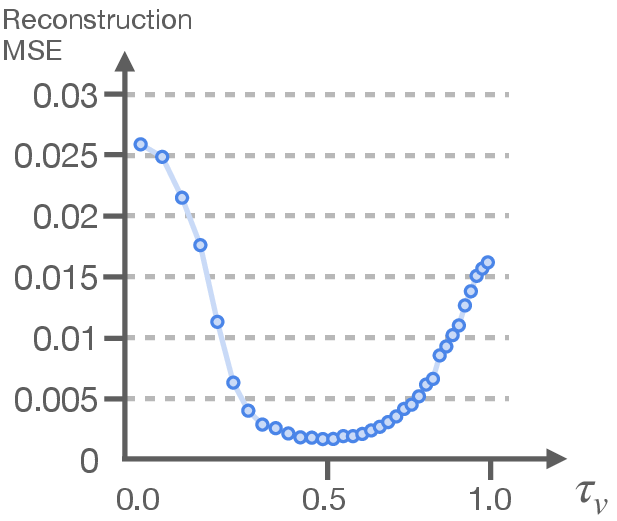
- Flow matching: A training trick where the model learns to turn noise into a clean signal step by step. Imagine starting with a fuzzy picture and gradually clearing it up—this process is used both in the video model and the action decoder. The neat part: for speed and stability, they don’t always “clear up” the whole video; sometimes a rough, partly de-noised plan is best.
- Partial de-noising (τv): Instead of finishing a full, high-detail video prediction, the system stops early at a “blurry but useful” stage. This is often enough to guide the robot and is much faster.
What did they test?
They tried mimic-video in three settings:
- SIMPLER-Bridge (simulation): Tests generalization to new tasks with realistic visuals.
- LIBERO (simulation): Tests learning many precise tabletop tasks with limited examples.
- Real-world bimanual dexterous tasks: Two Panda robot arms with human-like hands doing tricky jobs like sorting packages and stowing a measuring tape, with limited training time.
They compared against:
- Strong Vision-Language-Action (VLA) baselines (which rely on image+text backbones).
- Popular diffusion/transformer-based imitation learning models.
- A carefully matched “π0.5-style” VLA baseline using the same kind of action decoder as mimic-video (to fairly test “video vs image+text” representations).
Main findings (what worked and why it matters)
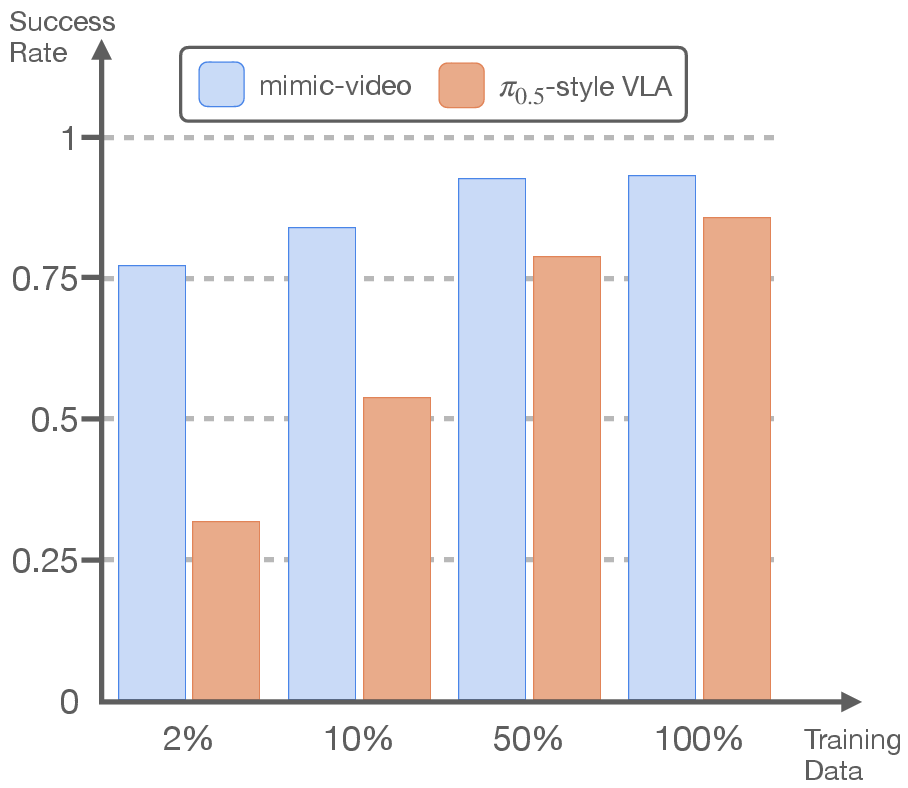
- Much less robot data needed: They report about 10× better sample efficiency than VLA-style models. In other words, mimic-video reaches similar success with roughly one-tenth the action data.
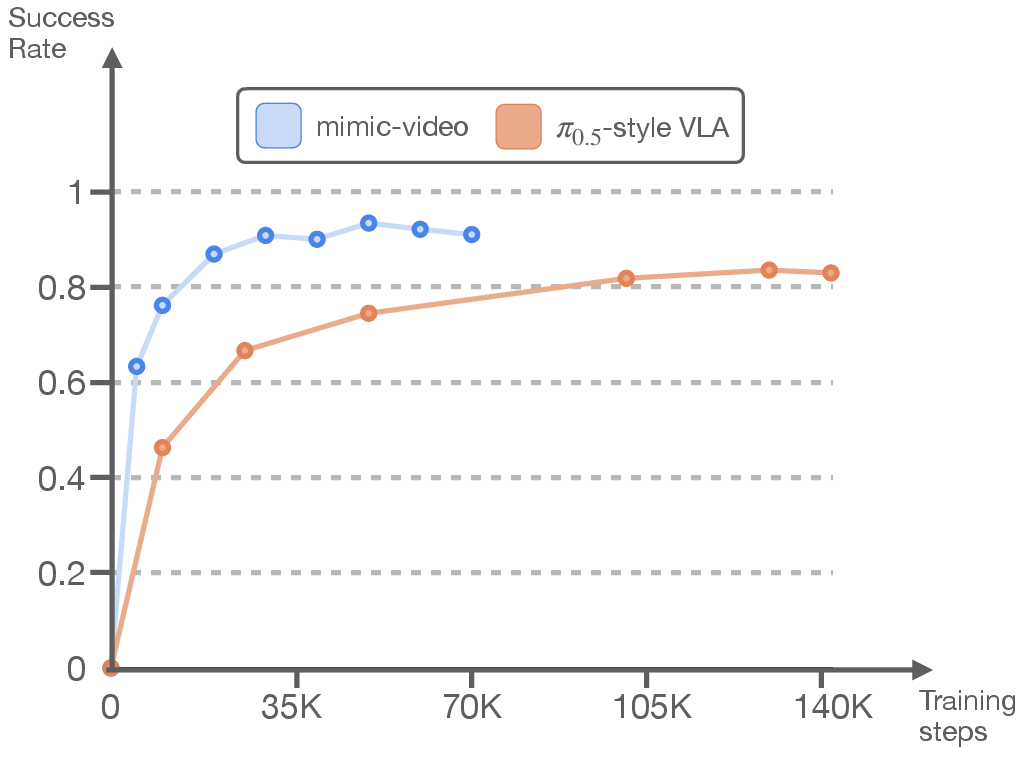
- Faster learning: About 2× quicker convergence during training of the action decoder.
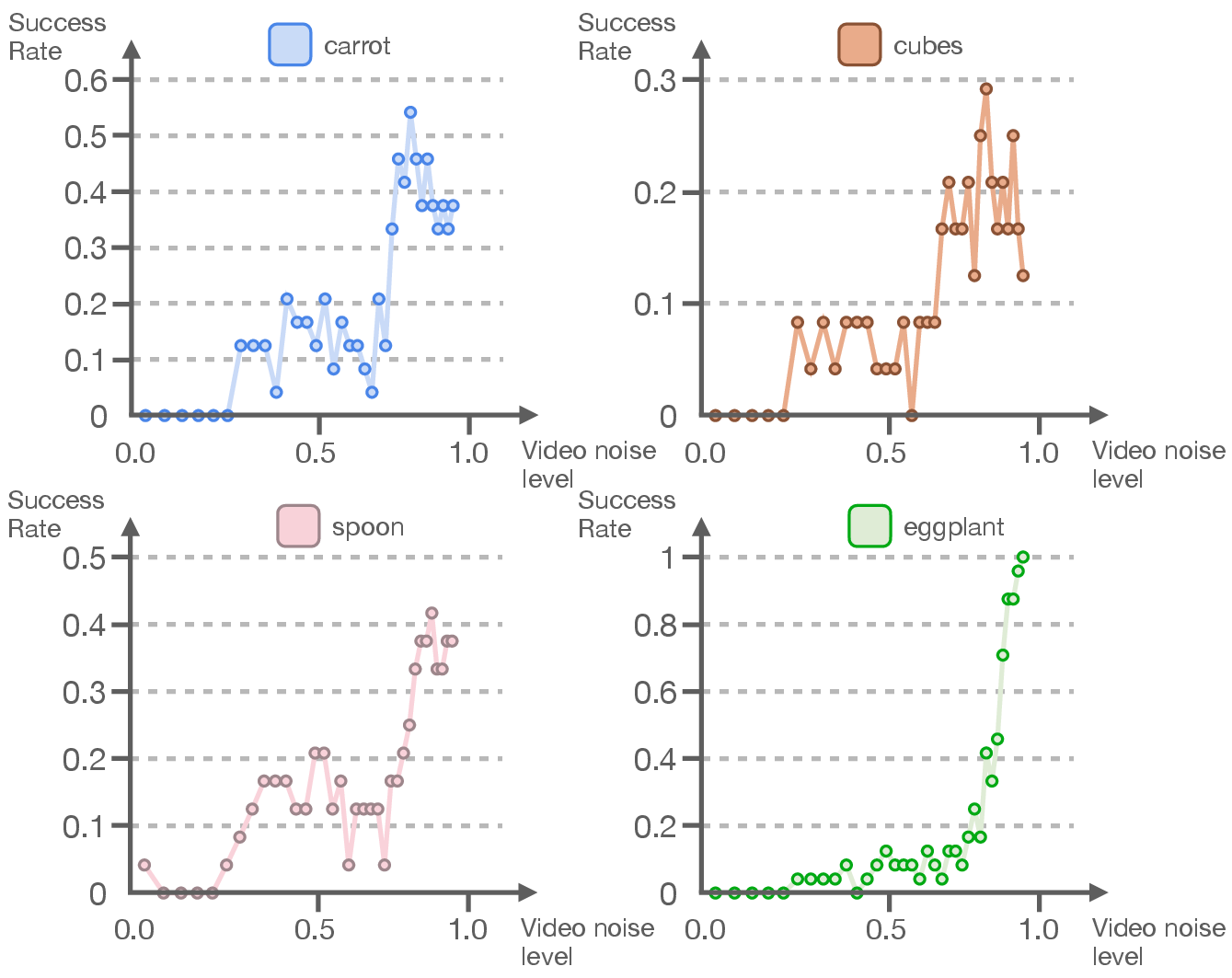
- Strong performance across tasks:
- On SIMPLER-Bridge and LIBERO, mimic-video matched or beat strong baselines—even those fine-tuned from big generalist models—despite training the action part from scratch.
- In real-world bimanual tasks, mimic-video surpassed a strong multi-view baseline while only using a single camera view. Because the video model “knows” how situations unfold, it can cope better with occlusions and uncertainty.
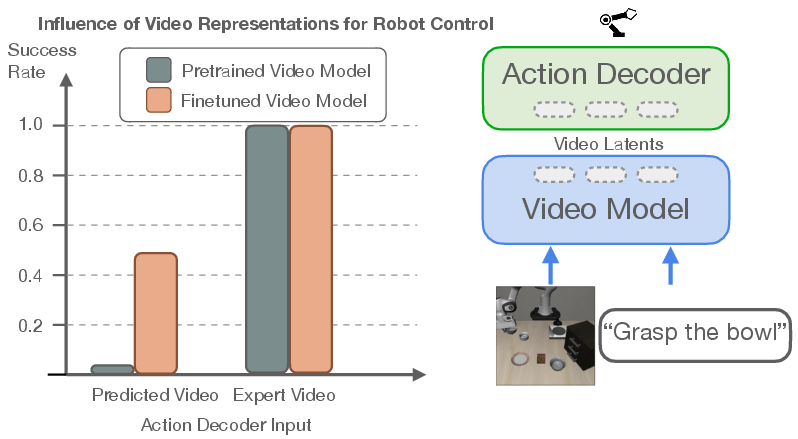
- Better conditioning from video than from image+text: The same action decoder did noticeably better when it was guided by a video model’s internal features than when guided by a vision-LLM’s features.
- You don’t need a perfect video: The best robot performance often came from using partially de-noised, “blurry” video features rather than fully detailed video predictions. That means faster inference and fewer errors from imperfect video generation.
Why this is important
- More practical robots: Collecting expert robot demonstrations is slow and expensive. If we can train effective policies with far fewer demonstrations by leveraging video pretraining, robots become cheaper and faster to develop.
- Better physics understanding: Video naturally contains motion and cause-and-effect. By tapping into that, robots can learn more realistic and robust behaviors.
- Faster, simpler control: Offloading “thinking about the future” to the video model lets the action decoder focus on a simpler task. This separation can make robot control more stable and efficient.
Final takeaway
mimic-video shows a new path: ground robot control in what videos already teach very well—how things move—then translate that into actions. This approach makes robots learn faster, use much less data, and handle complex, real-world tasks more reliably. In the future, extending this to multi-view video models and bigger, cross-robot training could make general-purpose robot skills even more capable and accessible.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Multi-view visual grounding: The approach uses a single-view video backbone; it does not explore native multi-view video models or fusion of workspace and wrist cameras, limiting occlusion robustness and 3D spatial reasoning.
- Cross-embodiment unification: A single, unified VAM that conditions on robot morphology/kinematics to generalize across embodiments is not trained or evaluated; current results rely on task/embodiment-specific decoders.
- Real-time performance characterization: End-to-end latency, control frequency, and compute requirements (GPU type, memory, batch size) are not quantified; it is unclear how reliably the 2B video backbone supports real-time control on typical robot hardware.
- τ_v selection and adaptation: Although τ_v strongly affects performance, there is no principled or adaptive mechanism to select τ_v per task/timestep; the paper defaults to τ_v=1 without online tuning or uncertainty-aware control.
- Theory linking τ_v, representations, and control: The counterintuitive finding that high noise (large τ_v) often helps performance lacks a formal explanation; no theory connects mutual information, intermediate activations, and action decoding quality.
- Intermediate-layer choice (k): The action decoder cross-attends to an empirically chosen video-layer k; there is no analysis or method to select k systematically, nor ablations on how k interacts with τ_v and task difficulty.
- Joint versus decoupled training: The video backbone is frozen for action decoding; the trade-offs of partial or joint fine-tuning (e.g., selective adapters, “knowledge insulation” vs. performance) are not studied.
- Robustness to video model prediction errors: The method assumes video latents provide reliable plan features, but it lacks mechanisms (e.g., confidence estimation, ensembles, consistency checks) to detect and mitigate plan errors or distribution shift.
- Closed-loop re-planning strategies: How frequently to regenerate visual plans, when to re-plan under deviations, and how to integrate action-conditional rollouts are not explored; the chunking horizon H and its effects are unspecified.
- Long-horizon task scaling: The approach is not evaluated on substantially longer tasks requiring multi-stage subgoal discovery or hierarchical planning; it is unclear how visual plans scale beyond short chunks.
- Failure mode analysis: Tasks like “Stack Blocks” exhibit lower performance; the paper does not analyze failure sources (e.g., perception errors, contact modeling, grasp failures) or propose targeted mitigations.
- Language grounding breadth: The method’s language-following ability is tested only on narrowly scoped instructions; it does not evaluate open-vocabulary generalization, compositional instructions, or instruction ambiguity resolution.
- Action multi-modality and causality: The decoder is framed as a (largely unimodal, non-causal) inverse dynamics model; there is no analysis of tasks requiring causal, multi-modal, or long-horizon credit assignment beyond short action windows.
- Sensor modality limits: Only RGB and proprioception are used; the benefits of adding depth, tactile, or force/torque sensing—especially for dexterous contact-rich tasks—are not investigated.
- Data regime clarity for video fine-tuning: The 200-hour robotics video corpus used for LoRA adaptation is mentioned but not characterized (scene diversity, viewpoints, object distribution); its impact on transfer and overfitting is unknown.
- Generalization under strong domain shift: SIMPLER offers some shift, but broader tests (new rooms, lighting, camera poses, novel object categories, clutter) are missing for both simulation and real-world.
- Baseline fairness and external pretraining: The “π0.5-style” baseline intentionally omits large-scale robot/data pretraining used in original VLA works; a matched-compute, matched-pretraining head-to-head comparison is not provided.
- Video backbone dependence: Results rely on Cosmos-Predict2; there is no systematic ablation across different video backbones, sizes, tokenizers, or training recipes to assess portability and sensitivity.
- Sample efficiency in the real world: While action data hours are reported, there is no explicit sample-efficiency scaling analysis in real-robot settings (success vs. demos curve, data per task threshold, asymptotes).
- Uncertainty and safety: The policy does not estimate uncertainty or enforce safety constraints; no framework is proposed for risk-aware control, collision avoidance, or recovery behaviors under uncertainty.
- Interpretability of visual plans: Intermediate video representations guiding control are not probed for interpretability (e.g., subgoal detection, keyframe extraction); debug tools for plan-action alignment are absent.
- Temporal alignment of video and actions: The method assumes clean alignment between latent video representations and action chunks; it does not study misalignment handling, time-warping, or latency compensation.
- Proprioception masking strategy: The practice of randomly masking proprioception during training is not ablated; its effect on robustness and overfitting is unknown.
- Horizon, chunking, and re-planning frequency: The choice of action horizon H, re-planning intervals, and their impact on stability, latency, and success rates are not evaluated systematically.
- Online adaptation and continual learning: The system does not incorporate online data collection, self-improvement, or RL fine-tuning; it is unclear how to adapt to new tasks or drift without full retraining.
- Task diversity and scale: Real-world evaluations cover two tasks; scaling to a broader repertoire, including fine manipulation and deformable/soft objects, is untested.
- Transfer across camera setups: The sensitivity to camera intrinsics/extrinsics, calibration errors, and camera changes (e.g., lens, resolution) is not studied.
- Action decoder architecture choices: Only a DiT-based flow-matching decoder is explored; comparisons with alternative decoders (RNN/Transformer causal models, diffusion vs. flow variants, latent-action spaces) are missing.
- Training schedule sensitivity: The effects of τ_a distribution, learning rates, LoRA ranks, and other scheduler choices on stability and performance are not ablated.
- Joint sampling from the video–action distribution: Although the model can, in principle, sample jointly, the paper does not evaluate whether joint sampling improves consistency, interpretability, or control robustness.
- Data and licensing reproducibility: The exact composition, availability, and licensing of the robotics video corpus for LoRA finetuning are not detailed, complicating replication and benchmarking.
- Energy and compute efficiency: The trade-offs between sample efficiency and computational cost (training/inference FLOPs, energy) are not quantified; deployment feasibility on resource-constrained platforms remains unclear.
Practical Applications
Immediate Applications
The following applications can be deployed now in controlled environments or with modest domain-specific finetuning and limited demonstrations. Each bullet lists the sector, the actionable use case, and the key dependencies/assumptions that affect feasibility.
- Manufacturing and Logistics
- Bimanual packing, kitting, and sorting cells (e.g., package sorting, bin-to-bin transfers, object stowing)
- Tools/workflows: integrate a mimic-video action decoder as a ROS node; LoRA-finetune the video backbone on in-domain videos; collect 1–3 hours of teleop demos per task for the action decoder.
- Dependencies: overhead workspace camera; GPU for real-time inference; safety interlocks; domain video corpus (tens to hundreds of hours) for LoRA finetuning; per-embodiment action decoder training.
- Occlusion-prone grasping and handovers using a single overhead camera
- Tools/workflows: deploy partial-denoising inference with τv≈1 for fast control; use “visual plan” introspection to debug failure modes; real-time policy server for chunked action execution.
- Dependencies: predictable lighting/background; time-synced sensing/control; reliable calibration of camera-to-robot frames.
- Low-data task onboarding for changeover lines
- Tools/workflows: “Skill-from-1–2 hours of demos” pipeline; τv sweep to optimize performance/latency trade-offs; LoRA adapters per product family.
- Dependencies: representative demos (covering object and pose variation); minimal covariate shift between onboarding and production runs.
- Lab Automation (Healthcare and Life Sciences)
- Gross manipulation tasks (e.g., vial/cap handling, tube sorting, tray loading/unloading) in benchtop cells
- Tools/products: domain video finetuning + small demo sets; visual plan monitor to validate robust sequencing under occlusions.
- Dependencies: non-sterile, controlled environments; consistent labware geometries; safety gating (force/torque limits). Fine liquid handling or sub-mm precision remains out of scope without further development.
- Retail and E-commerce Fulfillment
- Shelf restocking and tote sorting in micro-fulfillment centers
- Tools/workflows: overhead camera stations; lightweight teleop data collection; τv-tuned policies for speed.
- Dependencies: SKU variation covered by domain videos; collision-safe behaviors; seasonal product shifts (periodic adapters refresh).
- Construction and Fabrication Cells
- Tool pickup and placement, measuring, and simple assembly assistance (e.g., fixture loading)
- Tools/workflows: single-view workcells; action decoder per toolpack; “plan visualization” to validate sequences before live runs.
- Dependencies: rigid tooling and fixtures; consistent presentation; limited force-critical insertions.
- Robotics R&D and Academia
- Data-efficient imitation learning pipelines for new embodiments and tasks
- Tools/products: open-source training recipes (decoupled video LoRA + action flow matching), τv sweeps, Visual Plan Inspector, evaluation on SIMPLER/LIBERO.
- Dependencies: access to a pretrained video backbone (e.g., Cosmos-Predict2 or equivalent); compute for LoRA finetuning; telemetry logging for reproducibility.
- Rapid baseline replacement for VLA policies in research stacks
- Workflows: swap VLM conditioning for video-latent conditioning; preserve action decoder; measure sample-efficiency and convergence gains.
- Dependencies: compatible vision encoders/tokenizers; licensing of video models.
- Software/Tools
- mimic-video SDK for ROS/MoveIt integration and cloud/on-prem training
- Products: real-time inference server; LoRA finetuning toolkit; dataset ingestion from ROS bags; “Skill Compiler” (few-demos → action decoder weights); “Visual Plan Monitor” for debugging partial denoising.
- Dependencies: GPU availability; model weights licensing; MLOps for versioning and rollback.
- Governance and Safety (Policy within organizations)
- Internal validation protocols for video-pretrained robot policies
- Workflows: SIMPLER-style proxy tests before production; OOD stress tests (backgrounds, lighting, object shifts); uncertainty monitors via plan consistency checks.
- Dependencies: curated test suites; telemetry dashboards; documented fallback behaviors; process for τv changes (treated as safety-critical parameter updates).
Long-Term Applications
These require further research, scaling, or engineering (e.g., multi-view backbones, cross-embodiment generalization, safety certification).
- Generalist, Cross-Embodiment Controllers (Robotics/Software)
- One VAM controlling multiple robot types with minimal per-robot adaptation
- Products: unified action decoder with embodiment tokens; cross-robot skill libraries; centralized cloud foundation model.
- Dependencies: large, diverse robot video corpora; standardized action spaces or reliable embodiment adapters; robust domain randomization and safety guarantees.
- Home Robotics and Services
- Open-world manipulation with language-conditioned video plans (tidying, kitchen tasks, assistive support)
- Products: on-device VAM with local τv tuning; learning from sparse household demos; continual adaptation to user preferences.
- Dependencies: multi-view and on-robot cameras; reliable safety overlays; strong OOD robustness; privacy-preserving on-device finetuning.
- Healthcare and Surgical Assistance
- Dexterous, contact-rich tasks (e.g., instrument preparation, non-critical surgical assistance) under strict safety controls
- Workflows: clinically validated datasets; simulator-in-the-loop stress testing; regulatory audit trails for policies and τv schedules.
- Dependencies: certified safety envelopes; interpretable failure modes; latency-bounded inference; rigorous generalization/robustness proofs.
- Multi-View and 3D-Aware Video Backbones
- Native multi-camera video models for occlusion robustness and spatial reasoning
- Products: multi-view tokenizers; scene-centric latent representations (potentially JEPA-style); spatiotemporal consistency checks for plan reliability.
- Dependencies: synchronized multi-camera datasets; time-accurate calibration; efficient inference on edge hardware.
- Autonomous Data Engines
- Self-improving robots that log video+actions, curate data, finetune LoRA and action decoders online
- Workflows: active data selection, semi-automated labeling, periodic τv retuning; safety filters for on-robot learning.
- Dependencies: robust continual learning infrastructure; drift detection; guardrails against catastrophic forgetting.
- RL on Video Latents and Long-Horizon Planning
- Combine VAM with reinforcement learning for goal-conditioned, long-horizon skills
- Products: latent world-model planning; explicit uncertainty estimates; hierarchical policies (video-plan → action).
- Dependencies: reward design/tooling; scalable simulators; stable off-policy learning from mixed video/action logs.
- High-Precision Assembly and Tool Use in Industry
- Cable routing, connector insertions, electronics assembly with tight tolerances
- Workflows: integrate force/torque sensing; multi-view backbones; hybrid vision-force control with video-conditioned priors.
- Dependencies: high-fidelity sensing; domain-specific finetuning; safety certification for contact-rich operations.
- Agriculture, Mining, and Field Robotics
- Dexterous handling under variable conditions (fruit picking, sample collection)
- Products: weather-robust multi-view VAMs; on-device inference; self-supervised adaptation to seasonal shifts.
- Dependencies: ruggedized hardware; large field video corpora; robust power/compute at the edge.
- Safety Certification and Standards (Public Policy and Industry Standards)
- Regulatory frameworks for video-pretrained controllers in physical systems
- Workflows: standardized OOD benchmarks; auditability of plan latents; certifiable τv schedules; incident reporting norms.
- Dependencies: cross-industry consortiums; testbeds; traceable model/adapter provenance.
- Human-in-the-Loop and AR Teleoperation Assist
- Visual plan overlays for operators (predictive guidance for faster, safer teleop and training)
- Products: AR/VR interfaces showing partial denoised futures; mixed-initiative control (human corrects plan, robot executes).
- Dependencies: low-latency rendering; accurate time alignment; user studies and ergonomics validation.
Notes on Core Assumptions and Dependencies (common across applications)
- Pretrained video backbones: Access to high-quality, internet-scale video models (e.g., Cosmos-Predict2 or comparable) and licenses that allow finetuning for robotics.
- Domain adaptation: LoRA finetuning on domain-specific videos (often tens–hundreds of hours) to align semantics/dynamics; small amounts of teleop data (often 1–3 hours per task) to train action decoders.
- Real-time compute: GPUs or specialized accelerators to support partial-denoising and action decoding at control rates; τv tuning for latency-performance trade-offs.
- Embodiment-specific decoders: Today, per-embodiment action decoders are required; large-scale cross-embodiment unification is a long-term goal.
- Safety and compliance: Risk assessments, interlocks, and evaluation protocols (e.g., SIMPLER-like tests) are essential before deployment; formal certification remains a long-term effort.
- Data governance: Legal and privacy considerations for using internet or site-collected videos; reproducible MLOps for dataset/model versioning and rollbacks.
Glossary
- 3D-tokenizer: A learned encoder that converts spatiotemporal video patches into compact latent tokens. "3D-tokenizer."
- AdaLN: Adaptive layer normalization that conditions normalization parameters on side information (e.g., flow times). "modulated via AdaLN \cite{peebles2023scalablediffusionmodelstransformers}"
- Action chunk: A short horizon sequence of consecutive robot actions predicted and executed together. "For each action chunk, mimic-video generates a partially denoised video plan, and then executes the actions on the real robot."
- Action decoder: The policy module that maps observations and video features to low-level actions, trained via flow matching. "a lightweight action decoder that functions as an Inverse Dynamics Model (IDM)"
- Autoregressive: A modeling paradigm that predicts each token conditioned on previously generated tokens. "the autoregressive backbone is trained via Next Token Prediction"
- Bimanual: Involving two coordinated robot manipulators or hands. "a real-world bimanual robot setup"
- Bilinear-affine encoding: A low-rank conditioning scheme that mixes signals via bilinear and affine projections. "a low-rank bilinear-affine encoding of both video and action flow times and ."
- BridgeDataV2: A large real-robot dataset used for training and evaluation of manipulation policies. "BridgeDataV2 \cite{walke2024bridgedatav2datasetrobot}"
- Chain-of-Thought reasoning: A technique that elicits step-by-step intermediate reasoning for improved performance. "Chain-of-Thought reasoning~\cite{wei2022chain}"
- Conditional Flow Matching (CFM): A training objective for learning a vector field that transports noise to data conditioned on inputs. "Conditional Flow Matching (CFM) models"
- Conditional generating vector field: The time derivative of the interpolation between clean data and noise for a specific data sample. "is termed the conditional generating vector field"
- Continuous Normalizing Flow: A continuous-time generative model that transforms distributions by integrating an ODE. "Continuous Normalizing Flow \cite{chen2019neuralordinarydifferentialequations}"
- Cosmos-Predict2: A pretrained, open-source latent video Diffusion Transformer used as the video backbone. "Cosmos-Predict2 \cite{nvidia_world_2025,nvidia2025cosmosworldfoundationmodel}"
- Cross-attention: An attention mechanism that lets one sequence attend to another, e.g., video features attending to language tokens. "cross-attention to language instructions encoded by T5~\cite{raffel2023exploringlimitstransferlearning}"
- Cross-embodiment: Spanning or transferring across different robot morphologies or platforms. "massive web and cross-embodiment pretraining"
- Denoising Diffusion Models: Generative models that learn to reverse a gradual noising process to synthesize data. "Denoising Diffusion Models~\cite{ho_denoising_2020}"
- DiT (Diffusion Transformer): A transformer architecture tailored for diffusion/flow-based generative modeling. "latent Diffusion Transformer (DiT) \cite{peebles2023scalablediffusionmodelstransformers}"
- DiT-Block Policy: A diffusion transformer-based control policy architecture used as a baseline. "DiT-Block Policy~\cite{dasari2024ingredients}"
- Embodiment gap: The mismatch between human video demonstrations and robot capabilities or kinematics. "a severe embodiment gap."
- FAST: A method to discretize and compress actions for token-based training. "FAST~\cite{pertsch25-fast}"
- Flow Matching: A method to learn the velocity field that transports noise to data along a designed path. "Flow Matching framework~\cite{lipman_flow_2023}"
- Flow time: The continuous scalar variable that controls interpolation between noise and data in flow/diffusion models. "flow times "
- Generative video prior: Prior knowledge captured by a pretrained generative video model that guides control. "the predictive capacity of the generative video prior"
- Inference-time hyperparameter: A parameter chosen at sampling time (not during training) to trade off speed vs. fidelity. "an inference-time hyperparameter: the video flow time ."
- Inverse Dynamics Model (IDM): A model that infers the action needed to achieve a transition between states. "Inverse Dynamics Model (IDM)"
- Joint distribution: A combined probabilistic model over multiple variables (here, video and actions). "modeling the joint distribution of video and robot actions."
- Knowledge-Insulation protocol: A training scheme to protect pretrained knowledge by separating backbone and policy learning. "Adhering to the ``Knowledge-Insulation'' protocol~\cite{driess2025knowledge}"
- Latent representations: Hidden feature vectors produced by a model that summarize input information. "latent representations"
- LIBERO: A suite of multi-task simulated manipulation benchmarks. "LIBERO \cite{liu2023liberobenchmarkingknowledgetransfer}"
- LoRA (Low-Rank Adapters): Parameter-efficient finetuning using low-rank adapter layers added to a frozen model. "Low-Rank Adapters (LoRA)~\cite{hu2021loralowrankadaptationlarge}"
- Logit-normal distribution: A distribution over (0,1) obtained by applying a logistic transform to a normal variable. "a logit-normal distribution"
- Mutual information: An information-theoretic measure of dependence between random variables. "the mutual information "
- Next Token Prediction: An autoregressive training objective to predict the next token in a sequence. "Next Token Prediction"
- Octo: A generalist robot policy/baseline trained on large-scale data. "Octo \cite{team_octo_2024}"
- OpenVLA: A vision-language-action model baseline finetuned for robot control. "OpenVLA \cite{kim_openvla_2024}"
- Optimal transport path: A linear interpolation between data and noise used to define the flow trajectory in CFM. "the optimal transport path"
- PaliGemma: A 3B-parameter vision-LLM used as a backbone for VLA baselines. "PaliGemma~\cite{beyer2024paligemmaversatile3bvlm}"
- Partial denoising: Stopping generation at an intermediate noise level to extract useful features without full reconstruction. "partial denoising strategy"
- Proprioceptive state: The robot’s internal state (e.g., joint angles, velocities) used as input to the policy. "proprioceptive state"
- Residual path: A skip connection that bypasses a block to stabilize and ease optimization. "bypassed by a residual path"
- Self-attention: An attention mechanism relating positions within the same sequence. "self-attention over the full video sequence"
- SIMPLER: A high-fidelity simulation benchmark that mirrors real-world robot performance. "SIMPLER \cite{li2024evaluatingrealworldrobotmanipulation}"
- T5: A pretrained text encoder/decoder model used to encode language instructions. "T5~\cite{raffel2023exploringlimitstransferlearning}"
- Tokenized latent space: A compressed discrete representation of video frames used for generation and planning. "a compact, tokenized latent space."
- Video backbone: The pretrained video model that provides representations for downstream control. "The first stage focuses on the video backbone."
- Video diffusion backbone: A generative video model based on diffusion/flow used to synthesize/planning future frames. "Built upon a state-of-the-art video diffusion backbone"
- Video latents: Compressed latent variables representing video frames used by the video model. "video latents"
- Video-Action Model (VAM): A model class that couples video generation with action decoding for robot control. "Video-Action Model (VAM)"
- Vision-LLMs (VLMs): Models pretrained on paired image-text data to learn visual-semantic representations. "Vision-LLMs (VLMs)"
- Vision-Language-Action Models (VLAs): VLM-based policies augmented with action decoding for robotics. "Vision-Language-Action Models (VLAs)"
- World models: Predictive models that learn environment dynamics for planning and control. "learning predictive world models"
Collections
Sign up for free to add this paper to one or more collections.

